目录
P171【171_尚硅谷_Hadoop_源码解析_RPC通信原理解析】13:44
P172【172_尚硅谷_Hadoop_源码解析_NameNode启动源码解析】21:37
P173【173_尚硅谷_Hadoop_源码解析_DataNode启动源码解析】22:10
P174【174_尚硅谷_Hadoop_源码解析_HDFS上传源码_整体介绍】07:39
P175【175_尚硅谷_Hadoop_源码解析_HDFS上传源码_create】10:13
P176【176_尚硅谷_Hadoop_源码解析_HDFS上传源码_write】23:02
P177【177_尚硅谷_Hadoop_源码解析_Yarn源码解析】21:21
P178【178_尚硅谷_Hadoop_源码解析_Hadoop源码编译】21:01
07_尚硅谷大数据技术之Hadoop(源码解析)V3.3
P171【171_尚硅谷_Hadoop_源码解析_RPC通信原理解析】13:44
第0章 RPC通信原理解析
HDFS、YARN、MapReduce三者关系:




package com.atguigu.rpc;
public interface RPCProtocol {
long versionID = 666;
void mkdirs(String path);
}package com.atguigu.rpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
// 实现通信接口
public class NNServer implements RPCProtocol {
public static void main(String[] args) throws IOException {
//启动服务
RPC.Server server = new RPC.Builder(new Configuration())
.setBindAddress("localhost")
.setPort(8888)
.setProtocol(RPCProtocol.class)
.setInstance(new NNServer())
.build();
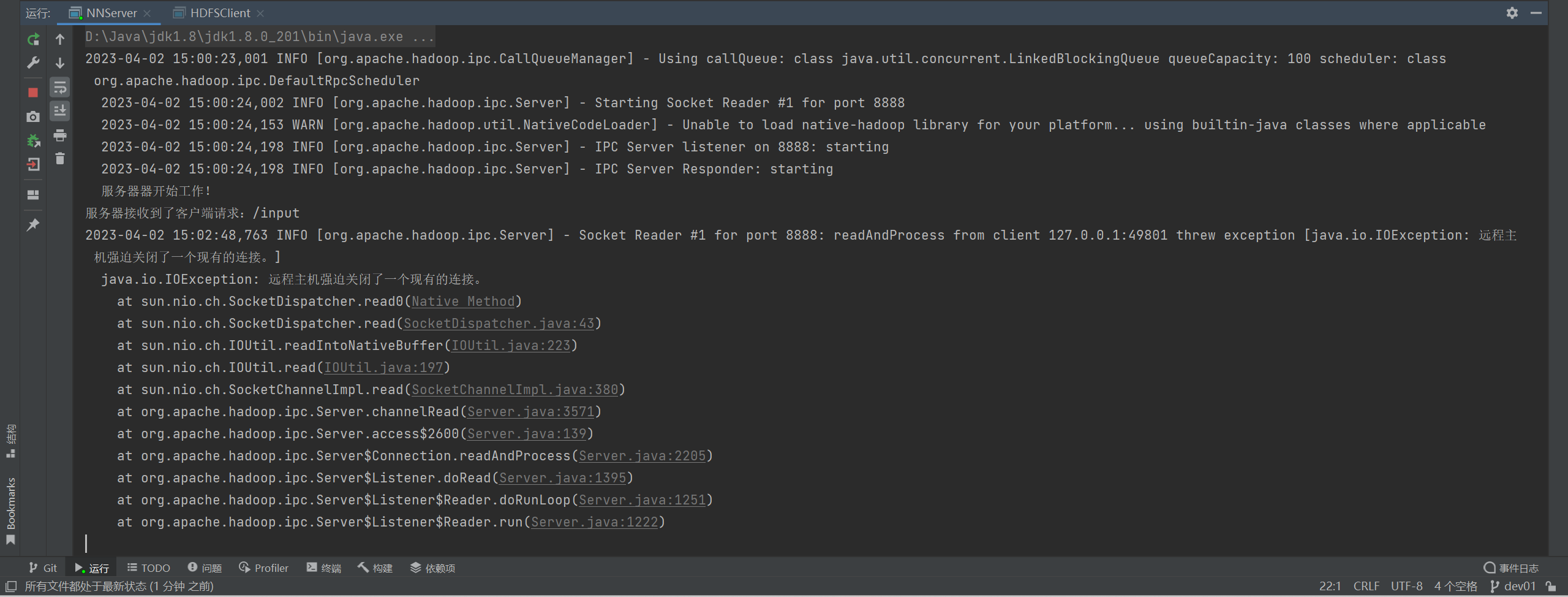
server.start();
System.out.println("服务器器开始工作!");
}
@Override
public void mkdirs(String path) {
System.out.println("服务器接收到了客户端请求:" + path);
}
}package com.atguigu.rpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
import java.net.InetSocketAddress;
public class HDFSClient {
public static void main(String[] args) throws IOException {
// 获取客户端对象
RPCProtocol client = RPC.getProxy(RPCProtocol.class, RPCProtocol.versionID, new InetSocketAddress("localhost", 8888),
new Configuration());
client.mkdirs("/input");//创建input文件夹
System.out.println("客户端开始工作!");
}
}P172【172_尚硅谷_Hadoop_源码解析_NameNode启动源码解析】21:37
第1章 NameNode启动源码解析



