1.介绍
整个搜索系统运行的流程,当用户的query输入后,第一先经过文本预处理模块,修正的数据进行召回,精排,重排,然后返给用户搜索的结果。

2.文本预处理模块
2.1.作用
在搜索系统中,文本预处理是一个关键的步骤,其作用是对原始文本进行一系列的处理和转换,以提高搜索质量和效率。下面是文本预处理在搜索系统中的主要作用:
分词(Tokenization):将原始文本拆分为单个词或词组的序列,称为词项(terms)。分词可以使用空格、标点符号等进行简单的切分,也可以使用更复杂的技术,如基于语言规则或机器学习的方法。分词使搜索系统能够以单词为单位进行索引和匹配。
去除停用词(Stop Word Removal):停用词是指在搜索过程中没有实际意义,通常在大量文本中频繁出现的词,如"a"、“an”、"the"等。去除停用词可以减少索引的大小,提高搜索效率,并且能够过滤掉一些常见但无关紧要的词。
大小写转换(Case Normalization):将文本中的字母统一转换为大写或小写形式。这样做可以消除大小写的差异,使得搜索系统不区分单词的大小写,从而提高搜索的准确性和覆盖范围。
词形还原(Stemming/Lemmatization):将单词转换为其基本形式,以消除不同词形的差异。例如,将"running"、“runs"和"ran"都还原为基本形式"run”。词形还原可以减少词汇的变体,扩展搜索的范围,同时减少搜索时的歧义性。
同义词处理(Synonym Handling):在搜索过程中,考虑到用户可能使用不同的词来表示相同的含义,可以进行同义词处理。这包括使用词典或知识库来扩展搜索查询的范围,以包括与查询词相关的同义词或相关词汇。
正规化(Normalization):对于某些特殊文本内容,如日期、时间、数字等,进行正规化处理,使得搜索系统能够正确解析和处理这些信息,以支持基于这些信息的搜索和排序。
去除噪声和特殊字符(Noise and Special Character Removal):在文本预处理中,可能需要去除一些噪声数据或特殊字符,以提高搜索的质量和性能。这些特殊字符包括HTML标签、标点符号、特殊符号等。
还包含繁体转简体,全角转半角,和删除文本前后空白字符等。
通过进行文本预处理,搜索系统可以将原始文本转换为更具有结构化和标准化的形式,提高搜索的效率和准确性。
2.2实现
搜索对应的python api接口实现
3.召回模块
待搜索文本存入ElasticSearch中,文本预处理修正后的文本去ES中召回1000条以内的相似文本。
3.1Elasticsearch实现全文搜索的方式主要基于以下几个关键组件和技术:
-
倒排索引(Inverted Index):Elasticsearch使用倒排索引结构来支持全文搜索。倒排索引是一种将文档中的词项映射到文档的数据结构,它提供了快速的词项检索能力。对于每个词项,倒排索引存储了包含该词项的文档的引用。
-
分词和标记化(Tokenization):在进行全文搜索之前,文本需要进行分词和标记化处理。Elasticsearch使用分析器(Analyzer)来将文本分割成词项,并应用各种标准化和过滤器来处理词项,如去除停用词、词干还原、同义词处理等。
-
查询解析和查询语言:Elasticsearch提供了灵活的查询解析功能,支持多种查询类型和查询语言。用户可以使用结构化查询语言(如Query DSL)或简单查询字符串来构建查询。查询解析器将查询解析为倒排索引可以理解的数据结构,以执行相应的搜索操作。
-
相似性计算和评分:Elasticsearch使用相似性计算和评分算法来确定搜索结果的相关性和排序。它考虑了多个因素,如词项频率、字段权重、文档长度等,以计算每个文档的得分,并将搜索结果按照得分进行排序,以提供最相关的结果。
-
高级搜索功能:除了基本的全文搜索功能,Elasticsearch还提供了一系列高级搜索功能,如模糊搜索、短语匹配、通配符搜索、范围搜索、正则表达式搜索等。这些功能允许用户执行更复杂和精细的搜索操作,以满足不同的搜索需求。
-
可定制的分析和插件:Elasticsearch提供了可定制的分析器和过滤器,使用户可以根据具体需求定义自己的文本分析过程。此外,它还支持插件机制,允许用户扩展和定制各种功能,如新的分析器、查询解析器等。
