一、前言
由于现在的课题为安卓恶意应用软件检测,需要从头至尾先把一些简单的检测算法跑一遍,熟悉一下。因此,本篇文章将介绍一下准备工作,如何获取安卓应用。为了更加高效,才使用爬虫批量下载,看了几篇前人的文章,由于都有些年头了,现在重新自己开始实践。
二、准备工作
先找到可以下载安卓应用的网址,我是参照的参考文献[3]。

在这里直接点击安装就会获取到apk文件。
浏览器F12,看到界面源代码
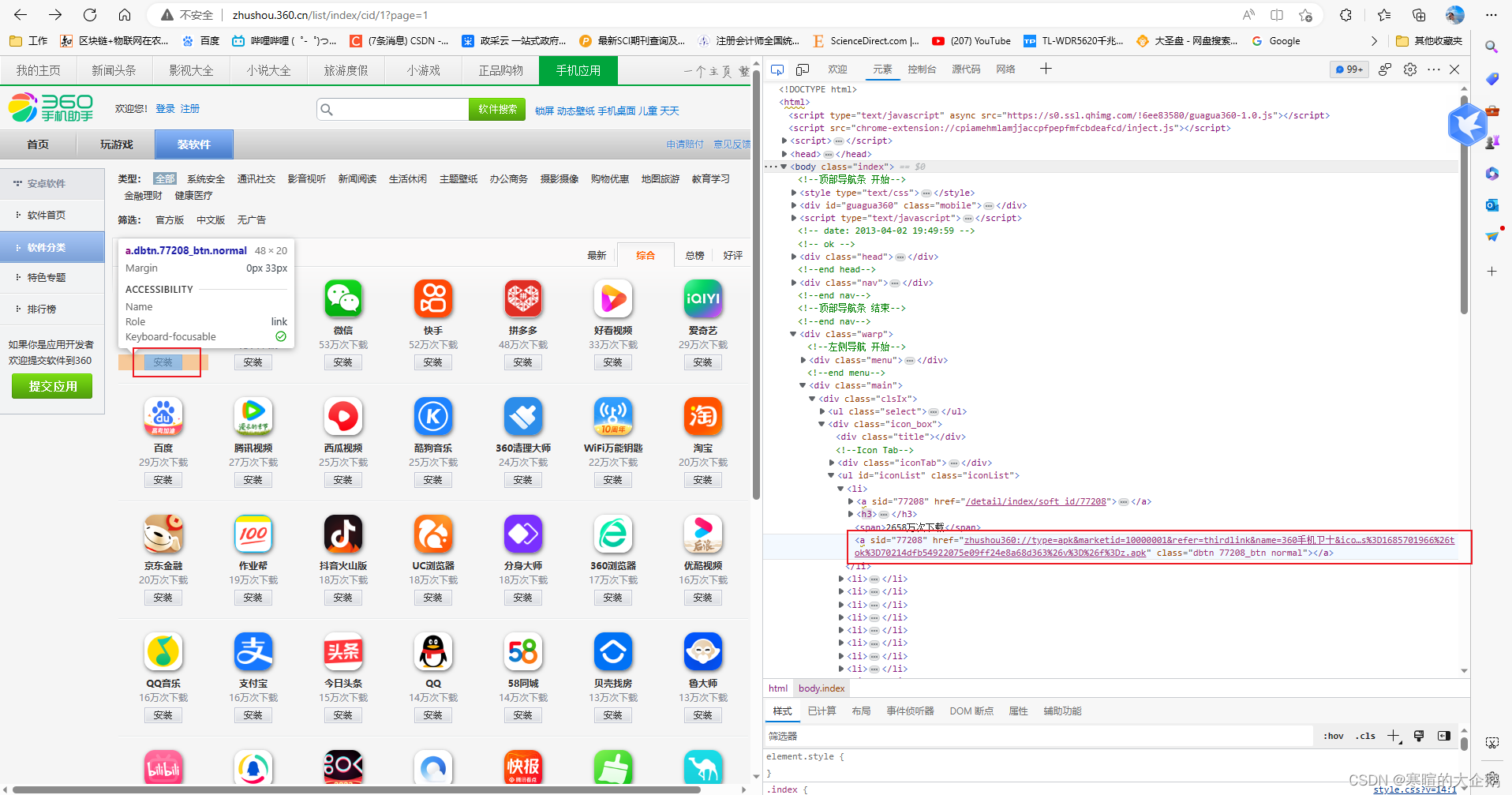
我们看到“安装”的页面代码:
http://zhushou.360.cn/list/index/cid/zhushou360://type=apk&marketid=10000001&refer=thirdlink&name=360%E6%89%8B%E6%9C%BA%E5%8D%AB%E5%A3%AB&icon=https://p0.qhimg.com/t01f16f431505dee4ad.png&appmd5=c4249385750f94882ab3d08b6dddc578&softid=77208&appadb=&url=http://s.shouji.qihucdn.com/220816/c4249385750f94882ab3d08b6dddc578/com.qihoo360.mobilesafe_280.apk?en=curpage%3D%26exp%3D1686306766%26from%3DAppList_json%26m2%3D%26ts%3D1685701966%26tok%3D70214dfb54922075e09ff24e8a68d363%26v%3D%26f%3Dz.apk
如果这时候你有迅雷,复制这段代码到迅雷,他就能识别出来:

我们看到其实正真起作用下载的url其实是这个:http://s.shouji.qihucdn.com/220816/c4249385750f94882ab3d08b6dddc578/com.qihoo360.mobilesafe_280.apk?en=curpage%3D%26exp%3D1686306766%26from%3DAppList_json%26m2%3D%26ts%3D1685701966%26tok%3D70214dfb54922075e09ff24e8a68d363%26v%3D%26f%3Dz.apk
