引言
随着科技的飞速发展,人工智能逐渐成为我们生活中不可或缺的一部分。尤其是在自然语言处理领域,大语言模型的出现让我们对AI有了全新的认识。那么,什么是大语言模型呢?它是如何工作的,又能为我们的生活带来哪些便利呢?接下来,就让我们一起揭开大语言模型的神秘面纱!
什么是大语言模型?
大语言模型是一种基于神经网络的自然语言处理技术,它可以理解和生成人类语言,从而实现智能对话、文本生成、翻译等功能。其中,最为知名的当属OpenAI推出的GPT系列模型。GPT全称为“生成预训练Transformer”,这一模型在近年来取得了显著的成果,使得机器能够理解人类语言,甚至能写出一些具有创造性的文本。
大语言模型的工作原理
大语言模型基于深度学习技术,利用神经网络对大量文本数据进行训练。训练过程中,模型会不断地学习语言的规律,包括词汇、语法、逻辑等方面。通过这种学习,模型逐渐掌握了人类语言的复杂性,从而可以生成符合语言规则的文本。
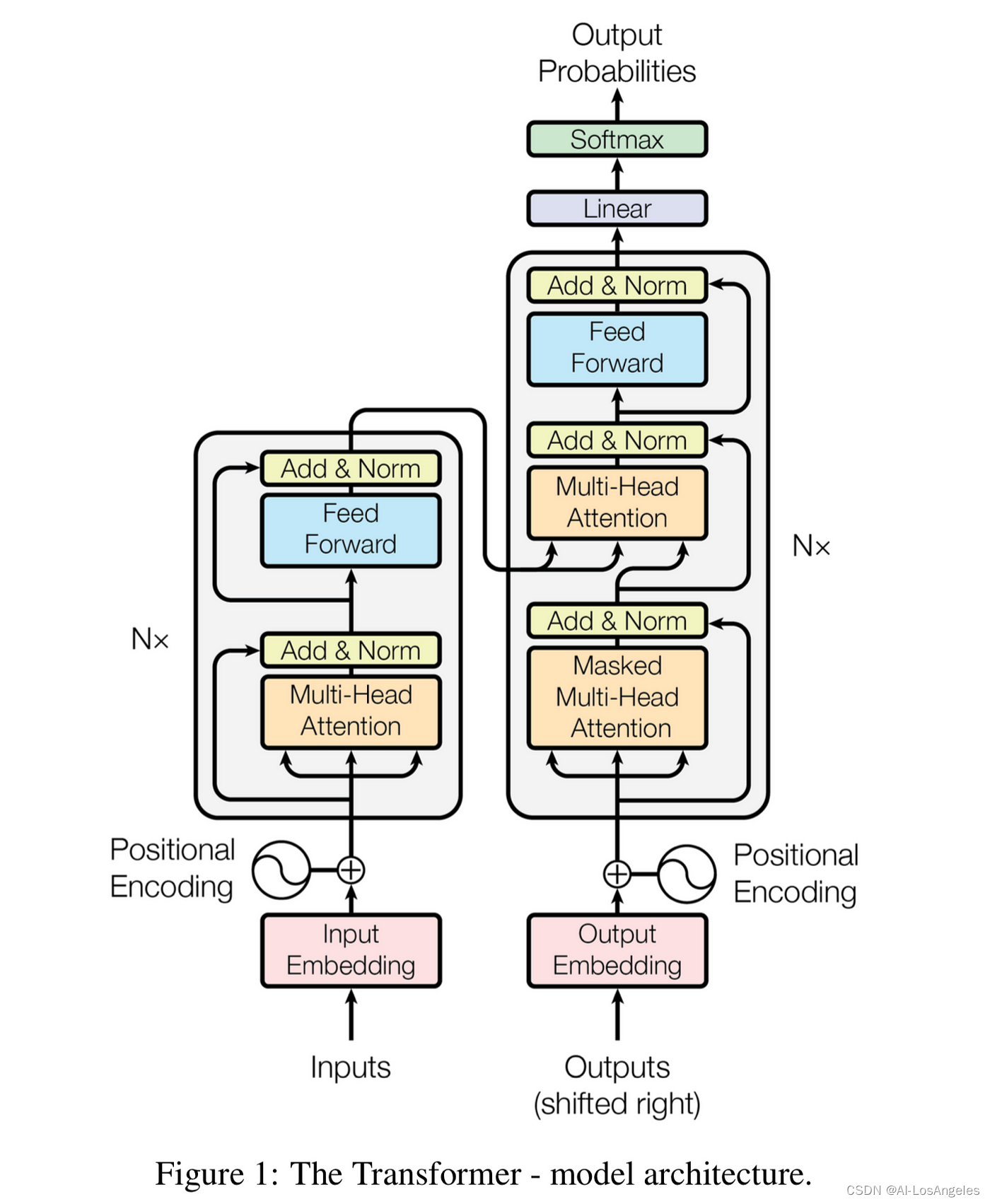
模型的核心结构是“Transformer”,这是一种特殊的神经网络架构,它采用自注意力机制来捕捉文本中的长距离依赖关系。自注意力机制使得模型能够关注到输入文本中的每一个单词,并为每个单词分配不同的权重,以此来实现更加精确的文本生成和理解。
大语言模型的应用
借助大语言模型,我们可以实现以下功能:
智能问答:大语言模型可以根据用户的问题提供准确的答案,实现智能客服、知识问答等功能。
文本生成:大语言模型可以生成具有连贯性和创意的文章、报告、博客等,帮助人们提高写作效率。
翻译:大语言模型具有强大的翻译能力,可以在多种语言之间实现高质量的翻译。
情感分析:大语言模型可以对文本进行情感分析,从而帮助企业了解用户的需求和反馈。
文本摘要:大语言模型可以自动生成文本摘要,方便用户快速了解文章的主要内容。
语音识别和合成:大语言模型还可以应用于语音识别和语音合成技术,让机器能够更好地理解和生成人类语音。
大语言模型的挑战与未来发展
虽然大语言模型在很多方面取得了显著成果,但它仍然面临一些挑战,例如:
模型偏见:由于训练数据中可能存在偏见,大语言模型在生成文本时也可能表现出一定程度的偏见。
安全性问题:恶意用户可能利用大语言模型进行不道德或非法的行为,如生成虚假信息或不当言论。
能耗问题:大语言模型的训练和运行需要大量的计算资源,这可能导致能耗问题。
面对这些挑战,研究人员正在不断努力改进大语言模型,以实现更高的准确性、安全性和可解释性。随着技术的不断进步,大语言模型有望为人类带来更多的便利和惊喜。
结语
大语言模型作为人工智能的重要成果,已经在许多领域展现出了强大的潜力。随着研究的深入,大语言模型未来有望为我们的生活带来更多的改变。让我们拭目以待,期待大语言模型为人类的发展带来更多的惊喜!