通过以上组件和技术的结合,Elasticsearch能够高效地实现全文搜索功能,提供快速、准确和灵活的搜索体验。用户可以利用其丰富的功能和查询语言来构建复杂的搜索应用,并根据需要进行调整和优化。
3.2 实现
要在Python中使用Elasticsearch实现查找数据和写入数据,您可以使用Elasticsearch官方提供的Python客户端库——Elasticsearch-Py。以下是基本的实现方法:
-
安装Elasticsearch-Py库:
在Python环境中安装Elasticsearch-Py库。您可以使用pip命令进行安装:pip install elasticsearch -
连接到Elasticsearch:
在Python代码中导入Elasticsearch库,并使用Elasticsearch()方法建立与Elasticsearch的连接:from elasticsearch import Elasticsearch # 连接到本地的Elasticsearch实例 es = Elasticsearch() -
搜索数据:
使用search()方法执行搜索操作。您可以指定要搜索的索引、查询条件和其他可选参数:# 搜索所有文档 res = es.search(index="your_index", body={ "query": { "match_all": { }}}) # 根据条件搜索文档 res = es.search(index="your_index", body={ "query": { "match": { "field_name": "search_term"}}}) -
写入数据:
使用index()方法将数据写入到指定的索引中。您可以指定索引、类型和要写入的文档数据:# 写入单个文档 data = { "field1": "value1", "field2": "value2"} res = es.index(index="your_index", body=data) # 写入多个文档 data = [ { "field1": "value1", "field2": "value2"}, { "field1": "value3", "field2": "value4"} ] res = es.bulk(index="your_index", body=data)
请注意,上述示例仅为基本操作示例,并未详尽列出所有可用的选项和参数。您可以参考Elasticsearch-Py的官方文档以获得更详细的信息和示例:https://elasticsearch-py.readthedocs.io/
4.精排模块
从ES召回的文本,经过精排计算与query的相似度。精排模块使用的是双塔模型,为提升整个系统响应速度,离线存储其中一塔的向量数据,用户query作为另一塔数据进行相似度计算。
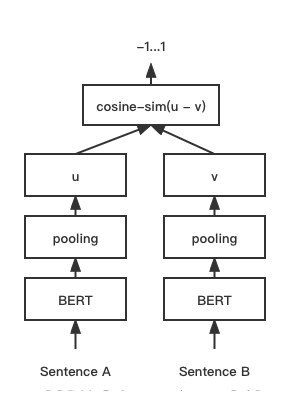
4.1双塔模型介绍
在自然语言处理(NLP)领域中,双塔模型是一种常见的模型结构,用于学习和比较文本之间的相似性或语义关系。双塔模型通常由两个对称的塔楼组成,每个塔楼用于处理一个文本输入,然后通过比较两个塔楼的输出来得到文本之间的相似性度量。
技术选型CoSENT模型,
CoSENT(Cosine Sentence)文本匹配模型,在Sentence-BERT上改进了CosineRankLoss的句向量方案
Cosent模型的整个处理逻辑和Sentence-BERT一样,损失函数的不同,定义了Cosent属于非交互式网络结构。Sentence-BERT详细介绍见我的另外文章link
training
inference
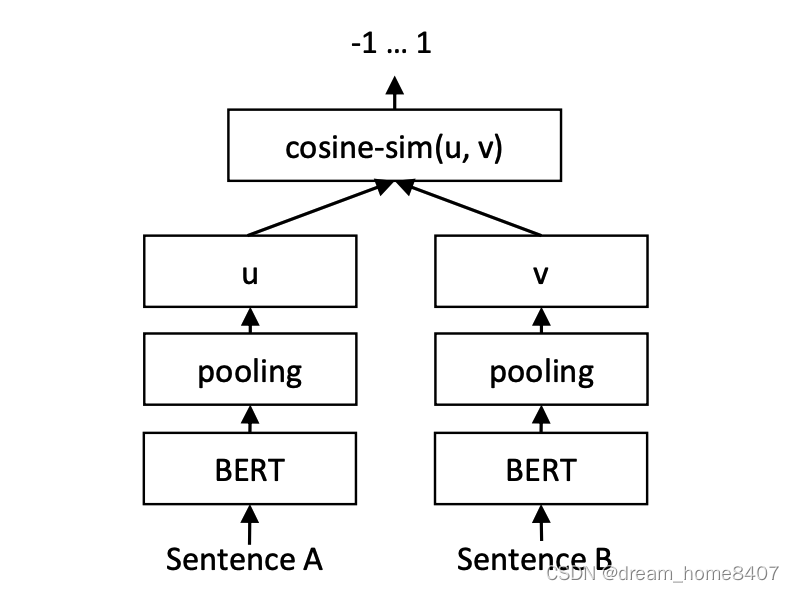

链接:link
4.2数据集构建
正样本构建:根据原始词条,利用chatgpt生成相似语料,提高模型泛化能力
负样本构建:1.简单负样本。全部词条样本中选择。
2.困难负样本,从召回结果中找出不相似文本
正负样本构建比例:正样本:负样本=1:10
负样本构建比例:简单负样本:困难负样本=1:1
5.重排模块
基于词条标签对精排后的数据重新排序
5.1实现
根据词条数据质量、热度数据、用户点击等特征标签,结合业务需求乘以相对应的权重
6.排序模块评价指标
使用的是nDCG评价指标,具体介绍和落地步骤请见我另一篇文章
link