1. 前期准备
1. 在hadoop102安装JDK, 使用root账户登录系统
注意:安装JDK前,一定确保提前删除了虚拟机自带的JDK
# 查看系统自带的java版本
java -version
# 查找JDK相关包是否被安装
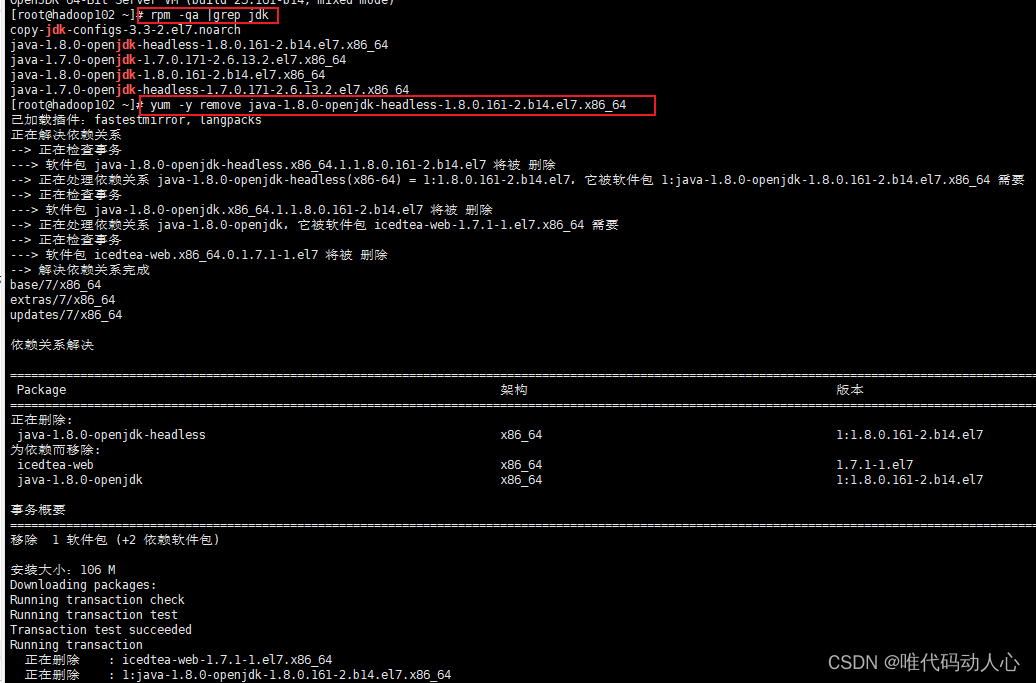
rpm -qa |grep jdk
# 使用yum -y remove 命令卸载已经安装的jdk相关包
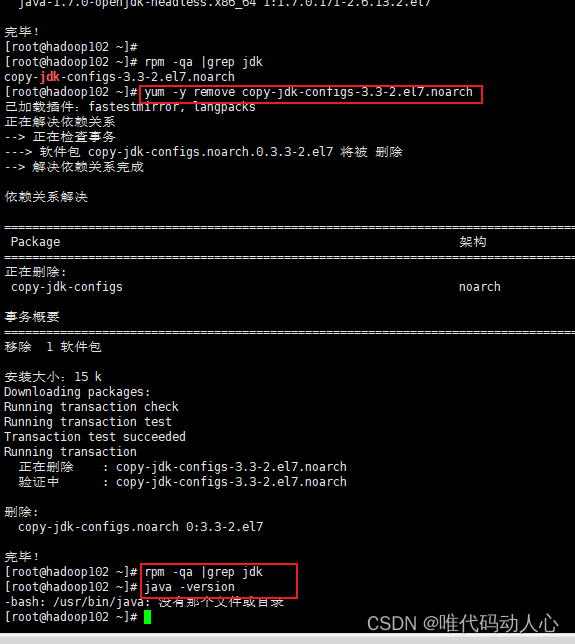
yum -y remove copy-jdk-configs-3.3-2.el7.noarch
yum -y remove java-1.8.0-openjdk-headless-1.8.0.161-2.b14.el7.x86_64
yum -y remove java-1.7.0-openjdk-1.7.0.171-2.6.13.2.el7.x86_64
yum -y remove java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64
yum -y remove java-1.7.0-openjdk-headless-1.7.0.171-2.6.13.2.el7.x86_64
# 再次查找JDK相关包是否被安装, 结果为空, 表示全部卸载
rpm -qa |grep jdk
# 再次查看系统自带的java版本
java -version
安装新的jdk
- 新建目录
mkdir /opt/module
mkdir /opt/software
- 将安装包上传到/opt/software目录下
- 解压安装包
# 进入/opt/software目录
cd /opt/software
# 解压jdk到/opt/module/目录下
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
- 配置JDK环境变量
# 进入/etc/profile.d/目录下
cd /etc/profile.d/
# 在/etc/profile.d/文件下新建一个my_env.sh文件, 里面用来存放自己安装软件的环境变量信息
vim /etc/profile.d/my_env.sh
# 在/etc/profile.d/my_env.sh中添加java环境变量信息
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
# source一下/etc/profile文件,让新的环境变量PATH生效
source /etc/profile
# 查看是否安装成功, 如果出现版本号就说明安装成功
java -version
# 如果java -version命令没有出现版本号, 就需要重启系统
reboot
为什么要在/etc/profile.d下新建一个my_env.sh
在Linux的系统配置文件 /etc/profile 中有一个
[root@hadoop102 software]# cat /etc/profile
# /etc/profile
# System wide environment and startup programs, for login setup
# Functions and aliases go in /etc/bashrc
# It's NOT a good idea to change this file unless you know what you
# are doing. It's much better to create a custom.sh shell script in
# /etc/profile.d/ to make custom changes to your environment, as this
# will prevent the need for merging in future updates.
pathmunge () {
case ":${
PATH}:" in
*:"$1":*)
;;
*)
if [ "$2" = "after" ] ; then
PATH=$PATH:$1
else
PATH=$1:$PATH
fi
esac
}
if [ -x /usr/bin/id ]; then
if [ -z "$EUID" ]; then
# ksh workaround
EUID=`/usr/bin/id -u`
UID=`/usr/bin/id -ru`
fi
USER="`/usr/bin/id -un`"
LOGNAME=$USER
MAIL="/var/spool/mail/$USER"
fi
# Path manipulation
if [ "$EUID" = "0" ]; then
pathmunge /usr/sbin
pathmunge /usr/local/sbin
else
pathmunge /usr/local/sbin after
pathmunge /usr/sbin after
fi
HOSTNAME=`/usr/bin/hostname 2>/dev/null`
HISTSIZE=1000
if [ "$HISTCONTROL" = "ignorespace" ] ; then
export HISTCONTROL=ignoreboth
else
export HISTCONTROL=ignoredups
fi
export PATH USER LOGNAME MAIL HOSTNAME HISTSIZE HISTCONTROL
# By default, we want umask to get set. This sets it for login shell
# Current threshold for system reserved uid/gids is 200
# You could check uidgid reservation validity in
# /usr/share/doc/setup-*/uidgid file
if [ $UID -gt 199 ] && [ "`/usr/bin/id -gn`" = "`/usr/bin/id -un`" ]; then
umask 002
else
umask 022
fi
for i in /etc/profile.d/*.sh /etc/profile.d/sh.local ; do
if [ -r "$i" ]; then
if [ "${-#*i}" != "$-" ]; then
. "$i"
else
. "$i" >/dev/null
fi
fi
done
unset i
unset -f pathmunge
[root@hadoop102 software]#
2. 在hadoop102安装Hadoop, 使用root账户登录系统
安装hadoop
- 新建目录
mkdir /opt/module
mkdir /opt/software
- 将安装包上传到/opt/software目录下
- 解压安装包
# 进入/opt/software目录
cd /opt/software
# 解压jdk到/opt/module/目录下
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
