一、前言
本文内容从多个LLM相关的实践项目中总结而来,着重描述如何科学的在垂直领域中高效设计LLM模型训练、微调和测试的方案。
二、模型选择与微调方案选择
2.1 模型选择
热门的底座模型为:
LLaMA(7B、13B、33B、65B):拥有多个参数的不同模型可以选择,在大多数情况下表现都很好,在支持中文微调的效果上大家意见不一(如果您想要尝试引入中文训练的效果,则可以使用Chinese-LLaMA-Alpaca项目);ChatGLM(6B):原生支持中文,在中文微调任务上表现绝佳;
最终,我们推荐大家选择LLaMA作为自己垂直领域任务的微调底座模型。
2.2 微调方案选择
热门的微调方法有:
- LoRA
- QLoRA
- P-Tuning V2
- Freeze
最终,我们推荐大家选择LoRA作为自己底座模型的微调方法,在算力不充足的情况下考虑使用QLoRA即可。
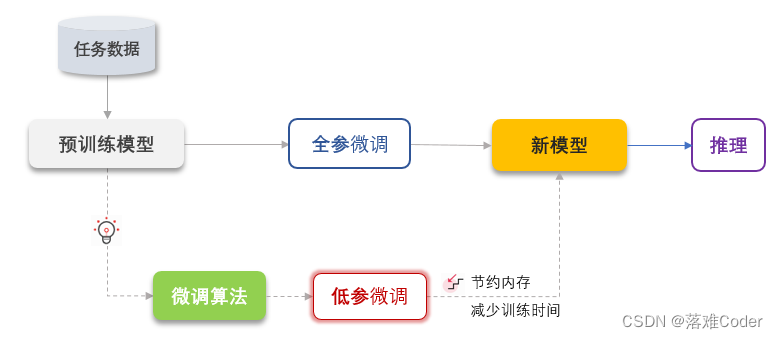
三、经典的垂直落地路径
- 预训练(可选):所谓训练就是引入大规模具体领域的数据对模型的全部参数进行重新训练,此过程需要花费大量算力和数据;
- 监督微调:引入部分领域数据进行微调训练;
- 奖励模型训练(推荐选择):所谓奖励模型训练就是在数据集中引入了人为的对于每个微调数据的评分,使得模型更贴近于人类喜欢接受的答案;
- 强化学习训练(选3必选4):利用先前训练得到的监督微调模型和奖励模型进行强化学习训练,使得模型的效果在垂直领域上进一步提升;
四、实战效果演示