因此,我们需要使用正则表达式,将这个页面中的url提取出来:
link_list = re.findall(r"(?<=&url=).*?apk.*?apk", html)
我们看到上述代码中有两个apk这是因为,如果你只写一个,他会默认识别到第一个apk为止,那样的话是下载不了的,因此,在这里需要写两个apk。
正则表达式个人也不熟悉,查阅资料这么解释的:
.? 表示匹配任意字符到下一个符合条件的字符
例子:正则表达式a.?bbb 可以匹配 acbbb abbbbb accccccccbbb
三、开始爬取下载
话不多说,上图和完整代码:
注意我在目录下方创建的restore文件包,通过urlretrieve把下载好的内容存储进来。
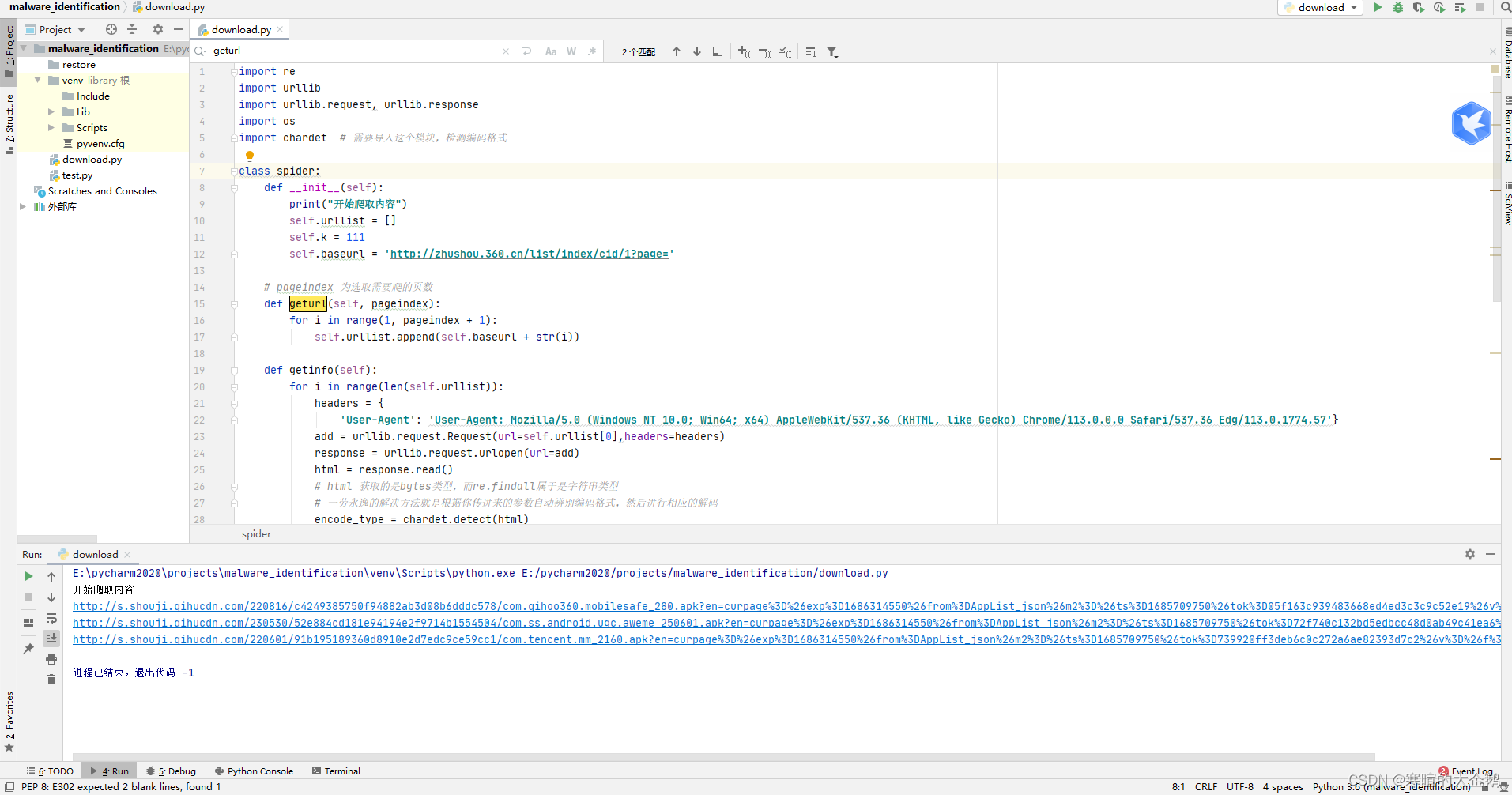
import re
import urllib
import urllib.request, urllib.response
import os
import chardet # 需要导入这个模块,检测编码格式
class spider:
def __init__(self):
print("开始爬取内容")
self.urllist = []
self.k = 111
self.baseurl = 'http://zhushou.360.cn/list/index/cid/1?page='
# pageindex 为选取需要爬的页数
def geturl(self, pageindex):
for i in range(1, pageindex + 1):
self.urllist.append(self.baseurl + str(i))
def getinfo(self):
for i in range(len(self.urllist)):
headers = {
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57'}
add = urllib.request.Request(url=self.urllist[0],headers=headers)
response = urllib.request.urlopen(url=add)
html = response.read()
# html 获取的是bytes类型,而re.findall属于是字符串类型
# 一劳永逸的解决方法就是根据你传进来的参数自动辨别编码格式,然后进行相应的解码
encode_type = chardet.detect(html)
html = html.decode(encode_type['encoding']) # 进行相应解码,赋给原标识符(变量)
# print(html)
# 在这里获取到的是本页的html内容,找到li标签链接中url=.apk中的内容
link_list = re.findall(r"(?<=&url=).*?apk.*?apk", html)
for url in link_list:
file_name = "%d.apk"%(self.k)
self.k = self.k + 1
file_path = os.path.join("restore", file_name)
print(url)
urllib.request.urlretrieve(url, file_path)
# print(self.urllist)
# 把上一页爬取到的地址清除,这样下一页就是要再次循环爬取的内容
del self.urllist[0]
if __name__ == '__main__':
a = spider()
# 作为实验,我们仅批量下载第一页的所有软件
a.geturl(1)
a.getinfo()
四、结语
目前刚刚涉猎爬虫,个人认为主要是一种工具,后续用作安卓恶意软件静态分析。
参考文献
[1] Python爬虫之抓取APP下载链接
[2] 用python批量下载apk
[3] 使用python批量爬取apk文件
[4] 正则表达式 (.*?)