在目标检测网络里加注意力机制已经是很常见的了,顾名思义,注意力机制是指在全局图像中获得重点关注的目标,常用的注意力机制有SE、CA、ECA、CBAM、GAM、NAM等。
1、SE模块
论文:https://arxiv.org/pdf/1709.01507.pdf
参考:CV领域常用的注意力机制模块(SE、CBAM)_学学没完的博客-CSDN博客_se注意力机制
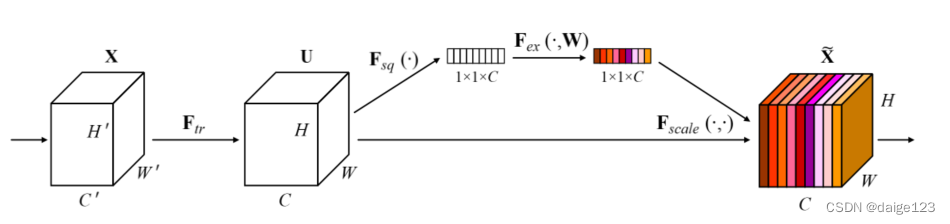
SE模块主要包括Squeeze和Excitation两个部分
Squeeze是Global pooling,对特征进行压缩;
Excitation是通过两层全连接结构得到feature map中每个通道的权值,并将加权后的feature map作为下一层网络的输入。
在ECA的论文中表示,SE结构的降维操作对通道注意有副作用。
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
2、CA模块(Coordinate attention)
论文:https://arxiv.org/abs/2103.02907
参考:CA(Coordinate attention) 注意力机制 - 知乎 (zhihu.com)
CVPR 2021 | 即插即用! CA:新注意力机制,助力分类/检测/分割涨点!_Amusi(CVer)的博客-CSDN博客
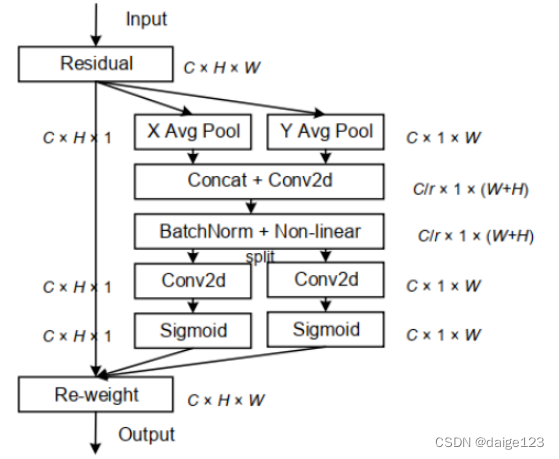
CVPR 2021 | 即插即用! CA:新注意力机制,助力分类/检测/分割涨点!_Amusi(CVer)的博客-CSDN博客CA对宽度和高度两个方向分别全局平均池化,分别获得在宽度和高度两个方向的特征图,然后将两个方向的特征图concat,然后送入共享卷积将维度降为C/r,再通过批量归一化处理和激活函数后得到特征图。
import torch
from torch import nn
class CA_Block(nn.Module):
def __init__(self, channel, h, w, reduction=16):
super(CA_Block, self).__init__()
self.h = h
self.w = w
self.avg_pool_x = nn.AdaptiveAvgPool2d((h, 1))
self.avg_pool_y = nn.AdaptiveAvgPool2d((1, w))
self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel//reduction, kernel_size=1, stride=1, bias=False)
self.relu = nn.ReLU()
self.bn = nn.BatchNorm2d(channel//reduction)
self.F_h = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False)
self.F_w = nn.Conv2d(in_channels=channel//reduction, out_channels=channel, kernel_size=1, stride=1, bias=False)
self.sigmoid_h = nn.Sigmoid()
self.sigmoid_w = nn.Sigmoid()
def forward(self, x):
x_h = self.avg_pool_x(x).permute(0, 1, 3, 2)
x_w = self.avg_pool_y(x)
x_cat_conv_relu = self.relu(self.conv_1x1(torch.cat((x_h, x_w), 3)))
x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([self.h, self.w], 3)
s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))
s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))
out = x * s_h.expand_as(x) * s_w.expand_as(x)
return out
if __name__ == '__main__':
x = torch.randn(1, 16, 128, 64) # b, c, h, w
ca_model = CA_Block(channel=16, h=128, w=64)
y = ca_model(x)
print(y.shape)3、ECA模块
论文:(PDF) ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks (researchgate.net)
参考:注意力机制(SE、Coordinate Attention、CBAM、ECA,SimAM)、即插即用的模块整理_吴大炮的博客-CSDN博客_se注意力机制
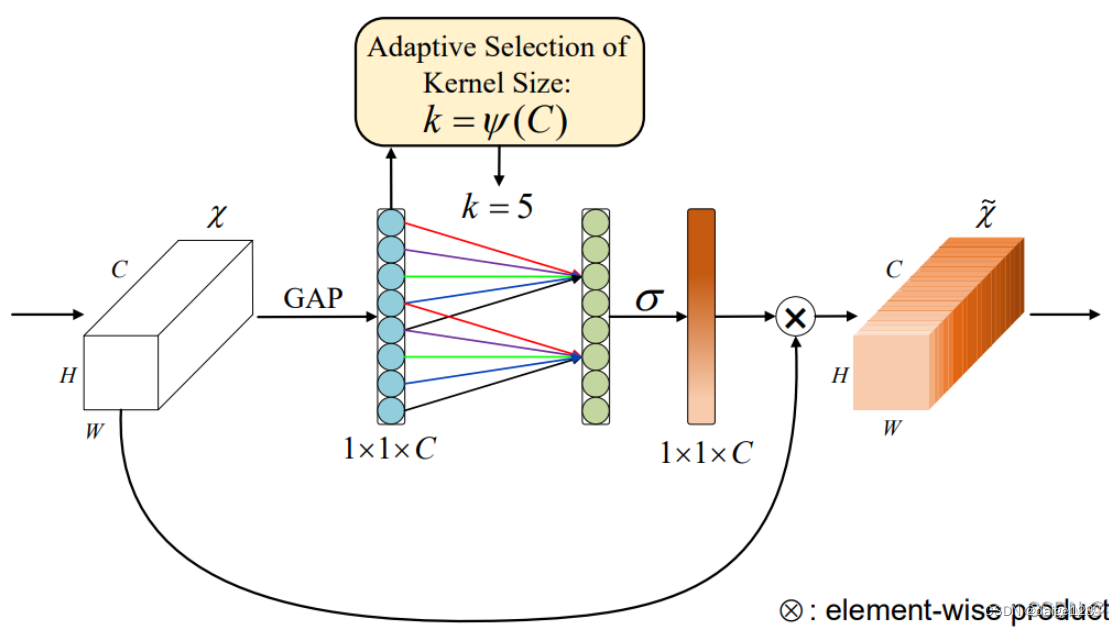
ECA首先通过全局平均池化,然后利用卷积进行特征提取,实现跨通道的交互。
4、CBAM模块
论文: [1807.06521] CBAM:卷积块注意模块 (arxiv.org)
参考:注意力机制之《CBAM: Convolutional Block Attention Module》论文阅读_落樱弥城的博客-CSDN博客


CBAM模块分为channel-wise attention和spatial attention,通道注意力和SE结构相同,只是加了一个maxpooling,中间共享一个MLP,最后将两部分的输出相加经过sigmoid。
空间注意力使用平均池化和最大池化对输入特征层进行通道压缩,在使用卷积操作。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
5、GAM模块
论文:https://paperswithcode.com/paper/global-attention-mechanism-retain-information
GAM注意力机制分为两个模块:CAM和SAM,通道注意是学习不同通道的权值,并用权值对不同通道进行多重划分,空间注意关注目标在图像上的位置信息,并通过空间特征的加权选择性的聚焦每个空间的特征。

通道注意力模块首先重新排列图像三维信息,然后通过MLP来放大跨维通道空间,如图6所示。在空间注意子模块中,使用两个卷积层进行空间信息融合,如图7所示,这样使通道更能关注空间信息。

import torch.nn as nn
import torch
class GAM_Attention(nn.Module):
def __init__(self, in_channels, out_channels, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(in_channels, int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(in_channels / rate), in_channels)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(in_channels, int(in_channels / rate), kernel_size=7, padding=3),
nn.BatchNorm2d(int(in_channels / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(int(in_channels / rate), out_channels, kernel_size=7, padding=3),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
out = x * x_spatial_att
return out
if __name__ == '__main__':
x = torch.randn(1, 64, 32, 48)
b, c, h, w = x.shape
net = GAM_Attention(in_channels=c, out_channels=c)
y = net(x)
6、NAM模块
论文:https://arxiv.org/abs/2111.12419
参考:https://cloud.tencent.com/developer/article/1909196
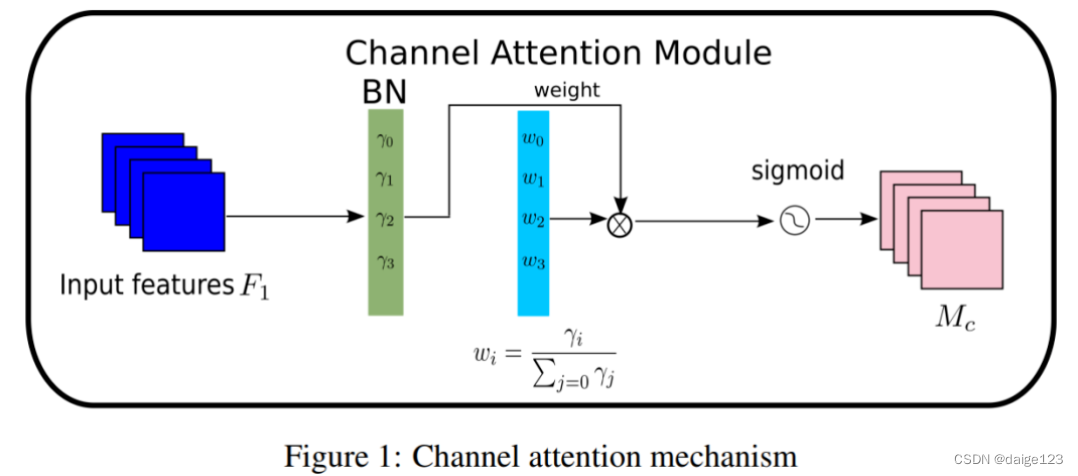
NAM采用CBAM的模块整合,重新设计了通道和空间注意子模块。在通道注意模块中使用批归一化中的比例因子。并且将其也运用到空间维度,来衡量像素的重要性。

import torch.nn as nn
import torch
from torch.nn import functional as F
# 具体流程可以参考图1,通道注意力机制
class Channel_Att(nn.Module):
def __init__(self, channels, t=16):
super(Channel_Att, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x
x = self.bn2(x)
# 式2的计算,即Mc的计算
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
x = x.permute(0, 2, 3, 1).contiguous()
x = torch.mul(weight_bn, x)
x = x.permute(0, 3, 1, 2).contiguous()
x = torch.sigmoid(x) * residual #
return x
class Att(nn.Module):Yichao Liu, 2 months ago: • Add files via upload
def __init__(self, channels,shape, out_channels=None, no_spatial=True):
super(Att, self).__init__()
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
x_out1=self.Channel_Att(x)
return x_out1