最全面的HashMap源码解析(JDK1.8)
前置知识:红黑树
要说红黑树,首先要提到二叉查找树(BST),它利用了二分查找的思想,来使正常情况下查找的时间复杂度为O(logn),例子如下图:
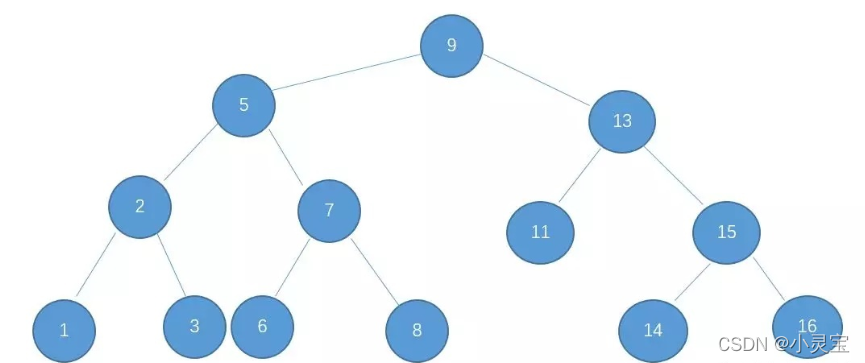
满足下列三个条件的树,即是二叉查找树:
- 左子树的值小于等于根的值
- 右子树的值大于等于根的值
- 左右子树也都是二叉查找树
满足了上述3个性质,BST的查找和插入都可以用二分查找思想来做,在BST中进行查找所需的最大次数=BST的高度,插入也是同理,通过不断比较大小来找到插入位置
但BST有一个弊端,那就是在极端条件下,BST会退化成链,如下图所示:
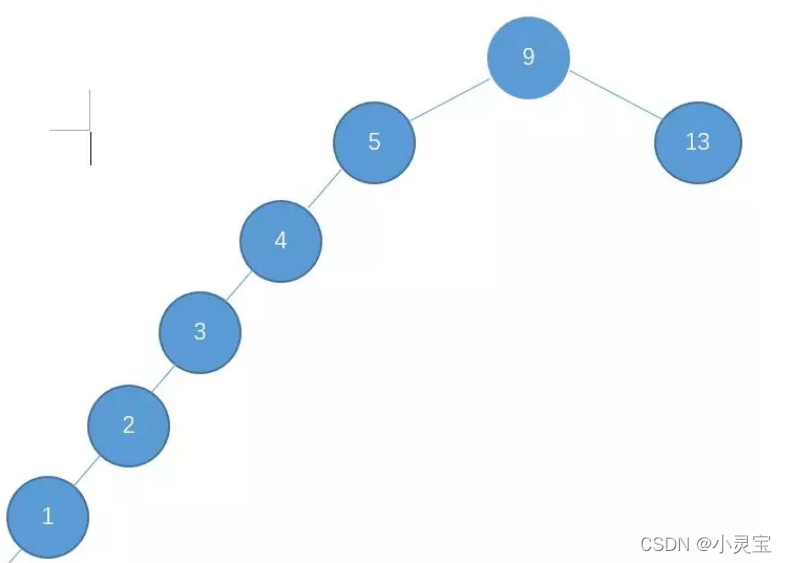
退化成链后,查找和插入的时间复杂度将退化到O(n),即退化为线性查找。也就是说BST具有不平衡性,为了弥补它的这个缺点,人们提出了平衡二叉树(AVL)。
平衡二叉树(AVL)具有BST的所有特性,它还有其独有的特性,那就是:左右子树的高度差最多为1。有了该特性,平衡二叉树将保保持它的平衡性,弥补了BST的不足,例子如下图所示:
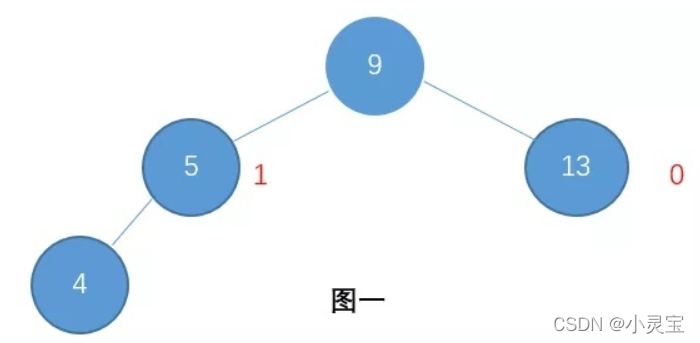
AVL树由于其平衡性,查找和插入的最坏时间复杂度变为了O(logn)
那么既然有了AVL,为什么还要提出红黑树呢?AVL虽好,但其对于平衡的定义:左右子树高度差最多为1这个条件过于严格,导致我们几乎每次进行插入或删除结点时,都会破坏平衡二叉树的结构,以至于要进行左旋或右旋处理,再将其变为平衡的。如果在那种插入、删除很频繁的场景中,平衡树需要频繁地进行调整,这会使平衡树的性能大打折扣。还有一个次要原因是,AVL的实现代码比较复杂,理论上的数据结构模型应用于实际还需要稍许修改折中。
