yolo2目标检测 object detection从原理到实践
本文主要介绍经典的目标检测算法yolo2的原理以及对应实现,实现地址见github:https://github.com/mjDelta/yolo2-keras。觉得实现效果不错的同学,欢迎star,fork,follow。
原理部分
笔者觉得要理解yolo2的原理,最主要理解anchor box的概念以及作用,所以整篇博文重点讲解anchor box。
anchor box
首先,anchor box 是什么?anchor box是作者提前对训练集进行聚类得到的五个bounding box 。通过实验,作者发现k=5时,能够在模型复杂度和准确率之间达到一个tradeoff。
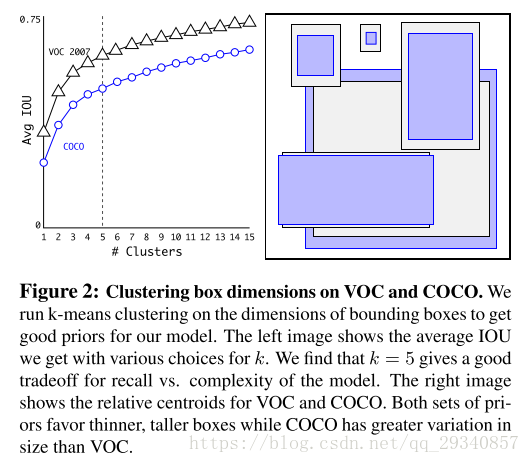
其次,anchor box的作用是什么?作者设计的darknet,输入图像大小为416*416,最终的feature map输出大小为13*13。yolo2完成了在feature map上的每个点上都预测了5个anchor box,每个预测出来的box都有中心点的(x,y)坐标以及w,h,confidence,物体类别概率,并以实际的bounding box与anchor box的iou值来决定置信度。因此,最终的feature map会输出13*13*5=845个预测的box,再从中根据iou值选择最优的box作为输出。
- x:预测中心点的横坐标
- y:预测中心点的纵坐标
- w:box的宽
- h:box的高
- confidence:根据与实际box的iou值计算
- class probability:物体概率
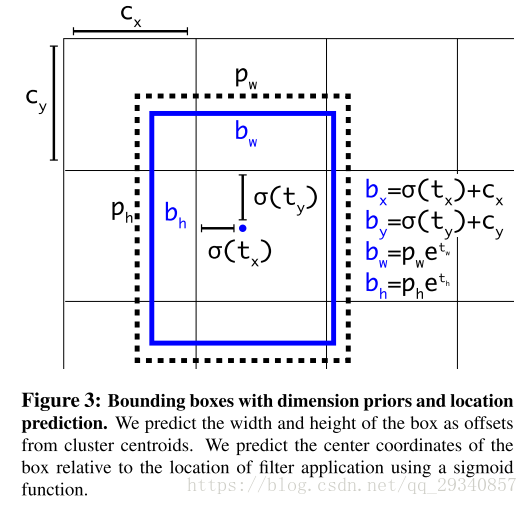
注意上述的预测值都是feature map的输出,因此不可避免的需要转换。
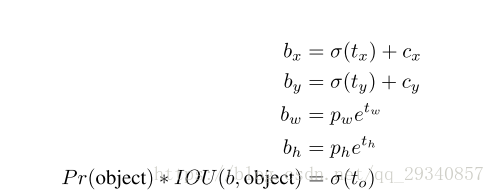
代码实践部分
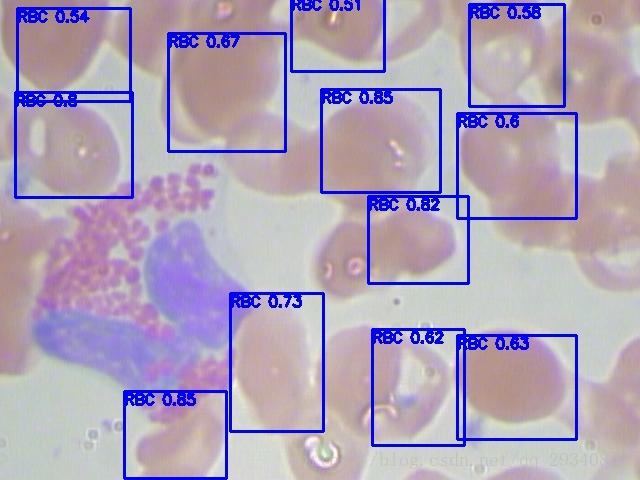
笔者用keras实践了yolo2用于红细胞检测上,发现效果还不错。实现的代码请移步:https://github.com/mjDelta/yolo2-keras。若觉得有帮助,请给出您宝贵的star!