- 配置Hadoop环境变量
# 进入/etc/profile.d/目录下
cd /etc/profile.d/
# 在/etc/profile.d/文件下新建一个my_env.sh文件, 里面用来存放自己安装软件的环境变量信息
vim /etc/profile.d/my_env.sh
# 在/etc/profile.d/my_env.sh中添加Hadoop环境变量信息
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
# source一下/etc/profile文件,让新的环境变量PATH生效
source /etc/profile
# 查看是否安装成功, 如果出现版本号就说明安装成功
hadoop version
# 如果java -version命令没有出现版本号, 就需要重启系统
reboot
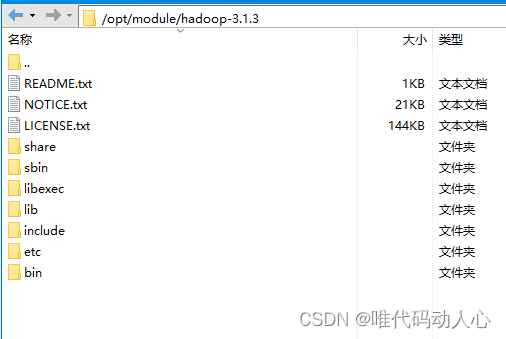
hadoop目录结构
(1)bin目录:存放对Hadoop相关服务(hdfs,yarn,mapred)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
3. 集群分发脚本
将JDK与hadoop的安装文件从hadoop102复制到hadoop103与hadoop104
3.1 scp(secure copy)安全拷贝
前提: 准备三台Linux机器, 配置静态ip地址, 配置主机名称, 配置主机名称映射hosts文件
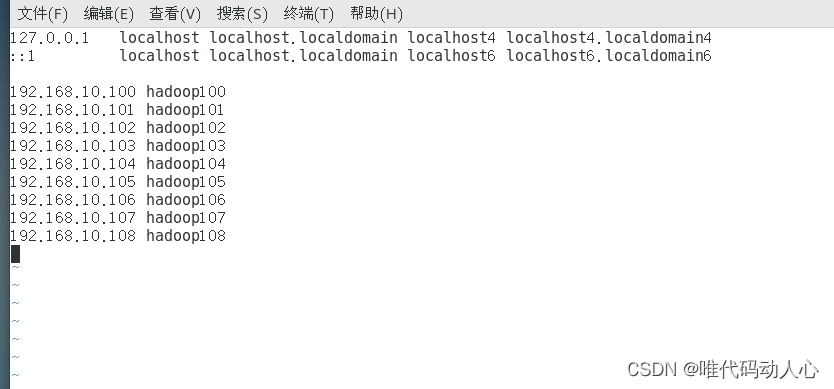
前提: 在hadoop102、hadoop103、hadoop104都已经创建好 /opt/module、 /opt/software 两个目录
chown root:root -R /opt/module
scp -r $user@$host:$pdir/$fname $user@$host:$pdir/$fname
命令 递归 来源地登录用户名@主机:来源地路径/名称 目的地登录用户名@主机:目的地路径/名称
如果不填写 $user@$host 则默认是本机
- 在hadoop102上,将hadoop102中/opt/module/jdk1.8.0_212目录拷贝到hadoop103上。
scp -r /opt/module/jdk1.8.0_212 root@hadoop103:/opt/module
- 在hadoop103上,将hadoop102中/opt/module/hadoop-3.1.3目录拷贝到hadoop103上
scp -r root@hadoop102:/opt/module/hadoop-3.1.3 /opt/module/
- 在hadoop103上操作,将hadoop102中/opt/module目录下所有目录拷贝到hadoop104上
scp -r root@hadoop102:/opt/module/* root@hadoop104:/opt/module
3.2 rsync远程同步工具
用rsync做文件的复制要比scp的速度快,rsync只对差异文件做更新。scp是把所有文件都复制过去
rsync -av $user@$host:$pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的用户@主机:文件路径/名称 目的地用户@主机:目的地路径/名称
- 删除hadoop103中/opt/module/hadoop-3.1.3/wcinput
rm -rf /opt/module/hadoop-3.1.3/wcinput
- 在hadoop102上, 同步hadoop102中的/opt/module/hadoop-3.1.3到hadoop103
rsync -av hadoop-3.1.3/ root@hadoop103:/opt/module/hadoop-3.1.3/
3.3 xsync集群分发脚本
- 创建文件
cd /bin
vim xsync
- 在xsync中添加以下脚本
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit; #退出
fi # if结束
#2. 遍历集群所有机器
for host in hadoop102 hadoop103 hadoop104
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
# $@表示传递给函数或脚本的所有参数
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
# $host是上面for循环的临时变量, ssh命令连接远程主机
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
- 修改脚本 xsync 具有执行权限
chmod +x xsync
或者
chmod 777 xsync
- 将hadoop102的 /etc/profile.d/my_env.sh 文件同步到 hadoop103 和 hadoop104
在hadoop103 和 hadoop104的 /etc/profile.d/ 目录下会多出一个 my_env.sh 文件
# xsync命令 路径要写全
/bin/xsync /etc/profile.d/my_env.sh
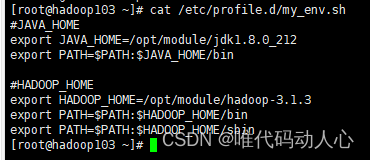
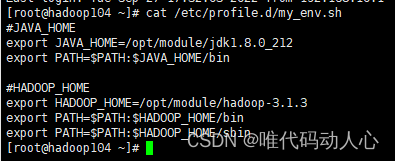
- 使 hadoop103与hadoop104的环境变量生效
[root@hadoop103 ~]# source /etc/profile
[root@hadoop104 ~]# source /etc/profile
- 测试环境变量是否生效
[root@hadoop103 ~]# java -version
openjdk version "1.8.0_161"
OpenJDK Runtime Environment (build 1.8.0_161-b14)
OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)
[root@hadoop103 ~]# hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
[root@hadoop103 ~]#
[root@hadoop104 ~]# java -version
openjdk version "1.8.0_161"
OpenJDK Runtime Environment (build 1.8.0_161-b14)
OpenJDK 64-Bit Server VM (build 25.161-b14, mixed mode)
[root@hadoop104 ~]# hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /opt/module/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
[root@hadoop104 ~]#
4. SSH无密登录配置
普通ssh语法
ssh hadoop103
# 输入密码后连接到 hadoop103
- 免密登录原理