基于上述两个原因,人们提出了一种不太严格的平衡树,也可以称之为一个折中方案,那就是红黑树。红黑树查找的最坏时间复杂度也为O(logn),但它在插入、删除等操作中,不会像AVL那样,频繁地破坏红黑树的规则,所以不需要频繁地调整,这也是我们为什么大多数情况下使用红黑树的原因。红黑树的例子如下(叶子NIL节点未画出):
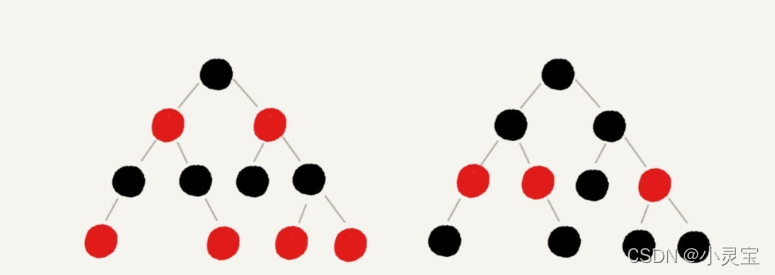
红黑树是一种自平衡的二叉查找树,它除了拥有BST的基本特性外,还拥有以下5个特性:
- 结点带颜色属性(红或黑)
- 根节点为黑色
- 每个叶节点都是黑色的空节点(NIL结点)
- 每个红色结点的两个子节点都是黑色(从每个叶子到根的所有路径上不能有两个连续的红色结点)
- 从任一结点到其每个叶子的所有路径都包含相同数目的黑色节点
根据上述5个特性,可以推出红黑树从根到叶子的最长路径不会超过最短路径的2倍。在插入或删除结点时,可能会破坏红黑树的规则,需要进行调整,调整的方法包括两个:变色和旋转,旋转又分为左旋和右旋
红黑树插入结点时,有5种局面,每种局面对应特定的调整方法,虽然比较复杂,但调整的套路是固定不变的,这里就不介绍了
HashMap的整体结构
HashMap的整体结构是一个数组,数组中的元素称为哈希桶,哈希桶可以为链表,也可以为红黑树,如下图所示:
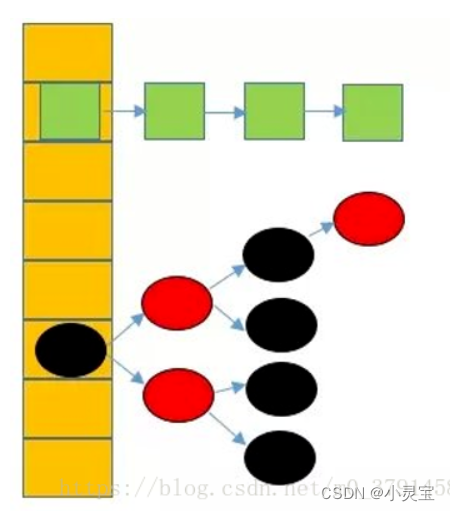
哈希桶中的每个元素都存储了key,value值,以及key对应的hash值等信息
在jdk 1.8之前HashMap都是数组+链表的结构,因为在链表的查询操作都是O(N)的时间复杂度,而且hashMap中查询操作也是占了很大比例的,如果当节点数量多,转换为红黑树结构,那么将会提高很大的效率,因为红黑树结构中,增删改查都是O(log n)。所以JDK1.8作出了这样的调整。
