这里写目录标题
- NumPy - 简介
- NumPy 操作
- NumPy – MatLab 的替代之一
- NumPy - Ndarray 对象
- NumPy - 数据类型
- NumPy - 数组属性
- NumPy - 数组创建例程
- NumPy - 来自现有数据的数组
- NumPy - 来自数值范围的数组
- NumPy - 切片和索引
- 基本切片 slice()
- NumPy - 高级索引
- NumPy - 广播
- NumPy - 数组上的迭代
- NumPy - 数组操作
-
- 修改形状
- numpy.reshape()
- numpy.ndarray.flat()
- numpy.*ndarray*.flatten()
- numpy.ravel()
- 翻转操作
- numpy.transpose()
- numpy.ndarray.T 方法
- numpy.rollaxis()
- numpy.swapaxes()
- 修改维度
- broadcast
- numpy.broadcast_to
- numpy.expand_dims
- numpy.squeeze
- 数组的连接
- numpy.concatenate
- numpy.stack
- numpy.hstack
- numpy.vstack
- 数组分割
- numpy.split
- numpy.hsplit
- numpy.vsplit
- 添加/删除元素
- numpy.resize
- numpy.append
- numpy.insert
- numpy.delete
- numpy.unique
NumPy - 简介
NumPy 是一个 Python 包。 它代表 “Numeric Python”。 它是一个由多维数组对象和用于处理数组的例程集合组成的库。
Numeric,即 NumPy 的前身,是由 Jim Hugunin 开发的。 也开发了另一个包 Numarray ,它拥有一些额外的功能。 2005年,Travis Oliphant 通过将 Numarray 的功能集成到 Numeric 包中来创建 NumPy 包。 这个开源项目有很多贡献者。
NumPy 操作
使用NumPy,开发人员可以执行以下操作:
- 数组的算数和逻辑运算。
- 傅立叶变换和用于图形操作的例程。
- 与线性代数有关的操作。 NumPy 拥有线性代数和随机数生成的内置函数。
NumPy – MatLab 的替代之一
NumPy 通常与 SciPy(Scientific Python)和 Matplotlib(绘图库)一起使用。 这种组合广泛用于替代 MatLab,是一个流行的技术计算平台。 但是,Python 作为 MatLab 的替代方案,现在被视为一种更加现代和完整的编程语言。
NumPy 是开源的,这是它的一个额外的优势
NumPy - Ndarray 对象
NumPy 中定义的最重要的对象是称为 ndarray 的 N 维数组类型。 它描述相同类型的元素集合(笔记:固定类型元素的组合;采用C语言的数组形式)。 可以使用基于零的索引访问集合中的项目。
ndarray中的每个元素在内存中使用相同大小的块。 ndarray中的每个元素是数据类型对象的对象(称为 dtype)。
从ndarray对象提取的任何元素(通过切片)由一个数组标量类型的 Python 对象表示。
下图显示了ndarray,数据类型对象(dtype)和数组标量类型之间的关系。
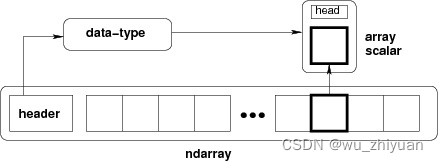
Ndarray (笔记:Ndarray 即 numpy data array)
ndarray类的实例可以通过本教程后面描述的不同的数组创建例程来构造。 基本的ndarray是使用 NumPy 中的数组函数创建的,如下所示:
# python
# 笔记:创建一个空ndarray对象
numpy.array
它从任何暴露数组接口的对象,或从返回数组的任何方法创建一个ndarray。
( 笔记:
通过拷贝其他数组对象object来创建一个ndarray对象
暴露接口:
就是你写好了一段程序,提供给别人一个访问的接口,别人不管你怎么实现的,调用者只需知道访问的方法及返回值就可以。如:你写的方法
public int sum(int a,int b){
int c = 0;
....
return c;
}
调用者不管你sum怎么实现,只需知道sum()需要两个int参数,返回值是int即可。
那么,暴露数组接口 即可以理解为返回值为数组的接口。
)
# Python
# 笔记:创建一个ndarray对象,并用object对其进行初始化
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
上面的构造器接受以下参数:
- object 任何暴露数组接口方法的对象都会返回一个数组或任何(嵌套)序列。
- dtype 数组的所需数据类型,可选。
- copy 可选,默认为true,对象是否被复制。
- order C(按行)、F(按列)或A(任意,默认)。
- subok 默认情况下,返回的数组被强制为基类数组。 如果为true,则返回子类。
- ndmin 指定返回数组的最小维数。
(笔记:subok 不理解)
看看下面的例子来更好地理解。
示例 1
import numpy as np
a = np.array([1,2,3]) # 采用暴露数组接口的方式创建ndarray
print a
# 输出如下:
[1, 2, 3]
示例 2 多维数组
# 多于一个维度
import numpy as np
a = np.array([[1, 2], [3, 4]]) # 二维数组
print a
# 输出如下:
[[1, 2]
[3, 4]]
示例 3 最小维度参数
# 最小维度
import numpy as np
a = np.array([1, 2, 3, 4, 5], ndmin = 2) # 最小维度为2
print a
# 输出如下:
[[1, 2, 3, 4, 5]]
# 笔记:最小维度为2,但是创建时只用了一维数组,因此ndarray会有一个空维度,即:[ [1, 2, 3, 4, 5] [] ],空维度不显示所以成如上显示
示例 4 指定元素类型
# dtype 参数
import numpy as np
a = np.array([1, 2, 3], dtype = complex) # 设置类型 complex表示复数; 创建时,将元素转换为负数
print a
# 输出如下:
[ 1.+0.j, 2.+0.j, 3.+0.j]
**ndarray ** 对象由计算机内存中的一维连续区域组成,带有将每个元素映射到内存块中某个位置的索引方案。 内存块以按行(C 风格)或按列(FORTRAN 或 MatLab 风格)的方式保存元素。
NumPy - 数据类型
NumPy 支持比 Python 更多种类的数值类型。 下表显示了 NumPy 中定义的不同标量数据类型。
| 名称 | 描述 |
|---|---|
| bool_ | 布尔型数据类型(True 或者 False) |
| int_ | 默认的整数类型(类似于 C 语言中的 long,int32 或 int64) |
| intc | 与 C 的 int 类型一样,一般是 int32 或 int 64 |
| intp | 用于索引的整数类型(类似于 C 的 ssize_t,一般情况下仍然是 int32 或 int64) |
| int8 | 字节(-128 to 127) |
| int16 | 整数(-32768 to 32767) |
| int32 | 整数(-2147483648 to 2147483647) |
| int64 | 整数(-9223372036854775808 to 9223372036854775807) |
| uint8 | 无符号整数(0 to 255) |
| uint16 | 无符号整数(0 to 65535) |
| uint32 | 无符号整数(0 to 4294967295) |
| uint64 | 无符号整数(0 to 18446744073709551615) |
| float_ | float64 类型的简写 |
| float16 | 半精度浮点数,包括:1 个符号位,5 个指数位,10 个尾数位 |
| float32 | 单精度浮点数,包括:1 个符号位,8 个指数位,23 个尾数位 |
| float64 | 双精度浮点数,包括:1 个符号位,11 个指数位,52 个尾数位 |
| complex_ | complex128 类型的简写,即 128 位复数 |
| complex64 | 复数,表示双 32 位浮点数(实数部分和虚数部分) |
| complex128 | 复数,表示双 64 位浮点数(实数部分和虚数部分) |
NumPy 数字类型是dtype(数据类型)对象的实例,每个对象具有唯一的特征。 这些类型可以是np.bool_,np.float32等。
数据类型对象 (dtype)
数据类型对象(dtype)描述了对应于数组的固定内存块的解释(笔记:参考上图,更易理解),取决于以下方面:
- 数据类型(整数、浮点或者 Python 对象)
- 数据大小
- 字节序(小端或大端)
- 在结构化类型的情况下,字段的名称,每个字段的数据类型,和每个字段占用的内存块部分。
- 如果数据类型是子序列,它的形状和数据类型。
字节顺序取决于数据类型的前缀<或>。
- 意味着编码是小端(最小有效字节存储在最小地址中)。
- 意味着编码是大端(最大有效字节存储在最小地址中)。
dtype可由一下语法构造:
numpy.dtype(object, align, copy)
参数为:
-
Object:被转换为数据类型的对象。
-
Align:如果为true,则向字段添加间隔,使其类似 C 的结构体。
-
Copy: 生成dtype对象的新副本,如果为flase,结果是内建数据类型对象的引用。
示例 1
# 使用数组标量类型
import numpy as np
dt = np.dtype(np.int32)
print dt
# 输出如下:
int32
示例 2 int8 等价于 i1
笔记:int8,int16,int32,int64 可替换为等价的字符串 ‘i1’,‘i2’,‘i4’,以及其他。 i1 中 1表示1个字节,1个字节为8位,因此 i1 等价于 int8
#int8,int16,int32,int64 可替换为等价的字符串 'i1','i2','i4',以及其他。
import numpy as np
dt = np.dtype('i4') # int32 即:4字节*8位
print dt
#输出如下:
int32
示例 3 端记号
# 使用端记号
import numpy as np
dt = np.dtype('>i4')
print dt
# 输出如下:
>i4
笔记:端记号的作用??
