1 redo log(重做日志)
1)InnoDB首先将redo log放入到redo log buffer,然后按一定频率将其刷新到redo log file。下列三种情况下会将redo log buffer刷新到redo log file:
- Master Thread每一秒将redo log buffer刷新到redo log file
- 每个事务提交时会将redo log buffer刷新到redo log file
- 当redo log缓冲池剩余空间小于1/2时,会将redo log buffer刷新到redo log file
MySQL里常说的WAL技术,全称是Write Ahead Log,即当事务提交时,先写redo log,再修改页。也就是说,当有一条记录需要更新的时候,InnoDB会先把记录写到redo log里面,并更新Buffer Pool的page,这个时候更新操作就算完成了
2)Buffer Pool是物理页的缓存,对InnoDB的任何修改操作都会首先在Buffer Pool的page上进行,然后这样的页将被标记为脏页并被放到专门的Flush List上,后续将由专门的刷脏线程阶段性的将这些页面写入磁盘
3)InnoDB的redo log是固定大小的,比如可以配置为一组4个文件,每个文件的大小是1GB,循环使用,从头开始写,写到末尾就又回到开头循环写(顺序写,节省了随机写磁盘的IO消耗)
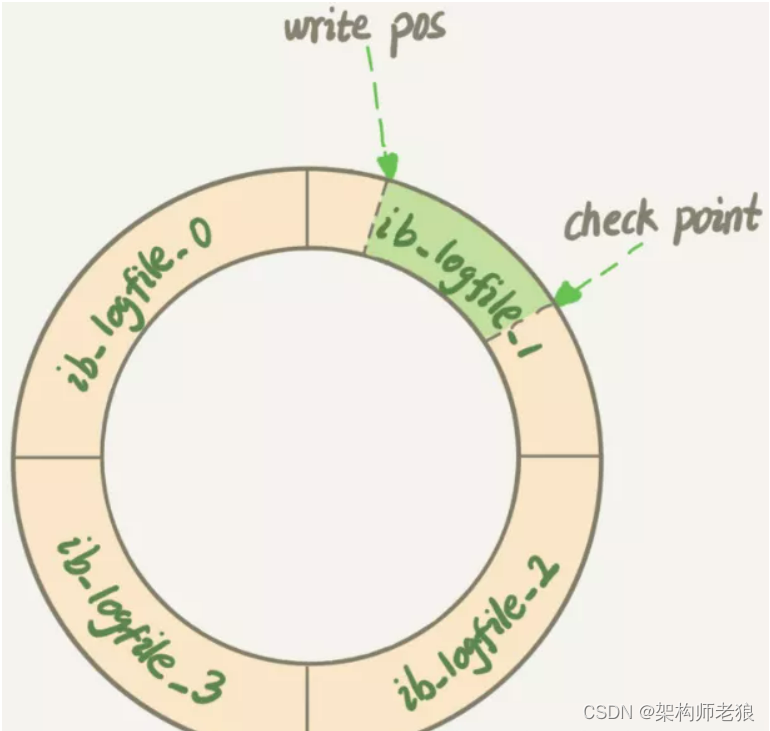
4)Write Pos是当前记录的位置,一边写一边后移,写到第3号文件末尾后就回到0号文件开头。Check Point是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件
5)Write Pos和Check Point之间空着的部分,可以用来记录新的操作。如果Write Pos追上Check Point,这时候不能再执行新的更新,需要停下来擦掉一些记录,把Check Point推进一下
6)当数据库发生宕机时,数据库不需要重做所有的日志,因为Check Point之前的页都已经刷新回磁盘,只需对Check Point后的redo log进行恢复,从而缩短了恢复的时间
7)当缓冲池不够用时,根据LRU算法会溢出最近最少使用的页,若此页为脏页,那么需要强制执行Check Point,将脏页刷新回磁盘。
2 binlog(归档日志)
1)MySQL整体来看就有两块:一块是Server层,主要做的是MySQL功能层面的事情;还有一块是引擎层,负责存储相关的具体事宜。redo log是InnoDB引擎特有的日志,而Server层也有自己的日志,称为binlog
2)binlog记录了对MySQL数据库执行更改的所有操作,不包括SELECT和SHOW这类操作,主要作用是用于数据库的主从复制及数据的增量恢复
3)使用mysqldump备份时,只是对一段时间的数据进行全备,但是如果备份后突然发现数据库服务器故障,这个时候就要用到binlog的日志了
4)binlog格式有三种:STATEMENT,ROW,MIXED:
- STATEMENT模式:binlog里面记录的就是SQL语句的原文。优点是并不需要记录每一行的数据变化,减少了binlog日志量,节约IO,提高性能。缺点是在某些情况下会导致master-slave中的数据不一致
- ROW模式:不记录每条SQL语句的上下文信息,仅需记录哪条数据被修改了,修改成什么样了,解决了STATEMENT模式下出现master-slave中的数据不一致。缺点是会产生大量的日志,尤其是alter table的时候会让日志暴涨
- MIXED模式:以上两种模式的混合使用,一般的复制使用STATEMENT模式保存binlog,对于STATEMENT模式无法复制的操作使用ROW模式保存binlog,MySQL会根据执行的SQL语句选择日志保存方式
3 redo log和binlog日志的不同
- redo log是InnoDB引擎特有的;binlog是MySQL的Server层实现的,所有引擎都可以使用
- redo log是物理日志,记录的是在某个数据也上做了什么修改;binlog是逻辑日志,记录的是这个语句的原始逻辑,比如给ID=2这一行的c字段加1
- redo log是循环写的,空间固定会用完;binlog是可以追加写入的,binlog文件写到一定大小后会切换到下一个,并不会覆盖以前的日志
4 两阶段提交
create table T(ID int primary key, c int);
update T set c=c+1 where ID=2;
执行器和InnoDB引擎在执行这个update语句时的内部流程:
- 执行器先找到引擎取ID=2这一行。ID是主键,引擎直接用树搜索找到这一行。如果ID=2这一行所在的数据也本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回
- 执行器拿到引擎给的行数据,把这个值加上1,得到新的一行数据,再调用引擎接口写入这行新数据
引擎将这行新数据更新到内存中,同时将这个更新操作记录到redo log里面,此时redo log处于prepare状态。然后告知执行器执行完成了,随时可以提交事务 - 执行器生成这个操作的binlog,并把binlog写入磁盘