HashMap的属性
默认容量DEFAULT_INITIAL_CAPACITY

DEFAULT_INITIAL_CAPACITY即为HashMap的默认容量,即数组默认大小,为16
为什么取16,是因为16是经不断统计实验所得到的最优解
默认加载因子DEFAULT_LOAD_FACTOR

DEFAULT_LOAD_FACTOR是HashMap的默认加载因子,为0.75,加载因子会在扩容时被用到。
何为加载因子?HashMap作为哈希表型数据结构的实现,一定要预留出一部分空间供新元素散列进来,当空间快要满时,就要进行扩容了,而不是等到真正满了再去扩容,因为等到真正放满了,那么之前肯定发生了很多Hash冲突,加载因子为0.75的意思就是,HashMap最多放75%乘以容量Capacity的键值对,若数据量超过了75%乘以容量,则需进行扩容。
加载因子为什么取0.75,和默认初始容量16一样,因为0.75是经不断统计实验所得到的最优解
TREEIFY_THRESHOLD
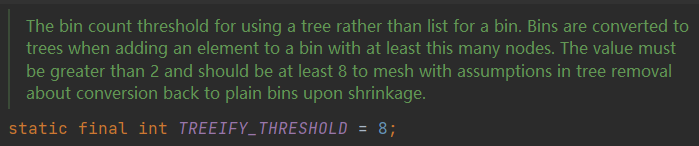
TREEIFY_THRESHOLD是哈希桶转化为红黑树的阈值,当某个哈希桶中结点数大于8时,且数组长度大于MIN_TREEIFY_CAPACITY = 64,该哈希桶将会转换为红黑树结构
UNTREEIFY_THRESHOLD

UNTREEIFY_THRESHOLD是红黑树转化为链表的阈值。当某个哈希桶中结点数小于6时,该哈希桶会转换为链表,前提是它当前是红黑树结构
MIN_TREEIFY_CAPACITY

链表长度大于TREEIFY_THRESHOLD = 8且数组长度大于MIN_TREEIFY_CAPACITY = 64时,链表转化为红黑树
