在现在这大规模语言模型(LLM)盛行的时代,由于模型参数和显卡配置的因素,预训练基本是大公司或者高校可以完成的事情,而对于小公司或个人,则只能对LLM进行微调,也就是说微调少量或额外的模型参数,固定大部分预训练模型(LLM)参数,从而大大降低了计算和存储成本,同时,也尽可能实现与全量参数微调相当的性能。
本文总结几种主流的微调方法,主要包括Freeze方法、P-tuning方法、Lora方法和Qlora方法。
Freeze方法
Freeze是冻结的意思,Freeze方法指的是参数冻结,对原始模型的大部分参数进行冻结,仅训练少部分的参数,这样就可以大大减少显存的占用,从而完成对大模型的微调。
P-tuning方法
P-tuning目前有两个版本。
P-Tuning v1 论文: https://arxiv.org/pdf/2103.10385.pdf
P-Tuning v2论文: https://arxiv.org/abs/2110.07602
P-tuning v1 github代码:https://github.com/THUDM/P-tuning
P-Tuning v2 github代码:https://github.com/THUDM/P-tuning-v2
prefix-tuning
prefix-tuning:Optimizing Continuous Prompts for Generation
论文地址:https://arxiv.org/abs/2101.00190
代码地址:https://github.com/XiangLi1999/PrefixTuning
在学习P-tuning之前,需要先了解下prefix-tuning,它指的是在微调模型的过程中只优化加入的一小段可学习的向量(virtual tokens)作为Prefix,而不需要优化整个模型的参数(训练的时候只更新Prefix部分的参数,而PLM中的其他部分参数固定)。
对于不同的任务和模型结构需要不同的prefix:
在autoregressive LM 前添加prefix:
z = [ P R E F I X ; x ; y ] z=[P R E F I X ; x ; y] z=[PREFIX;x;y]
在encoder和decoder之前添加prefixs:
z = [ PREFIX; x ; PREFIX ; y ] z=[\text { PREFIX; } x ; \text { PREFIX } ; y] z=[ PREFIX; x; PREFIX ;y]

对于prefix tuning可能还需要一些前置知识,soft prompt和hard prompt的概念。
prompt综述参考:
https://arxiv.org/pdf/2107.13586.pdf
https://zhuanlan.zhihu.com/p/524383554
hard prompt等同于discrete prompt;soft prompt等同于continuous prompt。
离散prompt是一个实际的文本字符串(自然语言,人工可读),通常由中文或英文词汇组成;
连续prompt通常是在向量空间优化出来的提示,通过梯度搜索之类的方式进行优化。
