目录
前言
本复习笔记基于叶老师的课堂PPT,供自己期末复习与学弟学妹参考用。
重点一览

Cache基本原理
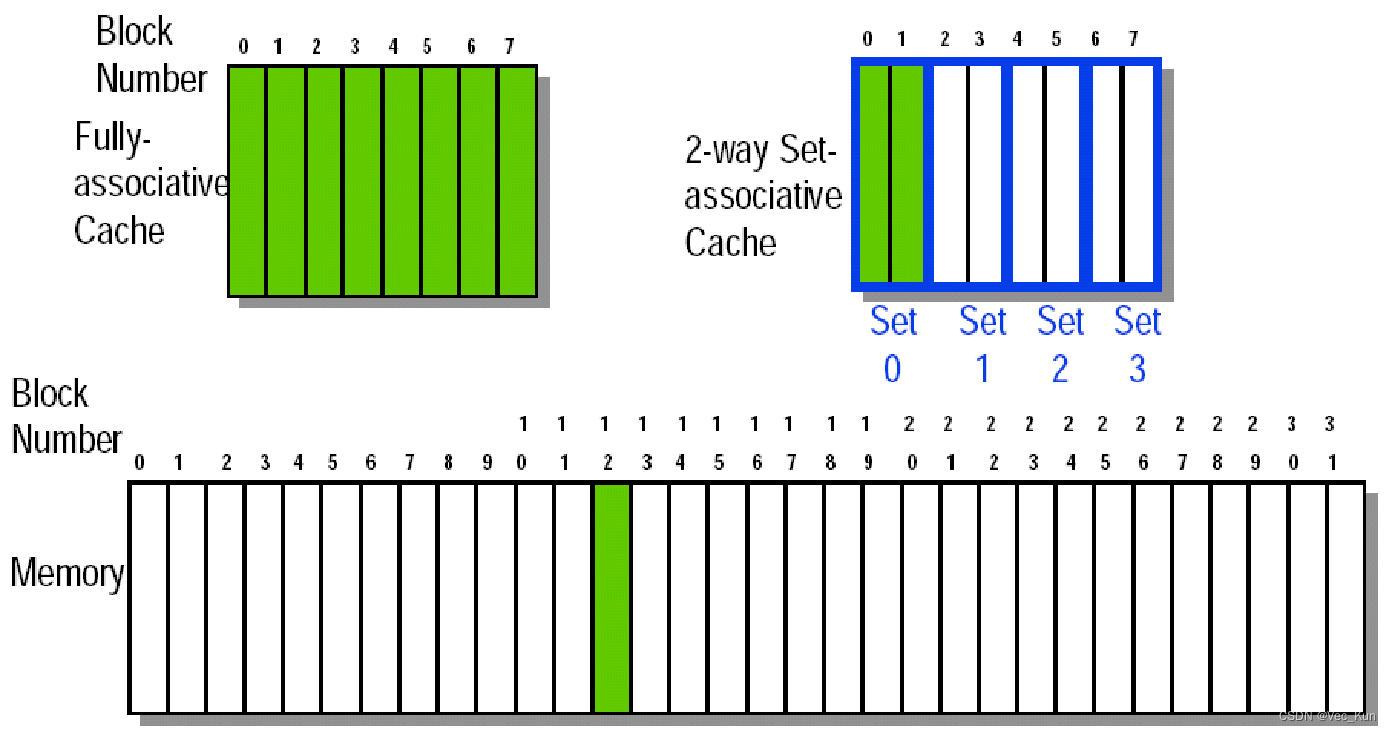
三种映像方式
- 直接映像
- 块只能放在Cache中唯一的位置
- 全相联
- 块可以放在Cache中的任意位置
- 组相联
- 块能够放在Cache一组中任意一块位置
- 如果一组有n块,则Cache称为n路组相联

物理地址与Cache地址的映射计算
物理地址的格式

- 索引 Index 字段选择
- 在直接映像Cache中,选择块
- 在组相联Cache中,选择组
- 索引位数: log2(#块数) ——直接映像caches
- log2(#组数) ——组相联caches
- 字节位移量 Byte Offset 字段选择
- 块中的某个字节
- 位数: log2(块字节数)
- 标识Tag 用于查找在Cache或一组中的匹配块(即相同的块)
- 位数:物理地址位数 – 索引位数 – 块内偏移位数
例题:

Cache块标识
Cache的每个块都有一个标识 tag :存放CPU访问数据所在块的主存物理地址中的高位部分(主存多块映射到cache一块)
当CPU访问cache时,将比较主存地址与cache tag-----如果两者相同,表示cache命中即数据在cache中
通常,每个cache块还有一位有效位 valid bit :表示cache块的内容是否有效
Cache替换算法
块替换(Cache缺失时)
直接映像 cache,仅有唯一的一块能够被替换 对于组相联和全相联 caches,则有N块替换位置( N是相联度)
3种替换策略
- 随机替换 –— 随机选择被替换的一块。硬件容易实现,需要随机数产生器;均匀使用一组中的各块;可能替换即将被访问的那一块
- 最近最少使用 (LRU)——选择一组中最近最少被访问的块作为被替换块。假定最近被访问的块很可能会一再访问;Cache中需要额外的位记录访问历史
- 先进先出(FIFO)——选择一组中最先进入cache的一块 作为被替换块
Cache写策略
- 如果数据写cache的同时也写主存,cache被称为写直达(write-through cache)
- Cache中的数据可以随时丢弃——主存中有最新的数据
- Cache 控制位:只需要一位 valid bit(是否包含有效信息:“1”时表示该目录表项有效)
- 主存(或其他处理器)总是有最新的数据