下面的例子展示了结构化数据类型的使用。 这里声明了字段名称和相应的标量数据类型。
示例 4 简单的结构化数据类型
笔记:所谓结构化数据类型,即:多种数据类型的结构体。注意:定义结构化类型时,方括号的使用。例如:[ (‘age’, np.int8) ] ,方括号内还有一层小括号。方括号表示为列表,小括号为元组
# 首先创建结构化数据类型。
import numpy as np
dt = np.dtype([('age',np.int8)]) # 注意:定义结构化类型时,方括号的使用。[('age',np.int8)] 方括号内还有一层小括号
print dt
# 输出如下:
[('age', 'i1')]
示例 5 将定义的dtype应用于 ndarray 对象
# 现在将其应用于 ndarray 对象
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt) # 没理解 dt结构化类型 如何定义的ndarray的元素?
print a
# 输出如下:
[(10,) (20,) (30,)]
笔记:没理解 dt结构化类型 如何定义的ndarray的元素?
看下例,解释了age的作用,‘age’原来作为列名使用。即,age = [10 20 30]。
[(10,),(20,),(30,)] 的排列结构:
| 列 0 列名:‘age’ | 列 1 列名:null | |
|---|---|---|
| 行0 | 10 | null |
| 行1 | 20 | null |
| 行2 | 30 | null |
示例 6 ndarray列名的用法
# 文件名称可用于访问 age 列的内容
import numpy as np
dt = np.dtype([('age',np.int8)])
a = np.array([(10,),(20,),(30,)], dtype = dt)
print a['age']
# 输出如下:
[10 20 30] # 有疑惑看上例
示例 7 复杂的结构化数据类型
以下示例定义名为 student 的结构化数据类型,其中包含字符串字段name,整数字段age和浮点字段marks。 此dtype应用于ndarray对象。
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
print student
# 输出如下:
[('name', 'S20'), ('age', 'i1'), ('marks', '<f4')])
示例 8 复杂的结构化数据类型定义ndarray
import numpy as np
student = np.dtype([('name','S20'), ('age', 'i1'), ('marks', 'f4')])
a = np.array([('abc', 21, 50),('xyz', 18, 75)], dtype = student)
print a
#输出如下:
[('abc', 21, 50.0), ('xyz', 18, 75.0)]
内建类型的符号代码
每个内建类型都有一个唯一定义它的字符代码:
- ‘b’:布尔值
- ‘i’:符号整数
- ‘u’:无符号整数
- ‘f’:浮点
- ‘c’:复数浮点
- ‘m’:时间间隔
- ‘M’:日期时间
- ‘O’:Python 对象
- ‘S’, ‘a’:字节串
- ‘U’:Unicode
- ‘V’:原始数据(void)
NumPy - 数组属性
这一章中,我们会讨论 NumPy 的多种数组属性。
ndarray.shape属性 与 ndarray.reshape()方法
这一数组属性返回一个包含数组维度的元组,它也可以用于调整数组大小。
示例 1 a.shape是数组a的属性,返回包含数组维度的元组
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
print a.shape # 注意:a.shape是数组a的属性,返回一个元组,该元组包含数组维度。
# 输出如下:
(2, 3)
示例 2 通过shape数组调整数组矩阵
# 这会调整数组大小
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
a.shape = (3,2) # 调整数组 矩阵
print a
# 输出如下:
[[1, 2]
[3, 4]
[5, 6]]
示例 3 reshape函数调整数组矩阵,与shape属性类似
NumPy 也提供了reshape函数来调整数组大小。
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = a.reshape(3,2) # 也可以写为:a.shape = (3,2) b = a
print b
# 输出如下:
[[1, 2]
[3, 4]
[5, 6]]
ndarray.ndim属性
这一数组属性返回数组的维数。
示例 1 np.arange() 一种初始化数组的方法
# 等间隔数字的数组
import numpy as np
a = np.arange(24) # 一种初始化数组的方法
print a
#输出如下:
[0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23]
示例 2 print(a.ndim) 数组的维度
# 一维数组
import numpy as np
a = np.arange(24)
print(a.ndim)
# 现在调整其大小
b = a.reshape(2,4,3)
print(b)
# 输出如下:
1 # print(a.ndim)
[[[ 0, 1, 2] # print(b) 三维数组
[ 3, 4, 5]
[ 6, 7, 8]
[ 9, 10, 11]]
[[12, 13, 14]
[15, 16, 17]
[18, 19, 20]
[21, 22, 23]]]
numpy.itemsize属性
这一数组属性返回数组中每个元素的字节单位长度。
示例 1 x.itemsize元素的字节长度
# 数组的 dtype 为 int8(一个字节)
import numpy as np
x = np.array([1,2,3,4,5], dtype = np.int8)
print x.itemsize
# 输出如下: 8位一个字节,因此x.itemsize = 1
1
示例 2
# 数组的 dtype 现在为 float32(四个字节)
import numpy as np
x = np.array([1,2,3,4,5], dtype = np.float32)
print x.itemsize
# 输出如下:
4
numpy.flags
ndarray对象拥有以下属性。这个函数返回了它们的当前值。
| 序号 | 属性及描述 |
|---|---|
| C_CONTIGUOUS ( C) | 数组位于单一的、C 风格的连续区段内 |
| F_CONTIGUOUS (F) | 数组位于单一的、Fortran 风格的连续区段内 |
| OWNDATA (O) | 数组的内存从其它对象处借用 |
| WRITEABLE (W) | 数据区域可写入。 将它设置为flase会锁定数据,使其只读 |
| ALIGNED (A) | 数据和任何元素会为硬件适当对齐 |
| UPDATEIFCOPY (U) | 这个数组是另一数组的副本。当这个数组释放时,源数组会由这个数组中的元素更新 |
示例
下面的例子展示当前的标志。
import numpy as np
x = np.array([1,2,3,4,5])
print x.flags
# 输出如下:
C_CONTIGUOUS : True
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
UPDATEIFCOPY : False
NumPy - 数组创建例程
新的ndarray对象可以通过任何下列数组创建例程或使用低级ndarray构造函数构造。
numpy.empty方法 创建未初始化的数组
它创建指定形状和dtype的未初始化数组。 它使用以下构造函数:
numpy.empty(shape, dtype = float, order = 'C')
构造器接受下列参数:
| 序号 | 参数及描述 |
|---|---|
| shape | 空数组的形状,整数或整数元组 |
| dtype | 所需的输出数组类型,可选 |
| order | 'C’为按行的 C 风格数组,'F’为按列的 Fortran 风格数组 |
示例
下面的代码展示空数组的例子:
import numpy as np
x = np.empty([3,2], dtype = int) # 创建未初始化的数组
print (x)
#输出如下: 因为未被初始化,所以
[[1701336096 1634235168]
[1864394096 1752440934]
[1701716069 1918967927]]
注意:数组元素为随机值,因为它们未初始化。
numpy.zeros 创建用0初始化的数组
返回特定大小,以 0 填充的新数组。
numpy.zeros(shape, dtype = float, order = 'C')
构造器接受下列参数:同numpy.empty方法
示例 1 np.zeros()默认:dtype = float
# 含有 5 个 0 的数组,默认类型为 float
import numpy as np
x = np.zeros(5) # 默认:dtype = float
print (x)
# 输出如下:
[ 0. 0. 0. 0. 0.]
示例 2
import numpy as np
x = np.zeros((5,), dtype = np.int)
print x
输出如下:
[0 0 0 0 0]
示例 3 np.zeros() dtype的自定义类型
# 自定义类型
import numpy as np
x = np.zeros((2,2), dtype = [('x', 'i4'), ('y', 'i4')]) #笔记:元素自定义类型,一个元素有2组变量 名称为x的一组,y为另一组
print (x)
print(x['x']) # 元素的名称输出
# 输出如下:
[[(0,0)(0,0)] # print (x)
[(0,0)(0,0)]]
[[0 0] # print(x['x']) # 元素的名称输出
[0 0]]
numpy.ones() 创建初始值为1的数组
返回特定大小,以 1 填充的新数组。
numpy.ones(shape, dtype = None, order = 'C')
构造器接受下列参数:同np.zeros() 和np.empty()
笔记:numpy.ones()方法的dtype属性默认值为float(测试验证),此处于np.zeros() 和np.empty()相同。
示例 1 numpy.ones()的dtype属性默认值为float
# 含有 5 个 1 的数组,默认类型为 float
import numpy as np
x = np.ones(5)
print(x)
#输出如下:
[ 1. 1. 1. 1. 1.]