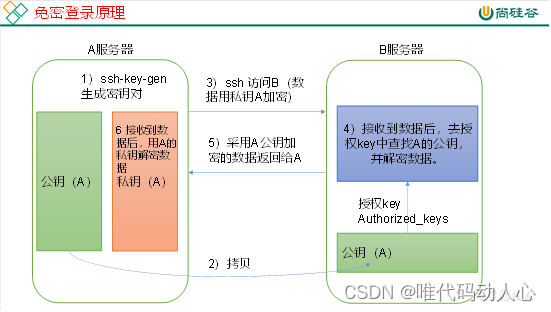
- 生成公钥和私钥
三台机器全部要进行以下操作, 这样在任意一台机器都可以对其他机器进行免密登录, 这里我使用的是 root 用户
# 进入/root目录下
cd /root
# 生成公钥和私钥, 执行命令后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
ssh-keygen -t rsa
# 进入/root/.ssh查看
cd /root/.ssh
# 将公钥拷贝到要免密登录的目标机器上, 输入 yes , 输入对应机器的密码
ssh-copy-id hadoop102
ssh-copy-id hadoop103
ssh-copy-id hadoop104
# 测试, 无需输入密码
ssh hadoop102
ssh hadoop103
ssh hadoop104
/root/.ssh 目录下各文件功能说明
| 文件名 | 说明 |
|---|---|
| known_hosts | 记录ssh访问过计算机的公钥(public key) |
| id_rsa | 生成的私钥 |
| id_rsa.pub | 生成的公钥 |
| authorized_keys | 存放授权过的无密登录服务器公钥 |
2. 集群配置
1. 集群部署规划说明
NameNode和SecondaryNameNode不要安装在同一台服务器
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上。
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode 、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
2. 集群配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值
| 要获取的默认文件 | 文件存放在Hadoop的jar包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml四个配置文件存放在 $HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置
3. 配置集群配置文件
3.1 核心配置文件: core-site.xml
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml
默认的 configuration 标签中的内容是空的, 我们加上以下内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop102:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>atguigu</value>
</property>
</configuration>
3.2 HDFS配置文件 : hdfs-site.xml
cd $HADOOP_HOME/etc/hadoop
vim hdfs-site.xml
默认的 configuration 标签中的内容是空的, 我们加上以下内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
3.3 YARN配置文件: yarn-site.xml
cd $HADOOP_HOME/etc/hadoop
vim yarn-site.xml
默认的 configuration 标签中的内容是空的, 我们加上以下内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
3.4 MapReduce配置文件: mapred-site.xml
cd $HADOOP_HOME/etc/hadoop
vim mapred-site.xml
默认的 configuration 标签中的内容是空的, 我们加上以下内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.5 在集群上分发hadoop102上配置好的Hadoop配置文件
/bin/xsync /opt/module/hadoop-3.1.3/etc/hadoop/
去103和104上查看文件分发情况
[root@hadoop103 hadoop]# cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
[root@hadoop104 hadoop]# cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
4. 启动集群
4.1 配置workers
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
在文件中增加下面内容, 集群上有几个节点, 这里就配置几个
hadoop102
hadoop103
hadoop104
给其他节点同步配置文件
/bin/xsync /opt/module/hadoop-3.1.3/etc/hadoop/
4.2 在hadoop102上启动HDFS
cd /opt/module/hadoop-3.1.3
# 如果集群是第一次启动,需要在hadoop102节点格式化NameNode
hdfs namenode -format
# 启动HDFS
sbin/start-dfs.sh
# 启动报错, 重新启动之前需要关闭HDFS
sbin/stop-dfs.sh
使用 jsp 命令测试 HDFS 启动结果
# hadoop102中启动了 NameNode 与 DataNode
[root@hadoop102 hadoop-3.1.3]# jps
9202 DataNode
9364 Jps
9048 NameNode
# hadoop103中只启动 DataNode
[root@hadoop103 hadoop-3.1.3]# jps
8649 DataNode
8733 Jps
# hadoop102中启动了 SecondaryNameNode 与 DataNode
[root@hadoop104 hadoop-3.1.3]# jps
9427 Jps
9379 SecondaryNameNode
9274 DataNode
第一次启动的时候报了下面这个错误, 解决方案: 使用root用户启动hadoop-3.1.3报错
[root@hadoop102 hadoop-3.1.3]# sbin/start-dfs.sh
Starting namenodes on [hadoop102]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [hadoop104]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
启动 HDFS出现了下面的情况, 解决方案: 新版Hadoop这个配置的参数更新了导致启动失败
[root@hadoop102 hadoop-3.1.3]# sbin/start-dfs.sh
WARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.