- 写停顿:采用写直达策略,CPU必须等待写操作完成
- 写缓冲:一个小缓冲区,存放等待写入主存的几个值。 为了避免等待,很多CPU都使用一个写缓冲。 在写操作集中时,这个缓冲很有作用。 它不能完全消除停顿。例如:如果写的数据量大于缓冲区, 就可能产生停顿。
- 如果数据写cache时不写主存,cache被称为写回(write-back cache)
- 不能丢弃cache中的数据——可能需要写回到主存
- Cache 控制位:需要 valid位 和dirty 位(是否被修改:dirty为”1“时表示该块修改过)
- 带宽较小,因为对同一块的多次写仅需要对主存写一次
- 写直达优点:读缺失不会导致替换时的写操作,保持了数据一致性,实现简单。
- 写回优点:写cache的速度更快,主存带宽更低。
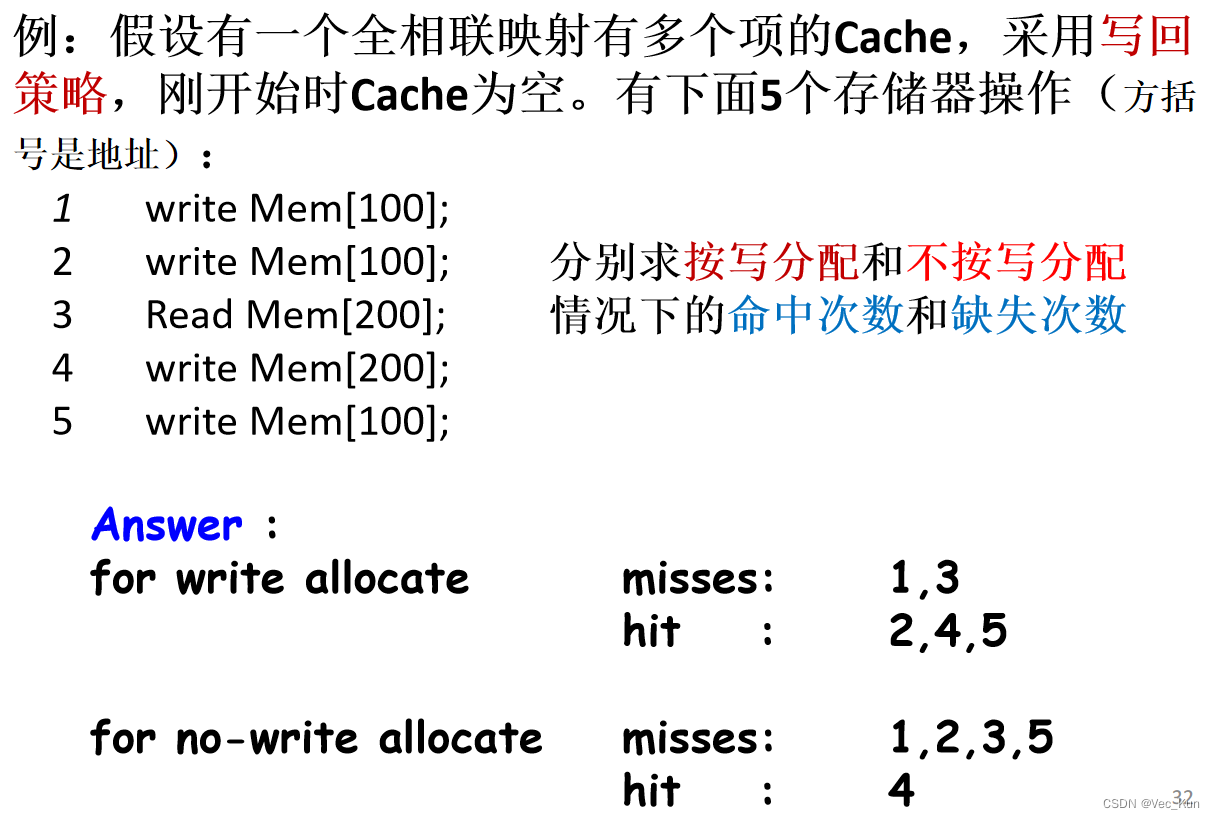
- 写缺失:对cache进行写时,如果要写的块不在cache,有两种策略选择:
- 写分配(Write allocate) 写失效时,把所写单元所在的块调入Cache(对应写回),然后再进行写命中操作。这与读失效类似。
- 不按写分配 Write around (no write allocate) 写失效时,直接将值写入下一级存储器而不将相应的块调入Cache。 写的值不在cache中(在主存中,所以对应写直达)。
- 通常,写回caches采用写分配;
- 写直达caches采用不按写分配。
分离cache与一体cache
一体cache:所有存储访问都是对单个 cache进行的。 需要较少的硬件;性能更低
分离的指令cache与数据cache:指令与数据存放在不同的 cache中;需要额外的硬件
Cache性能与优化
Cache性能计算
缺失率 :Cache访问中,访问缺失次数占访问总次数的百分比。
缺失代价 :Cache访问缺失时,访问下一级存储器所花费的时间,通常用时钟周期数表示。
CPU 执行时间 =( CPU 时钟周期数 + 存储器停顿周期数)×时钟周期时间 ①
存储器停顿时钟周期数 = 指令数 ×每条指令访存次数× 缺失率× 缺失代价 ②
将②带入①可得:
![]()
![]()
平均存储器访问时间:
Cache性能优化
![]()
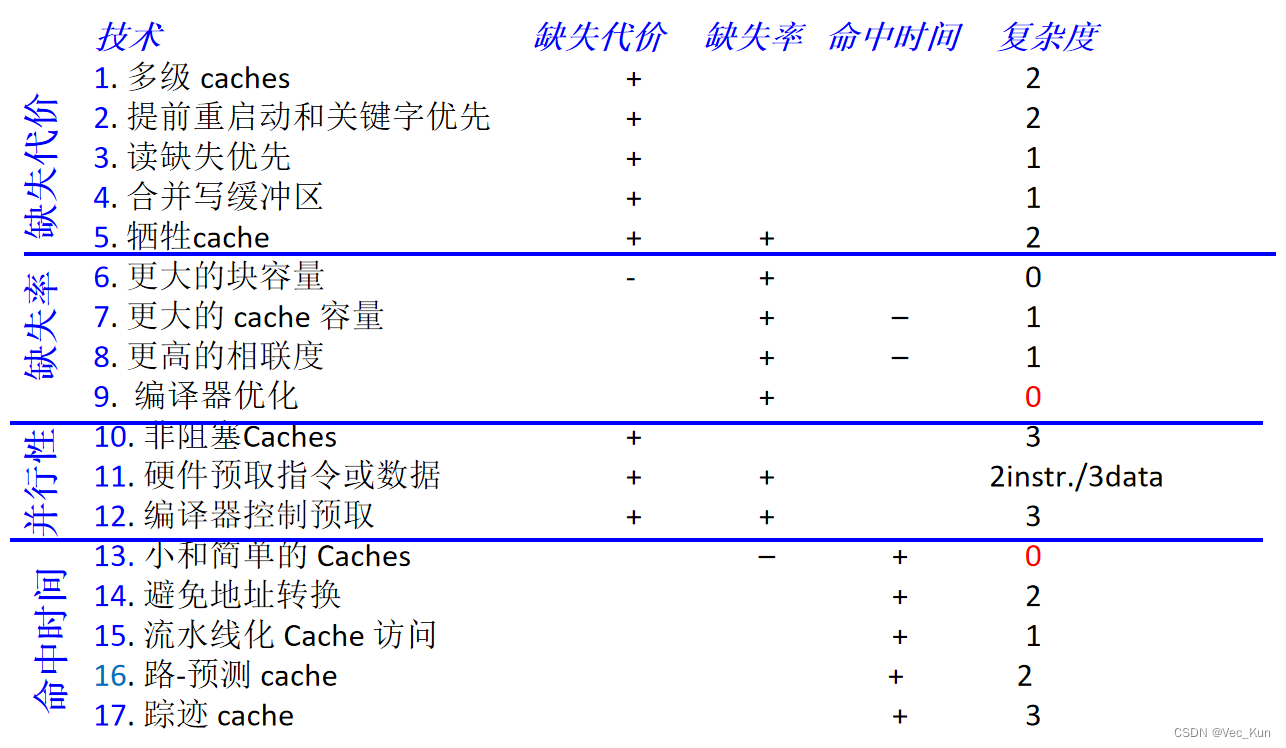
因此,17种 cache 优化措施分为4类:
1.减少缺失率 -- 4
