目录
前言
本复习笔记基于张老师的课堂PPT,供自己期末复习与学弟学妹参考用。
开始进入最最重点部分,下面是剩余知识的概要框架

重点一览

词法分析概述
词法分析的功能
扫描源程序的字符串,按照词法规则识别出单词符号作为输出,对于识别过程中发现的此法错误,则输出有关的错误信息(可以给出错信息赋予一个行号)。
词法分析器和语法分析器的关系
① 词法分析器可以作为单独的一环
② 词法分析器可以作为语法分析器的子程序
词法分析器的输出形式
单词的种类

单词输出形式
二元式 
单词类别划分:基本字(保留字)一字一码;标识符(字母开头的字母数字串)单列一种;常数按类型分类(整形、实型、布尔型、字符型……)
词法分析器的结构
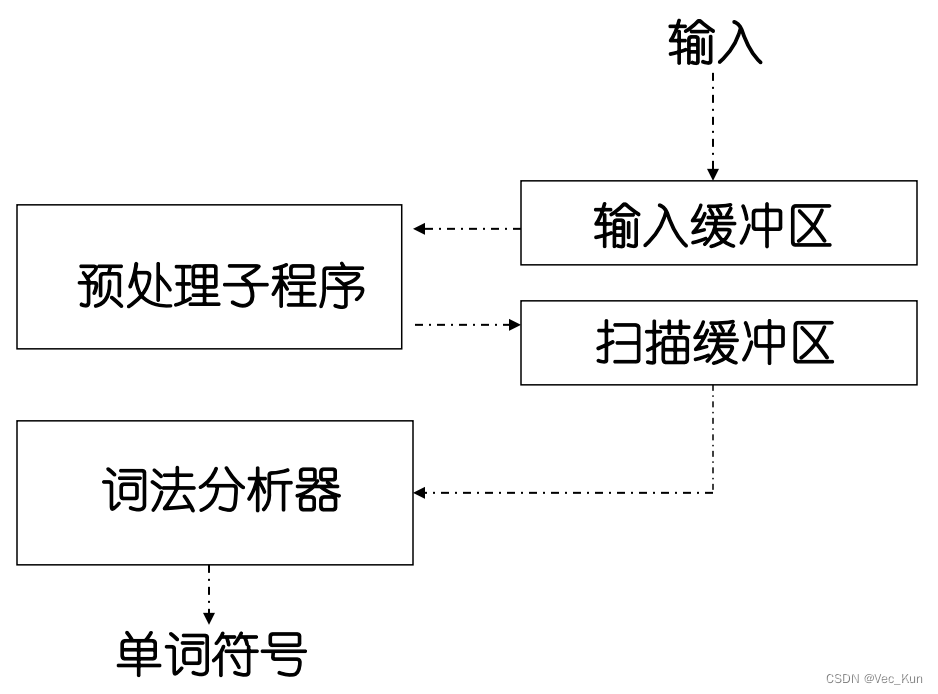
- 输入缓冲区:存放源程序
- 预处理程序:取消注解、提出无用的空白、制表、换行、回车等符号
- 扫描缓冲区(词法分析真正要使用的):从输入缓冲区输入固定长度的字符串到另一个
- 缓冲区(扫描缓冲区),词法分析器可以直接在此缓冲区进行符号识别
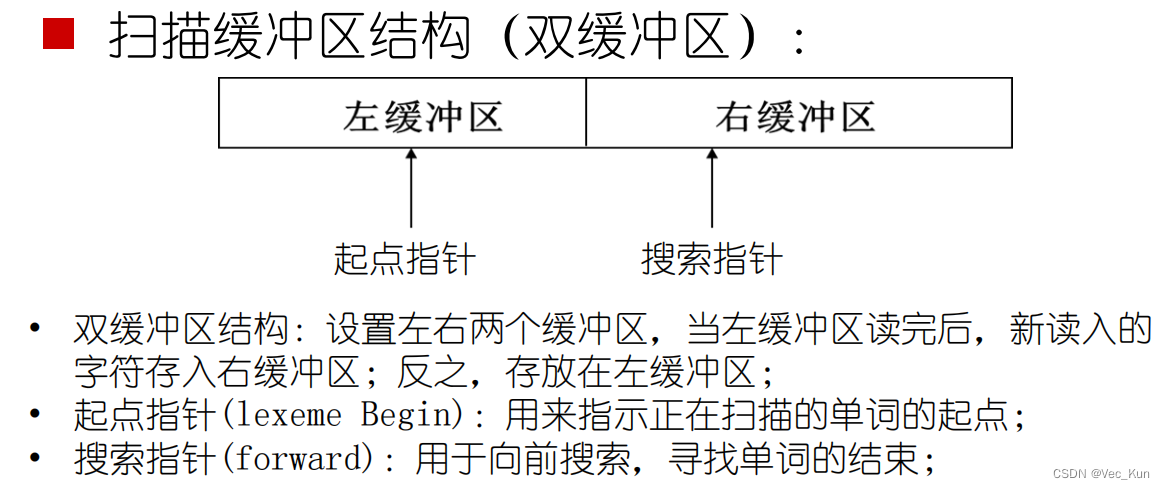
词法分析技术——超前搜索:为了判定一个单词符号的类别,必须多扫描一个或几个单位
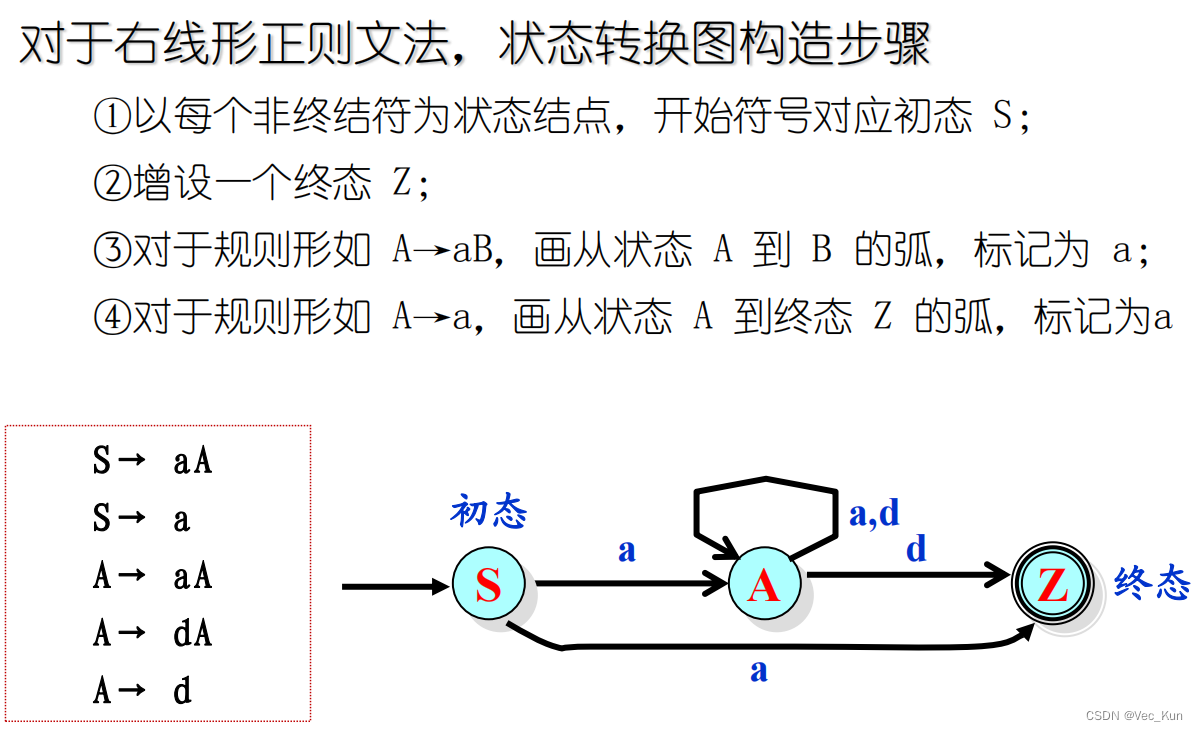
状态转换图
定义:一张有限有向图,圆圈表示节点,代表状态,有向边连接节点,其上的标记字符表示该状态下可能接受或识别的字符,有唯一初态,若干终态。
加*的状态表示如果最后识别的字符不在单词表中则需要退回一个字符

用状态转换图识别单词符号:
1)从初态开始;2)从输入串中读一个字符;3)判明读入字符与从当前状态出发的哪条弧上 的标记相匹配,便转到相应匹配的那条弧所指向的状态;4)重复3),均不匹配时便告失败;到达终态时便识别出一个单词符号。
- 如何区别符合标识符的基本字/保留字?
- 在符号表中预留保留字,并指明它们不是标识符。为保留字建立单独的状态转换图
状态转换图的构造
词法分析器的设计
基本结构

内容
- 单词
- 单词表
- 状态转换图
- 匹配算法
符号表
目的
程序中,用户用标识符定义了很多名称来代表不同的数据对象,编译程序可以将这些名称保存在符号表中。
组成
符号表除了记录名称本身,还记录了与名称关联的各种属性信息。
在词法分析中的作用
- 建立符号表、查填符号表
- 将不重复的标识符、数字常数和字符常数的性质填入符号表
- 将变量/常数在符号表中的入口地址写到其自身的单词(token)中
符号表的一般形式
每个名字对应一个表项,一个表项包括名字域和信息域
信息域设若干子域和标志位,内容和名字有关
常用的符号表结构
线性表
用N个数组来存放符号表的N个子域
HASH表/哈希表

总结与补充



为何分离词法和语法分析
- 简化编译器的设计
- 提高编译器的效率
- 增强编译器的可移植性
本章小结
