质量控制和质量保证的重要性是不言而喻的。因此,缺陷检测在很多行业中有着大量的需求、并且发挥着极其重要的作用。例如,在制造业中,通过检测生产线上的异常情况,企业可以确保只有最优质的产品能够出厂。而在医疗行业,通过医学成像及早发现异常有助于医生对患者进行准确诊断。
以上场景中的任何差错都会导致严重后果。正因如此,许多行业开始告别易受主观因素影响而出错的人工检查和维护,转而引入日新月异的计算机视觉和深度学习技术,实施自动化异常检测。
如要真正增强质量控制和质量保证,人工智能必须利用数据量丰富且平衡的数据集。虽然如今有大量良好的数据样本,但有时缺陷数据的不足很难帮助工业和医疗行业做出准确和有效的预测。
克服数据集挑战
基于监督式学习的方法利用足够的注释异常样本,通常可用于实现令人满意的异常检测结果。但如果数据集是缺乏异常类别代表性样本的不平衡数据集,结果会怎样?当缺陷可以是任何类型的形状时,您如何定义异常的边界?
解决这些问题的一个方法是无监督异常检测,它几乎不需要标注。无监督异常检测在训练阶段完全依赖正常样本,可以通过与所学的正常数据分布进行比较来识别异常样本。
开源的端到端异常检测库 Anomalib便是一种基于无监督异常检测算法的开源库,它提供了可根据特定用例和要求定制的先进异常检测算法。
Anomalib 在制造业中的应用——用自定义数据训练和部署缺陷检测模型
让我们看一个具有彩色立方体的生产线示例。其中一些立方体会有洞或缺陷,需要从传送带上取下。

对于这种场景下的异常检测,我们没有可用于在边缘训练模型的硬件加速器。我们也不能假设已经为边缘训练收集了数千幅图像、尤其是有缺陷的图像。此外,预计不会像真实的制造场景一样,存在大量缺陷已知的情况。
鉴于这些初始条件,我们的一个目标是在边缘实现更快的训练速度,并进行高精确和高效的异常检测。有一点需要记住,即如果有任何外部条件变化 - 如照明、摄像头或异常情况,我们将不得不重新训练模型。因此,进行不太费事的重新训练是有必要的。最后,为了确保模型在真实的制造用例中发挥作用,我们必须保证使用异常检测模型获得精确的推理结果。
借助内容广泛的 Anomalib 库,我们可以设计、实施和部署无监督异常检测模型,覆盖从数据收集到边缘应用在内的流程,从而满足我们的所有要求。
以下所有步骤的源代码都在这个入门 notebook 里。接下来我们逐步来分解看看都有哪些步骤,可以让你用自己自定义的数据集,完成无监督缺陷检测模型的训练和部署。
安装:
按照以下步骤使用源文件安装 Anomalib:
1. 使用 Python 3.8 版本创建运行 Anomalib + Dobot DLL 的环境
- 对于 Windows,使用以下代码:
python -m venv anomalib_env
anomalib_env\Scripts\activate- 对于 Ubuntu:
python3 -m venv anomalib_env
source anomalib_env/bin/activate2.从 GitHub 存储库中安装 Anomalib 及 OpenVINO™ 要求(在这篇博文中,我们将不使用 pip 安装命令):
python –m pip install –upgrade pip wheel setuptools
git clone https://github.com/openvinotoolkit/anomalib.git
cd anomalib
pip install -e . [openvino]3.安装 Jupyter Lab 或 Jupyter Notebook:
pip install notebook
pip install ipywidgets4.然后连接您的 USB 摄像头,使用简单的摄像头应用验证它在正常工作。然后,关闭该应用。
可选:如果您可以访问 Dobot,请实施以下步骤:
- 安装 Dobot 要求(更多信息请参考Dobot文档)。
- 检查 Dobot 的所有连接状态,并使用 Dobot Studio 验证它在正常工作。
- 将通风配件安装在 Dobot 上,并使用 Dobot Studio 验证它在正常工作。
- 在 Dobot Studio中,点击“Home”按钮,找到:
- 校准坐标:立方体阵列的左上角初始位置。
- 位置坐标:机械臂应将立方体放在传送带上方的位置。
- 异常坐标:释放异常立方体的位置。
- 然后在 notebook 中替换这些坐标。有关该步骤的更多说明,请参考自述文件。
5.如需使用机器人运行 notebook,从这里下载Dobot API 和驱动程序文件,并将它们添加到存储库 Anomalib 文件夹的 notebooks/500_uses_cases/dobot 中。
注:如果没有机器人,您可以转到另一个 notebook,如 501b notebook,通过这个链接下载数据集,并在那里尝试训练和推理。
Notebook 的数据采集和推理:
下面,我们需要使用正常的数据集创建文件夹。在这个示例中,我们创建了一个彩色立方体的数据集,并为异常情况添加一个黑色圆圈贴纸,以模拟盒子上的洞或缺陷。对于数据采集和推理,我们将使用 501a notebook。
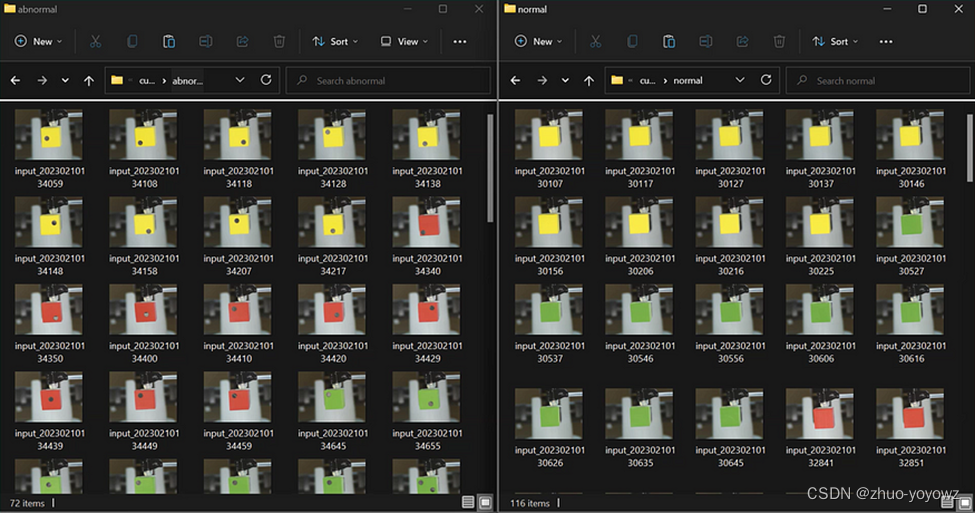
在采集数据时,请务必将 acquisition 变量设置 为 True 来运行notebook,并为没有异常的数据定义“正常”文件夹,为异常图像定义“异常”文件夹。数据集将直接在 Anomalib 克隆的文件夹中创建,所以我们将看到 Anomalib/dataset/cubes 文件夹。
如果您没有机器人,您可以修改代码以保存图像或使用下载的数据集进行训练。
推理:
对于推理,acquisition 变量应该是 False,我们不会保存任何图像。我们将读取采集到的视频帧,使用 OpenVINO™ 运行推理,并决定放置立方体的位置:对于正常立方体,放置在传送带上;对于异常立方体,放置在传送带外。
我们需要识别采集标记 — 采集模式为 True,推理模式为 False。在采集模式下,要注意是创建正常还是异常文件夹。例如,在采集模式下,notebook 会将每张图像保存在anomalib/datasets/cubes/{FOLDER}中,以便进一步训练在推理模式下,notebook 不会保存图像;它将运行推理并显示结果。
训练:
对于训练,我们将使用 501b notebook。在这个 notebook 中,我们将使用 PyTorch Lighting,并使用“Padim”模型进行训练。这种模型有几个优点:我们不需要 GPU,只用 CPU 就可以完成训练过程,而且训练速度也很快。
现在,让我们深入了解一下训练 notebook!
- 导入
在这一部分,我们将解释用于该示例的软件包。我们还将从 Anomalib 库中调用需要使用的软件包。
- 配置:
有两种方法来配置 Anomalib 模块,一种是使用配置文件,另一种是使用 API。最简单的方法是通过 API 查看该库的功能。如果您希望在您的生产系统中实施 Anomalib,请使用配置文件(YAML 文件),它是核心训练与测试进程,包含数据集、模型、试验和回调管理。
在接下来的部分,我们将描述如何使用 API 配置您的训练。

- 数据集管理器:
通过 API,我们可以修改数据集模块。我们将准备数据集路径、格式、图像大小、批量大小和任务类型。然后,我们使用以下代码将数据加载到管道中。
i, data = next(enumerate(datamodule.val_dataloader()))- 模型管理器:
对于异常检测模型,我们使用 Padim,您也可以使用其他 Anomalib 模型,如:CFlow、CS-Flow、DFKDE、DFM、DRAEM、FastFlow、Ganomaly Patchcore、Reverse Distillation和 STFPM。此外,我们使用 API 设置了模型管理器;使用 anomalib.models 导入 Padim。
- 回调(Callbacks)管理器:
为了适当地训练模型,我们需要添加一些其他的“非基础”逻辑,如保存权重、尽早终止、以异常分数为基准以及将输入/输出图像可视化。为了实现这些,我们使用回调Callbacks。Anomalib 有自己的Callbacks,并支持 PyTorch Lightning 的本地callbacks。通过该代码,我们将创建在训练期间执行的回调列表。
- 训练:
在设置数据模块、模型和callbacks之后,我们可以训练模型了。训练模型所需的最后一个组件是 pytorch_lightning Trainer 对象,它可处理训练、测试和预测管道。点击此处,查看 notebook 中的 Trainer 对象示例。
- 验证:
我们使用 OpenVINO 推理进行验证。在之前的导入部分,我们导入了 anomalib.deploy 模块中的 OpenVINOInferencer。现在,我们将用它来运行推理并检查结果。首先,我们需要检查 OpenVINO 模型是否在结果文件夹中。
- 预测结果:
为了实施推理,我们需要从 OpenVINOinference(我们可在其中设置 OpenVINO 模型及其元数据)中调用 predict 方法,并确定需要使用的设备:
predictions = inferencer.predict(image=image)预测包含与结果有关的各种信息:原始图像、预测分数、异常图、热图图像、预测掩码和分割结果。根据您要选择的任务类型,您可能需要更多信息。

最后,我们采用 Dobot 机器人的缺陷检测用例基本是这样的。

使用您自己的数据集的技巧和建议
数据集转换:
如果您想提高模型的准确性,您可以在您的训练管道中应用数据转换。您应该在 config.yaml 的 dataset.transform_config 部分提供增强配置文件的路径。这意味着您需要有一个用于 Anomalib 设置的 config.yaml 文件,以及一个可供 Anomalib config yaml 文件使用的单独 albumentations_config.yaml 文件。
在这个讨论贴中,您可以学习如何将数据转换添加到您的实际训练管道。
强大的模型:
异常检测库并非无所不能,在碰到麻烦的数据集时也可能会失效。好消息是:您可以尝试 13 个不同的模型,并能对每个实验的结果进行基准测试。您可以将基准测试入口点脚本用于其中,并将配置文件用于基准测试目的。这将帮助您为实际用例选择最佳模型。
如需更多指南,请查看“操作指南”。
下一步
如果您正在使用 Dobot,并希望通过该 notebook 看到更多探讨其使用场景的文章,请将您的意见或问题添加到下方评论中。如果您在 Anomalib 安装过程中遇到任何问题或错误,请在我们的GitHub 仓库中提交。
我们期待看到Anomalib在更多场景中的使用情况,欢迎大家一起讨论分享。