一、修改现有的网络模型
import torchvision
from torch import nn
# pretrained 为True时会自动下载模型所对应的权重
vgg16_false=torchvision.models.vgg16(pretrained=False)
vgg16_true=torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
# 向神经网络中添加训练层数
vgg16_true.add_module("linex",nn.Linear(1000,10))
print(vgg16_true)
# 修改神经网络模型中的,某一层
vgg16_false.classifier[6]=nn.Linear(4096,10)
print(vgg16_false)
这里加载了两个模型一个是带预训练权重的,一个是不带的。
pretrained为True时

pretrained为False时

我们可以通过上述的代码打印一下网络结构:
model1
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
VGG(
(features): Sequential(
...
...
...
(linex): Linear(in_features=1000, out_features=10, bias=True)
)
VGG(
(features): Sequential(
...
...
...
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
...
...
...
(6): Linear(in_features=4096, out_features=10, bias=True)
)
)
Process finished with exit code 0
可以发现vgg16_true模型多了一层 (linex): Linear(in_features=1000, out_features=10, bias=True)
vgg16_false中的
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
...
...
...
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
变成了
(classifier): Sequential(
...
...
...
(6): Linear(in_features=4096, out_features=10, bias=True)
)
二、模型的保存
训练好的模型要进行保存,模型的参数需要保存,模型的结构需要保存
最常用的有两种方式
- ①直接保存torch.save()
该方法有弊端,如果是自己搭建的模型,在加载的时候必须要有网络模型的声明
将模型与保存的文件名传进去,该方式会将模型的参数与结构都保存下来 - ②使用torch.save(vgg16.state_dict(),“文件名”)进行保存
该方法会将模型的参数进行保存
import torch
import torch.nn as nn
import torchvision
# 加载没有经过训练的vgg16模型
vgg16=torchvision.models.vgg16(pretrained=False)
# 第一种模型保存方式(结构参数都进行保存)
torch.save(vgg16,"vgg16_save.pth")
# 第二种模型保存方式(只保存参数)
torch.save(vgg16.state_dict(),"vgg16_dict.pth")
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
def forwark(self):
pass
三、模型的加载
也是两种方式,分别对应上述两种保存方式。
import torch
from torch import nn
import torchvision
vgg=torchvision.models.vgg16(pretrained=False)
# 第一种加载方式
model_load=torch.load("vgg16_save.pth")
print(model_load)
# 第二种加载方式
# 打印model_load1是一些参数,没有目录结构
model_load1=torch.load("vgg16_dict.pth")
# 将参数传进加载函数中
model_load1=vgg.load_state_dict(model_load1)
print(model_load1)
或者直接使用二进制方式打开文件,将数据加载进来。
with open("pth/resnet18_200.pth",'rb') as f:
resnet18.load_state_dict(torch.load(f))
四、模型的评估
模型的好坏通常需要使用测试集进行测试,tensor给出了很方便的测试方式。
可以使用argmax()方法,很容易的得出每行最高概率或者每列最高概率。
import torch
# output可以视为两个图片进行训练后得到的在三个类别概率分别是多少
# 进行训练之前会将图像数据,与标签放在两个数组内并对应
output= torch.tensor([
[0.1,0.3,0.2],
[0.3,0.4,0.7]])
# 获取到的是一列或一行数据对应概率值最大的位置对应的位置下标(以这个最大概率预测这个图像是什么)
# 参数为1的时候是对行进行操作
# 参数为0的时候会对列进行操作
print(output.argmax(1))
#这个传进去图像对应的类别(两个样本都是1)
targets=torch.tensor([1,1])
# 打印出预测准确的数据个数
true=(output.argmax(1)==targets).sum()
# 一个样本概率最高位置的下标是否与样本所打标签相同(相同代表预测正确)
# 可以通过下面方式批量对比,然后得出准确率
print((output.argmax(1)==targets).sum())
# 得出正确率
print(int(true)*100/2,'%')
五、训练模型的完整套路
大致可以分为以下几步:
- 加载数据
- 构建网络模型
- 设置训练参数
- 开始训练(如果想接着之前的训练可以先加载模型)
