基于深度学习的Reid主要流程为输入图像-->CNN(提取特征)-->Global average pooling-->特征向量,将用这些特征来衡量图像的相似情况。并用这些特征进行检索,返回分类情况。
在训练网络的时候需要涉及损失函数,因此就引出了表征学习和度量学习。
表征学习:在训练期间没有考虑图片的相似度,而仅仅是把行人重识别任务当作分类问题或者验证问题来看待,用这种方式辅助网络学习特征间的相似度。
度量学习:训练期间考虑了两张图的相似度,表现为同一行人的不同图片间的相似度大于不同行人的不同图片。(可以理解为正样本间的距离大于负样本距离)。
目录
2.3 改进的三元组损失(Improved triplet loss)
1 表征学习
分类损失:也称为ID损失,利用行人的ID作为训练标签,每次只需要输入一张图片。【可类比为猫狗分类,标签0代表猫,标签1代表狗】。相同之间的ID距离会拉近, 不同ID之间的距离会拉远。
验证损失:输入一对(两张)行人图片,让网络学习这两张图片是否属于同一个人,等效于二分类。
1.1 分类损失
只用分类损失(ID损失)训练的网络称为IDE网络(ID embedding)。特征层后接一个FC层,经过softmax计算交叉熵损失。参考下图,ResNet是用来做特征提取,ReID特征是我们Pool后得到的特征,然后需要用FC对这些特征进行分类(比如markt1501训练的时候分类为751类),然后经过softmax获取最终的输出。黄色框内的过程就是计算分类损失的过程。
但是!在测试的时候,是不需要用到FC层,是用我们的Reid特征,也就是Pool后得到的特征来做检索,丢弃FC层(只在训练的时候有FC层)。

1.1.1 属性损失(Attribute loss)
在进行Reid识别的时候可以通过一些辅助特征来判断是否为同一人,比如衣服的颜色,头发的颜色等。这种网络的结构设计如下,如果你属性预测的准,那么你最好得到的ID也就准。这种网络的特点为:
1.可以同时连接几个属性分类损失增强ReID特征的性能;
2.每一个属性损失都是一个分类的交叉熵;
3.这种结构的网络可以理解为一个multi-task网络(多任务网络),因为有很多FC层;
4.测试的时候也是丢弃FC层,只用Pool层。

1.2 验证损失(Verification loss)
1.验证损失每次输入一对(两张)图片,进入同一个Siamese(孪生)网络进行特征提取。对应到图中就是上下均为一对(就是上面输入两张,下面的分支输入两张,那就是4张图)。那么两个网络就会提取两个特征,然后可以用这两个网络输出的特征进行相减来提取特征差异(对应到上面分支最终输出的虚线框,yi-yj),然后再经过FC层做一个二分类,判断是否为同一个人。
2.融合两个网络的特征信息计算一个二分类损失;
3.训练阶段可以和ID损失一起使用;
4.测试阶段每次输入两张图片,直接判断两个人是否为同一人。

1.3 表征学习总结
1.不学习图片之间的相似性;
2.通常需要额外的FC层来辅助特征学习,测试阶段FC层则丢弃;
3.ID损失(分类损失)的FC层维度需要和ID数量一致,当训练集太大时难以收敛;
4.验证损失测试的时候需要输入一对图像,识别率低;
5.表征学习通常情况下训练比较稳定,结果易复现;
6.表征学习的分布式训练通常比较成熟;
2 度量学习
度量学习的目的是学习两张图片的相似性。这个相似性可以用以下映射关系表示:
上式表示为F维的图像空间映射到D维的特征空间。(该过程就是特征提取的过程)
然后再定义一个度量函数,这个度量函数是希望对两个特征向量进行距离上的判断。
距离的公式常用的有:
欧式距离:
余弦距离:
在度量学习中我们希望两个正样本的距离尽可能的小(表示为同一个人),负样本的距离尽可能大(不同行人)。
上面的过程就是在特征空间上聚类的过程。
传统的度量学习过程为下面这个式子:这个式子的含义是,D为距离函数,xi和xj是两个图像的特征,T表示向量转置,M是一个矩阵(这个M是可学习的)。而这两个x是手工提取的特征,比如HOG。
而在深度学习中的度量学习,这个矩阵M就是一个欧式距离,深度学习中学习特征x,而不是矩阵M。因为M的矩阵可以分解为,因此这个矩阵是可以找到近似解的,而这个矩阵是可以通过FC层进行拟合的,所以相当于在训练过程中,这个矩阵的解是已经近似拟合出来的,可以使其称为特征x的一部分,那么剩下学习的就只有特征x了。
上面这一段文字说的是传统学习和深度学习中度量函数思想的不同,如果不理解也没有关系,并不影响下面的学习。
常用的度量学习损失函数有:
1.对比损失(Contrastive loss)
2.三元组损失(Triplet loss)
3.改进的三元组损失(Improved triplet loss)
4.四元组损失(Quadruplet loss)
5.TriHard loss
2.1 对比损失(Contrastive loss)
同样也是孪生网络结构,输入两个图片,拉近正样本对间的距离趋于0(y=1),推开负样本对距离大于α(y=0),y是标签(表示是否为同一个人),α是手动设置的阈值,比如0.5,0.6。就是计算这个孪生网络中两个输出的之间的欧式距离。