离散的prompts中,提示语的变化对模型最终的性能特别敏感,加一个词、少一个词或者变动位置都会造成比较大的变化。成本比较高,并且效果不太好。
显然:Prefix Tuning属于Soft prompt。
Prompt Tuning
论文:The Power of Scale for Parameter-Efficient Prompt Tuning
论文地址:https://arxiv.org/pdf/2104.08691.pdf
该方法可以看做是Prefix Tuning的简化版本,它给每个任务都定义了自己的Prompt,拼接到数据上作为输出,但只在输入层加入prompt tokens。
通过实验发现,随着预训练模型参数量的增加,Prompt Tuning的方法会逼近全参数微调的结果。
P-tuning v1
论文:GPT Understands, Too
论文地址:https://arxiv.org/abs/2103.10385
该方法的核心是使用可微的virtual token替换了原来的discrete tokens,且仅加入到输入层,并使用prompt encoder(BiLSTM+MLP)对virtual token进行编码学习。
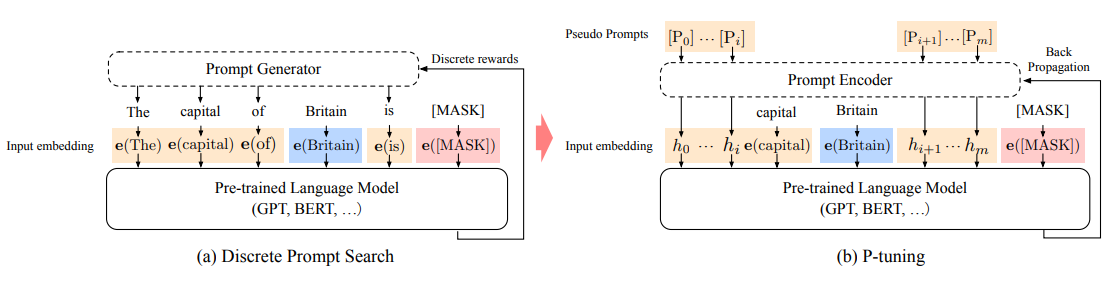
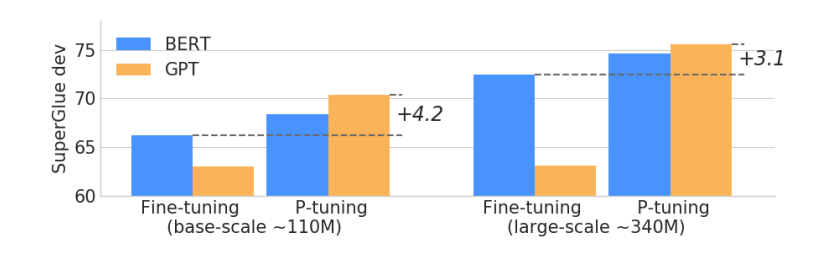
效果:相同参数规模,如果进行全参数微调,Bert的在NLU任务上的效果,超过GPT很多;但是在P-Tuning下,GPT可以取得超越Bert的效果。
之前的Prompt Tuning和P-Tuning等方法存在两个主要的问题:
第一,缺乏模型参数规模和任务通用性。
- 缺乏规模通用性:Prompt Tuning论文中表明当模型规模超过100亿个参数时,提示优化可以与全量微调相媲美。但是对于那些较小的模型(从100M到1B),提示优化和全量微调的表现有很大差异,这大大限制了提示优化的适用性。
- 缺乏任务普遍性:尽管Prompt Tuning和P-tuning在一些 NLU 基准测试中表现出优势,但提示调优对硬序列标记任务(即序列标注)的有效性尚未得到验证。
第二,缺少深度提示优化,在Prompt Tuning和P-tuning中,连续提示只被插入transformer第一层的输入embedding序列中,在接下来的transformer层中,插入连续提示的位置的embedding是由之前的transformer层计算出来的,这可能导致两个可能的优化挑战。
由于序列长度的限制,可调参数的数量是有限的。
输入embedding对模型预测只有相对间接的影响。
这些问题在P-tuning v2得到了改进。
P-tuning v2
论文:P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks
论文地址:https://arxiv.org/abs/2110.07602
P-Tuning v2主要是基于P-tuning和prefix-tuning技术,引入Deep Prompt Encoding和Multi-task Learning等策略进行优化的。
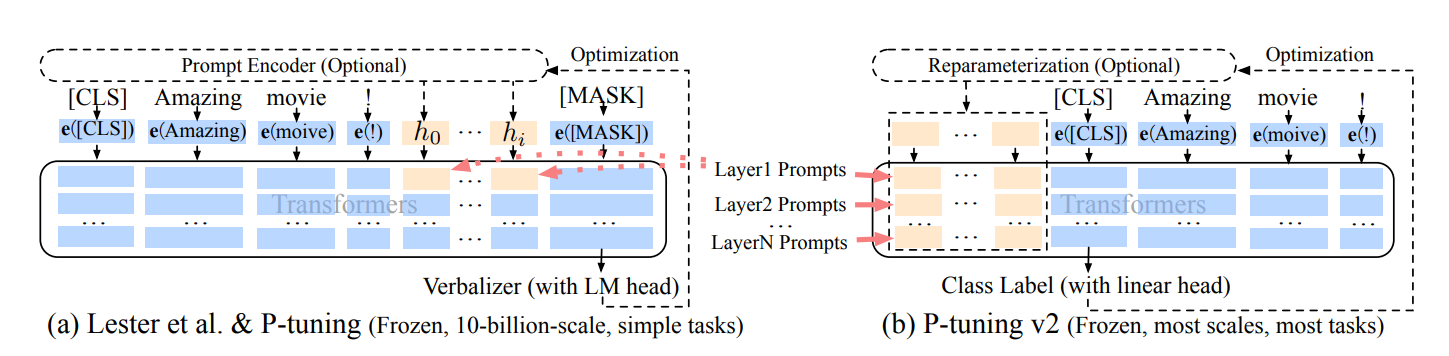
Deep Prompt Encoding
P-Tuning v2在每一层都加入了Prompts tokens作为输入,而不是仅仅加在输入层,这带来两个方面的好处:
- 更多可学习的参数(从P-tuning和Prompt Tuning的0.01%增加到0.1%-3%),同时也足够参数高效。
- 加入到更深层结构中的Prompt能给模型预测带来更直接的影响。
Multi-task learning
基于多任务数据集的Prompt进行预训练,然后再适配到下游任务。对于pseudo token的continous prompt,随机初始化比较难以优化,因此采用multi-task方法同时训练多个数据集,共享continuous prompts去进行多任务预训练,可以让prompt有比较好的初始化。
P-Tuning v2是一种在不同规模和任务中都可与微调相媲美的提示方法。P-Tuning v2对从330M到10B的模型显示出一致的改进,并在序列标注等困难的序列任务上以很大的幅度超过了Prompt Tuning和P-Tuning。
Lora方法
论文:LoRA: Low-Rank Adaptation of Large Language Models
论文地址:https://arxiv.org/abs/2106.09685
官方代码github:https://github.com/microsoft/LoRA
HuggingFace封装的peft库:https://github.com/huggingface/peft
Lora方法,指的是在大型语言模型上对指定参数增加额外的低秩矩阵,也就是在原始PLM旁边增加一个旁路,做一个降维再升维的操作。并在模型训练过程中,固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。用随机高斯分布初始化A,用0矩阵初始化B,保证训练的开始此旁路矩阵依然是0矩阵。
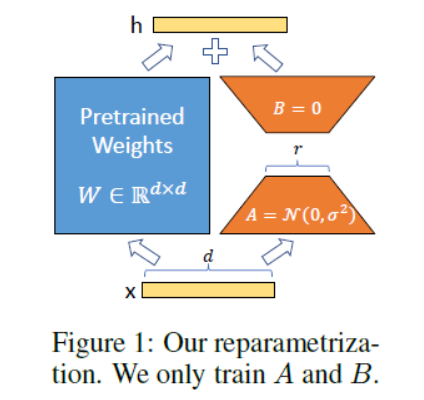
具体来看,假设预训练的矩阵为 W 0 ∈ R d × k W_0 \in \mathbb{R}^{d \times k} W0∈Rd×k ,它的更新可表示为:
W 0 + Δ W = W 0 + B A , B ∈ R d × r , A ∈ R r × k W_0+\Delta W=W_0+B A, B \in \mathbb{R}^{d \times r}, A \in \mathbb{R}^{r \times k} W0+ΔW=W0+BA,B∈Rd×r,A∈Rr×k其中秩 r < < min ( d , k ) r<<\min (d, k) r<<min(d,k) 。
对于 h = W 0 x h=W_0 x h=W0x ,它的前向计算变为:
h = W 0 x + Δ W x = W 0 x + B A x = ( W 0 + B A ) x h=W_0 x+\Delta W x=W_0 x+B A x=\left(W_0+B A\right) x h=W0x+ΔWx=W0x+BAx=(W0+BA)xLora的这种思想有点类似于残差连接,同时使用这个旁路的更新来模拟full finetuning的过程。