Starting namenodes on [hadoop102]
上一次登录:三 9月 28 15:39:17 CST 2022从 hadoop104pts/1 上
Starting datanodes
上一次登录:三 9月 28 18:37:26 CST 2022pts/0 上
4.3 在hadoop103上启动YARN
cd /opt/module/hadoop-3.1.3
# 启动 YARN
sbin/start-yarn.sh
# 关闭 YARN
sbin/stop-yarn.sh
使用 jps 命令测试 YARN启动结果
# hadoop102的 HDFS 中启动了 NameNode 与 DataNode
# hadoop102的 YARN 中启动了 NodeManager
[root@hadoop102 hadoop-3.1.3]# jps
13161 NodeManager
13355 Jps
11789 NameNode
11967 DataNode
# hadoop103的 HDFS 中只启动 DataNode
# hadoop102的 YARN 中启动了 ResourceManager 与 NodeManager
[root@hadoop103 hadoop-3.1.3]# jps
11394 Jps
9254 DataNode
10814 ResourceManager
11150 NodeManager
# hadoop102的 HDFS 中启动了 SecondaryNameNode 与 DataNode
# hadoop102的 YARN 中启动了 NodeManager
[root@hadoop104 hadoop-3.1.3]# jps
9379 SecondaryNameNode
10617 Jps
9274 DataNode
10411 NodeManager
启动 HDFS出现了下面的情况, 解决方案: 启动start-yarn.sh报错ERROR: Attempting to operate on yarn resourcemanager as root ERROR: but there is no
[root@hadoop103 hadoop-3.1.3]# sbin/start-yarn.sh
Starting resourcemanager
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
上一次登录:三 9月 28 15:39:32 CST 2022从 hadoop104pts/2 上
^C
4.4 Web端查看集群信息
关闭hadoop102、hadoop03、hadoop104 的防火墙
systemctl stop firewalld
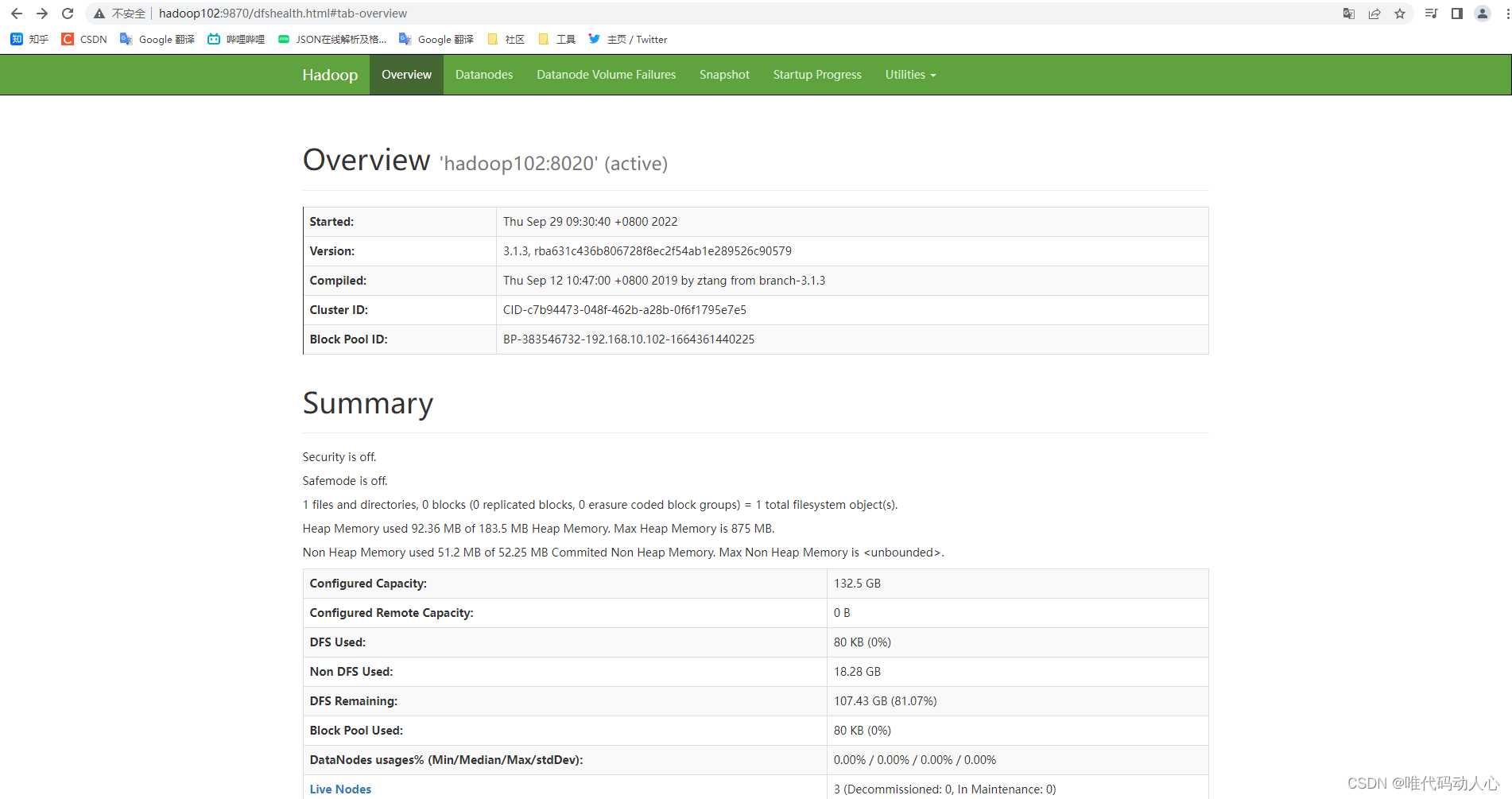
浏览器中输入:http://hadoop102:9870
查看HDFS上存储的数据信息