2.2 三元组损失(Triplet loss)
需要输入3张图片。关键是这三张图片是怎样的图片。这三张图片可以称为anchor,Positive【与anchor是同一个行人就是正样本图片】,Negative【与anchor不是同一个人的就是负样本图片】。也就是,三张图片是有两个ID的。学习的过程就是拉近正样本之间的距离,推开负样本之间的距离。这个过程其实就是样本的匹配过程。(如果你学过目标检测,里面也有这个概念,anchor和box的IOU关系来表示正负样本)。

设计的损失函数为:
不过上面这种设计是有缺陷的,上面这种没有考虑到的绝对距离,这样的话会在做跟踪任务中失效。打个比方,假设我此时设置的α为0.3,
,
,此时得到的L=0.1,然后假设
,
的时候,L还是等于0.1。虽然这在做检索问题的时候问题不大,但在跟踪问题时就容易出问题了。
2.3 改进的三元组损失(Improved triplet loss)
了解决这个缺点就需要改进三元组损失。公式如下。
2.4 四元组损失(Quadruplet loss)
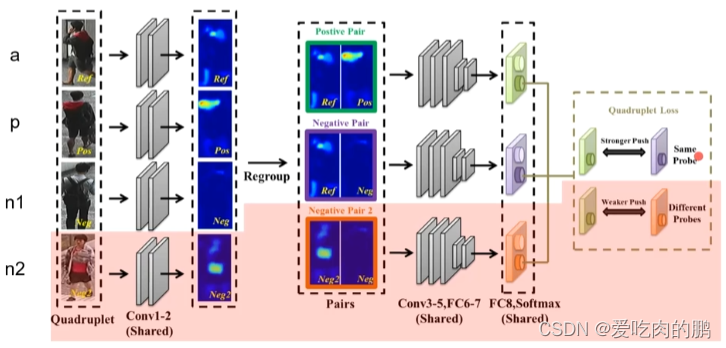
四元组损失是三元组损失的改进版。每次输入四张图片,a:anchor图片,p:正样本,n1,n2是两个负样本图片。
1.输入四个图片,那么就有3个ID;
2.损失函数的第一项为三元组损失函数,第二项为弱推动的三元组损失函数;
2.5 TriHard loss
这个loss的提出,主要是希望网络可以关注困难样本。
核心思想是:对于每一个训练的batch(也就是batch的选择),挑选P个ID的行人(不同类),然后这每个行人又随机挑选K张不同的图片,那么就是一个batch中有PxK张图片。之后对于batch中的每一张图片a,可以随机挑选一个最困难的正样本和最困难的负样本组成三元组。
定义两个集合A、B,A是与图片a相同ID的集合(也就是这个集合中全是a这个人),B就是和a不是一个人的集合。则损失函数为:
在正样本对里取最大距离为最困难的正样本;(表示为是同一个ID,但很难区分)
在负样本对里取最小的距离为最困难的负样本;(表示为不是同一个ID,但特征看起来非常的像)
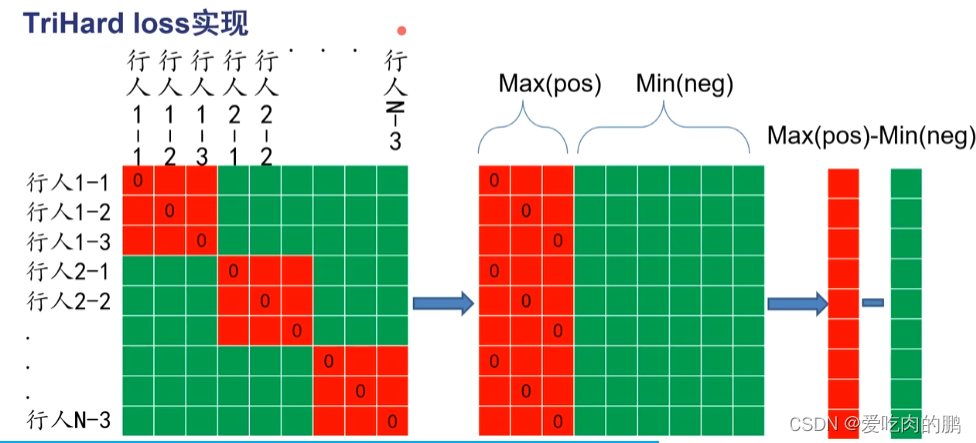
TriHard loss的实现过程为:
下图中的每个矩阵为距离矩阵,假设现在有N个人(那就是N个ID,就是P=N),每个人挑选3张图(K=3),则此时的batch就有3N张图片,则可以提取3N个特征,对这3N个特征两两计算距离,那就可以得到一个3NX3N的距离矩阵(第一个矩阵)。可以看红色矩阵内像素为0的值,就是表明同一张图片的距离,那么距离肯定为0,红色矩阵就是表示为同一ID的人(也就是正样本对),绿色就是负样本对之间的距离。第二个矩阵是对第一个矩阵的平移(或者说是重组),把所有的正样本(红色)挪到左边,负样本对(绿色)移动到右边,然后在每一行去一个最大距离(Max(pos)),这就是最困的正样本,每一行取最小的(Min(neg))表示为最困难的负样本。然后我们让Max(pos)-Min(neg)【这两个向量的长度都是3N维度的】。这个过程就是对上面的公式的实现。
不过这种Loss是只考虑的极端情况,如果数据集中打标签的时候出现了大量的错误,网络容易奔溃。
2.6 度量学习的总结
1.可直接学习图片之间的相似性;
2.不需要额外的FC层来辅助特征学习;
3.网络大小与训练集规模无关,但是数据采样器时间会增加;
4.TriHard loss为目前业界度量学习的标杆;
5.度量学习通常而言训练比较随机,需要有一定的训练经验;
6.度量学习的分布式训练不太成熟,通常需要自己实现这部分代码;
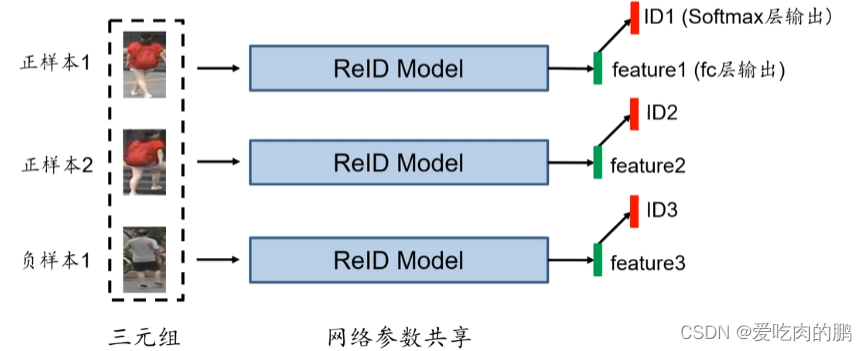
是否可以将表征学习和度量学习进行组合训练呢?答案肯定是可以的。就是如下图所示。就是三个图片输入(2个ID),将会提取3个特征f1,f2,f3,同时还可以跟表征学习,加入FC层,得到分类情况ID1,ID2,ID3。
测试阶段的FC测将被丢弃。