P173【173_尚硅谷_Hadoop_源码解析_DataNode启动源码解析】22:10
第2章 DataNode启动源码解析
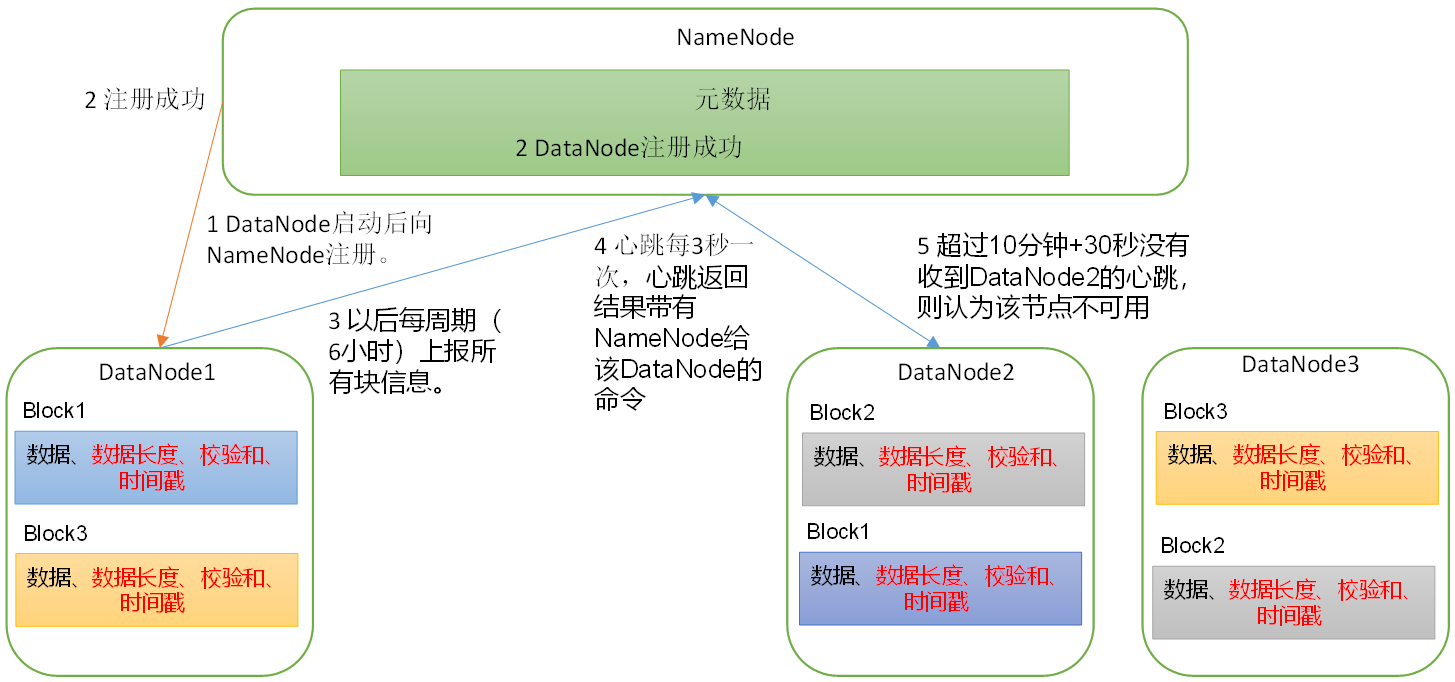
DataNode工作机制
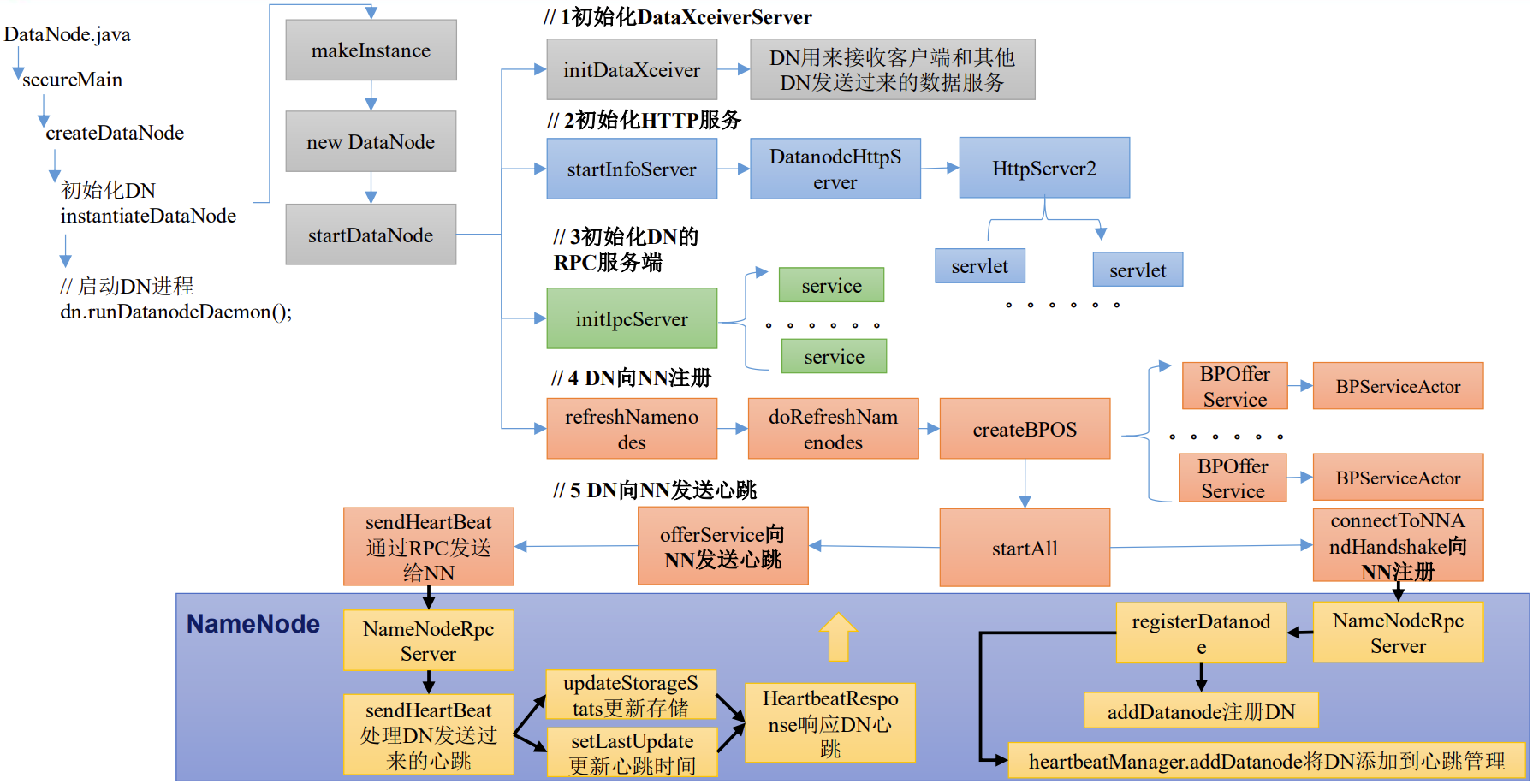
DataNode启动源码解析