- 模型保存与评估
import os
import torch.optim
import torchvision
# 准备数据集
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from Model.model import Model
import torch.nn as nn
basepath=os.path.split(os.getcwd())[0]
# ----------------------------------------加载数据-----------------------------#
train_data=torchvision.datasets.CIFAR10(
root=basepath+r"\数据集",
train=True,
transform=torchvision.transforms.ToTensor(),
download=True)
test_data=torchvision.datasets.CIFAR10(
root=basepath+r"\数据集",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True)
# 查看需要训练的数据长度
train_data_size=len(train_data)
test_data_size=len(test_data)
print("训练集长度",train_data_size)
print("测试集长度",test_data_size)
# 加载数据集
train_dataloader=DataLoader(train_data,64)
test_dataloader=DataLoader(test_data,64)
# ------------------------------构建网络模型-----------------------------------#
# 创建网络模型
myModel=Model()
# 损失函数
loss_F=nn.CrossEntropyLoss()
# 优化器
learn_rate=0.01
optimizer=torch.optim.SGD(myModel.parameters(),lr=learn_rate)
writer=SummaryWriter(basepath+r"\logss\log_model")
# ------------------------------设置训练参数-----------------------------------#
# 记录训练次数
total_train_step=0
# 记录测试次数
total_test_step=0
# 训练的轮数
epoch=10
# 训练数据在所有类别中最大概率对应的类别与实际类别可以对照上的总数
total_true=0
# ----------------------------------开始训练-----------------------------------#
# ------------------
# 开始训练
# myModel.train()
# 开始测试
# myModel.eval()
# 这段话只针对某些神经层有意义
# ------------------
for i in range(epoch):
print(f"-------------第{
i+1}轮训练开始----------------")
total_train_step = 0
total_test_step = 0
# 使用训练数据集对模型进行训练
for data in train_dataloader:
# 数据通过神经网络
imgs,targets=data
output=myModel(imgs)
loss=loss_F(output,targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step=total_train_step+1
if total_train_step%100==0:
# loss.item会将数值打印出来,不会带多余的东西
print(f"训练{
total_train_step}次,损失{
loss.item()}")
# 将数据加入到图像中
writer.add_scalar("train_loss",loss.item(),total_train_step)
# 使用测试数据集对模型进行测试,将得到的数据以图像的形式展示出来以及模型准确率评估
total_test_loss=0
with torch.no_grad():
for data in test_dataloader:
imgs,targets=data
# 使用损失函数测试模型的好坏
output=myModel(imgs)
loss=loss_F(output,targets)
total_test_loss=total_test_loss+loss.item()
# 获取本轮数据能够对应的样本数
temp_true=(output.argmax(1)==targets).sum()
# 获取所有数据能够对应上的样本数
total_true=total_true+temp_true
print(f"整体测试集上的损失{
total_test_loss}")
print(f"整体测试集上的正确率{
total_true/test_data_size}")
writer.add_scalar("test_loss",total_test_loss,total_test_step)
# 对训练好的模型进行测试,将正确率加入到图像中显示
writer.add_scalar("test_accuracy",total_true/test_data_size,total_test_step)
total_test_step=total_test_step+1
# 模型的保存
# 保存模型
torch.save(myModel,os.getcwd()+rf"\Model\model_01\model_{
i}.pth")
# 保存模型对应的参数
with open(os.getcwd()+rf"\Model\model_02.model_{
i}.txt",'a') as f:
f.write(str(total_test_loss))
print("模型已保存!")