示例 2
import numpy as np
x = np.ones([2,2], dtype = int)
print(x)
# 输出如下:
[[1 1]
[1 1]]
NumPy - 来自现有数据的数组
这一章中,我们会讨论如何从现有数据创建数组。
numpy.asarray() - Python 序列转换为ndarray非常有用
此函数类似于numpy.array,除了它有较少的参数。 这个例程对于将 Python 序列转换为ndarray非常有用。
numpy.asarray(a, dtype = None, order = None)
构造器接受下列参数:
- a
任意形式的输入参数,比如列表、列表的元组、元组、元组的元组、元组的列表 - dtype
通常,输入数据的类型会应用到返回的ndarray - order
'C’为按行的 C 风格数组,'F’为按列的 Fortran 风格数组
下面的例子展示了如何使用asarray函数:
示例 1 list 转 ndarray
# 将列表转换为 ndarray
import numpy as np
x = [1,2,3] # python list
a = np.asarray(x)
print(a)
# 输出如下:
[1 2 3]
示例 2 转变元素类型
# 设置了 dtype
import numpy as np
x = [1,2,3]
a = np.asarray(x, dtype = float)
print a
# 输出如下:
[ 1. 2. 3.]
示例 3 tuple 转 ndarray
# 来自元组的 ndarray
import numpy as np
x = (1,2,3)
a = np.asarray(x)
print(a)
# 输出如下:
[1 2 3]
示例 4 元组的列表 转 ndarray
# 来自元组列表的 ndarray
import numpy as np
x = [(1,2,3),(4,5)]
a = np.asarray(x)
print a
# 输出如下:
[(1, 2, 3) (4, 5)]
numpy.frombuffer() - 将缓冲区解释为一维数组
此函数将缓冲区解释为一维数组。 暴露缓冲区接口的任何对象都用作参数来返回ndarray。
numpy.frombuffer(buffer, dtype = float, count = -1, offset = 0)
构造器接受下列参数:
序号 参数及描述
- buffer
任何暴露缓冲区接口的对象 笔记:开辟内存对象或者数组 - dtype
返回数组的数据类型,默认为float - count
需要读取的数据数量,默认为-1,读取所有数据 - offset
需要读取的起始位置,默认为0
示例1
下面的例子展示了frombuffer函数的用法。
import numpy as np
s = 'Hello World'
a = np.frombuffer(s, dtype = 'S1')
print(a)
# 输出如下:
['H' 'e' 'l' 'l' 'o' ' ' 'W' 'o' 'r' 'l' 'd']
示例2
import numpy as np
...
img_buff = (c_ubyte * st_convert_param.nDstBufferSize)() # 创建c_ubyte类型图像缓存区
cdll.msvcrt.memcpy(byref(img_buff), st_convert_param.pDstBuffer, st_convert_param.nDstBufferSize) # 为图像缓冲区赋值
# img_buff 转为 numpy类型
img_buff = numpy.frombuffer(img_buff, count=int(st_convert_param.nDstBufferSize), dtype=numpy.uint8)
# 重构
img_buff = img_buff.reshape((frame_info.nHeight, frame_info.nWidth))
...
numpy.fromiter() 可迭代对象构建ndarray对象
此函数从任何可迭代对象构建一个ndarray对象,返回一个新的一维数组。
numpy.fromiter(iterable, dtype, count = -1)
构造器接受下列参数:
- iterable
任何可迭代对象 - dtype
返回数组的数据类型 - count
需要读取的数据数量,默认为-1,读取所有数据
以下示例展示了如何使用内置的range()函数返回列表对象。 此列表的迭代器用于形成ndarray对象。
示例 1 使用 range 函数创建列表对象
# 使用 range 函数创建列表对象
import numpy as np
list = range(5)
print list
# 输出如下:
[0, 1, 2, 3, 4]
示例 2 使用迭代器创建 ndarray
# 从列表中获得迭代器
import numpy as np
list = range(5)
it = iter(list) # 创建迭代器
# 使用迭代器创建 ndarray
x = np.fromiter(it, dtype = float)
print(x)
# 输出如下:
[0. 1. 2. 3. 4.]
NumPy - 来自数值范围的数组
这一章中,我们会学到如何从数值范围创建数组。
numpy.arange() 生成范围内等间隔值 ndarray对象
这个函数返回ndarray对象,包含给定范围内的等间隔值。
numpy.arange(start, stop, step, dtype)
构造器接受下列参数:
- start
范围的起始值,默认为0 - stop
范围的终止值(不包含) - step
两个值的间隔,默认为1 - dtype
返回ndarray的数据类型,如果没有提供,则会使用输入数据的类型。
下面的例子展示了如何使用该函数:
示例 1
import numpy as np
x = np.arange(5)
print(x)
# 输出如下:
[0 1 2 3 4]
示例 2
import numpy as np
# 设置了 dtype
x = np.arange(5, dtype = float)
print(x)
# 输出如下:
[0. 1. 2. 3. 4.]
示例 3
# 设置了起始值和终止值参数
import numpy as np
x = np.arange(10,20,2)
print(x)
# 输出如下:
[10 12 14 16 18]
numpy.linspace() 类似于arange()函数
此函数类似于arange()函数。 在此函数中,指定了范围之间的均匀间隔数量,而不是步长。 此函数的用法如下。
笔记:linspace()的特点是 均匀间隔,也就是说不需要设置步长,设置中间有多少个数(均匀间隔数量)就可以了。
numpy.linspace(start, stop, num, endpoint, retstep, dtype)
构造器接受下列参数:
- start
序列的起始值 - stop
序列的终止值,如果endpoint为true,该值包含于序列中 - num
要生成的等间隔样例数量,默认为50 - endpoint
序列中是否包含stop值,默认为ture - retstep
如果为true,返回样例,以及连续数字之间的步长 - dtype
输出ndarray的数据类型,默认类型float
下面的例子展示了linspace函数的用法。
示例 1 均匀间隔
import numpy as np
x = np.linspace(10,20,5) # 默认endpoint = true, 包含终止值20; 默认dtype=float
print x
# 输出如下:
[10. 12.5 15. 17.5 20.]
示例 2
# 将 endpoint 设为 false
import numpy as np
x = np.linspace(10, 20, 5, endpoint = False) # 不包含最后一个数20
print(x)
# 输出如下:
[10. 12. 14. 16. 18.]
示例 3 输出 retstep 值,即:输出步长
笔记:步长是等距间隔,不需要人工输出,但是将 retstep = True,可以输出该步长。
# 输出 retstep 值
import numpy as np
x = np.linspace(1,2,5, retstep = True)
print x
# 这里的 retstep 为 0.25
# 输出如下:
(array([ 1. , 1.25, 1.5 , 1.75, 2. ]), 0.25)
numpy.logspace 对数刻度均匀分布
此函数返回一个ndarray对象,其中包含在对数刻度上均匀分布的数字。 刻度的开始和结束端点是某个底数的幂,通常为 10。
numpy.logscale(start, stop, num, endpoint, base, dtype)
logspace函数的输出由以下参数决定:
- start
起始值是base ** start - stop
终止值是base ** stop - num
范围内的数值数量,默认为50 - endpoint
如果为true,终止值包含在输出数组当中 - base
对数空间的底数,默认为10 - dtype
输出数组的数据类型,如果没有提供,则取决于其它参数
下面的例子展示了logspace函数的用法。
示例 1
import numpy as np
# 默认底数是 10
a = np.logspace(1.0, 2.0, num = 10)
print a
# 输出如下:
[ 10. 12.91549665 16.68100537 21.5443469 27.82559402
35.93813664 46.41588834 59.94842503 77.42636827 100. ]
示例 2
# 将对数空间的底数设置为 2
import numpy as np
a = np.logspace(1,10,num = 10, base = 2)
print a
# 输出如下:
[ 2. 4. 8. 16. 32. 64. 128. 256. 512. 1024.]