链表长度大于TREEIFY_THRESHOLD = 8(且数组长度不大于MIN_TREEIFY_CAPACITY = 64),数组进行扩容,链表不转为红黑树,还是链表
也就是说,设置了MIN_TREEIFY_CAPACITY这个属性后,链表长度并不是大于8就变为红黑树,而是还要满足数组长度大于64这个条件时,链表才转为红黑树。这样做的目的是尽可能避免冲突,这是经过长期经验和数学推算总结出来的,数组长度小于一定数目的话,数组扩容会比哈希桶树化效果要好。
以通俗的话来说,数组长度小于等于64,表示数组还没放很多哈希桶,这时候某个桶中元素大于8,那么我扩容数组,将减少哈希冲突,桶中元素不会增加地很快,单纯把链表变为红黑树并不能减少冲突发生的可能性。数组长度大于64时,这时数组已经放了够多的哈希桶了,再对数组进行扩容会影响HashMap的操作效率,此时将链表变为红黑树,来提高查找等操作的效率。
Node< K,V >[] table

table表示存储哈希桶的数组,数组元素类型为Node<K,V>,即哈希桶。table中的元素称之为哈希桶,哈希桶可以是链表结构,也可以是红黑树结构
Set< Map.Entry< K,V > > entrySet

将数据转换为Set的另一种存储形式,主要用于迭代
我们不妨来看看Set的泛型Map.Entry<K,V>是什么:
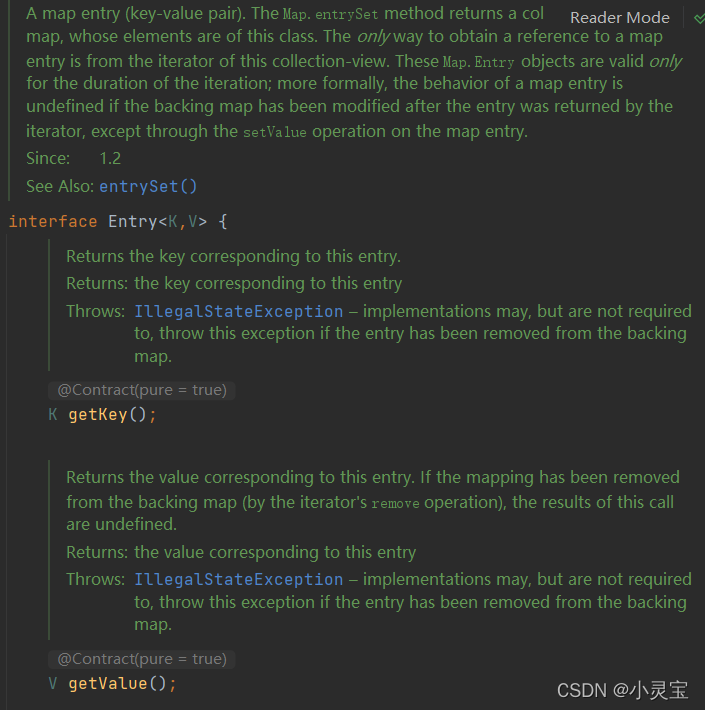
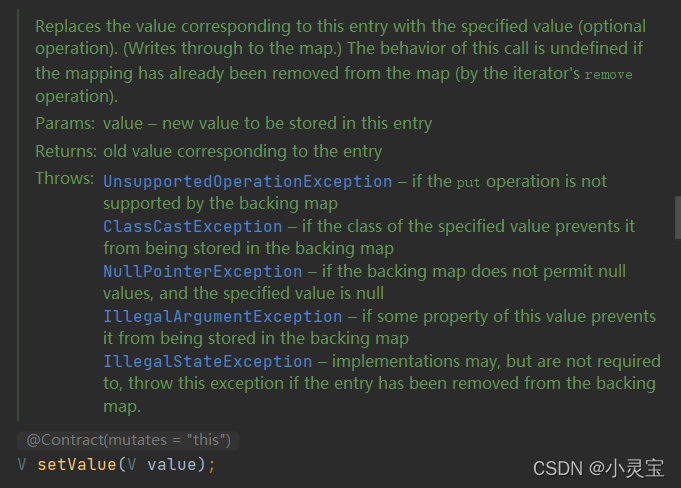
Map.Entry<K,V>是Map中定义的接口,其实就是表示键值对,其中定义了对key,value的get,set方法,以及key和value的比较方法等