——增加块大小,增大 cache 容量,更高相联度,编译优化
2.减少缺失代价 -- 5
——多级 caches,关键字优先,读缺失优于写缺失,合并写缓冲,牺牲缓冲
3. 通过并行减少缺失代价和缺失率--3
——非阻塞 caches,硬件预取,编译预取
4. 减少cache的命中时间 -- 5
——小和简单的 caches,避免地址转换,流水线 cache 访问,路预测,踪迹 caches
减少缺失率
缺失产生的原因
强制缺失—第1次访问一个块,它一定不在cache中,因此这一块必须被装入cache。这也称为冷启动缺失或首次访问缺失。 (甚至在一个无限 Cache中也有强制缺失)
容量缺失—如果 cache容纳不了一个执行程序的所有块,由于一些块被替换出去后又要被访问引起容量缺失。
冲突缺失—如果块放置策略是组相联或直接映像,如果有太多块映射到一组,一块可能被替换后又要被访问从而引起冲突缺失(除了强制和容量缺失外)也称为碰撞缺失或干涉缺失。
①强制性缺失与Cache大小无关。
②容量缺失随容量增加而减少,与相联度无关。
③相联度越高,冲突失效就越少。
④ 2:1的Cache经验规则,即大小为N的直接映象Cache的缺失率约等于大小为N/2的两路组相联Cache的缺失率。
方法一:增大块容量
- 方法
- 更大的块减小了强制缺失率(更大的块容量意味着第一次装入的块数就少了),这是利用了空间局部性。
- 绘制的曲线是 U-形的
- 可能会增加缺失代价,这是由于每次缺失需要取更多的数据。几乎会确定增加冲突缺失,这是因为cache中的块数更少。在小容量cache,甚至可能增加容量缺失。
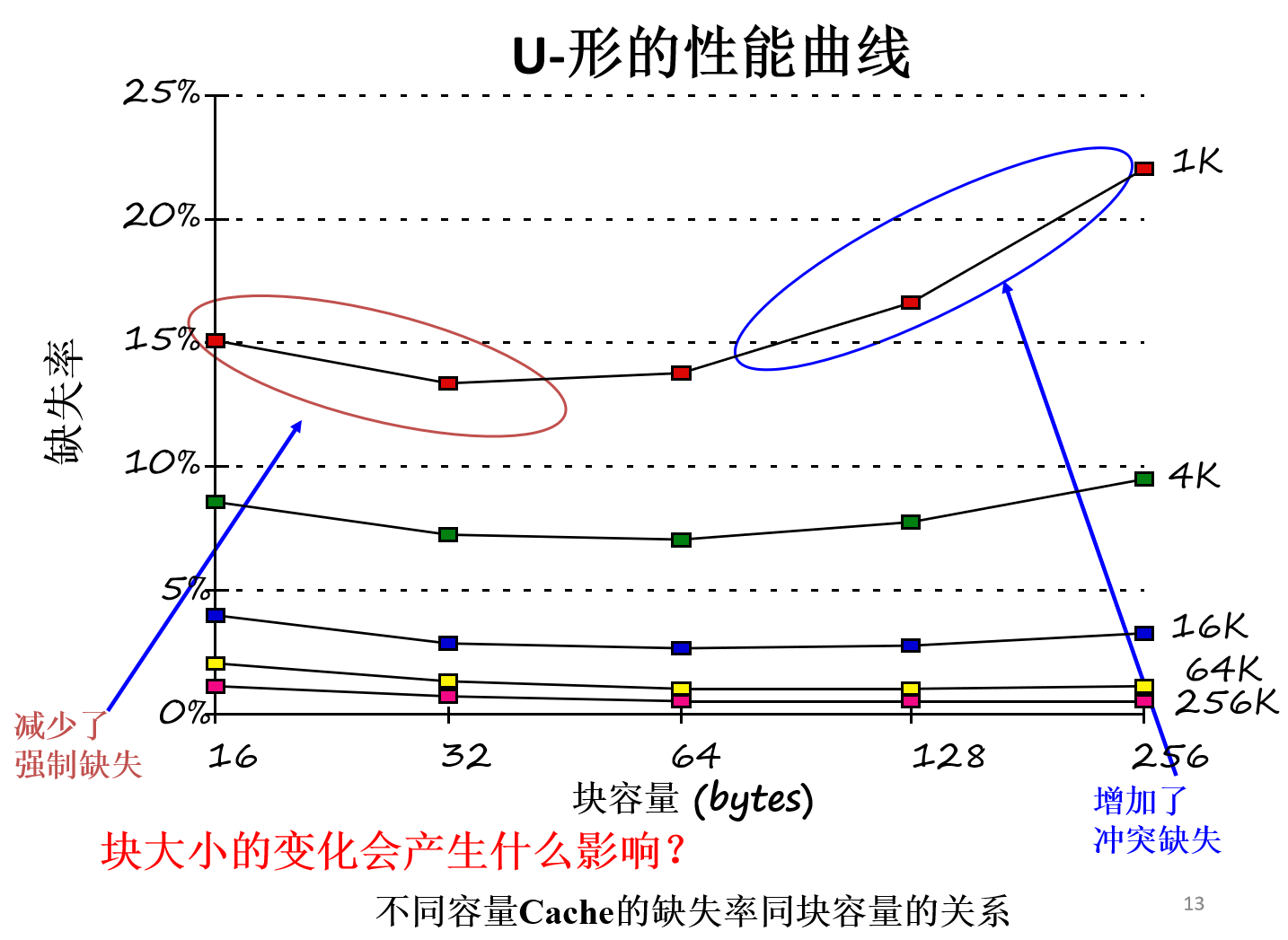
- 权衡
- 试图既要减小缺失率也要减小缺失代价。块容量的选择取决于下一级存储器的延迟和带宽。
方法二:增大cache容量
- 增大cache容量减小了容量缺失和冲突缺失
- 缺点:更长的命中时间;更高的价格
方法三:更高的相联度
- 方法
- 对于低相联度(尤其是直接映像)cache,冲突缺失是一个问题。
- 更高相联度减少了冲突缺失,从而改善了缺失率。
- Cache经验法则:2:1 经验法则
- 一个容量为 N直接映像cache与容量为 N/2的2-路组相联cache具有相同的缺失率。
- 从实用角度,8路组相联cache与相同容量全相联cache有效减少冲突缺失效果几乎相当
- 必须意识到:执行时间是唯一最终的评价指标! 时钟周期时间与命中时间紧密相关。