NumPy - 切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,就像 Python 的内置容器对象一样。
如前所述,ndarray对象中的元素遵循基于零的索引。
有三种可用的索引方法类型:
- 字段访问
- 基本切片
- 高级索引
基本切片 slice()
基本切片是 Python 中基本切片概念到 n 维的扩展。 通过将start,stop和step参数提供给内置的slice函数来构造一个 Python slice对象。 此slice对象被传递给数组来提取数组的一部分。
示例 1 设置切片范围slice()
import numpy as np
a = np.arange(10) # [0 1 2 3 4 5 6 7 8 9]
s = slice(2,7,2) # 创造切片。参数:起始,终止和步长
print a[s] # 获得a的s切片
# 输出如下:
[2 4 6]
在上面的例子中,ndarray对象由arange()函数创建。
然后,分别用起始,终止和步长值2,7和2定义切片对象。 当这个切片对象传递给ndarray时,会对它的一部分进行切片,从索引2到7,步长为2。
通过将由冒号分隔的切片参数(start:stop:step)直接提供给ndarray对象,也可以获得相同的结果。
示例 2 直接切片 - 切片参数(start:stop:step)
import numpy as np
a = np.arange(10)
b = a[2:7:2] # 等效于 s = slice(2,7,2) a[s]
# [起始:终止:步长] 可以只写需要的部分
print b
# 输出如下:
[2 4 6]
如果只输入一个参数,则将返回与索引对应的单个项目。 如果使用a:,则从该索引向后的所有项目将被提取。 如果使用两个参数(以:分隔),则对两个索引(不包括停止索引)之间的元素以默认步骤进行切片。
示例 3 对单个元素进行切片
# 对单个元素进行切片
import numpy as np
a = np.arange(10)
b = a[5]
print b
# 输出如下:
5
示例 4 只包含起始的切片[start:]
# 对始于索引的元素进行切片
import numpy as np
a = np.arange(10)
print a[2:]
# 输出如下:
[2 3 4 5 6 7 8 9]
示例 5 包含起始和终止的切片[start:end]
# 对索引之间的元素进行切片
import numpy as np
a = np.arange(10)
print a[2:5]
# 输出如下:
[2 3 4]
上面的描述也可用于多维ndarray。
示例 6 多维数组切片
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print(a)
# 对始于索引的元素进行切片
print '现在我们从索引 a[1:] 开始对数组切片'
print (a[1:])
# 输出如下: # print(a)
[[1 2 3]
[3 4 5]
[4 5 6]]
现在我们从索引 a[1:] 开始对数组切片
# print (a[1:])
[[3 4 5]
[4 5 6]]
笔记:在多维数组切片时,第一维切片例如a[1:] 中1表示切片第一维数组的第二个元素值开始至最后一个元素;那么第二维切片怎么表示呢?
第二维切片,例如a[…,1]中“逗号”后面的1表示第二维度数组的第二个元素。由此可见,**“逗号”**是区分维度的关键。再例如a[…,1:]因为1后面多了“:”则表示第二维度数组的第二个元素开始至最后一个元素;
切片还可以包括省略号(…),来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它将返回包含行中元素的ndarray。
示例 7 多维数组切片
# 最开始的数组
import numpy as np
a = np.array([[1,2,3],[3,4,5],[4,5,6]])
print '我们的数组是:'
print a
print '\n'
# 这会返回第二列元素的数组:
print '第二列的元素是:'
print a[...,1] # 切片包含省略号(...),来使选择元组的长度与数组的维度相同。
print '\n'
# 现在我们从第二行切片所有元素:
print '第二行的元素是:'
print a[1,...]
print '\n'
# 现在我们从第二列向后切片所有元素:
print '第二列及其剩余元素是:'
print a[...,1:]
#输出如下:
我们的数组是: # print(a)
[[1 2 3]
[3 4 5]
[4 5 6]]
第二列的元素是: # print a[...,1]
[2 4 5]
第二行的元素是: # print a[1,...]
[3 4 5]
第二列及其剩余元素是:
[[2 3]
[4 5]
[5 6]]
NumPy - 高级索引
如果一个ndarray是非元组序列,数据类型为整数或布尔值的ndarray,或者至少一个元素为序列对象的元组,我们就能够用它来索引ndarray。高级索引始终返回数据的副本。 与此相反,切片只提供了一个视图。
有两种类型的高级索引:
- 整数
- 布尔值
整数索引
这种机制有助于基于 N 维索引来获取数组中任意元素。 每个整数数组表示该维度的下标值。 当索引的元素个数就是目标ndarray的维度时,会变得相当直接。
以下示例获取了ndarray对象中每一行指定列的一个元素。 因此,行索引包含所有行号,列索引指定要选择的元素。
示例 1 高级索引之二维下标矩阵
笔记:此种方法获得一维数组
import numpy as np
x = np.array([[1, 2], [3, 4], [5, 6]])
y = x[[0,1,2], [0,1,0]]
'''
笔记:理解下标矩阵
[[0,1,2], [0,1,0]] 组成了一个二维下标矩阵
[0,1,2] 为第一维下标队列
[0,1,0] 为第二维下标队列
组合为矩阵后,列1为 第一维下标队列,列2为 第二维下标队列
(0,0)
(1,1)
(2,0)
'''
print y
# 输出如下:
[1 4 5] # 获得的是一维数组
该结果包括数组中(0,0),(1,1)和(2,0)位置处的元素。
下面的示例获取了 4X3 数组中的每个角处的元素。 行索引是[0,0]和[3,3],而列索引是[0,2]和[0,2]。
示例 2 行下标矩阵与列下标矩阵
笔记:此种方法获得二维数组
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print ('我们的数组是:')
print (x)
print ('\n')
rows = np.array([[0,0],[3,3]])
cols = np.array([[0,2],[0,2]])
y = x[rows,cols]
'''
笔记:理解行列下标矩阵
rows获得据矩阵为
0,0
3,3
cols获得的矩阵为
0,2
0,2
[rows,cols] 获得矩阵为:
[0,0],[0,2]
[3,0],[3,2]
'''
print '这个数组的每个角处的元素是:'
print y
# 输出如下:
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
这个数组的每个角处的元素是:
[[ 0 2]
[ 9 11]]
返回的结果是包含每个角元素的ndarray对象。
高级和基本索引可以通过使用切片:或省略号…与索引数组组合。 以下示例使用slice作为列索引和高级索引。 当切片用于两者时,结果是相同的。 但高级索引会导致复制,并且可能有不同的内存布局。
示例 3 使用slice作为列索引和高级索引
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]]) # 二维数组
print '我们的数组是:'
print x
print '\n'
# 切片
z = x[1:4,1:3] # 切片 写法
print '切片之后,我们的数组变为:'
print z
print '\n'
# 对列使用高级索引
y = x[1:4,[1,2]] # 高级索引 写法
print '对列使用高级索引来切片:'
print y
# 输出如下:
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
切片之后,我们的数组变为:
[[ 4 5]
[ 7 8]
[10 11]]
对列使用高级索引来切片:
[[ 4 5]
[ 7 8]
[10 11]]
笔记:
切片和高级索引的区别:
切片是连续的,而高级索引可以不是连续的。因此,高级所以更灵活。
切片和高级索引的相同点:
切片可以获得一维数组,也可以切片多维数组。
高级索引同样可以获得一维数组,也可以获得多维数组。
布尔索引
当结果对象是布尔运算(例如比较运算符)的结果时,将使用此类型的高级索引。
示例 1 一维布尔索引
这个例子中,大于 5 的元素会作为布尔索引的结果返回。
import numpy as np
x = np.array([[ 0, 1, 2],[ 3, 4, 5],[ 6, 7, 8],[ 9, 10, 11]])
print '我们的数组是:'
print x
print '\n'
# 现在我们会打印出大于 5 的元素
print '大于 5 的元素是:'
print x[x > 5] # 布尔索引 一维布尔索引,比如:[x > 5]
#输出如下:
我们的数组是:
[[ 0 1 2]
[ 3 4 5]
[ 6 7 8]
[ 9 10 11]]
大于 5 的元素是:
[ 6 7 8 9 10 11]
示例 2
这个例子使用了~(取补运算符)来过滤NaN。
笔记:nan(NAN,Nan): not a number 表示不是一个数字,np.nan是一个float类型的数据
import numpy as np
a = np.array([np.nan, 1, 2, np.nan, 3,4,5]) # 笔记:array的参数[np.nan, 1, 2, np.nan, 3,4,5]是一个列表,由2个非数字(np.nan)和5个数字组成
print a[~np.isnan(a)] # 笔记:np.isnan(a) 判断是否为非数字,~np.isnan(a)表示是否为数字
# 输出如下:
[ 1. 2. 3. 4. 5.]