在本案例中,我们使用了网上公开的中文医患对话数据集,该数据集收集了“好大夫在线”网站上的1300余条有关新型冠状病毒肺炎(COVID-19)的医患对话文本。我们的目的是根据这些对话文本微调 ChatGLM-6B 模型,使其能够模仿医生,对患者的问题进行自动诊断和答复。
我们通过以下三部得到了两个模型:
- Stage-1:监督微调; -> SFT模型
- Stage-2:奖励模型训练;
- Stage-3:强化学习训练; -> PPO模型
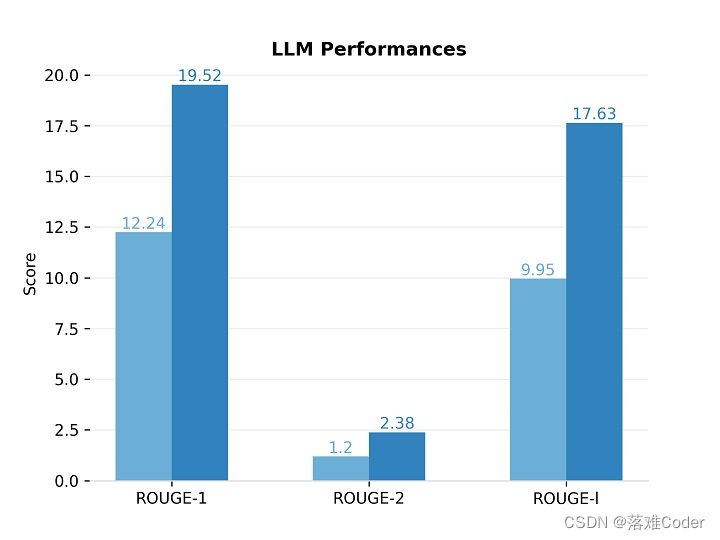
下图对比了原始 ChatGLM-6B 模型和监督微调模型在测试集上的 ROUGE 分数,可以看出,监督微调后的SFT模型在领域数据上的表现超过了原始模型。
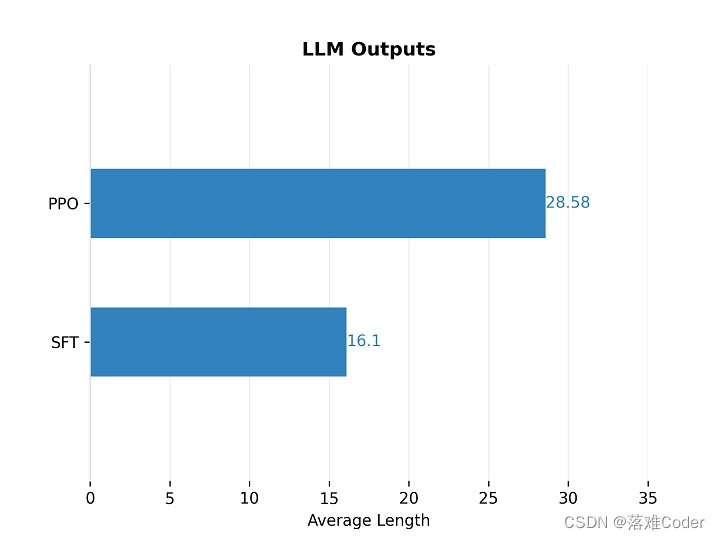
尽管监督微调模型在数据集上表现更好,但由于数据集质量不高,它往往会产生很短的回复,我们期望它能给出更详细的回答。因此在RLHF阶段,我们的目的是让模型输出更长的句子。下图对比了监督微调(SFT)模型和强化学习(PPO)模型产生的句子平均长度。可以看出,PPO 模型的回复长度显著优于 SFT 模型。
在实际测试上,我们的PPO模型输出如下:
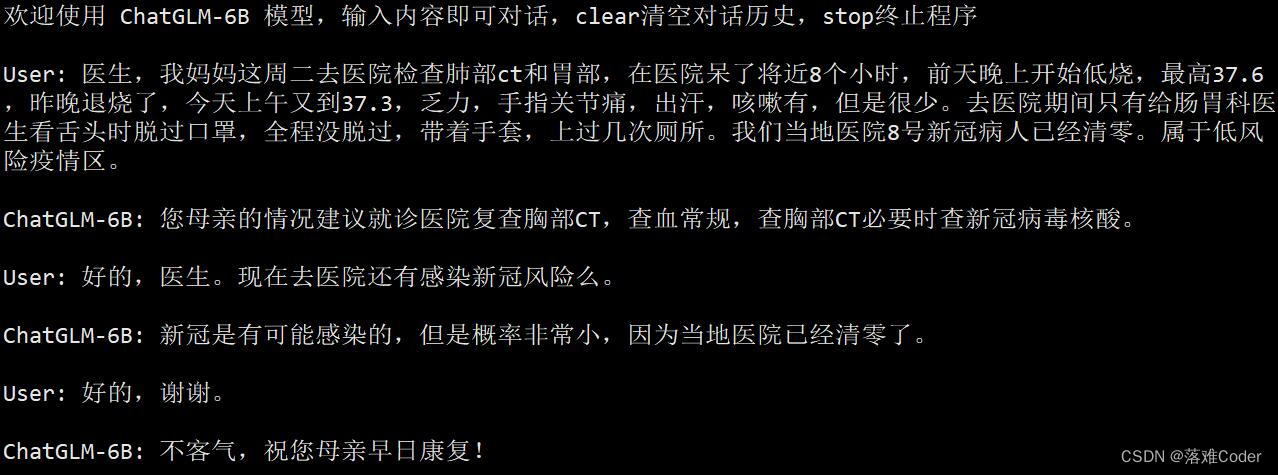
原版模型的输出如下:

在训练过程中,我们也给模型注入了领域知识,例如训练后的PPO模型还可能给出用药建议:

而原版 ChatGLM-6B 模型的回复同样比较笼统:

总结
- 大参数的模型比高精度的模型要好;
- 模型的预训练虽然会付出极高的代价,但是效果也会提升比较明显;
- 强化学习在一般的微调任务中很有必要加入;
- 适当的在数据中引入历史对话可能有一定的提升效果;
- 模型测试方法: