二、静态链接
1、过程
(1)预处理(预编译).i:
处理源代码中“#”开始的预编译指令,如展开所有宏定义;
保留所有#pragma;
删除所有注释;
添加行号和文件名标识
(2)编译.s:
词法分析、语义分析、语法分析、优化后产生相应的汇编代码文件
(3)汇编.o:
将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令;生成目标文件
(4)链接.e:
主要是链接函数和全局变量,最终链接确定定义其他模块的全局变量和函数在最终运行时的绝对地址
2、编译器:
将高级语言翻译成机器语言的工具
扫描—语法分析—语义分析—源代码优化—代码生成—目标代码优化
1).词法分析
源代码字符序列分割成一系列的记号,识别各记号同时分类存放入表
2).语法分析
由语法分析器生成语法树(上下文无关语法分析手段),即以表达式为节点的树
3).语义分析
在语法树中插入相应的转化节点
(1)静态语义(编译器):编译期可以确定的语义,包括声明和类型的匹配、转换
(2)动态语义:只有在运行期才能确定的语义
4).中间语言生成
源代码优化器将整个语法树转换成中间代码,为语法树的顺序表示;
中间代码(Intermediate Representation或者IR)复杂性介于源程序语言和机器语言的一种表示形式。
编译程序锁使用的中间代码有多种形式。常见的有逆波兰记号,三元式,四元式,和树形表示。四元式是一种普遍采用的中间代码形式,很类似于三地址指令,有时把这类中间表示称为“三地址代码”,这种表示可以看作是一种虚拟三地址机的通用汇编码,每条”指令“包含操作符和三个地址,两个是为运算对象的,一个是为结果的
进入编译器后端(代码生成器、目标代码优化器)———源代码级优化器产生中间代码
5).目标代码生成与优化
代码生成器将中间代码转换成目标机器代码,目标代码优化器对上述目标代码进行优化,如选择合适的寻址方式、使用位移来代替乘法运算、删除多余的指令等
3、链接
每个源代码模块独立的编译,按照需求将它们“组装”起来,这个组装模块的过程为链接。把各个模块(目标文件)之间相互引用的部分都处理好使得各个模块之间能够正确的衔接
地址和空间分配—符号/名称决议(静态)/绑定(动态)—重定位
据编译器的连接参数指定:
1)、静态链接
所谓静态链接就是在编译链接时直接将需要的执行代码拷贝到调用处,优点就是在程序发布的时候就不需要的依赖库,也就是不再需要带着库一块发布,程序可以独立执行,但是体积可能会相对大一些。(所谓库就是一些功能代码经过编译连接后的可执行形式。)
2)、动态链接
所谓动态链接就是在编译的时候不直接拷贝可执行代码,而是通过记录一系列符号和参数,在程序运行或加载时将这些信息传递给操作系统,操作系统负责将需要的动态库加载到内存中,然后程序在运行到指定的代码时,去共享执行内存中已经加载的动态库可执行代码,最终达到运行时连接的目的。优点是多个程序可以共享同一段代码,而不需要在磁盘上存储多个拷贝,缺点是由于是运行时加载,可能会影响程序的前期执行性能。
4、链接器
将目标文件链接起来形成可执行文件
重定位:程序修改时重新计算各个目标的地址过程
重定位入口:需修正的地方
库文件.Lib/.a:中间文件打包
三、目标文件里有什么
1、目标文件
编译器编译源代码后但未进行链接的中间文件,已经是编译后的可执行文件
1)、格式
目标文件与可执行文件的格式几乎相同,内容与结构相似
可执行文件主要格式(PC):
PE(Windows)、
ELF(Linux)
2)、存储
动态链接库:
动态链接库 (DLL) 是作为共享函数库的可执行文件。动态链接提供了一种方法,使进程可以调用不属于其可执行代码的函数。函数的可执行代码位于一个 DLL 中,该 DLL 包含一个或多个已被编译、链接并与使用它们的进程分开存储的函数。DLL 还有助于共享数据和资源。多个应用程序可同时访问内存中单个 DLL 副本的内容。
静态链接库:
动态链接(Lib)与静态链接的不同之处在于它允许可执行模块(.dll文件或.exe文件)仅包含在运行时定位 DLL 函数的可执行代码所需的信息。在静态链接中,链接器从静态链接库获取所有被引用的函数,并将库同代码一起放到可执行文件中。