- 执行器调用引擎的提交事务接口,引擎把刚刚写入的redo log改成提交状态,更新完成
- 将redo log的写入拆成了两个步骤:prepare和commit,这就是两阶段提交
5 分库分表
-
水平拆分:同一个表的数据拆到不同的库不同的表中。可以根据时间、地区或某个业务键维度,也可以通过hash进行拆分,最后通过路由访问到具体的数据。拆分后的每个表结构保持一致
-
垂直拆分:就是把一个有很多字段的表给拆分成多个表,或者是多个库上去。每个库表的结构都不一样,每个库表都包含部分字段。一般来说,可以根据业务维度进行拆分,如订单表可以拆分为订单、订单支持、订单地址、订单商品、订单扩展等表;也可以,根据数据冷热程度拆分,20%的热点字段拆到一个表,80%的冷字段拆到另外一个表。
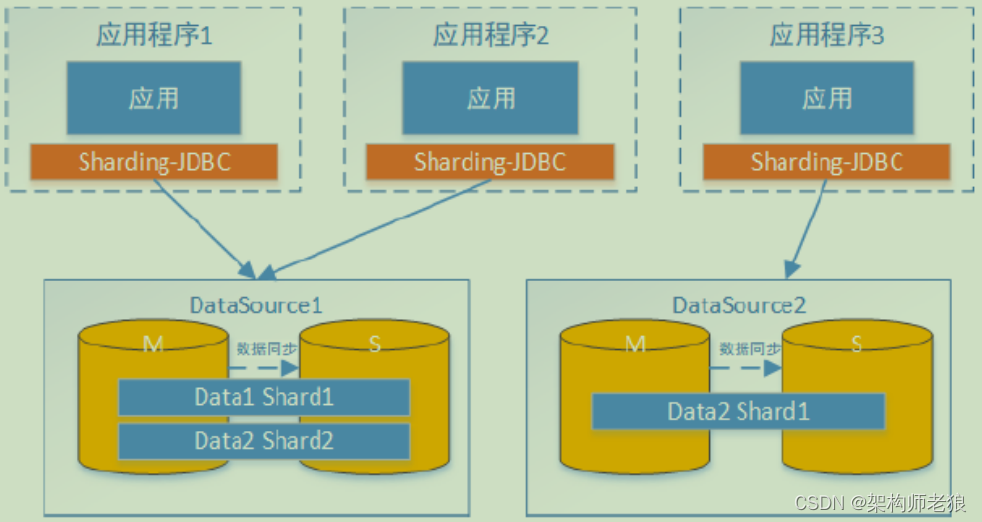
Sharding-JDBC分片策略:
-
standard:标准分片策略,对应StandardShardingStrategy。提供对SQL语句中的=, IN和BETWEEN AND的分片操作支持。StandardShardingStrategy只支持单分片键,提供PreciseShardingAlgorithm和RangeShardingAlgorithm两个分片算法。PreciseShardingAlgorithm是必选的,用于处理=和IN的分片。RangeShardingAlgorithm是可选的,用于处理BETWEEN AND分片,如果不配置RangeShardingAlgorithm,SQL中的BETWEEN AND将按照全库路由处理。
-
complex:符合分片策略,对应ComplexShardingStrategy。复合分片策略。提供对SQL语句中
的=, IN和BETWEEN AND的分片操作支持。ComplexShardingStrategy支持多分片键,由于多分片键之间的关系复杂,因此并未进行过多的封装,而是直接将分片键值组合以及分片操作符透传至分片算法,完全由应用开发者实现,提供最大的灵活度。 -
inline:行表达式分片策略,对应InlineShardingStrategy。使用Groovy的表达式,提供对SQL
语句中的=和IN的分片操作支持,只支持单分片键。对于简单的分片算法,可以通过简单的配置使用,从而避免繁琐的Java代码开发,如: t_user_$->{u_id % 8} 表示t_user表根据u_id模8,而分成8张表,表名称为t_user_0 到t_user_7 。 -
hint:Hint分片策略,对应HintShardingStrategy。通过Hint而非SQL解析的方式分片的策略。
对于分片字段非SQL决定,而由其他外置条件决定的场景,可使用SQL Hint灵活的注入分片字段。例:内部系统,按照员工登录主键分库,而数据库中并无此字段。SQL Hint支持通过Java API和SQL注释(待实现)两种方式使用。 -
none:不分片策略,对应 NoneShardingStrategy。不分片的策略。
-
水平分表
# shardingjdbc分片策略
# 配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=m1
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://hadoop02:3306/course_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=***
#指定course表分布情况,配置表在哪个数据库里面,表名称都是什么 m1.course_1 , m1.course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m1.course_$->{
1..2}
spring.shardingsphere.sharding.default-data-source-name=m1
# 指定course表里面主键cid 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定分片策略 约定cid值偶数添加到course_1表,如果cid是奇数添加到course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{
cid % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
- 水平分库
# shardingjdbc分片策略
# 配置数据源,给数据源起名称,
# 水平分库,配置两个数据源
spring.shardingsphere.datasource.names=m1,m2
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置第一个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m1.url=jdbc:mysql://hadoop02:3306/course_db?serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m1.username=root