方法四:编译器优化
- 方法
- 无需修改硬件、利用编译器对指令程序、数据重排序就可以减小缺失率。
- 指令
- 如,编译器预测转移发生,可以将转移目标基本块与转移指令后的基本块互换
- 数据
- 合并数组:将二个连续数组合并为一个数组,改善空间和时间局部性
- 循环交换:改变嵌套循环顺序以便按照数据的存储顺序来访问数据
- 循环融合:将有相同循环和一些变量重叠的2个独立循环组合成一个循环
- 分块:利用重复访问数据“块”(相对于整列或整行访问)改善空间局部性
减少缺失代价
缺失代价是由于访问目标不在Cache中而从存储器中替换该块所花费的时间。
方法一:多级Caches
- 方法
- 在一个小而快的一级cache与主存之间增加一个二级 cache
- 帮助满足 cache 快而大
- 一级 cache :
- 一级 cache 是快得足够匹配CPU的时钟周期时间,而且小的可以与CPU做在一块芯片上,从而减少命中时间。
- 二级 cache:
- 更大的二级cache大得足以捕捉很多本该到主存的访问,从而有效地减少缺失代价。
 (局部缺失率)
(局部缺失率)- 一级cache缺失代价实际上是二级cache的平均访存时间
- 全局缺失率L1和局部缺失率相同;全局缺失率L2=局部缺失率L1*局部缺失率L2
方法二:关键字优先和提前重启动(关键字优先)
- 方法
- CPU只需要块中的一个字,不要等到取到整个块后才重新启动CPU(缺失代价就是读取关键字的代价)
- 关键字优先—首先从存储器请求缺失的字并尽可能快地送到CPU;让CPU继续执行同时填放块中的其余字。
- 提前重启动— 以正常顺序取块,只要块中所请求的字到达,就送到CPU,让CPU继续执行。
- 通常用在大块中
- 空间局部性 => 趋向于将需要下一个连续的字,应该说提前重启动是有利的
方法三:读缺失的优先级高于写缺失(读缺失优先)
- 方法
- 如果系统有写缓冲,写操作能够延迟到读后。
- 但是,系统必须小心检查写缓冲中是否有读缺失要读的值。
- 写直达
- 当读缺失产生读主存时,有可能要读的数据在写缓冲中,还没有写入主存:
- 数据在写缓冲中=> RAW 冒险
- 解决办法: 如果简单等待写缓冲空,可能增加读缺失代价。可以在读之前检查写缓冲数据:如果没有冲突,让读主存优先。
- 写回
- 读缺失替换脏块
- 通常操作:写脏块到主存,然后进行读操作。