P174【174_尚硅谷_Hadoop_源码解析_HDFS上传源码_整体介绍】07:39
第3章 HDFS上传源码解析
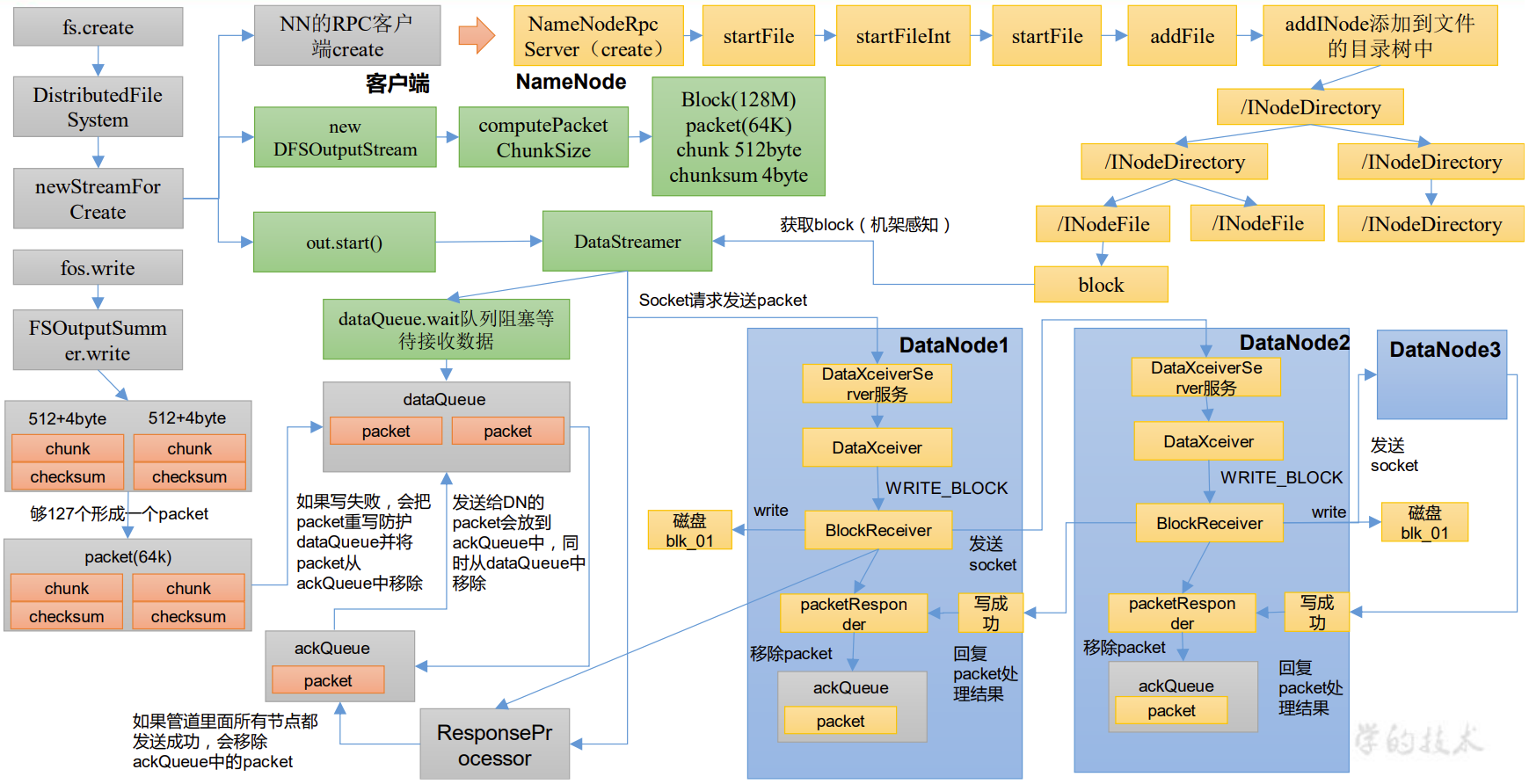
HDFS的写数据流程
HDFS上传源码解析

P175【175_尚硅谷_Hadoop_源码解析_HDFS上传源码_create】10:13

P176【176_尚硅谷_Hadoop_源码解析_HDFS上传源码_write】23:02

P177【177_尚硅谷_Hadoop_源码解析_Yarn源码解析】21:21
第4章 Yarn源码解析
Yarn工作机制
Yarn源码解析


P178【178_尚硅谷_Hadoop_源码解析_Hadoop源码编译】21:01
第5章 MapReduce源码解析
官网下载源码,Apache Hadoop






Windws环境编译源码比Linux环境编译源码麻烦,在Linux环境下编译源码速度较快!