spring.shardingsphere.datasource.m1.password=***
#配置第二个数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.m2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.m2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.m2.url=jdbc:mysql://10.1.1.21:3306/course_db?characterEncoding=utf-8&useSSL=false&serverTimezone=GMT%2B8
spring.shardingsphere.datasource.m2.username=root
spring.shardingsphere.datasource.m2.password=***
#指定数据库分布情况,数据库里面表分布情况
# m1 m2 course_1 course_2
spring.shardingsphere.sharding.tables.course.actual-data-nodes=m$->{
1..2}.course_$->{
1..2}
# 指定course表里面主键cid 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.course.key-generator.column=cid
spring.shardingsphere.sharding.tables.course.key-generator.type=SNOWFLAKE
# 指定表分片策略 约定cid值偶数添加到course_1表,如果cid是奇数添加到course_2表
spring.shardingsphere.sharding.tables.course.table-strategy.inline.sharding-column=cid
spring.shardingsphere.sharding.tables.course.table-strategy.inline.algorithm-expression=course_$->{
cid % 2 + 1}
# 指定数据库分片策略 约定user_id是偶数添加m1,是奇数添加m2
#spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column=user_id
#spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression=m$->{user_id % 2 + 1}
spring.shardingsphere.sharding.tables.course.database-strategy.inline..sharding-column=user_id
spring.shardingsphere.sharding.tables.course.database-strategy.inline.algorithm-expression=m$->{
user_id % 2 + 1}
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
6 主从复制
1)Mysql主从复制原理
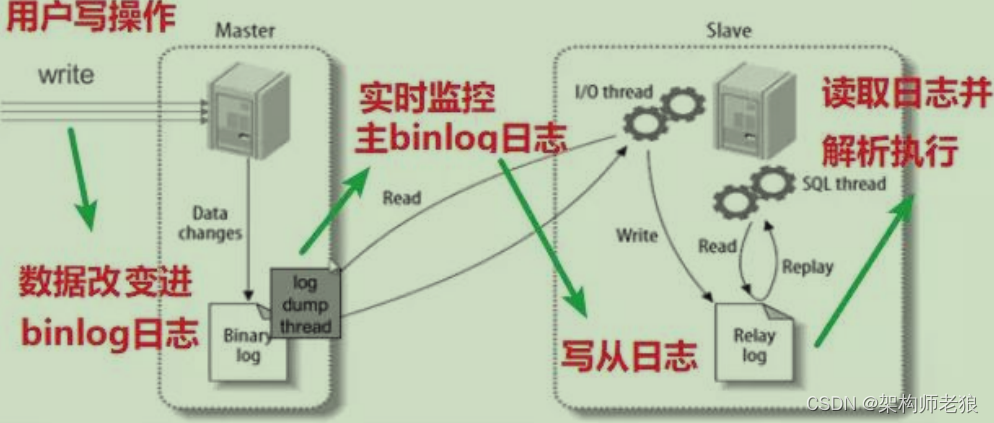
主从复制不是完全实时地进行同步,而是异步实时。这中间存在主从服务之间的执行延时,如果主服务器的压力很大,则可能导致主从服务器延时较大。
2)主库配置
vim /usr/local/mysqlData/master/cnf/mysql.cnf
[mysqld]
## 设置server_id,注意要唯一
server-id=1
## 开启binlog
log-bin=mysql-bin
## binlog缓存
binlog_cache_size=1M
## binlog格式(mixed、statement、row,默认格式是statement)
binlog_format=mixed
3)从库配置
vim /usr/local/mysqlData/slave/cnf/mysql.cnf
[mysqld]
## 设置server_id,注意要唯一
server-id=2
## 开启binlog,以备Slave作为其它Slave的Master时使用
log-bin=mysql-slave-bin
## relay_log配置中继日志
relay_log=edu-mysql-relay-bin
## 如果需要同步函数或者存储过程
log_bin_trust_function_creators=true
## binlog缓存
binlog_cache_size=1M
## binlog格式(mixed、statement、row,默认格式是statement)
binlog_format=mixed
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
4)从服务器启动I/O 线程和SQL线程
mysql> start slave;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.1.1.13
Master_User: reader
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 591
Relay_Log_File: edu-mysql-relay-bin.000002
Relay_Log_Pos: 320
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Slave_IO_Running: Yes,Slave_SQL_Running: Yes即表示启动成功
5) 主从复制延迟

- 延迟是sql thread与io thread之间差值,主机器负载过高造成更新推送延迟,从机器负载过高造成拉取延迟
- 高并发分流:采用多主,谁写谁读,业务层增加nosql 层-有更新读缓存
- 从库可以使用mysql5.7-支持多线程复制,rpl_semi_sync_master_enabled-完全同步机制
6)sharding jdbc实现读写分离
- Sharding-JDBC读写分离则是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库。
它提供透明化读写分离,让使用方尽量像使用一个数据库一样使用主从数据库集群。
spring.main.allow-bean-definition-overriding=true
#显示sql
spring.shardingsphere.props.sql.show=true
#配置数据源
spring.shardingsphere.datasource.names=ds1,ds2,ds3
#master-ds1数据库连接信息
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://hadoop02:3306/sharding-jdbc-db?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=***
spring.shardingsphere.datasource.ds1.maxPoolSize=100
spring.shardingsphere.datasource.ds1.minPoolSize=5
#slave-ds2数据库连接信息
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://hadoop03:3307/sharding-jdbc-db?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=***
spring.shardingsphere.datasource.ds2.maxPoolSize=100
spring.shardingsphere.datasource.ds2.minPoolSize=5
#slave-ds3数据库连接信息
spring.shardingsphere.datasource.ds3.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds3.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds3.url=jdbc:mysql://hadoop01:3307/sharding-jdbc-db?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
spring.shardingsphere.datasource.ds3.username=root
spring.shardingsphere.datasource.ds3.password=***
spring.shardingsphere.datasource.ds.maxPoolSize=100
spring.shardingsphere.datasource.ds3.minPoolSize=5
#配置默认数据源ds1 默认数据源,主要用于写
spring.shardingsphere.sharding.default-data-source-name=ds1
#配置主从名称
spring.shardingsphere.masterslave.name=ms
#置主库master,负责数据的写入
spring.shardingsphere.masterslave.master-data-source-name=ds1
#配置从库slave节点
spring.shardingsphere.masterslave.slave-data-source-names=ds2,ds3
#配置slave节点的负载均衡均衡策略,采用轮询机制
spring.shardingsphere.masterslave.load-balance-algorithm-type=round_robin
#整合mybatis的配置
mybatis.type-aliases-package=com.ppdai.shardingjdbc.entity