示例 3
以下示例显示如何从数组中过滤掉非复数元素。
import numpy as np
a = np.array([1, 2+6j, 5, 3.5+5j])
print a[np.iscomplex(a)]
#输出如下:
[2.0+6.j 3.5+5.j]
NumPy - 广播
术语广播是指 NumPy 在算术运算期间处理不同形状的数组的能力。 对数组的算术运算通常在相应的元素上进行。 如果两个阵列具有完全相同的形状,则这些操作被无缝执行。
笔记:广播 是 对不同形状的数组(shape)进行数值计算的方式,对数组的算术运算通常在响应的元素上进行。
示例 1 - 2组数量相同的队列 相乘
import numpy as np
a = np.array([1,2,3,4])
b = np.array([10,20,30,40])
c = a * b
print c
# 输出如下:
[10 40 90 160]
形状相同
如果两个数组a和b形状相同,即:a.shape() == b.shape(),那么a+b的结果就是a与b数组对应位元素相加。要求,维度相同,且对应维度的长度相同。
形状不同
如果两个数组的维数不相同,则元素到元素的操作是不可能的。 然而,在 NumPy 中仍然可以对形状不相似的数组进行操作,因为它拥有广播功能。
较小的数组会广播到较大数组的大小,以便使它们的形状可兼容。
如果满足以下规则,可以进行广播:
- ndim较小的数组会在前面追加一个长度为 1 的维度。
- 输出数组的每个维度的大小是输入数组该维度大小的最大值。
- 如果输入在每个维度中的大小与输出大小匹配,或其值正好为 1,则在计算中可它。
- 如果输入的某个维度大小为 1,则该维度中的第一个数据元素将用于该维度的所有计算。
如果上述规则产生有效结果,并且满足以下条件之一,那么数组被称为可广播的。
- 数组拥有相同形状。
- 数组拥有相同的维数,每个维度拥有相同长度,或者长度为 1。
- 数组拥有极少的维度,可以在其前面追加长度为 1 的维度,使上述条件成立。
笔记:ndim中的dim是英文dimension维度的缩写。ndim是数组轴(维度)的个数。
下面的例称展示了广播的示例。
示例 2 广播 两个数组相加
import numpy as np
a = np.array([[0.0,0.0,0.0],[10.0,10.0,10.0],[20.0,20.0,20.0],[30.0,30.0,30.0]])
b = np.array([1.0,2.0,3.0])
print '第一个数组:'
print a
print '\n'
print '第二个数组:'
print b
print '\n'
print '第一个数组加第二个数组:'
print a + b
# 输出如下:
第一个数组:
[[ 0. 0. 0.]
[ 10. 10. 10.]
[ 20. 20. 20.]
[ 30. 30. 30.]]
第二个数组:
[ 1. 2. 3.]
第一个数组加第二个数组:
[[ 1. 2. 3.]
[ 11. 12. 13.]
[ 21. 22. 23.]
[ 31. 32. 33.]]
下面的图片展示了数组b如何通过广播来与数组a兼容。
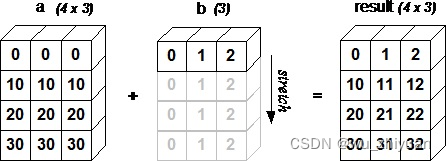
笔记:b数组维度小,并且可以追加一个长度为 1 的维度。
NumPy - 数组上的迭代
NumPy 包包含一个迭代器对象numpy.nditer。 它是一个有效的多维迭代器对象,可以用于在数组上进行迭代。 数组的每个元素可使用 Python 的标准Iterator接口来访问。
迭代器对象numpy.nditer
让我们使用arange()函数创建一个 3X4 数组,并使用nditer对它进行迭代。
示例 1 numpy.nditer(a)迭代器对象
import numpy as np
a = np.arange(0,60,5) # 0 至 59 步长5
a = a.reshape(3,4) # 也可以利用属性 a.shape(3,4)
print '原始数组是:'
print a print '\n'
print '修改后的数组是:'
for x in np.nditer(a): # x 为numpy.nditer迭代器对象
print x,
# 输出如下:
原始数组是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
修改后的数组是:
0 5 10 15 20 25 30 35 40 45 50 55
示例 2 迭代的顺序匹配数组的内容布局
迭代的顺序匹配数组的内容布局,而不考虑特定的排序(参照下例理解,转换后,迭代器输出不变)。 这可以通过迭代上述数组的转置来看到。
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始数组是:'
print a
print '\n'
print '原始数组的转置是:'
b = a.T # 矩阵的置换 可以理解为以00,nn连线为轴的镜像操作
print b
print '\n'
print '修改后的数组是:'
for x in np.nditer(b): # 笔记:转换后,迭代器输出不变。
print x,
输出如下:
原始数组是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
原始数组的转置是:
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
修改后的数组是:
0 5 10 15 20 25 30 35 40 45 50 55
笔记: b = a.T 其中a.T为 转置变换。元素[0,0]、元素[m,n]保持不变,其他元素行列颠倒。
迭代顺序
如果相同元素使用 F 风格顺序存储,则迭代器选择以更有效的方式对数组进行迭代。
笔记: 所谓风格,即order参数; C(按行)、F(按列)或A(任意,默认);order的风格 影响 迭代器的输出顺序
示例 1 order风格 影响 迭代器的顺序
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始数组是:'
print a
print '\n'
print '原始数组的转置是:'
b = a.T
print b
print '\n'
print '以 C 风格顺序排序:'
c = b.copy(order='C')
print c for x in np.nditer(c):
print x,
print '\n'
print '以 F 风格顺序排序:'
c = b.copy(order='F')
print c
for x in np.nditer(c): # order 分隔影响 迭代器的顺序
print x,
# 输出如下:
原始数组是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
原始数组的转置是:
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
以 C 风格顺序排序: # C风格:按行排序
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
0 20 40 5 25 45 10 30 50 15 35 55
以 F 风格顺序排序: # F风格:按列排序
[[ 0 20 40]
[ 5 25 45]
[10 30 50]
[15 35 55]]
0 5 10 15 20 25 30 35 40 45 50 55
示例 2 强制nditer对象使用某种顺序
可以通过显式提醒,来强制nditer对象使用某种顺序:
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始数组是:'
print a
print '\n'
print '以 C 风格顺序排序:'
for x in np.nditer(a, order = 'C'): # 强制规定迭代器风格 C-行
print x,
print '\n'
print '以 F 风格顺序排序:'
for x in np.nditer(a, order = 'F'):
print x,
# 输出如下:
原始数组是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
以 C 风格顺序排序:
0 5 10 15 20 25 30 35 40 45 50 55
以 F 风格顺序排序:
0 20 40 5 25 45 10 30 50 15 35 55
修改数组的值
nditer对象有另一个可选参数op_flags。 其默认值为只读,但可以设置为读写或只写模式。 这将允许使用此迭代器修改数组元素。
示例1 修改数组值
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始数组是:'
print a
print '\n'
for x in np.nditer(a, op_flags=['readwrite']): # 修改迭代器为 读写
x[...]=2*x # 笔记:x[...] 这个写法没有理解??
print '修改后的数组是:'
print a
# 输出如下:
原始数组是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
修改后的数组是:
[[ 0 10 20 30]
[ 40 50 60 70]
[ 80 90 100 110]]
小实验 证明a.T没有创建新的数组
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print ('原始数组是:' )
print (a)
print ('\n' )
b = a.T # 颠倒
for x in np.nditer(a, op_flags=['readwrite']): # 修改迭代器为 读写
x[...]=2*x
print ('修改后的数组是:' )
print (a)
print("b = ")
print(b)
#输出结果
原始数组是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
修改后的数组是:
[[ 0 10 20 30]
[ 40 50 60 70]
[ 80 90 100 110]]
b =
[[ 0 40 80]
[ 10 50 90]
[ 20 60 100]
[ 30 70 110]]
笔记:b = a.T 位于修改a数组值之前,但是输出b时,b的元素值也被改变了。这说明,b = a.T 并没有 创建新的数组,而是执行了a所开辟的内存,只是显示顺序改变了而已。
外部循环
nditer类的构造器拥有flags参数,它可以接受下列值:
- c_index 可以跟踪 C 顺序的索引 (行顺序)
- f_index 可以跟踪 Fortran 顺序的索引 (列顺序)
- multi-index 每次迭代可以跟踪一种索引类型
- external_loop 给出的值是具有多个值的一维数组,而不是零维数组
示例
在下面的示例中,迭代器遍历对应于每列的一维数组。
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '原始数组是:'
print a
print '\n'
print '修改后的数组是:'
for x in np.nditer(a, flags = ['external_loop'], order = 'F'):
print x,
# 输出如下:
原始数组是:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
修改后的数组是:
[ 0 20 40] [ 5 25 45] [10 30 50] [15 35 55] # 给出的值是具有**多个值的一维数组**,而不是零维数组
广播迭代
如果两个数组是可广播的(笔记:数组间的加减乘除运算),nditer组合对象能够同时迭代它们。 假设数组a具有维度 3X4,并且存在维度为 1X4 的另一个数组b,则使用以下类型的迭代器(数组b被广播到a的大小)。
示例
import numpy as np
a = np.arange(0,60,5)
a = a.reshape(3,4)
print '第一个数组:'
print a
print '\n'
print '第二个数组:'
b = np.array([1, 2, 3, 4], dtype = int)
print b
print '\n'
print '修改后的数组是:'
for x,y in np.nditer([a,b]): # 迭代器广播
print "%d:%d" % (x,y),
# 输出如下:
第一个数组:
[[ 0 5 10 15]
[20 25 30 35]
[40 45 50 55]]
第二个数组:
[1 2 3 4]
修改后的数组是:
0:1 5:2 10:3 15:4 20:1 25:2 30:3 35:4 40:1 45:2 50:3 55:4
NumPy - 数组操作
NumPy包中有几个例程用于处理ndarray对象中的元素。 它们可以分为以下类型:
修改形状
- reshape() 不改变数据的条件下修改形状
- flat 数组上的一维迭代器
- flatten 返回折叠为一维的数组副本
- ravel 返回连续的展开数组
