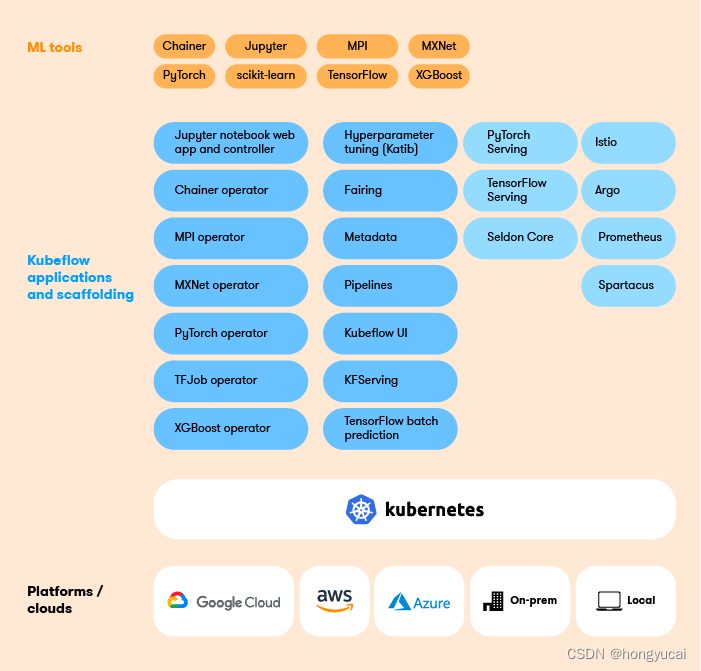
Kubeflow提供了一大堆组件,涵盖了机器学习的方方面面,为了对Kubeflow有个更直观深入的了解,先整体看一下Kubeflow都有哪些组件,并对Kubeflow的主要组件进行简单的介绍:
(1) Central Dashboard:Kubeflow的dashboard看板页面
(2) Metadata:用于跟踪各数据集、作业与模型
(3) Jupyter Notebooks:一个交互式业务IDE编码环境
(4) Frameworks for Training:支持的ML框架
Chainer MPI MXNet PyTorch TensorFlow
(5) Hyperparameter Tuning:Katib,超参数服务器
(6) Pipelines:一个ML的工作流组件,用于定义复杂的ML工作流
(7) Tools for Serving:提供在上对机器学习模型的部署
KFServing、 Seldon Core Serving 、TensorFlow Serving(TFJob):提供对Tensorflow模型的在线部署,支持版本控制及无需停止线上服务、切换模型等NVIDIA Triton Inference Server(Triton以前叫TensorRT)TensorFlow Batch Prediction(8) Multi-Tenancy in Kubeflow:Kubeflow中的多租户
(9) Fairing:一个将code打包构建image的组件
Kubeflow中大多数组件的实现都是通过定义CRD来工作。目前Kubeflow主要的组件有:Operator是针对不同的机器学习框架提供资源调度和分布式训练的能力(TF-Operator,PyTorch-Operator,Caffe2-Operator,MPI-Operator,MXNet-Operator);Pipelines是一个基于Argo实现了面向机器学习场景的流水线项目,提供机器学习流程的创建、编排调度和管理,还提供了一个Web UI。Katib是基于各个Operator实现的超参数搜索和简单的模型结构搜索的系统,支持并行搜索和分布式训练等。超参优化在实际的工作中还没有被大规模的应用,所以这部分的技术还需要一些时间来成熟;Serving支持部署各个框架训练好的模型的服务化部署和离线预测。Kubeflow提供基于TFServing,KFServing,Seldon等好几种方案。由于机器学习框架很多,算法模型也各种各样。工业界一直缺少一种能真正统一的部署框架和方案。这方面Kubeflow也仅仅是把常见的都集成了进来,但是并没有做更多的抽象和统一。以上,我对Kubeflow组件进行了系统的概括,来帮助我们对各个组件有一个基本的了解和整体的把握。趁热打铁,接下来我们详细介绍每一个组件的架构和工作流程。
pipeline主要划分为八部分:
Python SDK: 用于创建kubeflow pipelines组件的特定语言(DSL)。
DSL compiler: 将Python代码转换成YAML静态配置文件(DSL编译器 )。
Pipeline Web Server: pipeline的前端服务,它收集各种数据以显示相关视图:当前正在运行的pipeline列表,pipeline执行的历史记录,有关各个pipeline运行的调试信息和执行状态等。Pipeline Service: pipeline的后端服务,调用K8S服务从YAML创建 pipeline运行。
Kubernetes Resources: 创建CRDs运行 pipeline。
Machine Learning Metadata Service: 用于监视由Pipeline Service创建的资源,并将这些资源的状态持久化在ML元数据服务中(存储任务流容器之间的input/output数据交互)。
Artifact Storage: 用于存储Metadata和Artifact。Kubeflow Pipelines将元数据存储在MySQL数据库中,将工件存储在Minio服务器或Cloud Storage等工件存储中。
Orchestration Controllers:任务编排,比如 Argo Workflow控制器,它可以协调任务驱动的工作流。
katib目前有哪些组件:
Experiment Controller:提供对Experiment CRD的生命周期管理。
Trial Controller:提供对Trial CRD的生命周期管理。
Suggestions:以Deployment的方式部署,用Service方式暴露服务,提供超参数搜索服务。目前有随机搜索,网格搜索,贝叶斯优化等。
Katib Manager:一个GRPC server,提供了对Katib DB的操作接口,同时充当Suggestion与 Experiment之间的代理。
Katib DB:数据库。其中会存储Trial和Experiment,以及Trial的训练指标。目前默认的数据库为 MySQL。
Katib工作原理
当一个Experiment被创建的时候,Experiment Controller会先通过Katib Manager在Katib DB中创建一个Experiment对象,并且打上Finalizer表明这一对象使用了外部资源(数据库)。随后,Experiment Controller会根据自身的状态和关于并行的定义,通过Katib Manager提供的GRPC接口,让Manager通过 Suggestion提供的GRPC接口获取超参数取值,然后再转发给Experiment Controller。在这个过程中,Katib Manager是一个代理的角色,它代理了Experiment Controller对Suggestion的请求。拿到超参数取值后,Experiment Controller会根据Trial Template和超参数的取值,构造出Trial的定义,然后在集群中创建它。