- 如果有写缓冲:复制脏块到写缓冲,然后先读,再写。 有读缺失时,也要检查写缓冲,看地址是否有冲突,没有则可以读缺失优先。
方法四:合并写缓冲
- 方法
- 用写多个字代替写一个字,可以改善写缓冲的效率。
- 写直达,如果写缓冲包含其他修改的块,检查新数据的地址是否与写缓冲中的其他有效项地址匹配。如果匹配,新数据合并到那一项中。
- 合并写优化技术有时可以减少写缓冲满时导致的停顿。
方法五:牺牲缓存(牺牲cache)
- 方法
- 牺牲缓存是一个小的全相联 cache,它存放几个最近被替换出的块 。 该技术常见并非必须。
- 在发生缺失要访问下一级存储器以前,先检查牺牲cache:
- 看是否有缺失的数据
- 如果有,交换牺牲块与 cache 块。
利用并行减少 Cache 缺失代价或缺失率
方法一:非阻塞cache减少cache缺失停顿(非阻塞cache)
非阻塞cache:当等待取数据返回的同时,Cache并不停止,而是可以继续提供指令和数据
- 方法
- 减少缺失代价
- 乱序执行的流水线处理器,在Cache缺失停顿时,仍然可以执行其他无关指令。
- 非阻塞cache(无锁 cache):在处理读缺失过程中,允许cache 继续提供命中(“缺失下命中”,“多重缺失下命中”)。
- 非阻塞Cache通过重叠存储器访问和执行时间有效地降低了缺失代价;(处理器在等待数据Cache返回数据时,可以继续从指令Cache中取指令)
- 复杂 caches 甚至能够重叠多个缺失( “缺失下缺失”),将进一步有效地降低缺失代价。
方法二:指令和数据的硬件预取
- 方法
- 减少缺失
- 在CPU实际需要访存数据以前,提前从主存取数据。
- 在产生访存请求之前获取数据可减少强制缺失。
- 可能增加其他缺失,如从cache中移走了有用的块。
- 因此,很多 caches 会增加一个特殊的缓冲器中保存预取的块
- 例如:指令预取
- 缺失时先访问流缓冲器,命中读出该块,发下一块预取请求; 如不命中,则从下级存储器取该块和下一块到Cache和流缓冲器
- 预取与CPU执行可以同时进行
方法三:编译器控制的预取
方法
减少缺失
- 编译器插入预取指令请求数据(在实际使用这些数据之前)
- 有两种预取方式:
- 捆绑预取Binding prefetch:请求预取的值直接装入寄存器。
- 非捆绑预取:将数据预取到cache,不放入寄存器。
- 通常特殊的预取指令不会引起异常:一种特殊的执行形式
- 发射执行预取指令需要花费时间
- 预取产生的开销 < 减少缺失节省的开销?