调用Map.entrySet(),可以将Map转为Set形式,Set中的元素类型就是Entry,即键值对形式
size

size表示HashMap中键值对的数量,当size>threshold时会执行resize扩容操作
modCount

modCount表示HashMap被结构性修改的次数,主要用于在迭代器迭代时,若又对HashMap进行了修改,会抛出ConcurrentModificationException,并发修改异常
threshold

threshold为临界值,当HashMap存储的key-value键值对数量大于threshold临界值时,数组会进行扩容
loadFactor
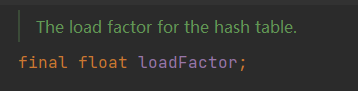
loadFactor表示加载因子,作为变量使用
HashMap的内部类
HashMap的内部类有红黑树结点TreeNode<K,V>以及链表节点Node<K,V>
红黑树结点TreeNode< K,V >
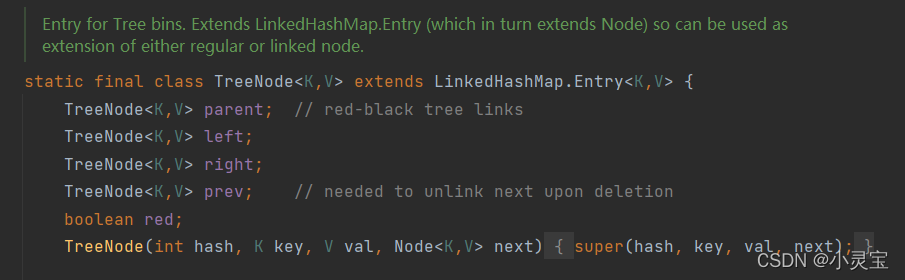
红黑树结点TreeNode<K,V>继承了LinkedHashMap.Entry<K,V>,相当于继承了Node<K,V>,因为LinkedHashMap.Entry<K,V>继承了HashMap.Node<K,V>。
TreeNode<K,V>内部类中包含了在红黑树中插入、查找元素,将红黑树转化为链表等方法
链表节点Node< K,V >
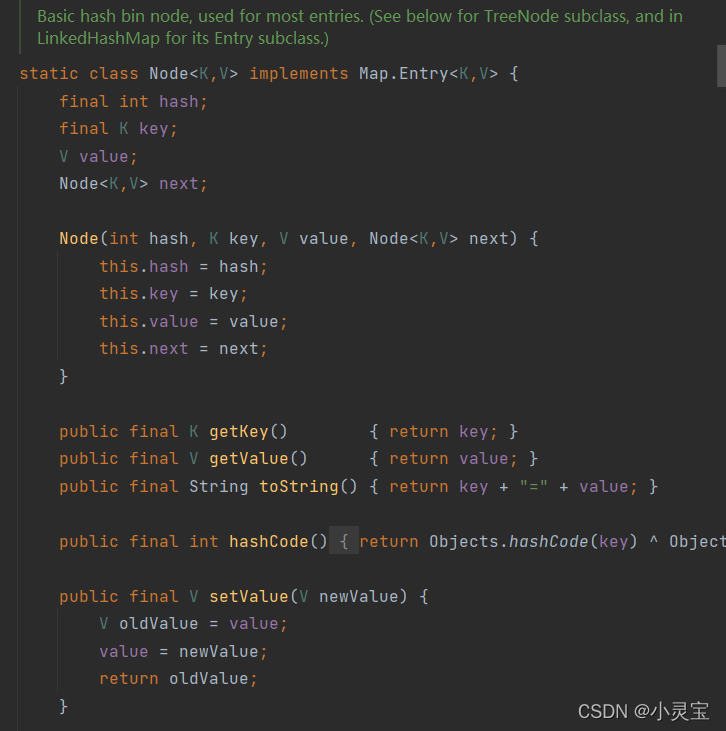
链表节点Node<K,V>实现了Map.Entry<K,V>接口,其属性有key,value,key对应的hash值,以及下一个Node结点,方法包括key,value对应的get、set方法等
HashMap的方法