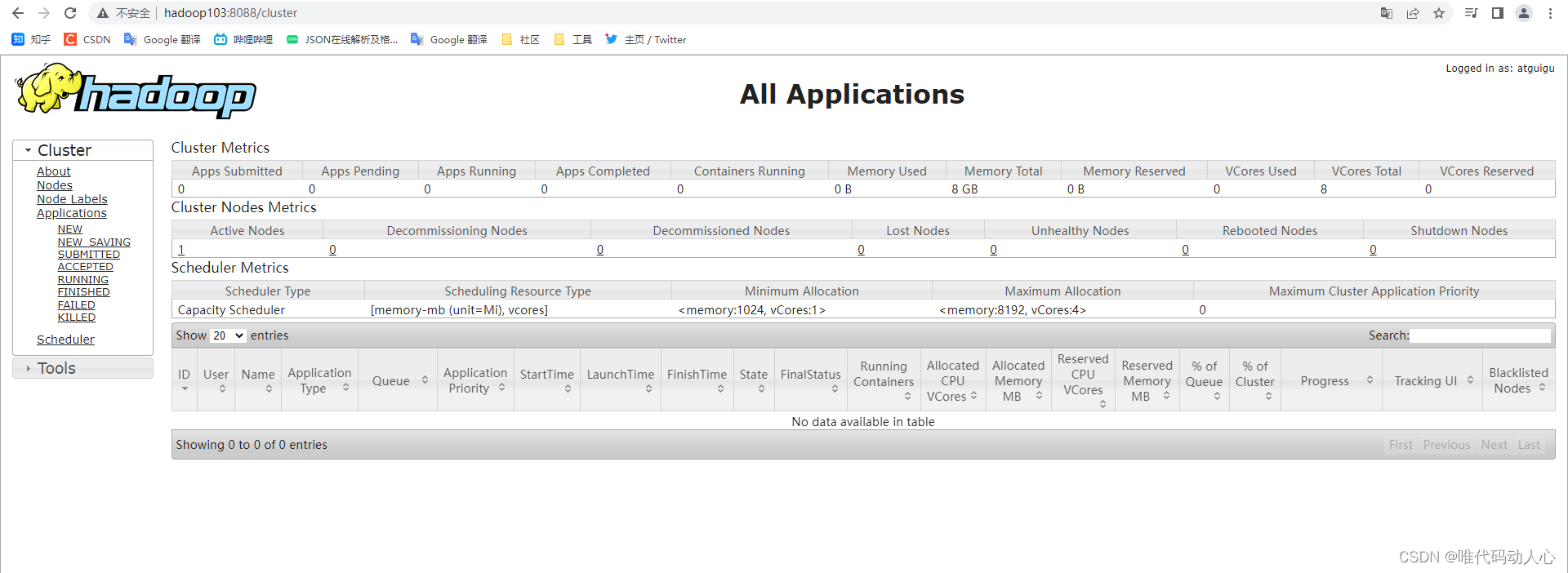
浏览器中输入:http://hadoop103:8088
查看YARN上运行的Job信息
5. 集群基本测试
5.1 上传文件到集群
命令 : hadoop fs -put 本地文件 HDFS目录
# 在 HDFS 的根目录下创建一个 input文件夹
hadoop fs -mkdir /input
# 將 /hadoop-3.1.3/README.txt上传到HDFS中新建的 input 目录下
hadoop fs -put $HADOOP_HOME/README.txt /input
# 在 HDFS 隔壁目录下上传 jdk-8u212-linux-x64.tar.gz
hadoop fs -put /opt/software/jdk-8u212-linux-x64.tar.gz /
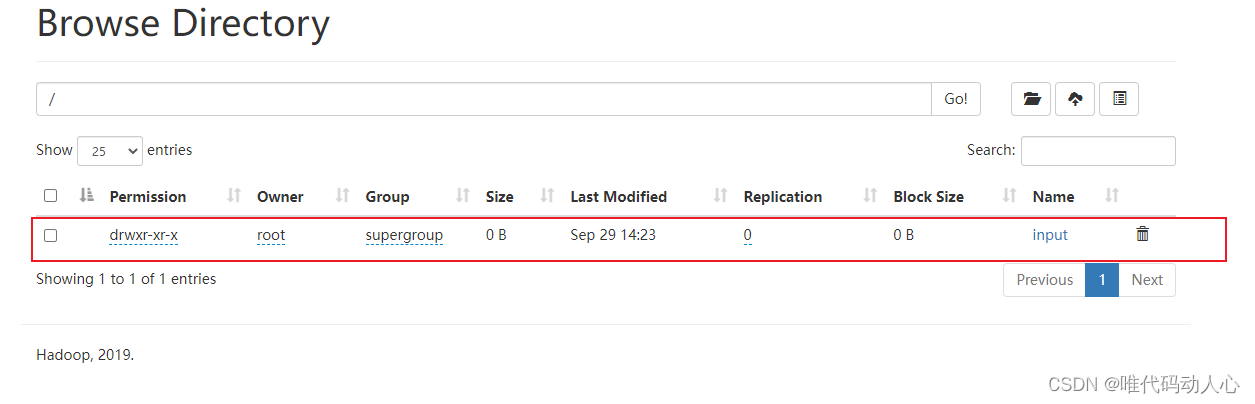
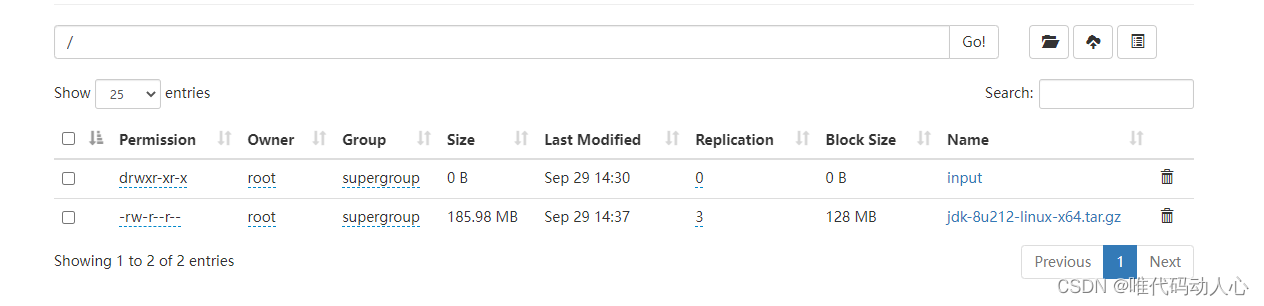
刷新HDFS的web页面http://hadoop102:9870/explorer.html#/
新建input目录
上传的README.txt文件
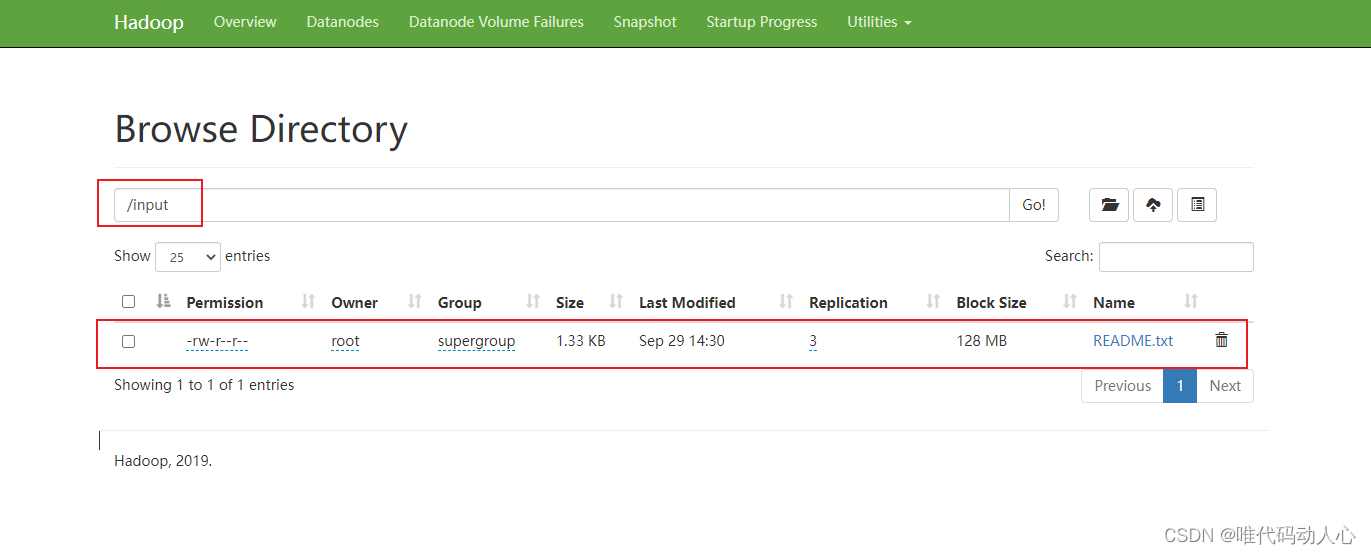
上传的 jdk-8u212-linux-x64.tar.gz
5.2 HDFS 文件存储位置
前面在core-site.xml中配置, 文件存储在/opt/module/hadoop-3.1.3/data/ 下
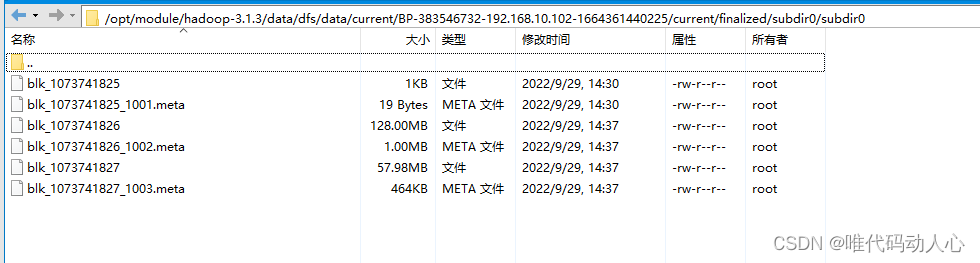
# 在 hadoop102 hadoop103 hadoop104 做个三次备份
cd /opt/module/hadoop-3.1.3/data/dfs/data/current/BP-383546732-192.168.10.102-1664361440225/current/finalized/subdir0/subdir0
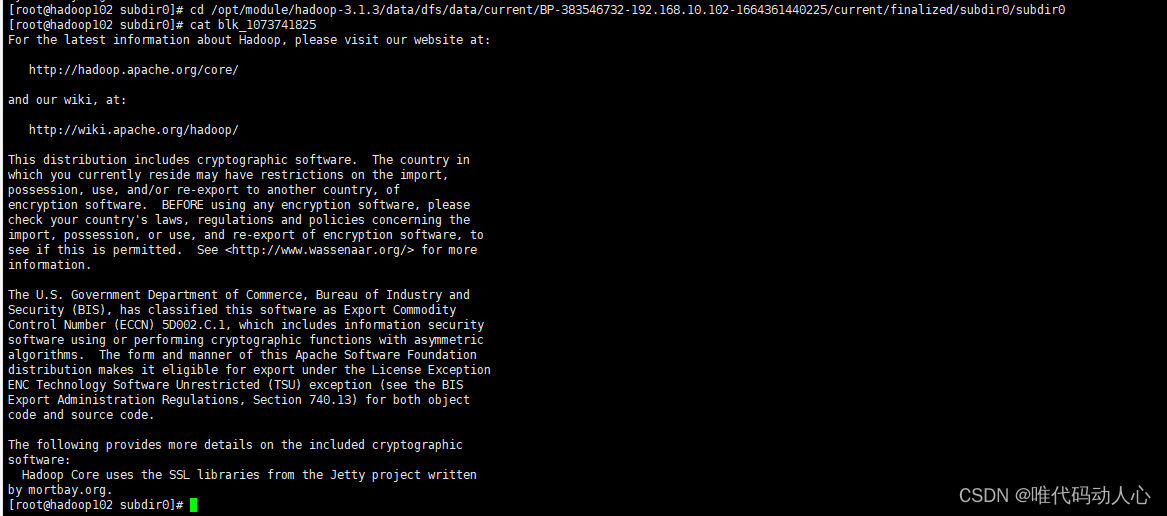
# 查看文件内容, 发现是刚刚上传的 README.txt 中的内容
cat blk_1073741825
5.3 下载HDFS 上的文件到本地
命令: hadoop fs -get HDFS上文件 本地目录
hadoop fs -get /jdk-8u212-linux-x64.tar.gz ./
5.4 测试YARN
WordCount是Hadoop默认自带的“Hello World程序”——用来单词计数
cd /opt/module/hadoop-3.1.3/
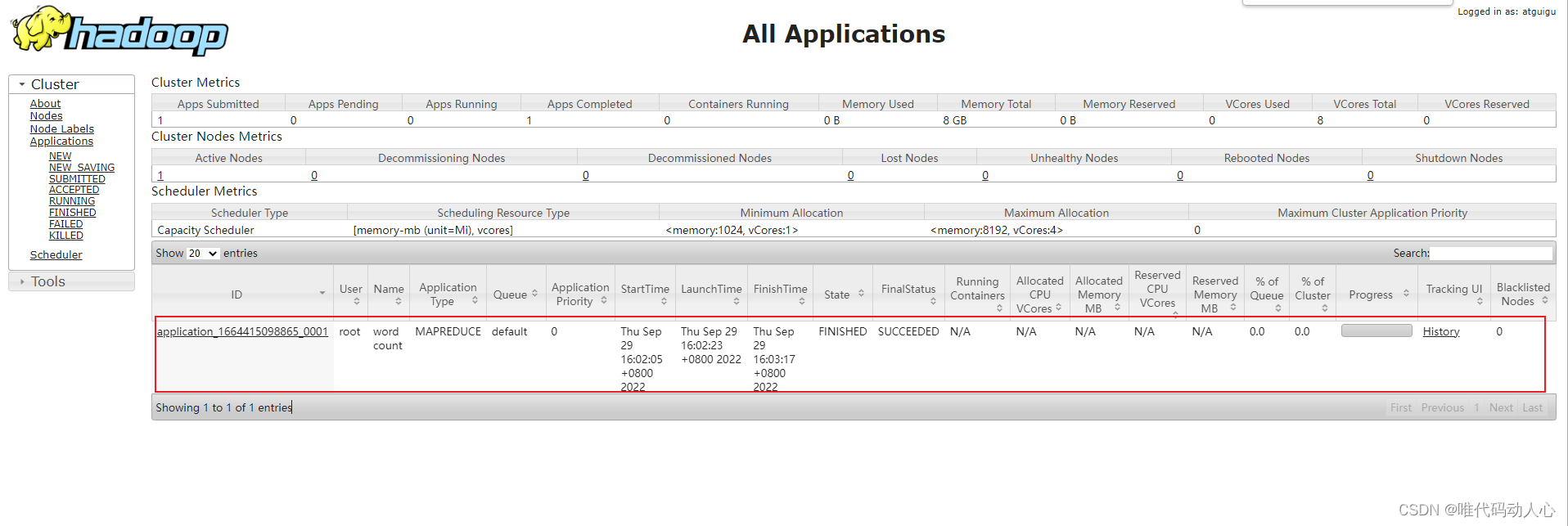
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