使用动态链接代替静态链接有若干优点。DLL节省内存,减少交换操作,节省磁盘空间,更易于升级,提供售后支持,提供扩展 MFC库类的机制,支持多语言程序,并使国际版本的创建轻松完成。
3)、内容
编译后的机器指令代码、数据、链接时所需要的信息,按照不同属性以“节”/“段”(默认情况)的形式存储
.text段:编译后执行语句都编译成机器代码
.data段:已初始化的全局变量和局部静态变量
.bss段:未初始化的全局变量和局部静态变量(为0,预留位置,不占用空间)
程序源代码编译后主要分为程序指令(代码段)和程序数据(数据段、.bss段)
程序被装载后,数据(可读写)和指令(只读)分别映射到两个虚存区域
数据区与指令区的分离有利于提高程序的局部性,对CPU的缓存命中率提高有好处
资源共享节省内存
2、SimpleSection.o
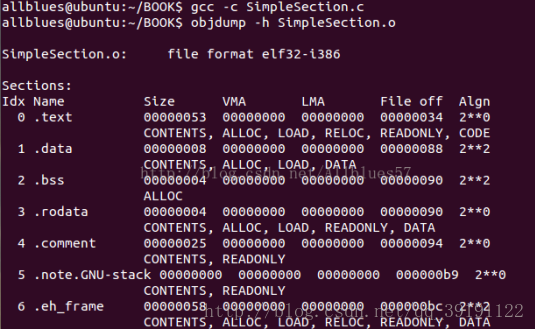
1).查看.o目标文件用objdump 命令, 参数“-h”就是把ELF文件的各个段的基本信息打印出来。也可以使用-X打印更多的信息
段的属性,Size是段的长度,FIle off 是段开始的位置,每个段的第二行中“CONTENTS”、“ALLOC”等表示段的属性,“CONTENTS”表示
该段在文件中存在。虽然BSS段没有“CONTENTS”,表示它实际在ELF文件中并不存在。
2). 可以用Size命令来查看ELF文件的代码段、数据段和BSS段的长度;
.text段:编译后执行语句都编译成机器代码,仅包含函数func1()和main()的指令
.data段:已初始化的全局变量和局部静态变量,global_init_var和static_var共8字节
.bss段:未初始化的全局变量和局部静态变量(为0,预留位置,不占用空间),4字节
.rodata段:为只读信息段,存放字符串常量“%d\n”,4字节
.conment段:注释信息段
.note.GUN_stack段:堆栈段
.eh_frame段:调试信息
自定义段:在全局变量或函数之前加上“attribute((section(“section_name”)))”属性即可将其放到指定的段中。
attribute((section(“FOO”))) int global = 42;
attribute((section(“BAR”))) void foo() {}
3、ELF文件
ELF(Executable and Linking Format)是一种对象文件的格式,用于定义不同类型的对象文件(Object files)中都放了什么东西、以及都以什么样的格式去放这些东西
elf文件分三种类型:
(1)、目标文件(通常是.o);
(2)、可执行文件(我们的运行文件) ;
(3)、动态库(.so)
可执行文件一般分成4个部分,能扩展,我们理解这4部分就够了。
1)、elf文件头 ,这个文件是对elf文件整体信息的描述,在32位系统下是56的字节,在64位系统下是64个字节。
对于可执行文件来说,文件头包含的一下信息与进程启动相关
e_entry 程序入口地址
e_phoff segment偏移
e_phnum segment数量
2)、 segment表, 这个表是加载指示器,操作系统(确切的说是加载器,有些elf文件,比如操作系统内核,是由其他程序加载的),该表的结构非常重要。
typedef struct
{
Elf64_Word p_type; /* Segment type */
Elf64_Word p_flags; /* Segment flags */ /*segment权限,6表示可读写,5表示可读可执行
Elf64_Off p_offset; /* Segment file offset */ /*段在文件中的偏移*/
Elf64_Addr p_vaddr; /* Segment virtual address */ /*虚拟内存地址,这个表示内存中的
Elf64_Addr p_paddr; /* Segment physical address /*物理内存地址,对应用程序来说,这个字段无用*/
Elf64_Xword p_filesz; /* Segment size in file */ /*段在文件中的长度*/
Elf64_Xword p_memsz; /* Segment size in memory */ /在内存中的长度,一般和p_filesz的值一样*/
Elf64_Xword p_align; /* Segment alignment */ /* 段对齐*/
} Elf64_Phdr;
3)、 elf的主题,对于可执行文件来说,最主要的就是数据段和代码段
4)、 section表,对可执行文件来说,没有用,在链接的时候有用,是对代码段数据段在链接是的一种描述
3、符号—链接接口
符号:函数和变量(全局符号可被其他目标文件引用)
符号值:定义符号对应地址
符号表:每个目标文件相应的符号表
符号的分类如下:
定义在本目标文件中的全局符号,可以被其它文件引用。
在本目标文件中引用的全局符号,却没有定义在本目标文件,这一般叫做外部符号(External Symbol), 也就是我们前所谓符号引用。
段名,这种符号通常由编译器产生,它的值就是该段的起始地址。
局部符号,这类符号只在当前编译单元内部可见。局部符号对于链接过程没有作用,链接器往往忽略它们。
行号信息,即目标指令与源代码中代码行的对应关系,它是可选的。
1)、ELF符号表结构
ELF符号表域说明:

特殊符号:当我们使用ld作为链接器来链接生产可执行文件时,它会为我们定义很多特殊的符号,这些符号并没有在程序中定义,但是可以直接声明并且引用它,称之为特殊符号,id与链接脚本有关
__executable_start,该符号为程序起始地址,注意,不是入口地址,是程序的最开始的地址。
__etext或_etext或etext,该符号为代码段结束地址,即代码段最末尾的地址。
_edata或edata,该符号为数据段结束地址,即数据段最末尾的地址。
_end或end,该符号为程序结束地址。
2)、符号修饰、函数签名
函数签名(Function Signature):函数签名包含了一个函数的信息,包括函数名、它的参数类型、它所在的类和名称空间及其他信息。函数签名用于识别不同的函数,就像签名用于识别不同的人一样,函数的名字只是函数签名的一部分。在编译器及链接器处理符号时,它们使用某种名称修饰的方法,使得每个函数签名对应一个修饰后名称(Decorated Name)。编译器在将C++源代码编译成目标文件时,会将函数和变量的名字进行修饰,形成符号名,也就是说,C++的源代码编译后的目标文件中所使用的符号名是相应的函数和变量的修饰后名称。
① C++编译器和链接器都使用符号来识别和处理函数和变量,所以对于不同函数签名的函数,即使函数名相同,编译器和链接器都认为它们是不同的函数,函数名称不能完全标识一个函数;因此我们用“函数签名(function signature)”来唯一标识一个函数
② “函数签名”经过不同“编译器/链接器”的“名称修饰(name decoration)”得到不同的“修饰后名称(decorated name)”。由于不同编译器采用不同的名字修饰方法,必然会导致由不同编译器产生的目标文件无法正常链接,这是导致不同编译器之间不能互操作的主要原因之一
3)、关键字-exter”C”
http://blog.csdn.net/qq_22274565/article/details/78960073
4)、弱符号与强符号
对于C/C++语言来说,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。
关于多个强弱符号定义类型不一致的主要有下面三种情况:
① 两个或两个以上强符号类型不一致
② 有一个强符号,其他都是弱符号
③ 两个或两个以上弱符号类型不一致
对于情况一,编译会报符号重定义错误。
对于情况二,链接最终会选择强符号。
5、调试信息
调试信息是在编译器生成机器码的时候一起产生的,它代表着可执行程序和源代码之间的关系
http://blog.csdn.net/xushiweizh/article/details/1584661
一般要查找程序的上下文信息主要有以下几种方法:
① 源代码窗口
② 通过源代码查看程序执行到代码的那一部分
③ 程序堆栈(由硬件,操作系统和编译器共同支持的)
硬件: 提供堆栈指针;
操作系统:为每个进程建立堆栈空间,并管理堆栈。一旦堆栈溢出,而产生一个错误;
汇编级调试:反汇编,查看寄存器,查看内存