构造方法
空参构造HashMap()
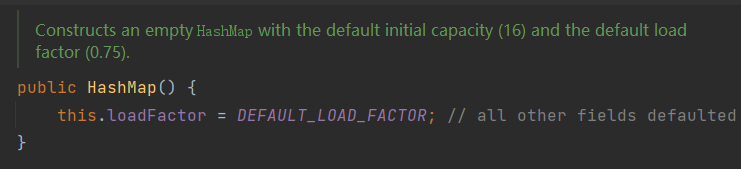
使用空参构造,将得到一个空的HashMap,其容量(即数组大小)为默认的16,装填因子为0.75
HashMap(int initialCapacity)

使用这种构造函数,将设置初始容量为参数的值,装填因子为默认的0.75
HashMap(int initialCapacity, float loadFactor)
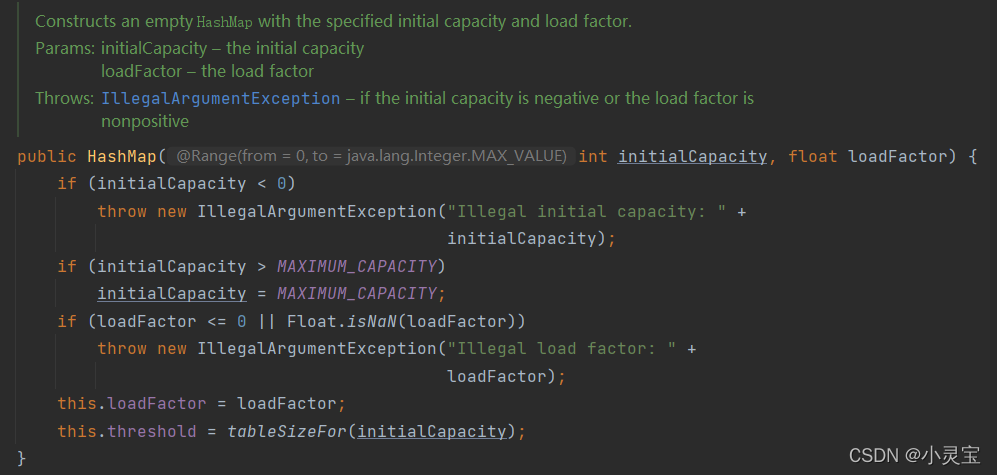
使用该构造函数,将设置对应的初始容量和装填因子
该方法会验证参数的正确性,将属性loadFactor赋为对应参数,并设置属性threshold(数组扩容临界值)为tableSizeFor(initialCapacity)
tableSizeFor方法用于计算>=参数的最小2的整数次方,因为HashMap的大小总是2的整数幂
为什么HashMap的大小要设置为2的整数幂?主要是为了方便进行位运算,具体可以看如下链接:
HashMap的长度为什么要是2的n次方
HashMap(Map< ? extends K,? extends V > m)

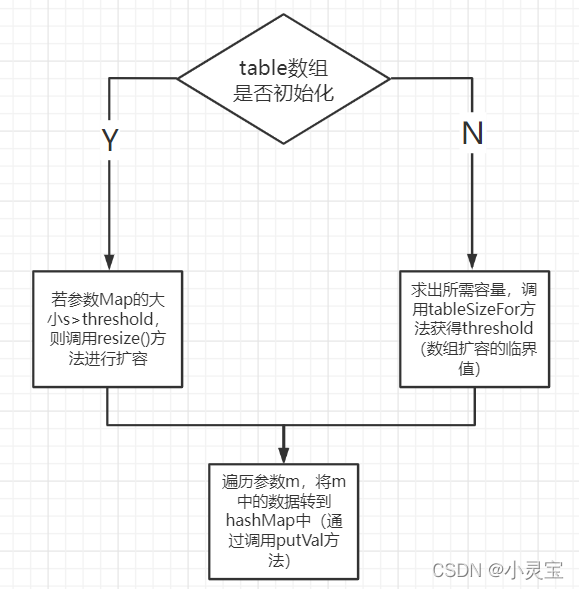
该构造函数传入一个Map,然后再将该Map转换为HashMap。转换的HashMap的装填因子为0.75。该方法调用了putMapEntries(m, false)方法,putMapEntries方法其实就是把Map中的数据放入HashMap中:
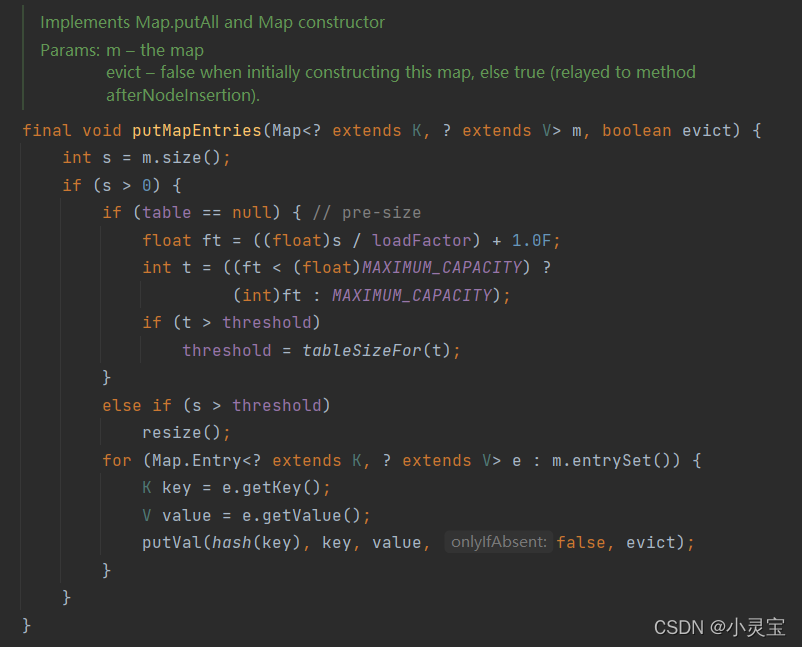
