笔记来源:
http://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html
http://blog.jobbole.com/86813/
- “请简述Unicode与UTF-8之间的关系。”
(UTF-8是Unicode的一种实现方式,而Unicode是一个统一标准规范,Unicode的实现方式除了UTF-8还有其它的,比如UTF-16等。可以这样理解:Unicode是字符集,UTF-32/ UTF-16/ UTF-8是三种字符编码方案。)
- “windows Notepad中的编码ANSI保存选项,代表什么含义?”
ANSI是windows的默认的编码方式,对于英文文件是ASCII编码,对于简体中文文件是GB2312编码(只针对Windows简体中文版,如果是繁体中文版会采用Big5码)。所以,如果将一个UTF-8编码的文件,另存为ANSI的方式,对于中文部分会产生乱码。
- "什么是UTF-8的BOM?"
========================================================
基本常识
- 位和字节
位(bite)指的是二进制(0/1)。
字节(byte)由8个位组合而成,取值范围“0000 0000 ---1111 1111”
- 字符编码
指定义一套规则,将真实世界里的字母/字符与计算机的二进制序列进行相互转化。
- 编码标准
字符编码是一套规则。既然是规则,就必须有标准。下面列举常见的字符编码标准。
- 拉丁编码
- 中文编码
- Unicode
- 拉丁编码
ASCII的全称是American Standard Code for Information Interchange(美国信息交换标准代码)。
ASCII的设计也很简单,用一个字节(8个位)来表示一个字符,并保证最高位的取值永远为’0’。即表示字符含义的位数为7位,不难算出其可表达字符数为27 =128个。
- 中文编码
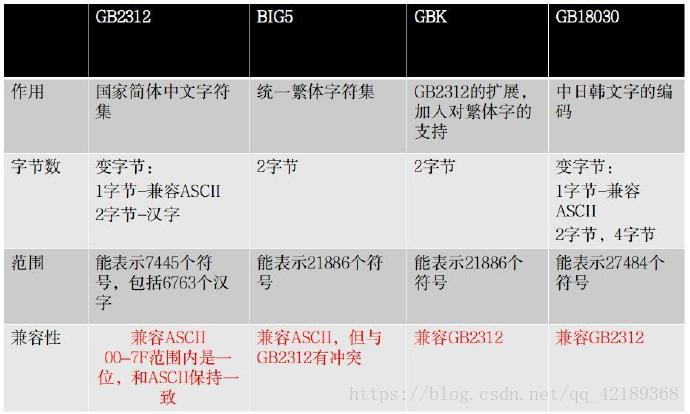
- Unicode
针对不同的语言采用不同的编码,有可能导致冲突与不兼容性,如果我们打开一份字节序文件,如果不知道其编码规则,就无法正确解析其语义,这也是产生乱码的根本原因。
有没有一种规则是全世界字符统一的呢?当然有,Unicode就是一种。为了能独立表示世界上所有的字符,Unicode采用4个字节表示一个字符,这样理论上Unicode能表示的字符数就达到了2^31 = 2147483648 = 21 亿左右个字符,完全可以涵盖世界上一切语言所用的符号。
Unicode对所有的字符编码均需要四个字节,而这对于拉丁字母或汉字来说是浪费的,其前面三个或两个字节均是0,这对信息存储来说是极大的浪费。另外一个问题就是,如何区分Unicode与其它编码这也是一个问题,比如计算机怎么知道四个字节表示一个Unicode中的字符,还是分别表示四个ASCII的字符呢?
以上两个问题,困扰着Unicode,让Unicode的推广上一直面临着困难。直至UTF-8作为Unicode的一种实现后,部分问题得到解决,才得以完成推广使用。说到此,我们可以回答文章一开始提出的问题了,UTF-8是Unicode的一种实现方式,而Unicode是一个统一标准规范,Unicode的实现方式除了UTF-8还有其它的,比如UTF-16等。
关于UTF-8的基本规则,其实简单来说就两条(来自阮一峰老师的总结):
- 规则1:对于单字节字符,字节第一位为0,后7位为这个符号的Unicode码,所以对于拉丁字母,UTF-8与ASCII码是一致的。
- 规则2:对于n字节(n>1)的字符,第一个字节前n位都设为1,第n+1位为0,后面字节的前两位一律设为10,剩下没有提及的位,全部为这个符号的Unicode编码。
举例来说,’微’的Unicode是’\u5fae’,二进制表示是”00000000 00000000 01011111 10101110“,其取值就位于’0000 0800-0000 FFFF’之间,所以其UTF-8编码为’11100101 10111110 10101110’ (加粗部分为固定编码内容)。
Unicode取值范围与UTF-8字节序表示的对应关系,如下表,

Unicode(UTF-8)与GBK,GB2312这些汉字编码规则是完全不兼容的,也就是说这两者之间不能通过任何算法来进行转换,如需转换,一般通过GBK查表的方式来进行。