刷新HDFS的web页面http://hadoop102:9870/explorer.html#/
HDFS 的 / 目录下多出了一个 output 目录
刷新YARN的web页面: http://hadoop103:8088/cluster
6. 配置历史服务器
上面的YARN的web页面中点击纪录后面的 History会跳转失败, 失败的原因是没有配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器
配置mapred-site.xml
cd /opt/module/hadoop-3.1.3/etc/hadoop/
vim mapred-site.xml
在 configuration 标签中添加如下内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
</configuration>
# 分发配置
/bin/xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
# 在hadoop102启动历史服务器
mapred --daemon start historyserver
查看是否启动成功
[root@hadoop102 hadoop]# jps
12386 JobHistoryServer # 历史服务器
12419 Jps
2952 DataNode
2799 NameNode
Web端查看历史服务信息 http://hadoop102:19888/jobhistory
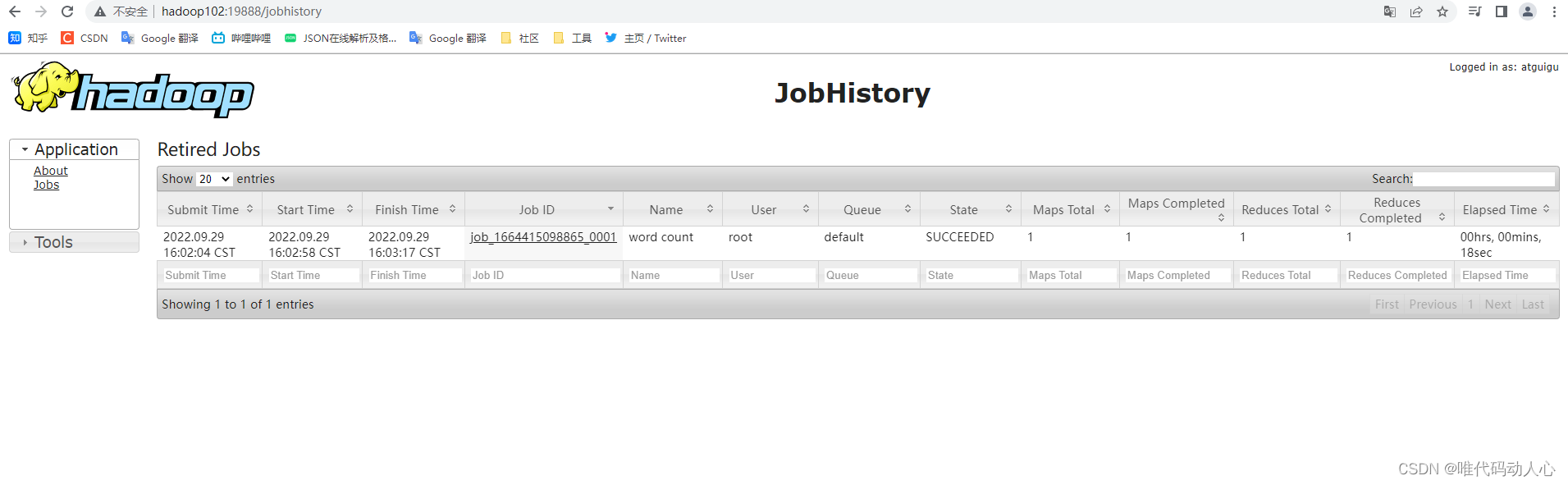
7. 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
配置yarn-site.xml
cd /opt/module/hadoop-3.1.3/etc/hadoop/
vim yarn-site.xml
在 configuration 标签中添加如下内容
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
# 分发配置
/bin/xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml
开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryServer。
# 进入hadoop目录
cd $HADOOP_HOME
# 关闭NodeManager 、ResourceManager
sbin/stop-yarn.sh
# 关闭HistoryServer
mapred --daemon stop historyserver
# 启动NodeManager 、ResourceManage
start-yarn.sh
# 启动HistoryServer
mapred --daemon start historyserver
删除HDFS中上次执行生成的文件
hadoop fs -rm -r /output
执行WordCount程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
历史记录中多出一条
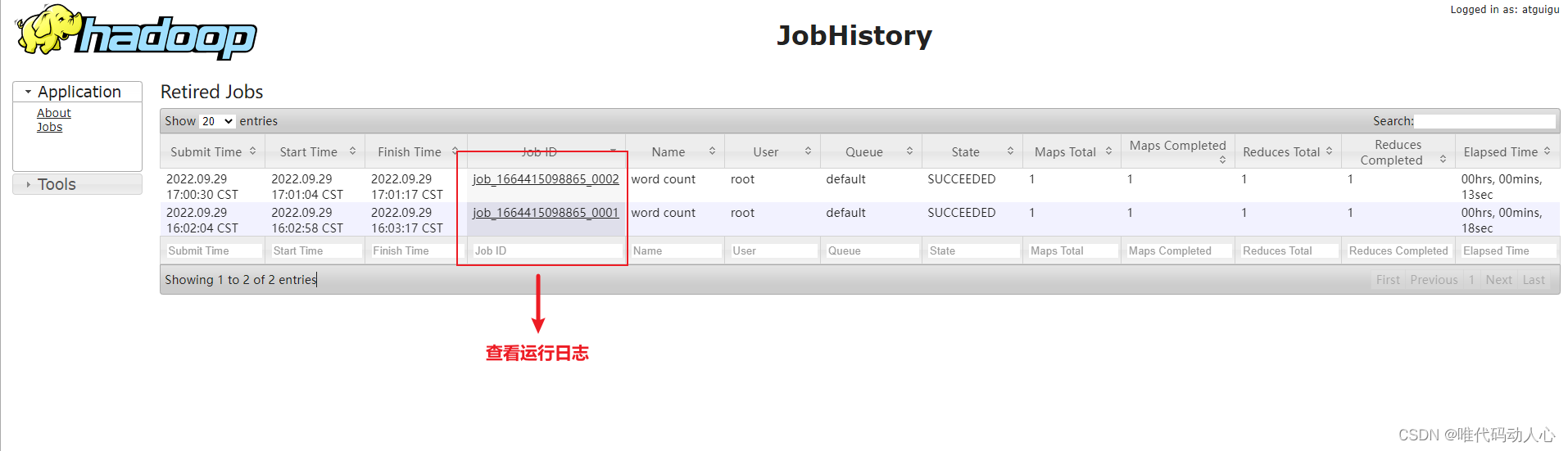
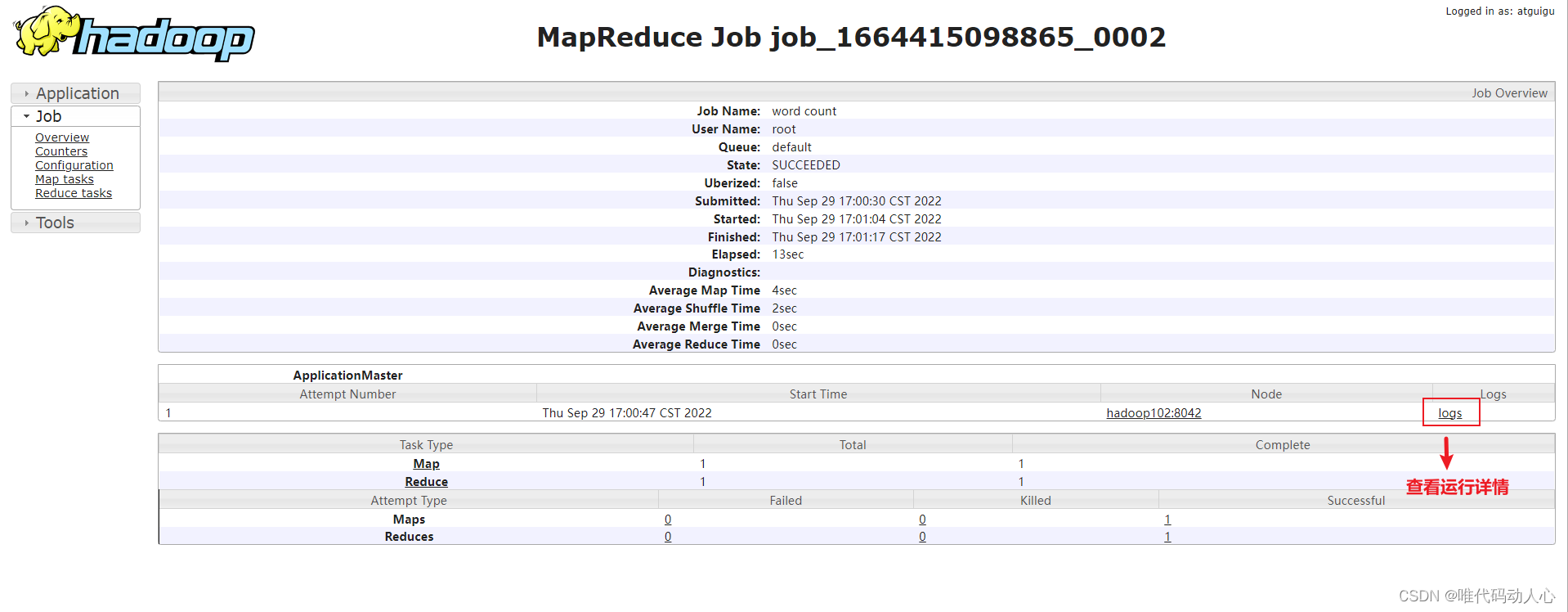
8.集群启动/停止方式总结
cd /opt/module/hadoop-3.1.3/sbin
# 启动HDFS
start-dfs.sh
# 停止HDFS
stop-dfs.sh
# 启动YARN
start-yarn.sh
# 停止YARN
stop-yarn.sh
# 关闭HistoryServer
mapred --daemon stop historyserver
cd /opt/module/hadoop-3.1.3/bin
# 启动NodeManager 、ResourceManage
start-yarn.sh
# 启动HistoryServer
mapred --daemon start historyserver
8.1 集群同时启动与停止脚本
cd /opt/module/hadoop-3.1.3/sbin
vim myhadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
给脚本执行权限
chmod +x myhadoop.sh
8.2 查看三台服务器Java进程脚本
cd /opt/module/hadoop-3.1.3/sbin
vim jpsall.sh
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo =============== $host ===============
ssh $host jps
done
给脚本执行权限
chmod +x jpsall.sh
给整个集群同步刚刚编辑的两个脚本
/bin/xsync /opt/module/hadoop-3.1.3/sbin
8.4 测试脚本
# 启动集群
myhadoop.sh start
# 停止集群
myhadoop.sh stop
# 查看三台服务器Java进程
jpsall.sh
9. 端口变动
| 端口名称 | Hadoop2.x | Hadoop3.x |
|---|---|---|
| NameNode内部通信端口 | 8020 / 9000 | 8020 / 9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
10. 集群时间同步
找一个机器,作为时间服务器,所有的机器与这台集群时间进行定时的同步,生产环境根据任务对时间的准确程度要求周期同步。
# 查看 ntpd 状态
systemctl status ntpd
# 启动 ntpd
systemctl start ntpd
# 设置 ntpd 服务开机自启动
systemctl is-enabled ntpd
修改hadoop102的ntp.conf配置文件
vim /etc/ntp.conf
将 # restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
改成 : restrict 192.168.10.0 mask 255.255.255.0 nomodify notrap
将
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
改成
# server 0.centos.pool.ntp.org iburst
# server 1.centos.pool.ntp.org iburst
# server 2.centos.pool.ntp.org iburst
# server 3.centos.pool.ntp.org iburst
添加下面两行
server 127.127.1.0
fudge 127.127.1.0 stratum 10
修改hadoop102的/etc/sysconfig/ntpd 文件
vim /etc/sysconfig/ntpd
SYNC_HWCLOCK=yes
重新启动ntpd服务
systemctl start ntpd
设置ntpd服务开机启动
systemctl enable ntpd
hadoop103 与 hadoop104中修改
# 停止 ntpd
systemctl stop ntpd
# 设置开机自启动
systemctl disable ntpd
# 添加定时任务
crontab -e
# 定时任务脚本
*/1 * * * * /usr/sbin/ntpdate hadoop102
# 更改时间
date -s "2021-9-11 11:11:11"
# 查看时间, 一分钟后再次查看时间
date
11. 遇到的问题
11.1 在虚拟机上的Hadoop启动正常,xshell 连接正常但是在浏览器中无法访问: http://hadoop102:9870
先看是否已经关闭防火墙
# 启动防火墙:
systemctl start firewalld
# 查看防火墙状态:
systemctl status firewalld
# 停止防火墙:
systemctl disable firewalld
# 禁用防火墙:
systemctl stop firewalld
再看 hadoop是否启动
jps
再看windows的 host 文件是否配置了 hadoop102映射
打开 C:\Windows\System32\drivers\etc 中的 hosts文件
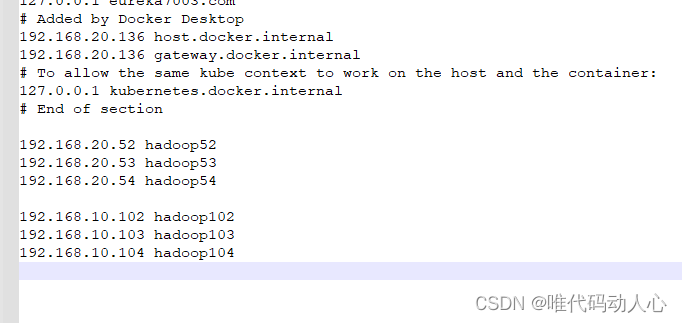
配置完成时候要刷新 windows DNS解析
打开 cmd, 输入
ipconfig/flushdns