其中,Map.entrySet()方法返回一个Set<Map.Entry<K,V>>,这个Set的泛型为Map的内部类Entry,Entry是一个存放key-value的实例
putMapEntries方法的执行流程如下图所示:
扩容方法resize()
当数组中的key-value键值对个数大于临界值threshold时,将调用resize()方法进行数组扩容,我们来看看该方法是如何实现的:
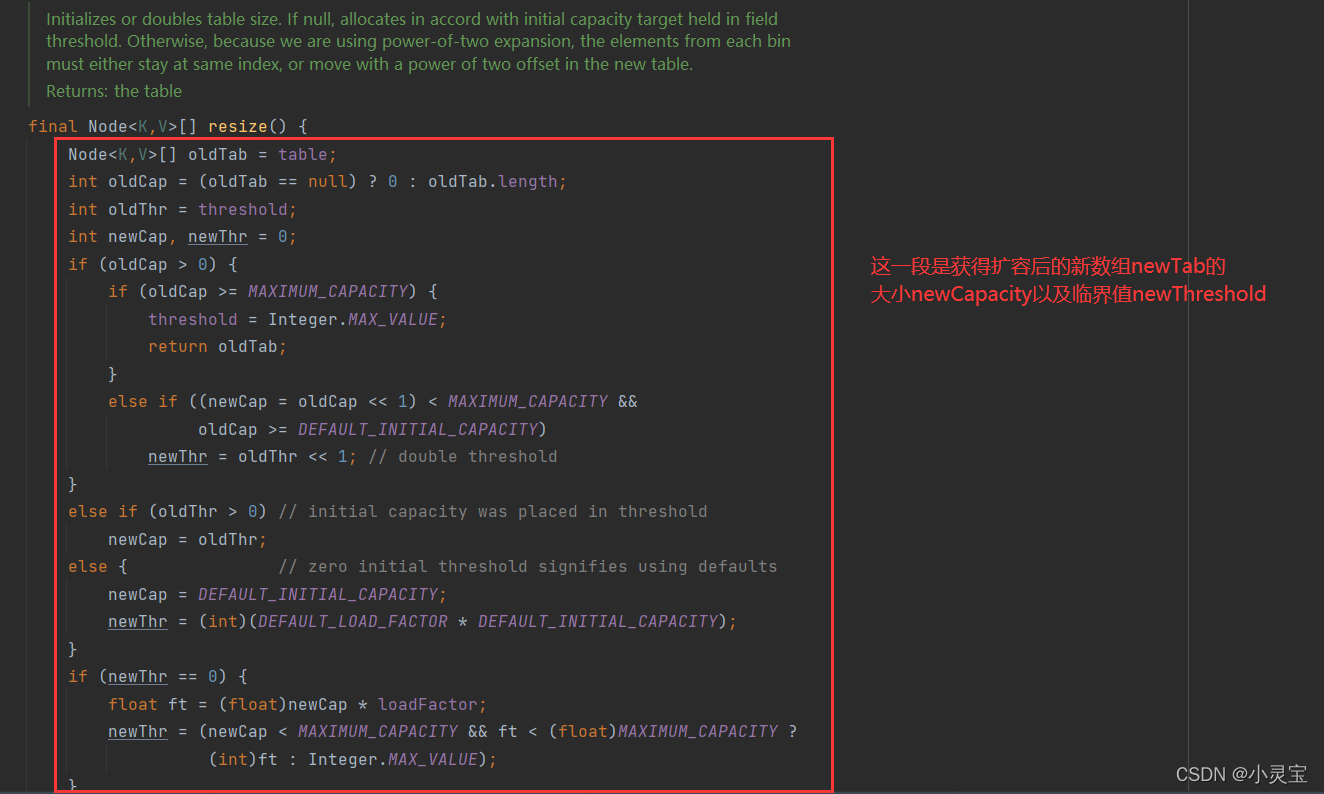
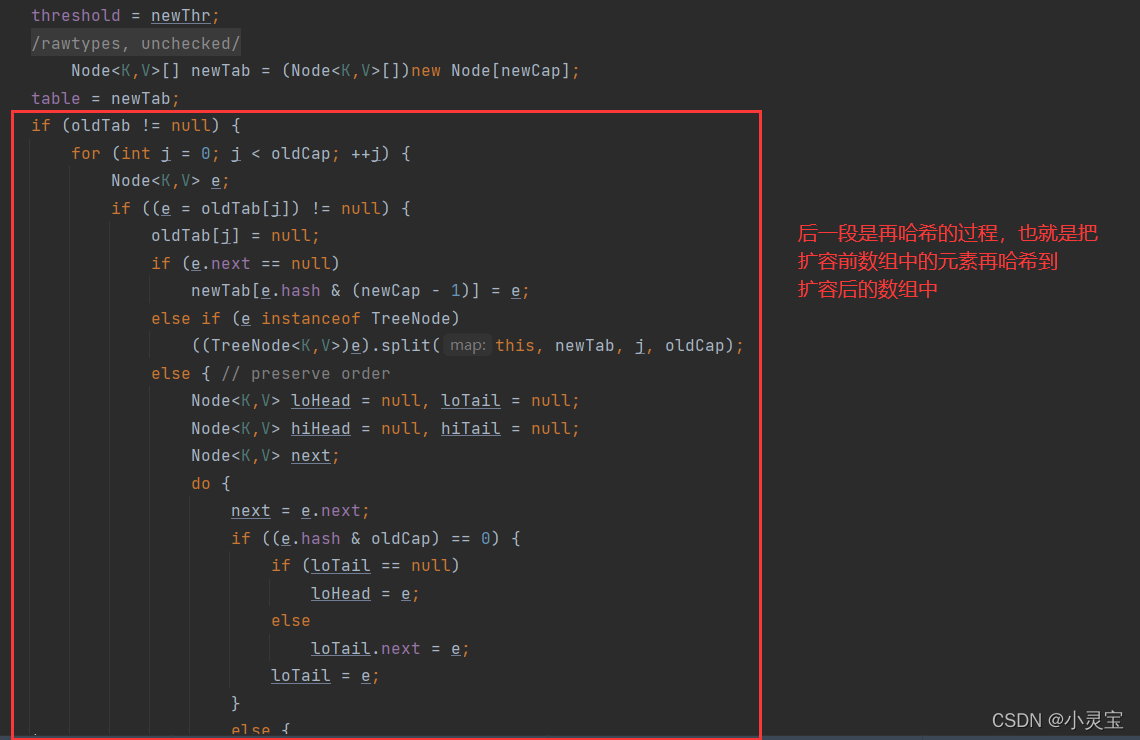
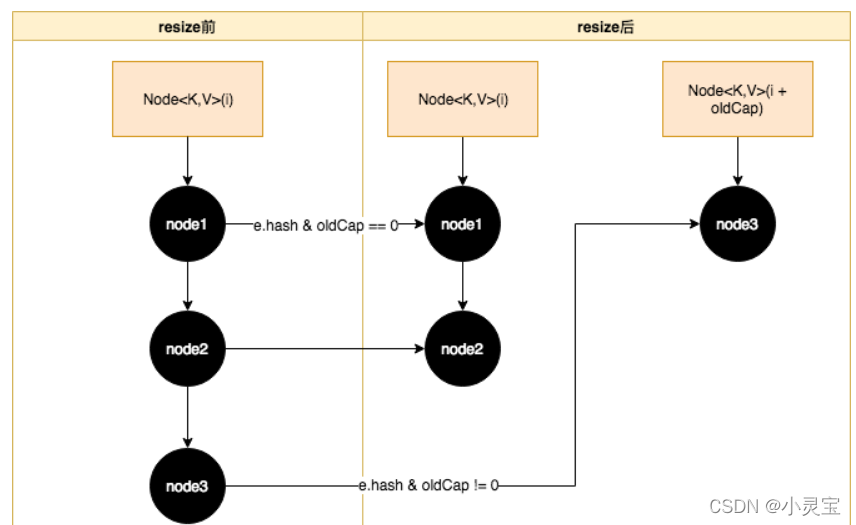
该方法做了两件事,一是获取扩容后的数组newTab的大小以及临界值,二是将扩容前原有元素再哈希到新数组中。该方法具体的流程如下图所示:
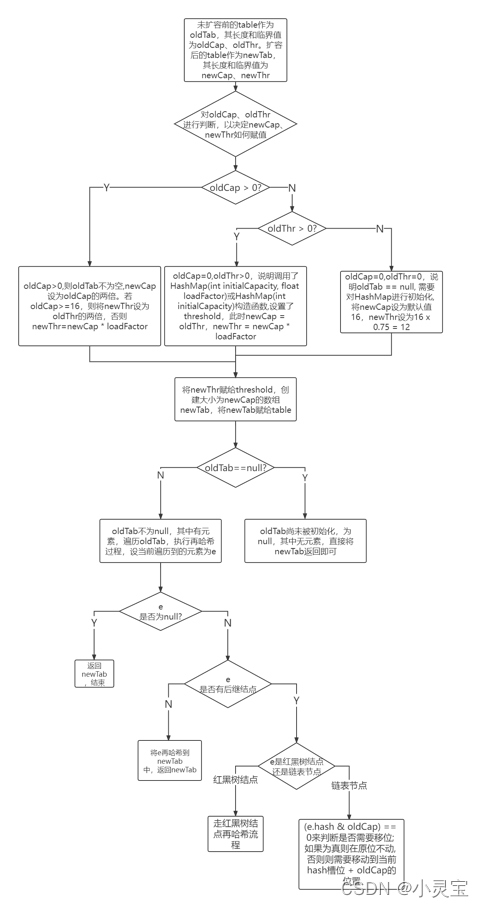
链表哈希桶的再哈希过程如下图所示:
增删改查方法
添加:put方法
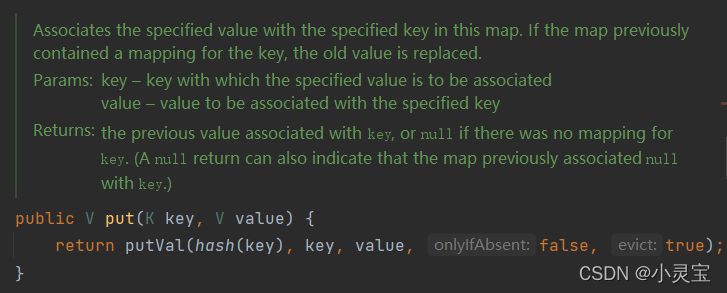
put方法实际上是调用了putVal方法,除开key,value外,还将key的hash值作为了参数,通过调用hash(key)方法来获得key对应的hash值,我们来看看hash方法是如何计算hash值的:
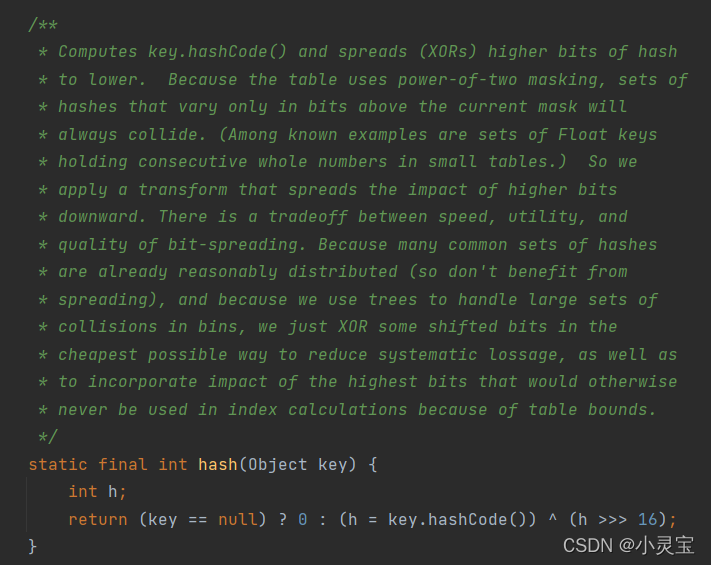
若key为null,其hash值为0,否则为key的hashCode与hashCode向右无符号右移16位的异或
put方法实际上是通过调用putVal方法向HashMap中加入元素,我们来看看putVal方法:
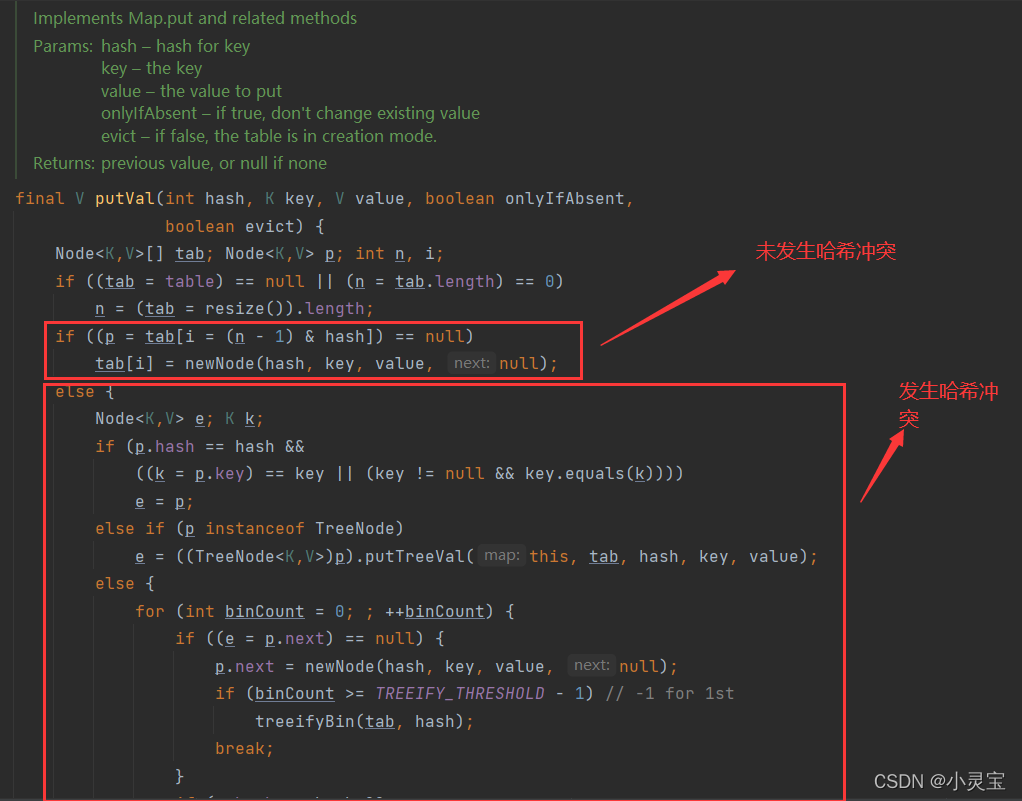
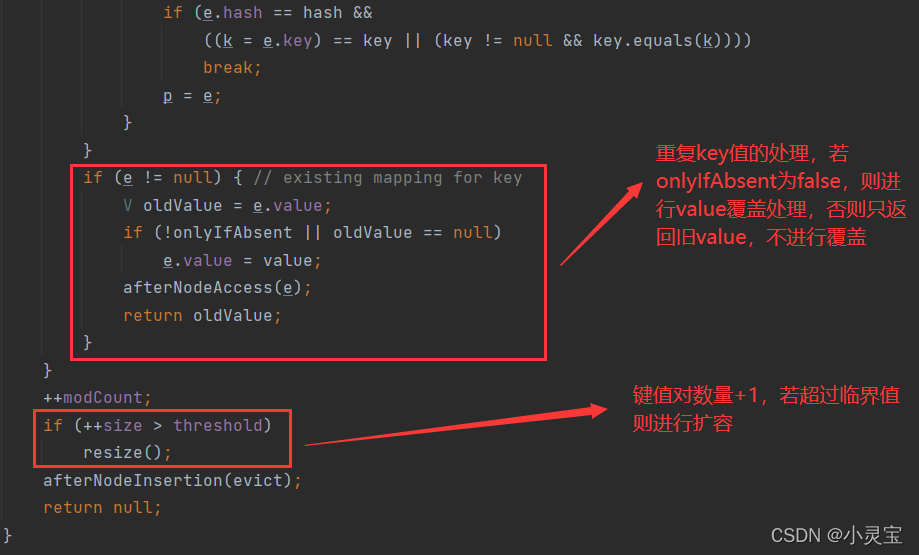
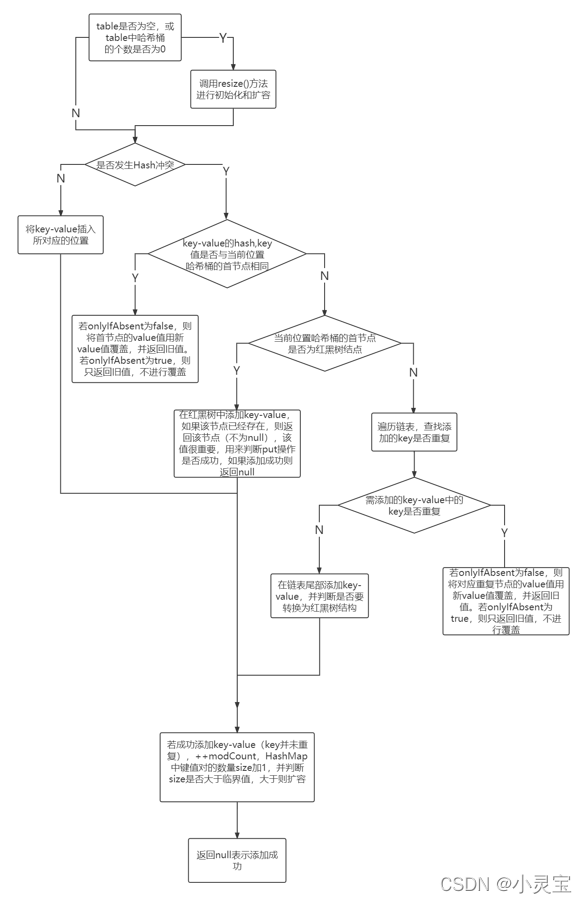
putVal方法的流程如下图所示:
注意,在table为空时,会调用resize方法进行初始化,这也是为什么说HashMap是懒加载的原因,因为它只有在使用它的时候才会分配空间,否则不会为其分配存储空间
值得注意的是,jdk提供了几个钩子函数:

它们的默认实现为空,可以由程序员重写,使得在key值重复和成功插入两种情况下分别进行不同的处理
删除:remove方法
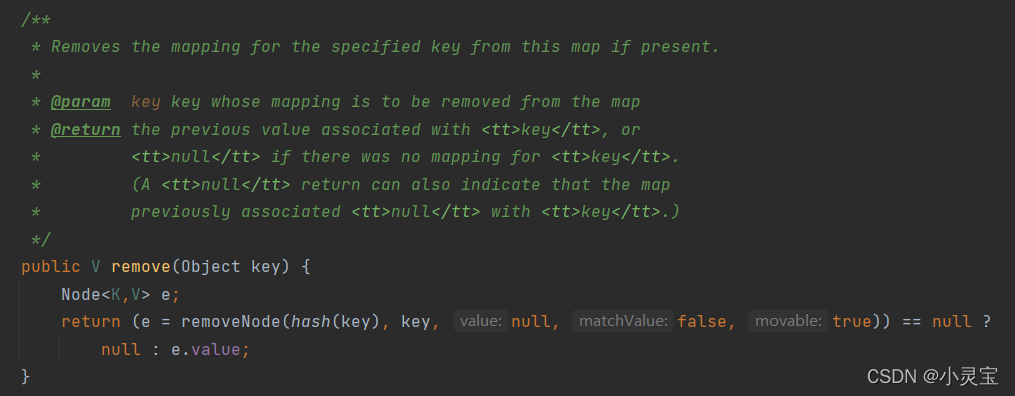
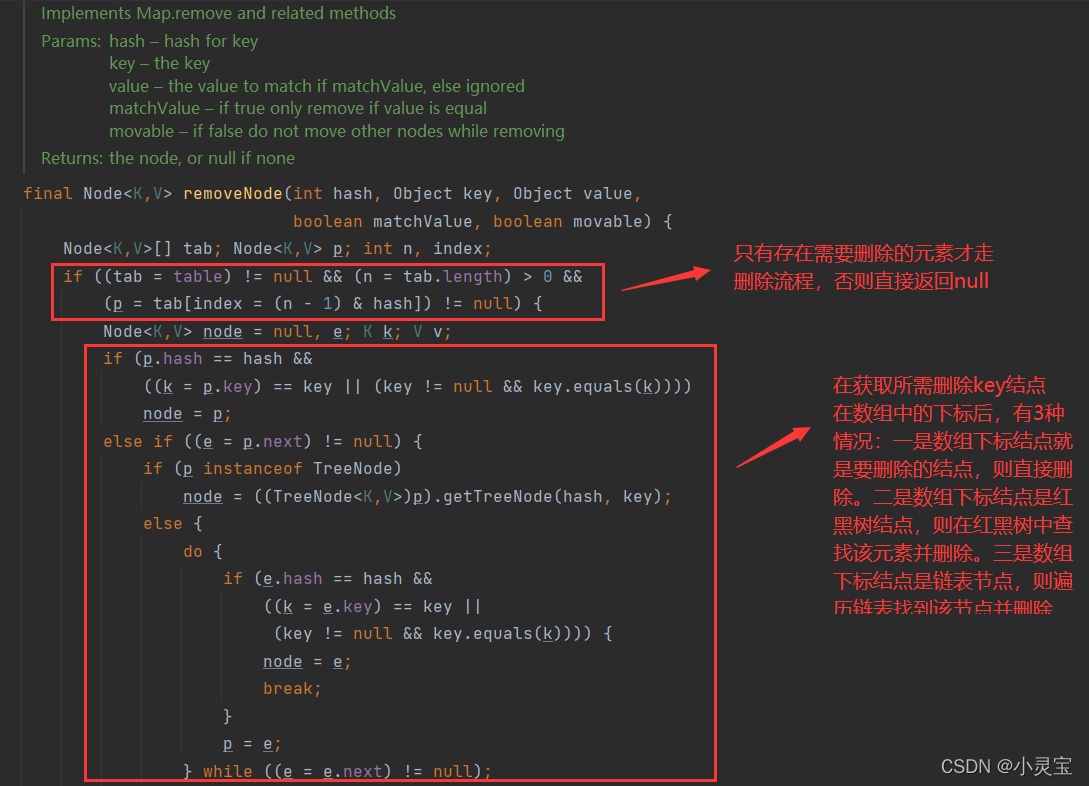
remove方法实际上是调用了removeNode方法,我们来看看该方法:
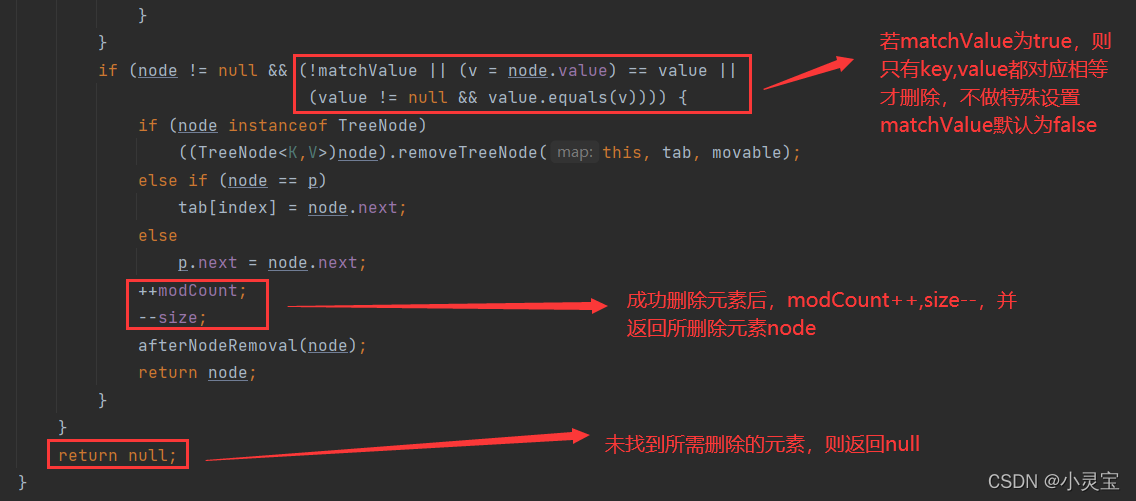
删除还有一个clear()方法,该方法删除所有键值对,其实就是将数组所有元素都置为null

改:put方法
元素的修改也是put方法,因为key是唯一的,且onlyIfAbsent为false,所以修改元素,是把新值覆盖旧值。
查:get方法
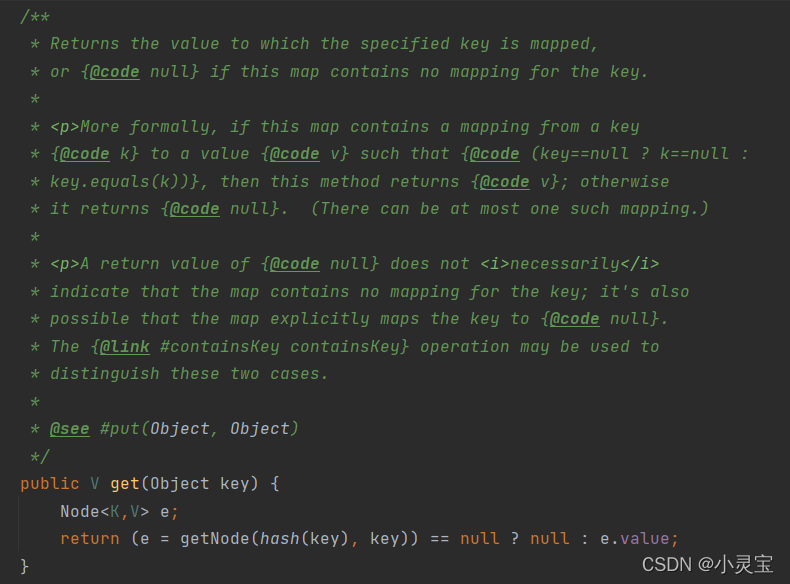
get方法实际上是调用了getNode方法,我们来看看该方法:
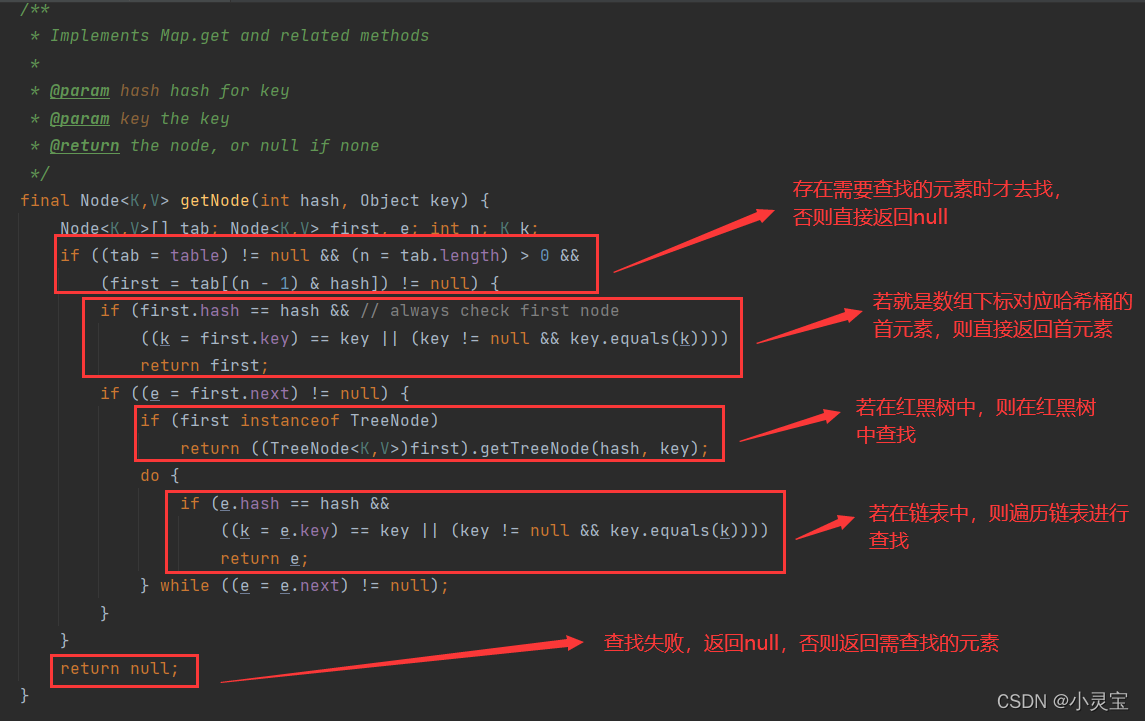
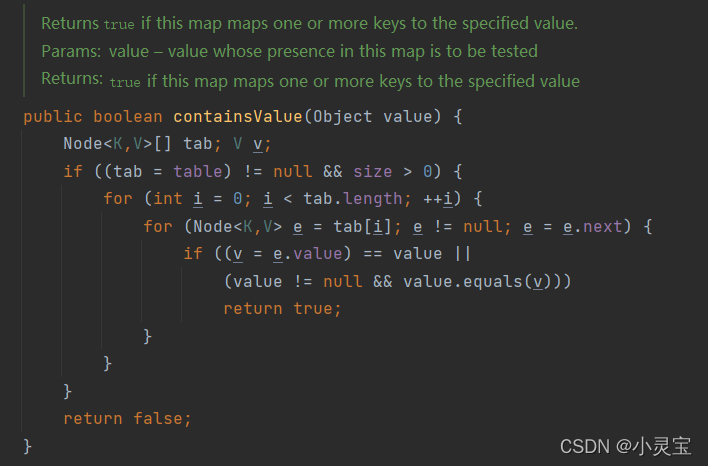
还有一个常用的方法,containsKey方法,查找是否存在某个key,其实就是调用了getNode方法:

而与之对应的一个查找是否有value值存在的方法containsValue方法,效率就很低了,是用的遍历数组暴搜: