kubeflow是一个胶水项目,它把诸多对机器学习的支持,比如模型训练,超参数训练,模型部署等进行组合并已容器化的方式进行部署,提供整个流程各个系统的高可用及方便的进行扩展部署了 kubeflow的用户就可以利用它进行不同的机器学习任务。kubeflow是一个为 Kubernetes 构建的可组合,便携式,可扩展的机器学习技术栈。
Kubeflow想解决的问题是如何基于Kubernetes去方便地维护ML Infra。Kubeflow中大多数组件的实现都是基于Kubernetes Native 的解决方案,通过定义CRD来功能。这很大程度上减少了运维的工作。同时,利用Kubernetes提供的扩展性和调度能力,对大规模分布式训练和AutoML也有得天独厚的优势。
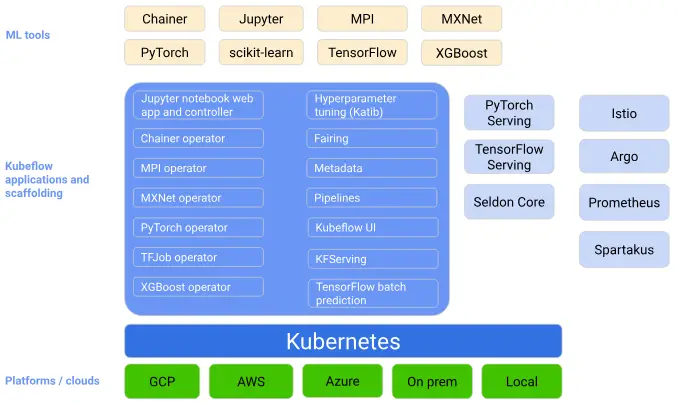
kubeflow的重要结构:
-
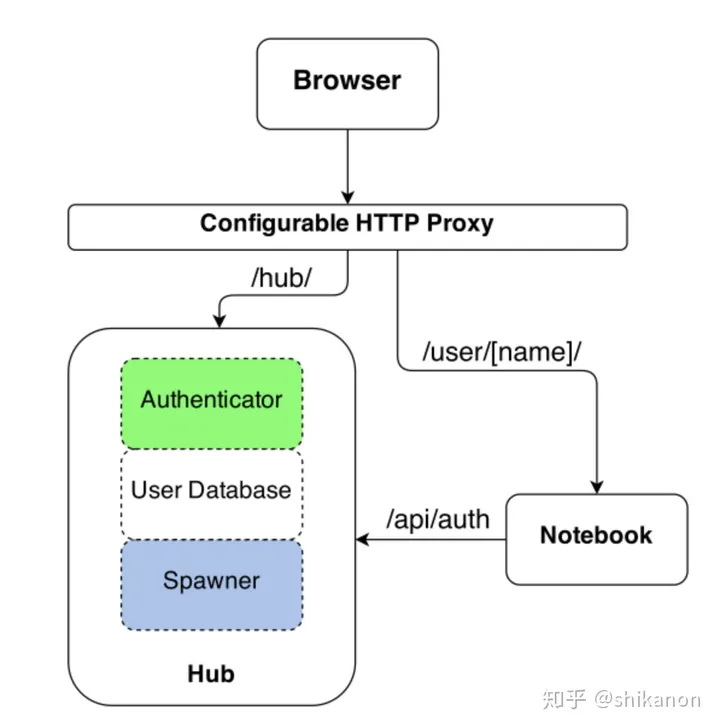
jupyter :jupyter 创建和管理多用户交互式Jupyter notebooks。
-
多租户隔离:简化用户操作以允许用户仅查看和编辑其配置中的 Kubeflow 组件和模型制品。这个 Kubeflow 的多用户隔离下的关键概念包括身份验证、授权、管理员、用户和配置文件。
-
TFJob-operator :K8S有一种Jobs的Controller类型,K8S会跟踪Job的状态,如果没有正常结束,K8S可以再次把任务调度起来。Job是有结束时间的任务,当Job正常结束之后,K8S会把刚刚的Job清理掉。这个特性非常适合用来执行机器学习的训练任务。TFJob-operator即是KubeFlow的深度学习框引擎,资源类型TFJob是一个基于tensorflow构建的CRD(自定义资源),通过这样一个资源类型,使用 TensorFlow 进行机器学习训练的工程师们不再需要编写繁杂的配置,只需要按照他们对业务的理解,确定 PS 与 worker 的个数以及数据与日志的输入输出,就可以进行一次训练任务。

apiVersion: kubeflow.org/v1beta2 kind: TFJob metadata: name: mnist-train namespace: kubeflow spec: tfReplicaSpecs: Chief: # 调度器 replicas: 1 template: spec: containers: - command: - /usr/bin/python - /opt/model.py env: - name: modelDir value: /mnt - name: exportDir value: /mnt/export image: mnist-test:v0.1 name: tensorflow volumeMounts: - mountPath: /mnt name: local-storage workingDir: /opt restartPolicy: OnFailure volumes: - name: local-storage persistentVolumeClaim: claimName: local-path-pvc Ps: # 参数服务器 replicas: 1 template: spec: containers: - command: - /usr/bin/python - /opt/model.py env: - name: modelDir value: /mnt - name: exportDir value: /mnt/export image: mnist-test:v0.1 name: tensorflow volumeMounts: - mountPath: /mnt name: local-storage workingDir: /opt restartPolicy: OnFailure volumes: - name: local-storage persistentVolumeClaim: claimName: local-path-pvc Worker: # 计算节点 replicas: 2 template: spec: containers: - command: - /usr/bin/python - /opt/model.py env: - name: modelDir value: /mnt - name: exportDir value: /mnt/export image: mnist-test:v0.1 name: tensorflow volumeMounts: - mountPath: /mnt name: local-storage workingDir: /opt restartPolicy: OnFailure volumes: - name: local-storage persistentVolumeClaim: claimName: local-path-pvc -
katib :超参数服务器,Kubeflow 集成了一个超参调优工具 Katib,主要用来模型自动优化和超参数调整,提供了 超参数调整(Hyperparameter Tuning),早停法(Early Stopping)和神经网络架构搜索(Neural Architecture Search)。
-
训练算子(Operators) :、每个深度学习框架都对应一个的 operator 独立在一个 repository 中进行维护。使您能够通过算子训练 ML 模型。例如,它提供了在 Kubernetes 上运行 TensorFlow 模型训练的 TensorFlow 训练(TFJob)、用于 Pytorch 模型训练的 PyTorchJob 等。
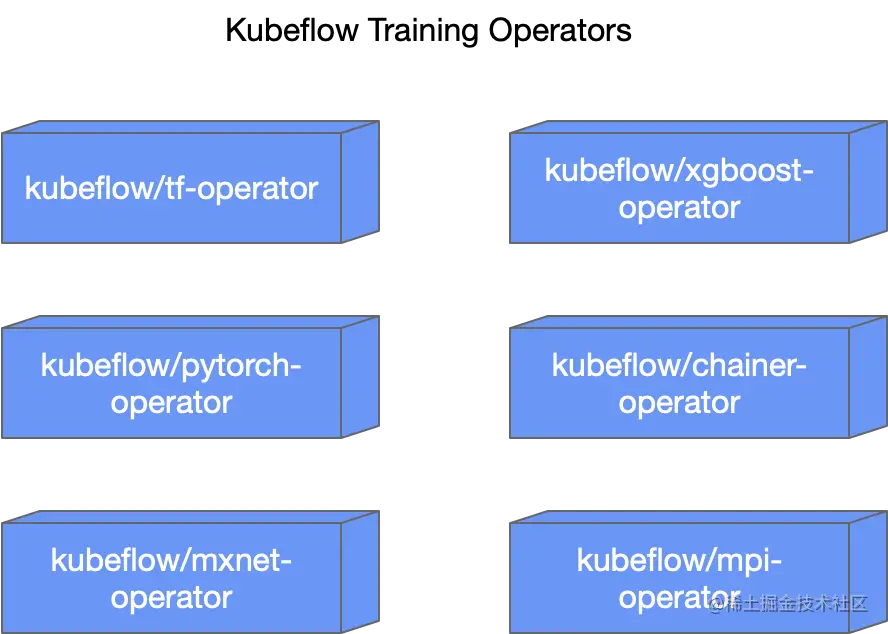
当然, Kubeflow 1.4 Release 预计会支持融合后的 tf-operator:部署单个 operator 即可支持包括 TFJob、PyTorchJob、MXNetJob 和 XGBoostJob 在内的四种 API 支持。
-
Kubeflow pipelines:一个机器学习的工作流组件,使您能够基于 Docker 容器构建和部署可移植、可扩展的机器学习工作流,
pipeline定义了算法组合的模板,通过pipeline我们可以将算法中各处理模块按特定的拓扑图的方式组合起来。它包括一个用于管理作业的用户界面、一个用于安排多步骤 ML 工作流的引擎、一个用于定义和操作管道的 SDK,以及用于通过 SDK 与系统交互的 Notebooks ,基于argo 用于pipeline任务工作流编排。Argo Workflow流程引擎,可以编排容器流程来执行业务逻辑,Argo的步骤间可以传递文件与结果信息,下一步(容器)可以获取上一步(容器)的结果。详细介绍可以前往https://blog.csdn.net/qq_45808700/article/details/132188234 -
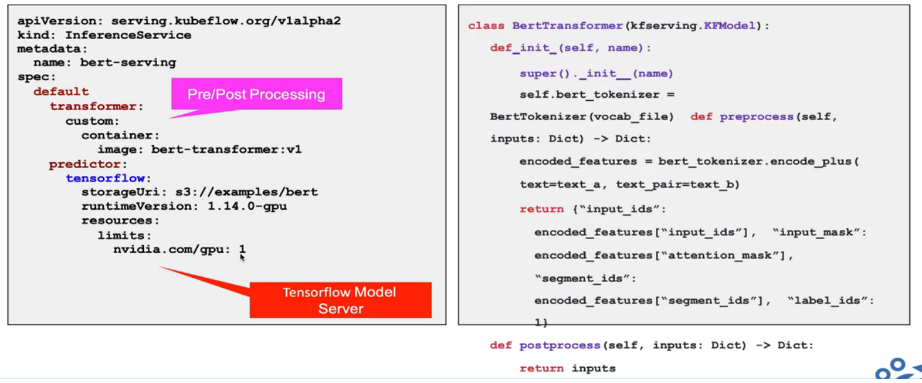
KFServing:KFServing 提供一个稳定的接口,供用户调用,来应用该模型,serving 通过模型文件直接创建模型即服务(Model as a service),在 Kubernetes 上启用无服务器推理。
Kubeflow提供基于TFServing,KFServing,Seldon等好几种方案。有了 KFServing,用户可以轻松地在 GPU 上部署推理服务,并使用 用户可以利用性能卓越的行业领先模型服务器在 GPU 上轻松部署推理服务,并从所有无服务器功能中获益。它还为 PyTorch、TensorFlow、scikit-learn 和 XGBoost 等 ML 框架提供高性能和高度抽象的接口。TensorFlow-serving可以将训练好的机器学习模型部署到线上,使用 gRPC 作为接口接受外部调用。它支持模型热更新与自动模型版本管理。这意味着一旦部署 Serving 后,你再也不S需要为线上服务操心,只需要关心你的线下模型训练。借助 Serving,您可以轻松部署新算法和实验,同时保留相同的服务器架构和 API。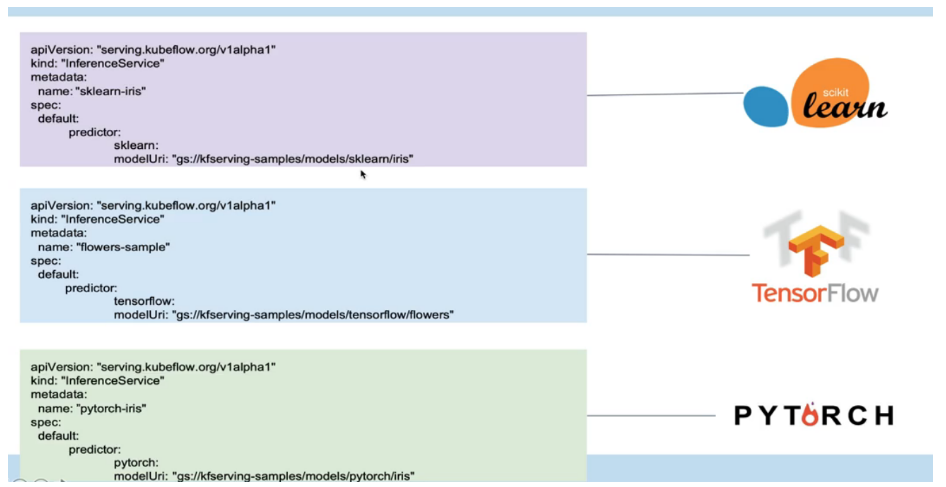
-
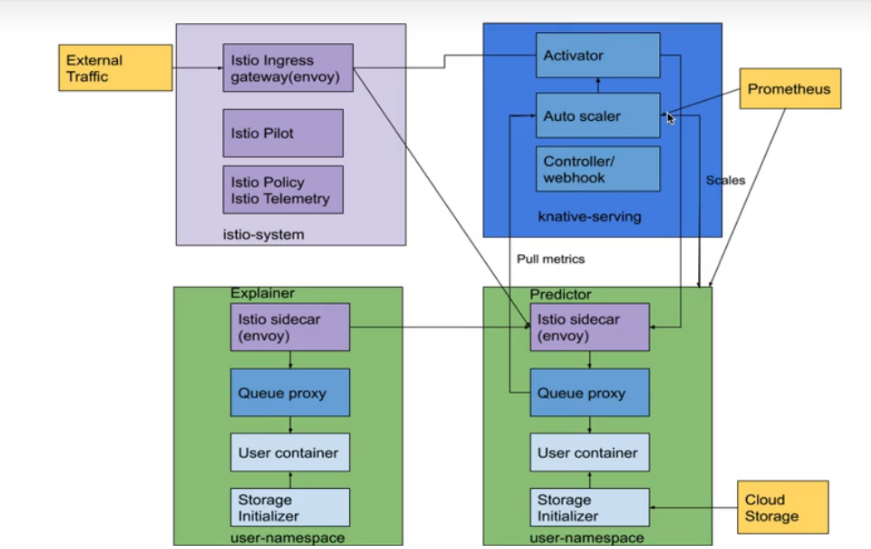
Istio:Kubeflow 主要利用 Istio 来进行资源的管理和进行运维, 例如查看相关资源的指标, 权限的验证, 资源的分配和测试等等。
-
ambassador :Ambassador 对外提供统一服务的网关(API Gateway),它是一个 Kubernetes 原生的微服务 API 网关,它部署在网络边缘,将传入网络的流量路由到相应的内部服务(也被称为“南北”流量)。
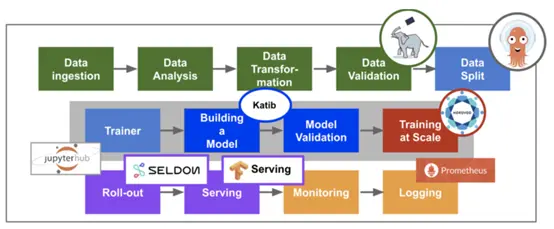
虽然kubeflow最开始只是基于tf-operator,但后来随着项目发展最后变成一个基于云原生构建的机器学习任务工具大集合。从数据采集,验证,到模型训练和服务发布,几乎所有步骤Kubeflow都提供解决方案的组件。
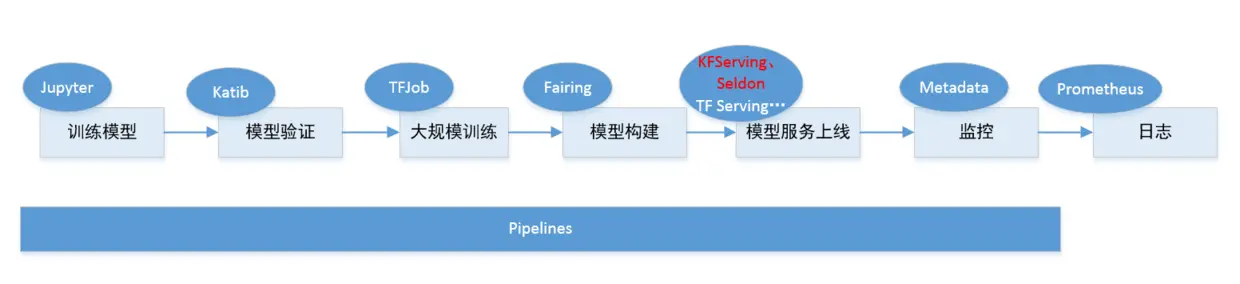
通过Kubeflow ,用户可以使用Jupyter开发模型,然后使用fairing(SDK)等工具构建容器,并创建Kubernetes资源训练其模型。模型训练完成后,用户还可以使用KFServing创建和部署用于推理的服务器。再结合pipeline(流水线)功能可实现端到端机器学习系统的自动化敏捷构建,实现AI领域的DevOps。