writer.close()
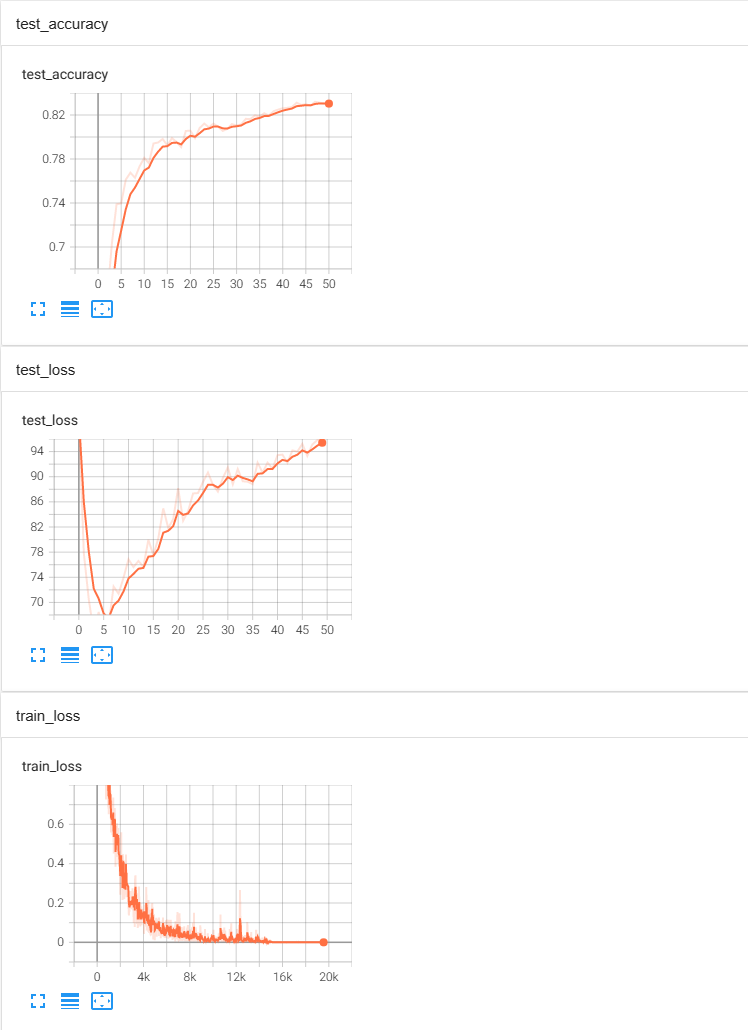
使用tensorboard查看训练过程。(过拟合大王哈哈哈哈)
六、使用GPU加速模型的训练
使用GPU训练我们的模型,可以提高很快的速度。
第一种调用GPU的方式(先判断是否有可用GPU)
# 创建网络模型
myModel=Model()
if torch.cuda.is_available():
myModel=myModel.cuda()
# 损失函数
loss_F=nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_F=loss_F.cuda()
第二种调用GPU的方式(常用)
# gpu cuda均可以加入其中,如果有多个gpu可以指定每一步使用那个gpu
# 先判断有没有可用GPU
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载模型到GPU
# 创建网络模型
myModel=Model()
myModel=myModel.to(device)
# 损失函数
loss_F=nn.CrossEntropyLoss()
loss_F=loss_F.to(device)
还有很多使用方式,大家可以在网上自己搜一下。通过这两种方式我们可以轻松地实现数据在GPU与CPU之间进行转换。
七、模型训练完整的验证套路
基本步骤是:
- 加载测试数据集
- 加载训练权重到模型
- 要测试的图片通过模型预测
- 对比预测出的标签与原始标签是否一致
- 得出准确率
import os.path
import torch
import torch.nn as nn
from torchvision import transforms
import torchvision
from Model.model import Model
from PIL import Image
basepath=os.path.split(os.getcwd())[0]
# 处理要进行测试的数据
image_path1=basepath+r"\数据集\air.png"
image_path2=basepath+r"\数据集\dog.png"
image1=Image.open(image_path1)
image2=Image.open(image_path2)
# png有4种颜色通道,RGB还有一个透明度通道(要将png图片转换成rgb)
image1=image1.convert("RGB")
image2=image2.convert("RGB")
transform=transforms.Compose([transforms.Resize((32,32)),transforms.ToTensor()])
img1=transform(image1)
img2=transform(image2)
# 导入训练好的模型
# 如果是通过GPU训练的模型导入的时候要进行 map_location=torch.device('cpu')参数的传递
print(basepath+r"\3.模型的训练\Model\model_01\model_9.pth")
myModel=torch.load(basepath+r"\3.模型的训练\Model\model_01\model_9.pth",map_location=torch.device('cpu'))
img1=torch.reshape(img1,(1,3,32,32))
img2=torch.reshape(img2,(1,3,32,32))
myModel.eval()
# 不进行反向传播,这里是测试不是训练
with torch.no_grad():
output1=myModel(img1)
output2=myModel(img2)
print(output1.argmax(1).item())
print(output2.argmax(1).item())
'''
0 飞机
5 狗
'''
'''
CIFAR10包含哪几类 这10类分别是airplane (飞机),automobile(汽车),bird(鸟),cat(猫),deer(鹿),
dog(狗),frog(青蛙),horse(马),ship(船)和truck(卡车)
'''