LoRA 的最大优势是速度更快,使用的内存更少,因此可以在消费级硬件上运行。
在多卡训练时,Lora也是效率很高的,在多卡训练中,LoRA的速度优势主要体现在两个方面: 1. 计算效率:由于LoRA只需要计算和优化注入的低秩矩阵,因此它的计算效率比完全微调更高。在多卡训练中,LoRA可以将注入矩阵的计算和优化分配到多个GPU上,从而加速训练过程。 2. 通信效率:在多卡训练中,通信效率通常是一个瓶颈。由于LoRA只需要通信注入矩阵的参数,因此它的通信效率比完全微调更高。在多卡训练中,LoRA可以将注入矩阵的参数分配到多个GPU上,从而减少通信量和通信时间。 因此,LoRA在多卡训练中通常比完全微调更快。具体来说,LoRA可以将硬件门槛降低多达3倍,从而提高训练的效率。
Qlora方法
论文:QLORA: Efficient Finetuning of Quantized LLMs
论文地址:https://arxiv.org/abs/2305.14314
作者提出了一种可以在不降低任何性能的情况下微调量化为 4 bit模型的方法。
核心点如下:
- 4bit NormalFloat(NF4):对于正态分布权重而言,一种信息理论上最优的新数据类型,该数据类型对正态分布数据产生比 4 bit整数和 4bit 浮点数更好的实证结果。
- 双量化:对第一次量化后的那些常量再进行一次量化,减少存储空间。
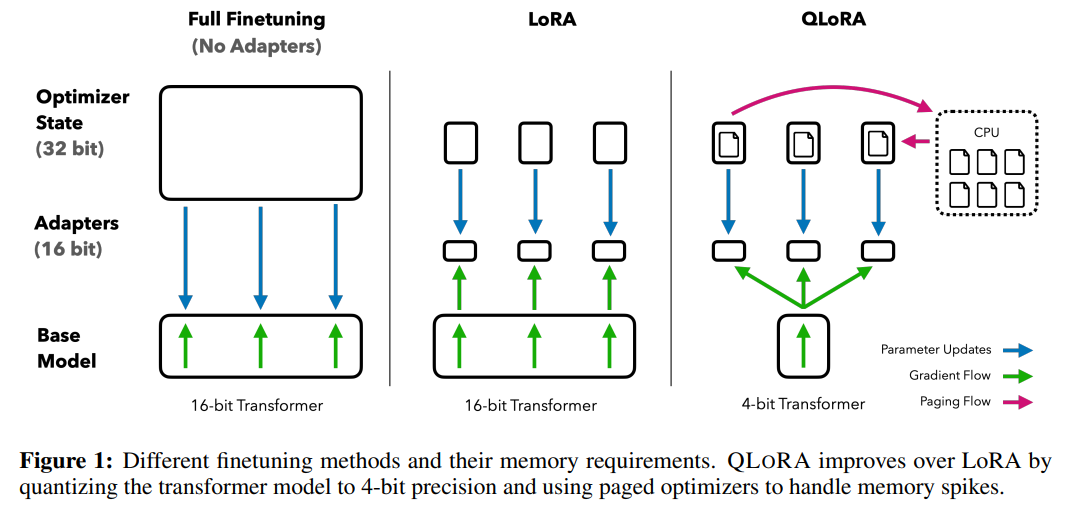
- 分页优化器:使用NVIDIA统一内存特性,该特性可以在在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页到分页的传输,以实现无错误的 GPU 处理。该功能的工作方式类似于 CPU 内存和磁盘之间的常规内存分页。使用此功能为优化器状态(Optimizer)分配分页内存,然后在 GPU 内存不足时将其自动卸载到 CPU 内存,并在优化器更新步骤需要时将其加载回 GPU 内存。
实验证明,无论是使用16bit、8bit还是4bit的适配器方法,都能够复制16bit全参数微调的基准性能。这说明,尽管量化过程中会存在性能损失,但通过适配器微调,完全可以恢复这些性能。
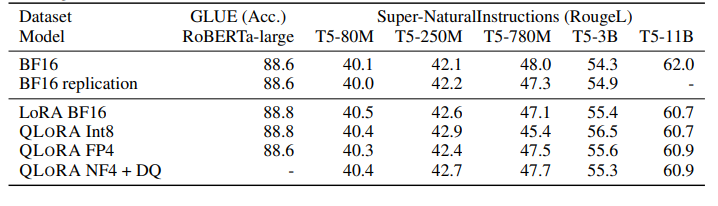
实验还比较了不同的4bit数据类型对效果(zero-shot均值)的影响,其中,NFloat 显著优于Float,而NFloat + DQ略微优于NFloat,虽然DQ对精度提升不大,但是对于内存控制效果更好。
参考:
https://finisky.github.io/lora/
大模型参数高效微调技术原理综述(二)-BitFit、Prefix Tuning、Prompt Tuning
大模型参数高效微调技术原理综述(三)-P-Tuning、P-Tuning v2
大模型参数高效微调技术原理综述(五)-LoRA、AdaLoRA、QLoRA