- 超标量支持多指令发射有助于提高预取指令执行效率
减少Cache命中时间
方法一:小和简单的Caches
- 方法
- 使用小的和直接映像 cache
- 实现一个cache必要的硬件越少,通过硬件的关键路径就越短。
- 直接映像无论是读还是写都快于组相联cache
- 命中的cache与CPU在同一芯片上,对于加快访问时间是非常重要的
方法二:在cache索引时避免地址转换(避免地址转换)
- 传统物理地址Cache存在的问题:地址转换。
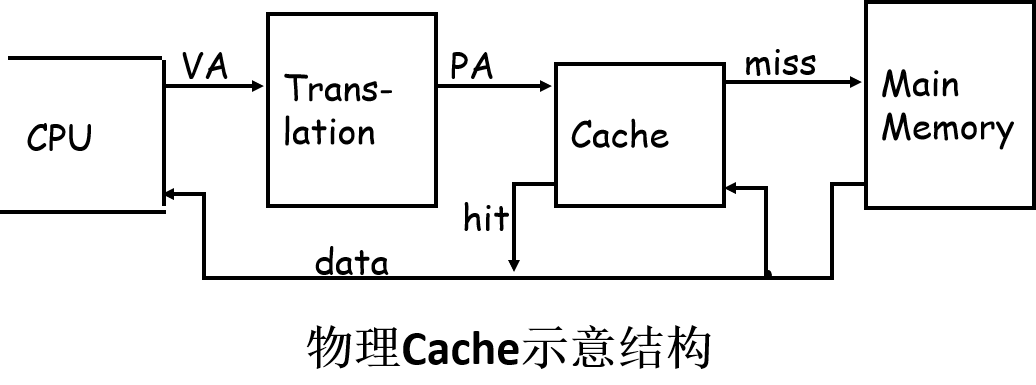
- CPU使用虚拟地址VA,Cache使用物理地址PA。页表在主存中,是一个大的数据结构。从主存取数据、存结果、取指令,需要2次访问主存!
- 一种快速地址转换的方式是使用一个特殊的缓存cache 存放最近用过的页表项
- 最常用的名字为 Translation Lookaside Buffer or TLB
- TLB实际上是页表映射的一个cache
- TLB 的访问时间与cache 访问时间相当 (大大少于主存访问时间)
- 类似于 cache,TLB 可以采用全相联、组相联、直接映像组织结构。
- TLBs 通常是小的,* 在高端机器中典型大小不超过 128 - 256 项,采用全相联结构来检索;* 中档机器采用小的n-路组相联结构。

- 避免VA-PA地址转换的方法
- Cache 也可以使用虚拟地址
- 一个 cache 用虚拟地址检索称为虚拟 cache ( 相对于物理 cache )。
- 虚拟索引物理标识:地址转换与cache访问并行进行,可以减少命中时间。
- 避免索引时的地址转换
- 虚拟索引也是物理地址的一部分,用索引访问cache与VA转换能够并行执行,则其后可以将通过TLB转换得到的物理 tag与访问cache获得的物理tag进行比较,如果相等,则Cache命中(即在Cache中能找得到)
- 限制 cache不超过页大小: 采用该方法而cache更大怎么办?
- 更高的相联度;页着色:同义地址的低位相同
- 虚拟cache虚拟标识 :在命中时,不需要从虚拟地址转换为物理地址。
- 同义问题:OS与用户程序使用不同的虚拟地址可能映射到同一物理地址,导致两个Cache副本
- 每次进程切换时,逻辑上必须刷新cache,否则会假命中
- 代价:刷新时间 + 来自空cache的“强制”缺失
- 解决方法:增加tag宽度,加上进程标识符PID识别进程
- 处理别名或同义synonyms: 两个不同VA映射到同一个PA
- 硬件别名消去:保证每个cache块有唯一的地址
- 软件方法:让所有别名地址的低位相同(称为页着色 page coloring)
- I/O 与cache交互:I/O一般使用物理地址,因此需要将PA映射为VA
- Cache 也可以使用虚拟地址
方法三:流水线化Cache访问
- 方法
- 写命中比读命中花费更长时间,因为在检查标识后才能写入数据。
- 将写操作分为两步:
- 第1步标识检查
- 第2步写数据
- 本次写的第2步与下次标识比较的第1步同时进行。
方法四:路预测
- 路预测:针对组相联
- 在cache中预留特殊的位,用来预测下一次访问cache可能在组中会用到的路或块。
- 减少命中时间,减少功耗
方法五:踪迹 cache
- 踪迹cache:块中是动态指令序列(包括发生分支),而不是限制指令在一个静态cache块中(空间局部性)。
- Cache块中包含了由CPU确定的要执行指令的动态踪迹,而不是仅由存储器确定的静态指令序列。
- 转移预测操作需要加入到cache,预测的地址必须单独验证以证明是一次有效的取操作。
主存储器与虚拟存储器
主存储器性能优化
- 主存储器是存储层次结构中cache的下一层——也称为内存
- 主存通常采用DRAM,caches采用SRAM。
- 主存的性能:延迟Latency :减小更困难(对cache很重要);带宽Bandwidth:用新的组织更容易改善带宽(单位 B/CLK)(对I/O重要)。对于2级cache,可以有更大的块容量。
- 本节分析如何组织主存以改善带宽,也减小了缺失代价

提高带宽方法一:增加主存储器带宽
- 双倍或四倍cache与主存之间的带宽
- 主存带宽也将增加双倍或四倍
- Amdahl’提出的经验规律:主存容量应该与CPU速度增长成线性比例

- 单体多字存储器的性能随着主存宽度的增加而改善,缺失代价减少,带宽增加。
- 代价是增加硬件
提高带宽方法二: 简单交叉存储器
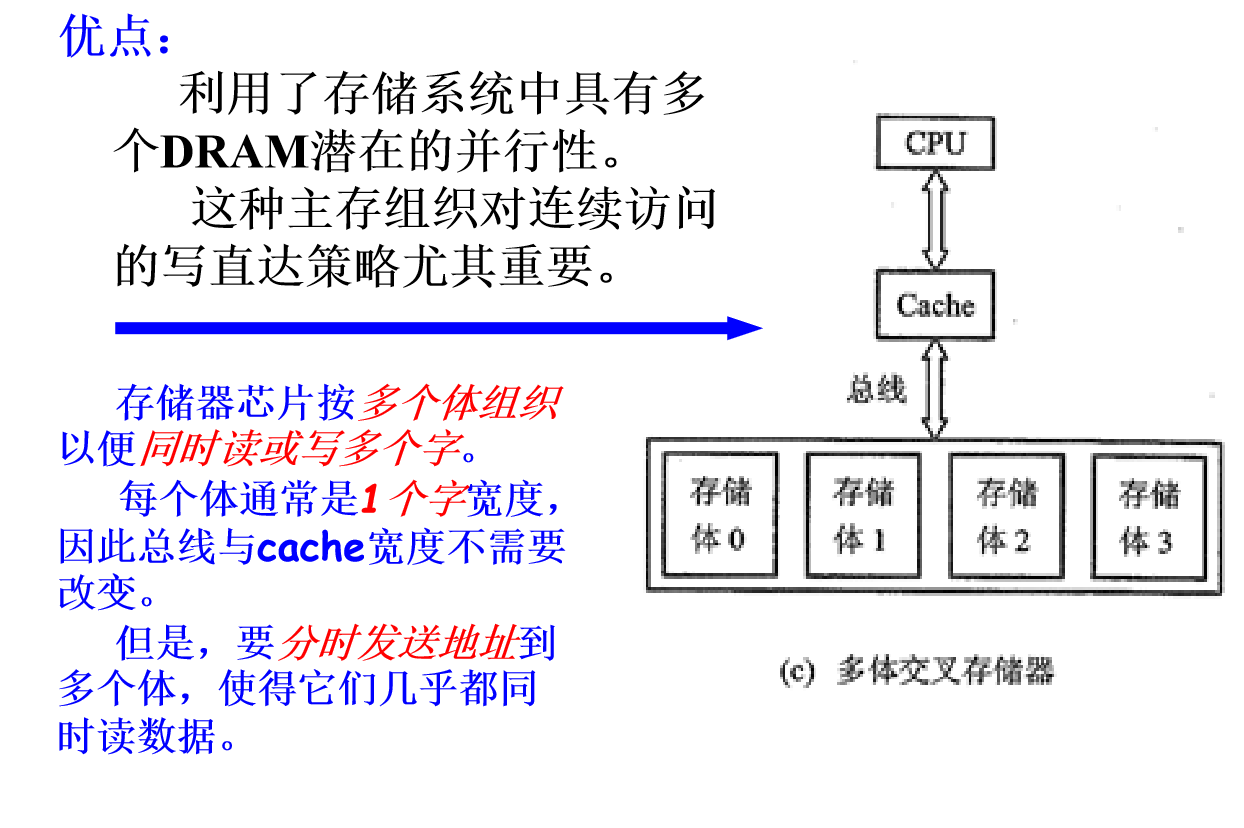
怎么决定是购买交叉存储器还是宽存储器?
答案:可以通过计算CPI比较不同方案的性能改善。
虚拟存储器
- 允许执行的一个程序
- 可以放在不连续的存储位置
- 不必全部放在主存中
- 允许计算机“欺骗”一个程序相信
- 存储器是连续的
- 存储空间比物理存储器更大,提供了很大存储空间的假象
- 虚拟存储器(VM)重要性
- 便宜 – 不必买许多RAM
- 解脱了程序员管理存储器资源的负担
- 允许多道程序设计,分时共享,保护
优点
主存(物理存储器)作为辅助存储器(磁盘)的一个Cache
具有更大和连续物理存储器的假象
程序按“页”或“段”重定位
多道程序中的保护
虚拟地址:程序员使用的地址
虚拟地址空间:虚拟地址的集合
存储器地址:物理存储器中的字地址,也称为“物理地址” 或“实际地址”
虚拟存储器系统分为两类:
页---- 固定大小的块 页式虚拟存储器
段---- 可变大小的块 段式虚拟存储器
- 映像规则:考虑块的高缺失代价和需要更低的缺失率,OS允许块放在主存的任意位置
- 查找方法:要查找块,段式可在段的物理地址上加上偏移地址就得到物理地址;页式可在物理页地址后简单拼接偏移地址就得到物理地址。
- 替换算法:虚拟存储器缺失时,为了最小化页缺失率,几乎所有操作系统都替换最近最少使用(LRU-least-recently used)的块。按照局部性原则,被替换的块正是将来很少可能用到的块。
- 写策略:执行写操作时,由于访问磁盘代价过高,写策略采用写回方式,并且只有块被修改后才允许写回磁盘

快速地址转换技术
- 页表存放主存中:
- 页表很大,可能分页;
- 从主存取数据、存结果、取指令,至少需要2次访问主存:
- 一次按虚拟地址访存从页表获得物理地址,二次访存获得数据。
- 访存时间太长!减少虚拟地址转换为物理地址的时间。
- 解决方法:
- 使用一个特殊的cache,存放最近用过的页表项 。这个cache就是TLB( Translation Lookaside Buffer )变换旁路缓冲器。
虚拟存储器与cache综合的地址计算
虚拟地址到物理地址的转换:

例题

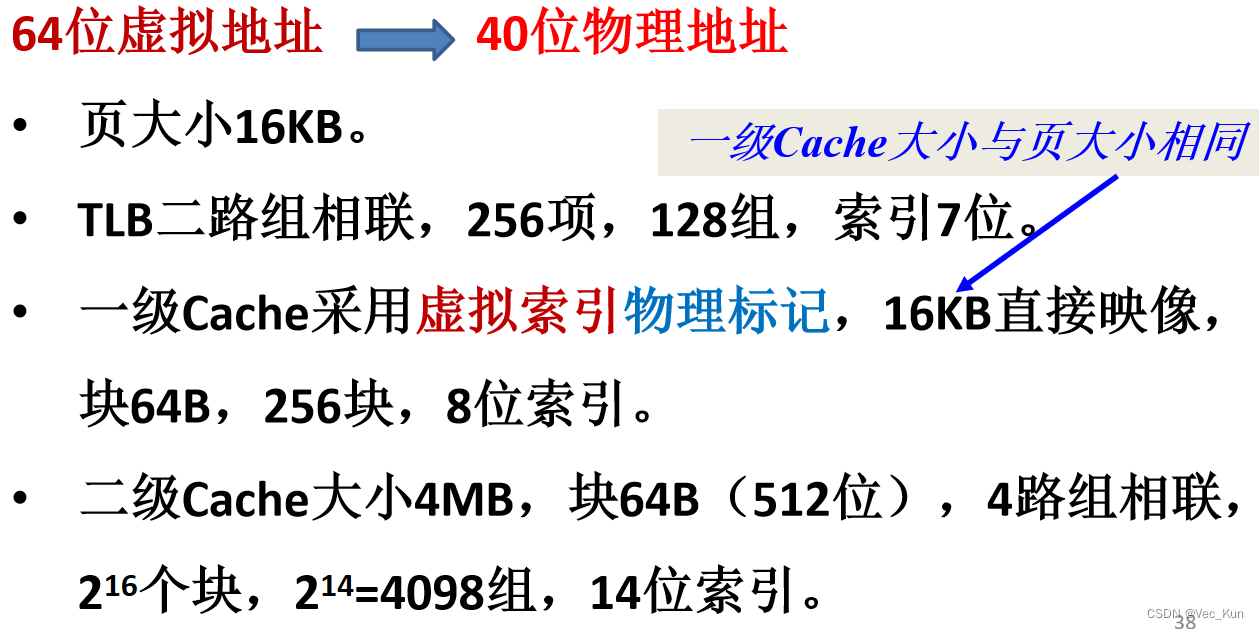

如果一级Cache缺失,物理地址将继续用于二级Cache访问
本章小结
- Cache存储器的三种映像方式(全相联、直接映像,组相联)
- 物理地址与Cache地址的映射计算
- Cache的映像规则,块标识,替换算法,写策略,性能计算
- Cache性能优化的方法(减少缺失率4种,减少缺失代价5种,减少缺失率或缺失代价3种,减少命中时间5种)
- 存储器层次结构概念,CPU—Cache—主存之间的信息访问单位
- Cache的映像规则,块标识,替换算法,写策略
- Cache性能优化的方法,减少缺失率4种,减少缺失代价5种,减少缺失率或缺失代价3种,减少命中时间5种
- 主存增加带宽(减少缺失代价):增加主存宽度,简单交叉存储器
- 页式虚拟存储器,TLB原理及基本结构,一级Cache采用虚拟索引的VM如何实现虚拟地址转换为物理地址