numpy.reshape()
这个函数在不改变数据的条件下修改形状,它接受如下参数:
numpy.reshape(arr, newshape, order')
其中:
- arr:要修改形状的数组
- newshape:整数或者整数数组,新的形状应当兼容原有形状
- order:'C’为 C 风格顺序,'F’为 F 风格顺序,'A’为保留原顺序。
例子
import numpy as np
a = np.arange(8)
print '原始数组:'
print a
print '\n'
b = a.reshape(4,2) # 可以用 a.reshape(4,2) 也可以用numpy.reshape()函数的形式
print '修改后的数组:'
print b
# 输出如下:
原始数组:
[0 1 2 3 4 5 6 7]
修改后的数组:
[[0 1]
[2 3]
[4 5]
[6 7]]
numpy.ndarray.flat()
该函数返回数组上的一维迭代器,行为类似 Python 内建的迭代器。
笔记:不管数组的形状(例如:reshape(2,4)),只将数组作为一维进行迭代。注意,flat()方法属于ndarray类。flat 水平的
例子
import numpy as np
a = np.arange(8).reshape(2,4) # 也是一种写法
print '原始数组:'
print a
print '\n'
print '调用 flat 函数之后:'
# 返回展开数组中的下标的对应元素
print a.flat[5] # 不管数组的形状,只将数组作为一维进行迭代。
# 输出如下:
原始数组:
[[0 1 2 3]
[4 5 6 7]]
调用 flat 函数之后:
5
numpy.ndarray.flatten()
该函数返回折叠为一维的数组副本,函数接受下列参数:
ndarray.flatten(order)
其中:
order:‘C’ – 按行,‘F’ – 按列,‘A’ – 原顺序,‘k’ – 元素在内存中的出现顺序。
例子
import numpy as np
a = np.arange(8).reshape(2,4)
print('src list')
print (a)
print ('\n')
# default is column-major
print('展开的数组:')
b = a.flatten()
print(b)
print('\n')
print('again src list')
a[0] = 23
print (a)
print ('\n')
print('展开的数组:')
print(b)
# 输出如下:
src list
[[0 1 2 3]
[4 5 6 7]]
展开的数组:
[0 1 2 3 4 5 6 7]
again src list
[[23 23 23 23]
[ 4 5 6 7]]
展开的数组:
[0 1 2 3 4 5 6 7]
笔记:从上例可以看出,副本即一个全新内存块。
numpy.ravel()
这个函数返回展开的一维数组,并且按需生成副本(笔记:一个全新的内存块)。返回的数组和输入数组拥有相同数据类型。这个函数接受两个参数。
numpy.ravel(a, order)
构造器接受下列参数:
a: ndarray数组对象
order:‘C’ – 按行,‘F’ – 按列,‘A’ – 原顺序,‘k’ – 元素在内存中的出现顺序。
例子
import numpy as np
a = np.arange(8).reshape(2,4)
print '原数组:'
print a
print '\n'
print '调用 ravel 函数之后:'
print a.ravel()
print '\n'
print '以 F 风格顺序调用 ravel 函数之后:'
print a.ravel(order = 'F')
原数组:
[[0 1 2 3]
[4 5 6 7]]
调用 ravel 函数之后:
[0 1 2 3 4 5 6 7]
以 F 风格顺序调用 ravel 函数之后:
[0 4 1 5 2 6 3 7]
翻转操作
- transpose 翻转数组的维度
- ndarray.T 和 **self.transpose()**相同
- rollaxis 向后滚动指定的轴
- swapaxes 互换数组的两个轴
numpy.transpose()
这个函数翻转给定数组的维度。如果可能的话它会返回一个视图。函数接受下列参数:
笔记:行、列对调 形成的翻转
numpy.transpose(arr, axes)
其中:
- arr:要转置的数组
- axes:整数的列表,对应维度,通常所有维度都会翻转。
例子
import numpy as np
a = np.arange(12).reshape(3,4)
print '原数组:'
print a
print '\n'
print '转置数组:'
print np.transpose(a)
#输出如下:
原数组:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
转置数组:
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
numpy.ndarray.T 方法
该函数属于ndarray类,行为类似于numpy.transpose。
笔记:写的时候由于没有参数,因此T不需要加括号
例子
import numpy as np
a = np.arange(12).reshape(3,4)
print '原数组:'
print a
print '\n'
print '转置数组:'
print a.T # 写法简单,但是没有numpy.transpose灵活。
# 输出如下:
原数组:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
转置数组:
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
笔记:这种置换,可以理解为在原有一维数组的基础上,调整order属性。即:原ndarray对象.order=‘C’, 调用numpy.ndarray.T 方法 或者 numpy.transpose()后,ndarray对象.order=‘F’。反之亦然。
numpy.rollaxis()
该函数向后滚动特定的轴,直到一个特定位置。这个函数接受三个参数:
numpy.rollaxis(arr, axis, start)
其中:
- arr:输入数组
- axis:要向后滚动的轴,其它轴的相对位置不会改变
- start:默认为0,表示完整的滚动。会滚动到特定位置。
笔记:
轴的介绍
例如 a = np.arange(12).reshape(1,2,3)
1表示第一维长度1,第一维即:轴0
2表示第二维长度2,第二维即:轴1
3表示第三维长度3,第三维即:轴2
轴也有如下表示
轴0 深度方向
轴1 高度方向
轴2 宽度方向
轴的滚动
二维滚动
a=np.arrage(12).reshape(3,4)
a.shape = (3,4)
b=np.rollaxis(a,1) # 滚动轴
b.shape = (4,3)
例子
import numpy as np
a = np.arange(24).reshape(2,3,4)
print("a=", a)
print("a.shape = ", a.shape)
print("\n")
d = np.rollaxis(a,1)
print("np.rollaxis(a,1) = \n", d)
print("shap = ", d.shape)
print("\n")
b = np.rollaxis(a,2)
print("np.rollaxis(a,2) = \n", b)
print("shap = ", b.shape)
print("\n")
c = np.rollaxis(a,2,1)
print("np.rollaxis(a,2,1) = \n", c)
print("shap = ", c.shape)
# 输出如下:
a= [[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]
[16 17 18 19]
[20 21 22 23]]]
a.shape = (2, 3, 4)
np.rollaxis(a,1) =
[[[ 0 1 2 3]
[12 13 14 15]]
[[ 4 5 6 7]
[16 17 18 19]]
[[ 8 9 10 11]
[20 21 22 23]]]
shap = (3, 2, 4) # 轴1 和 轴0 滚动调换
np.rollaxis(a,2) =
[[[ 0 4 8]
[12 16 20]]
[[ 1 5 9]
[13 17 21]]
[[ 2 6 10]
[14 18 22]]
[[ 3 7 11]
[15 19 23]]]
shap = (4, 2, 3) # 轴2 和轴1 滚动对调
np.rollaxis(a,2,1) =
[[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
[[12 16 20]
[13 17 21]
[14 18 22]
[15 19 23]]]
shap = (2, 4, 3) # 轴2 和 轴1 滚动对调
numpy.swapaxes()
该函数交换数组的两个轴。对于 1.10 之前的 NumPy 版本,会返回交换后数组的试图。这个函数接受下列参数:
numpy.swapaxes(arr, axis1, axis2)
- arr:要交换其轴的输入数组
- axis1:对应第一个轴的整数
- axis2:对应第二个轴的整数
# 创建了三维的 ndarray
import numpy as np
a = np.arange(8).reshape(2,2,2)
print '原数组:'
print a
print '\n'
# 现在交换轴 0(深度方向)到轴 2(宽度方向)
print '调用 swapaxes 函数后的数组:'
print np.swapaxes(a, 2, 0)
# 输出如下:
原数组:
[[[0 1]
[2 3]]
[[4 5]
[6 7]]]
调用 swapaxes 函数后的数组:
[[[0 4]
[2 6]]
[[1 5]
[3 7]]]
修改维度
笔记:区分修改形状和修改维度。
修改形状是在相同维度下修改形状,例如:a.shape() = (2,3) 修改形状后 a.shape() = (1,6) 。
修改维度则是增加或减少维度。例如:2维 变 3
- **broadcast()**产生模仿广播的对象
- broadcast_to() 将数组广播到新形状
- expand_dims() 扩展数组的形状
- squeeze() 从数组的形状中删除单维条目
笔记:对广播的肤浅理解,广播为一个矩阵对另一个矩阵到操作(加减乘除);由于其中一个矩阵可能很小,只有一维(例如[1:4])。而另一个矩阵可能很大,有2维(例如:[10:4])。从中文字面理解,2个矩阵操作中,1 至 10的操作过程就像广播。
broadcast
如前所述,NumPy 已经内置了对广播的支持。 此功能模仿广播机制。 它返回一个对象,该对象封装了将一个数组广播到另一个数组的结果。
笔记:b = np.broadcast(x,y) x为维度形状模板,将y广播与x形状相同。返回值b 并不是一个ndarray对象,而是一个封装将一个数组广播到另一个数组的结果。比如: b = <numpy.broadcast object at 0x000002274B3F0AA0>
b内包含有x和广播y的结果, 例如:r,c = b.iters r迭代器表示x,c迭代器表示y
该函数使用两个数组作为输入参数。 下面的例子说明了它的用法。
import numpy as np
x = np.array([[1], [2], [3]]) # 二维数组
y = np.array([4, 5, 6]) # 一维数组
# 对 y 广播 x
b = np.broadcast(x,y)
# 它拥有 iterator 属性,基于自身组件的迭代器元组
print '对 y 广播 x:'
r,c = b.iters
print next(r), next(c)
print next(r), c.next(c)
print '\n'
# shape 属性返回广播对象的形状
print '广播对象的形状:'
print b.shape
print '\n'
# 手动使用 broadcast 将 x 与 y 相加
b = np.broadcast(x,y)
c = np.empty(b.shape)
print '手动使用 broadcast 将 x 与 y 相加:'
print c.shape
print '\n'
c.flat = [u + v for (u,v) in b] # flat 该函数返回数组上的**一维迭代器**,行为类似 Python 内建的迭代器。
print '调用 flat 函数:'
print c
print '\n'
# 获得了和 NumPy 内建的广播支持相同的结果
print 'x 与 y 的和:'
print x + y
# 输出如下:
对 y 广播 x:
1 4
1 5
广播对象的形状:
(3, 3)
手动使用 broadcast 将 x 与 y 相加:
(3, 3)
调用 flat 函数:
[[ 5. 6. 7.]
[ 6. 7. 8.]
[ 7. 8. 9.]]
x 与 y 的和:
[[5 6 7]
[6 7 8]
[7 8 9]]
numpy.broadcast_to
此函数将数组广播到新形状。 它在原始数组上返回只读视图。 它通常不连续。 如果新形状不符合 NumPy 的广播规则,该函数可能会抛出ValueError。
注意 - 此功能可用于 1.10.0 及以后的版本。
该函数接受以下参数。
numpy.broadcast_to(array, shape, subok)
例子
import numpy as np
a = np.arange(4).reshape(1,4)
print '原数组:'
print a
print '\n'
print '调用 broadcast_to 函数之后:'
print np.broadcast_to(a,(4,4))
# 输出如下:
[[0 1 2 3]
[0 1 2 3]
[0 1 2 3]
[0 1 2 3]]
numpy.expand_dims
函数通过在指定位置插入新的轴来扩展数组形状。该函数需要两个参数:
numpy.expand_dims(arr, axis) # axis 轴
其中:
- arr:输入数组
- axis:新轴插入的位置
例子
import numpy as np
x = np.array(([1,2],[3,4]))
print '数组 x:'
print x
print '\n'
y = np.expand_dims(x, axis = 0)
print '数组 y:'
print y
print '\n'
print '数组 x 和 y 的形状:'
print x.shape, y.shape
print '\n'
# 在位置 1 插入轴
y = np.expand_dims(x, axis = 1)
print '在位置 1 插入轴之后的数组 y:'
print y
print '\n'
print 'x.ndim 和 y.ndim:'
print x.ndim,y.ndim
print '\n'
print 'x.shape 和 y.shape:'
print x.shape, y.shape
输出如下:
数组 x:
[[1 2]
[3 4]]
数组 y:
[[[1 2]
[3 4]]]
数组 x 和 y 的形状:
(2, 2) (1, 2, 2)
在位置 1 插入轴之后的数组 y:
[[[1 2]]
[[3 4]]]
x.ndim 和 y.ndim:
2 3
x.shape and y.shape:
(2, 2) (2, 1, 2)
numpy.squeeze
函数从给定数组的形状中删除一维条目。 此函数需要两个参数。
numpy.squeeze(arr, axis)
其中:
- arr:输入数组
- axis:整数或整数元组,用于选择形状中单一维度条目的子集
例子
import numpy as np
x = np.arange(9).reshape(1,3,3)
print '数组 x:'
print x
print '\n'
y = np.squeeze(x)
print '数组 y:'
print y
print '\n'
print '数组 x 和 y 的形状:'
print x.shape, y.shape
输出如下:
数组 x:
[[[0 1 2]
[3 4 5]
[6 7 8]]]
数组 y:
[[0 1 2]
[3 4 5]
[6 7 8]]
数组 x 和 y 的形状:
(1, 3, 3) (3, 3)
数组的连接
- concatenate 沿着现存的轴连接数据序列
- stack 沿着新轴连接数组序列
- hstack 水平堆叠序列中的数组(列方向)
- vstack 竖直堆叠序列中的数组(行方向)
numpy.concatenate
此函数用于沿指定轴连接相同形状的两个或多个数组。 该函数接受以下参数。
笔记:连接的前提形状相同。
numpy.concatenate((a1, a2, ...), axis)
其中:
- a1, a2, …:相同类型的数组序列
- axis:沿着它连接数组的轴,默认为 0
例子
import numpy as np
a = np.array([[1,2],[3,4]]) # 一行两列
print '第一个数组:'
print a
print '\n'
b = np.array([[5,6],[7,8]]) # 一行两列
print '第二个数组:'
print b
print '\n'
# 两个数组的维度相同
print '沿轴 0 连接两个数组:'
print np.concatenate((a,b)) # 轴0 一行
print '\n'
print '沿轴 1 连接两个数组:'
print np.concatenate((a,b),axis = 1) # 轴1 列
输出如下:
第一个数组:
[[1 2]
[3 4]]
第二个数组:
[[5 6]
[7 8]]
沿轴 0 连接两个数组:
[[1 2]
[3 4]
[5 6]
[7 8]]
沿轴 1 连接两个数组:
[[1 2 5 6]
[3 4 7 8]]
numpy.stack
此函数沿新轴连接数组序列。 此功能添加自 NumPy 版本 1.10.0。 需要提供以下参数。
numpy.stack(arrays, axis)
其中:
- arrays:相同形状的数组序列
- axis:返回数组中的轴,输入数组沿着它来堆叠
import numpy as np
a = np.array([[1,2],[3,4]])
print '第一个数组:'
print a
print '\n'
b = np.array([[5,6],[7,8]])
print '第二个数组:'
print b
print '\n'
print '沿轴 0 堆叠两个数组:'
print np.stack((a,b),0)
print '\n'
print '沿轴 1 堆叠两个数组:'
print np.stack((a,b),1)
# 输出如下:
第一个数组:
[[1 2]
[3 4]]
第二个数组:
[[5 6]
[7 8]]
沿轴 0 堆叠两个数组:
[[[1 2]
[3 4]]
[[5 6]
[7 8]]]
沿轴 1 堆叠两个数组:
[[[1 2]
[5 6]]
[[3 4]
[7 8]]]
numpy.hstack
numpy.stack函数的变体,通过堆叠来生成水平的单个数组。
例子
import numpy as np
a = np.array([[1,2],[3,4]])
print '第一个数组:'
print a
print '\n'
b = np.array([[5,6],[7,8]])
print '第二个数组:'
print b
print '\n'
print '水平堆叠:'
c = np.hstack((a,b))
print c
print '\n'
输出如下:
第一个数组:
[[1 2]
[3 4]]
第二个数组:
[[5 6]
[7 8]]
水平堆叠:
[[1 2 5 6]
[3 4 7 8]]
numpy.vstack
numpy.stack函数的变体,通过堆叠来生成竖直的单个数组。
import numpy as np
a = np.array([[1,2],[3,4]])
print '第一个数组:'
print a
print '\n'
b = np.array([[5,6],[7,8]])
print '第二个数组:'
print b
print '\n'
print '竖直堆叠:'
c = np.vstack((a,b))
print c
输出如下:
第一个数组:
[[1 2]
[3 4]]
第二个数组:
[[5 6]
[7 8]]
竖直堆叠:
[[1 2]
[3 4]
[5 6]
[7 8]]
数组分割
- split 将一个数组分割为多个子数组
- hsplit 将一个数组水平分割为多个子数组(按列)
- vsplit 将一个数组竖直分割为多个子数组(按行)
numpy.split
该函数沿特定的轴将数组分割为子数组。函数接受三个参数:
numpy.split(ary, indices_or_sections, axis)
其中:
- ary:被分割的输入数组
- indices_or_sections:可以是整数,表明要从输入数组创建的,等大小的子数组的数量。 如果此参数是一维数组,则其元素表明要创建新子数组的点。
- axis:默认为 0
例子
import numpy as np
a = np.arange(9)
print ("a = \n", a)
b = np.split(a,3)
print ('np.split(a,3) = \n',b)
b = np.split(a,[4,7])
print("np.split(a,[4,7]) = \n", b)
# 输出如下:
a =
[0 1 2 3 4 5 6 7 8]
np.split(a,3) =
[array([0, 1, 2]), array([3, 4, 5]), array([6, 7, 8])]
np.split(a,[4,7]) =
[array([0, 1, 2, 3]), array([4, 5, 6]), array([7, 8])]
numpy.hsplit
numpy.hsplit是split()函数的特例,其中轴为 1 表示水平分割,无论输入数组的维度是什么。
import numpy as np
a = np.arange(16).reshape(4,4)
print '第一个数组:'
print a
print '\n'
print '水平分割:'
b = np.hsplit(a,2)
print b
print '\n'
#输出:
第一个数组:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
水平分割:
[array([[ 0, 1],
[ 4, 5],
[ 8, 9],
[12, 13]]),
array([[ 2, 3],
[ 6, 7],
[10, 11],
[14, 15]])]
numpy.vsplit
numpy.vsplit是split()函数的特例,其中轴为 0 表示竖直分割,无论输入数组的维度是什么。下面的例子使之更清楚。
import numpy as np
a = np.arange(16).reshape(4,4)
print '第一个数组:'
print a
print '\n'
print '竖直分割:'
b = np.vsplit(a,2)
print b
输出如下:
第一个数组:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]
[12 13 14 15]]
竖直分割:
[array([[0, 1, 2, 3],
[4, 5, 6, 7]]), array([[ 8, 9, 10, 11],
[12, 13, 14, 15]])]
添加/删除元素
- resize 返回指定形状的新数组
- append 将值添加到数组末尾
- insert 沿指定轴将值插入到指定下标之前
- delete 返回删掉某个轴的子数组的新数组
- unique 寻找数组内的唯一元素
numpy.resize
此函数返回指定大小的新数组。 如果新大小大于原始大小,则包含原始数组中的元素的重复副本。 该函数接受以下参数。
笔记:np.resize() 与 ndarray.shape() 效果相同
numpy.resize(arr, shape)
其中:
- arr:要修改大小的输入数组
- shape:返回数组的新形状
例子
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
print '第一个数组:'
print a
print '\n'
print '第一个数组的形状:'
print a.shape
print '\n'
b = np.resize(a, (3,2))
print '第二个数组:'
print b
print '\n'
print '第二个数组的形状:'
print b.shape
print '\n'
# 要注意 a 的第一行在 b 中重复出现,因为尺寸变大了
print '修改第二个数组的大小:'
b = np.resize(a,(3,3))
print b
输出如下:
第一个数组:
[[1 2 3]
[4 5 6]]
第一个数组的形状:
(2, 3)
第二个数组:
[[1 2]
[3 4]
[5 6]]
第二个数组的形状:
(3, 2)
修改第二个数组的大小:
[[1 2 3]
[4 5 6]
[1 2 3]]
numpy.append
此函数在输入数组的末尾添加值。 附加操作不是原地的,而是分配新的数组。 此外,输入数组的维度必须匹配否则将生成ValueError。
笔记:np.append() 返回 新的数组(分配新的内存)
函数接受下列函数:
numpy.append(arr, values, axis)
其中:
- arr:输入数组
- values:要向arr添加的值,比如和arr形状相同(除了要添加的轴)
- axis:沿着它完成操作的轴。如果没有提供,两个参数都会被展开。
例子
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
print '第一个数组:'
print a
print '\n'
print '向数组添加元素:'
print np.append(a, [7,8,9])
print '\n'
print '沿轴 0 添加元素:'
print np.append(a, [[7,8,9]],axis = 0)
print '\n'
print '沿轴 1 添加元素:'
print np.append(a, [[5,5,5],[7,8,9]],axis = 1)
#输出如下:
第一个数组:
[[1 2 3]
[4 5 6]]
向数组添加元素:
[1 2 3 4 5 6 7 8 9]
沿轴 0 添加元素:
[[1 2 3]
[4 5 6]
[7 8 9]]
沿轴 1 添加元素:
[[1 2 3 5 5 5]
[4 5 6 7 8 9]]
numpy.insert
此函数在给定索引之前,沿给定轴在输入数组中插入值。 如果值的类型转换为要插入,则它与输入数组不同。 插入没有原地的,函数会返回一个新数组。 此外,如果未提供轴,则输入数组会被展开。
insert()函数接受以下参数:
numpy.insert(arr, obj, values, axis)
其中:
- arr:输入数组
- obj:在其之前插入值的索引
- values:要插入的值
- axis:沿着它插入的轴,如果未提供,则输入数组会被展开
例子
import numpy as np
a = np.array([[1,2],[3,4],[5,6]])
print ('第一个数组:' )
print (a )
print ('未传递 Axis 参数。 在插入之前输入数组会被展开。' )
print (np.insert(a,3,[11,12]) )
print ('\n' )
print ('传递了 Axis 参数。 会广播值数组来配输入数组。' )
print ('沿轴 0 广播:')
print (np.insert(a,1,[11],axis = 0) )
print ('\n' )
print ('沿轴 1 广播:' )
print (np.insert(a,1,11,axis = 1))
# 输出结果
第一个数组:
[[1 2]
[3 4]
[5 6]]
未传递 Axis 参数。 在插入之前输入数组会被展开。
[ 1 2 3 11 12 4 5 6]
传递了 Axis 参数。 会广播值数组来配输入数组。
沿轴 0 广播:
[[ 1 2]
[11 11]
[ 3 4]
[ 5 6]]
沿轴 1 广播:
[[ 1 11 2]
[ 3 11 4]
[ 5 11 6]]
numpy.delete
此函数返回从输入数组中删除指定子数组的新数组。 与insert()函数的情况一样,如果未提供轴参数,则输入数组将展开。 该函数接受以下参数:
Numpy.delete(arr, obj, axis)
其中:
- arr:输入数组
- obj:可以被切片,整数或者整数数组,表明要从输入数组删除的子数组
- axis:沿着它删除给定子数组的轴,如果未提供,则输入数组会被展开
例子
import numpy as np
a = np.arange(12).reshape(3,4)
print '第一个数组:'
print a
print '\n'
print '未传递 Axis 参数。 在插入之前输入数组会被展开。'
print np.delete(a,5)
print '\n'
print '删除第二列:'
print np.delete(a,1,axis = 1)
print '\n'
print '包含从数组中删除的替代值的切片:'
a = np.array([1,2,3,4,5,6,7,8,9,10])
print np.delete(a, np.s_[::2]) # [::2] 表示 [start:end:step]
#输出如下:
第一个数组:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
未传递 Axis 参数。 在插入之前输入数组会被展开。
[ 0 1 2 3 4 6 7 8 9 10 11]
删除第二列:
[[ 0 2 3]
[ 4 6 7]
[ 8 10 11]]
包含从数组中删除的替代值的切片:
[ 2 4 6 8 10]
numpy.unique
此函数返回输入数组中的去重元素数组。 该函数能够返回一个元组,包含去重数组和相关索引的数组。 索引的性质取决于函数调用中返回参数的类型。
笔记:去掉重复元素,并且返回去重数组会排序
numpy.unique(arr, return_index, return_inverse, return_counts)
其中:
- arr:输入数组,如果不是一维数组则会展开
- return_index:如果为true,返回输入数组中的元素下标
- return_inverse:如果为true,返回去重数组的下标,它可以用于重构输入数组
- return_counts:如果为true,返回去重数组中的元素在原数组中的出现次数
例子
import numpy as np
a = np.array([5,2,6,2,7,5,6,8,2,9])
print '第一个数组:'
print a
print '\n'
print '第一个数组的去重值:'
u = np.unique(a) # 会排序
print u
print '\n'
print '去重数组的索引数组:'
u,indices = np.unique(a, return_index = True)
print indices
print '\n'
print '我们可以看到每个和原数组下标对应的数值:'
print a
print '\n'
print '去重数组的下标:'
u,indices = np.unique(a,return_inverse = True)
print u
print '\n'
print '下标为:'
print indices
print '\n'
print '使用下标重构原数组:'
print u[indices]
print '\n'
print '返回去重元素的重复数量:'
u,indices = np.unique(a,return_counts = True)
print u
print indices
输出如下:
第一个数组:
[5 2 6 2 7 5 6 8 2 9]
第一个数组的去重值:
[2 5 6 7 8 9]
去重数组的索引数组:
[1 0 2 4 7 9]
我们可以看到每个和原数组下标对应的数值:
[5 2 6 2 7 5 6 8 2 9]
去重数组的下标:
[2 5 6 7 8 9]
下标为:
[1 0 2 0 3 1 2 4 0 5]
使用下标重构原数组:
[5 2 6 2 7 5 6 8 2 9]
返回唯一元素的重复数量:
[2 5 6 7 8 9]
[3 2 2 1 1 1]