虚拟文件系统
在现代计算机的操作系统当中,除了CPU和内存之外,剩下的基本上都是IO设备。对于程序来讲,模拟使用的是整个内存。一个程序如果想要执行的时候,想要获取IO当中数据的时候就得先通过内核kernel。kernel既管内存的分配,又管磁盘的IO,在kernel中有一个虚拟文件系统 (VFS)。在win中这种文件系统就是我们熟知的C盘、D盘.....在每一个磁盘中都有自己的目录树结构去存放数据。只不过在Linux系统,或者说是类Unix系统中它是一棵树,树上面每一个不同的节点映射到不同的物理位置。而不同的物理位置可以是不同的具体的文件系统,比如:FAT、EXT4.....
为什么叫虚拟文件系统,其实在win中可以理解成就是真正的物理文件系统,因为看到的C盘它就是C盘那个位置。但是Linux弄出来的这个虚拟文件系统,是为了解决上层应用程序对于底层的存储空间来讲,在很多地方存储数据,比如磁盘、比如网卡。可以简单的理解成底层那些硬件上存储数据的地方,想象成MySQL数据库,而中间的虚拟文件系统就是与数据库的链接。这样的话,有了这个虚拟文件系统,它就可以连接到不同的数据库,在不同的地方去存储数据,从而对存储数据的一个管理解耦出来。把这个虚拟文件系统想象成给用户空间的程序暴露出来的一个统一数据存储接口,它的底层挂载了不同的设备。
这个虚拟文件系统中的一些基本概念先了解一下:
1、inode,这个就想象成每一个文件的唯一标识符ID;
2、pagecache,页缓存,内存中默认4k。程序读取出来的数据会在内存中开辟这个空间去存放,不同的程序想要读取同一个文件,那么这个文件在内存中开辟出来的这个pagecache通过VFS来给它们共享;
3、dirty,脏页。程序将数据从磁盘中读取出来,缓存在pagecache中,然后程序对内存中的这个数据进行了修改,就会被记为dirty;
4、flash,刷新写入。将pagecache中修改过后的数据重新写入磁盘中,这种书写形式就决定了采用哪种IO模型;
5、FD,文件描述符。这个有点类似于Java中的迭代器模式中指针的概念,通过不同位置的偏移量来让不同程序可以访问不同位置的数据。这样在修改不同位置数据的时候也不需要加锁。你修改a位置的数据,我修改b位置的数据,可以各自修改各自的,少了锁的约束就可以极大的提高效率;
Linux系统中文件的类型
我们都知道在Linux系统中的概念是一切皆文件,那么文件的类型也分为很多种:
- 普通文件
普通文件可以是可执行文件,可以是图片,可以是文本.....

d 目录文件
b 块设备
块设备是IO设备中的一类,是将信息存储在固定大小的块中,每个块都有自己的地址,还可以在设备的任意位置读取一定长度的数据,例如硬盘,U盘,SD卡等。

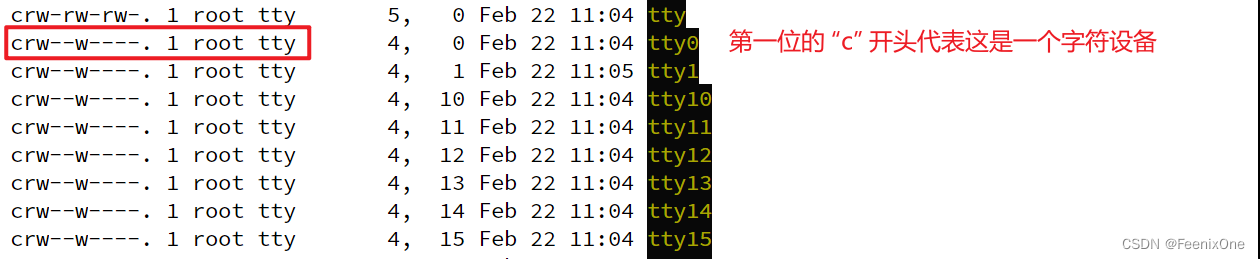
c 字符设备
字符设备是指在IO传输过程中以字符为单位进行传输的设备,例如键盘,打印机等。在类UNIX系统中,字符设备以特别文件方式在文件目录树中占据位置并拥有相应的结点。
l 链接

链接也分软链接和硬链接,通过 ln 命令,没有加参数,默认建立起来的链接是硬链接

通过stat命令,可以看到这个链接的元数据信息,包含了Inode号

会发现,通过硬链接关联起来的两个文件的文件号Inode是一样的。其实就是同一份文件建立了不同的path路径,指向同一个物理文件。
-rw-r--r--. 2 root root 416 Feb 22 11:51 feenix.txt
-rw-r--r--. 2 root root 416 Feb 22 11:51 iamlxj.txt
这个 “2” 指的就是硬链接引用的数量,如果将其中一个链接删掉,这个计数就会降为1

通过 ln -s 命令,建立起来的就是软链接

通过软链接创建出来的指向,和win中的快捷方式一样,且这两个文件是相互独立的

无论是软链接还是硬连接,只要修改了其中一方中的内容,其余一方中的内容也会跟着相应变化。只不过对于软链接来说,如果将它原始的文件删除,那么这个指向就会错误。

s socket
echo $$
cd /proc/6853/fd
exec 8<> /dev/tcp/www.baidu.com/80

准备文件描述符8,输出输出,来自于目录/dev/tcp/www.baidu.com/80,就会生成一个文件描述符8,指向一个socket。
lsof -op $$

看到这个文件描述符8指向一个IPv4,平时看不到,只要当它产生了以后,文件描述符才能给它标识出来。NODE这列显示它是一个TCP连接,不是一个真的文件了。NAME这列显示已经和www.baidu.com成功建立起了http连接,这就是一个socket连接。
p 管道及Linux中的重定向机制
在Linux系统中,任何程序都有,且必须有:0-标准输入、1-标准输出、2-报错输出。
Linux系统有个功能叫重定向,这是一种机制,而不是命令。将标准输出(本身也是一个文件/dev/stdout)导向一个文件或者追加到一个文件中。在Linux系统中,使用>符号来表示导向到一个文件,使用>>符号来表示追加到一个文件。
read a,这个命令会阻塞输入,只有按下回车的时候才会退出。它通过标准输入(也就是键盘的输入,它的0就是相当于对接的键盘),来判断每个字符是不是回车。如果是回车则停止,并将读取到的东西赋值给a。所以当echo $a的时候,就是回车前输入的那些东西。
所以read在给a输入的时候,后面就可以通过参数来指定:read a 0< feenix.txt,读取的东西来自于feenix.txt,所以此时回车之后,就会直接退出,因为已经从feenix.txt中读取到东西了。但是a这个变量存的东西仅仅是文件的第一行而已,因为read在遇到换行符的时候就会结束读取。这就是Linux最基本的输入输出原理。

重定向操作符,无论是输入"<",还是输出">",左边都是程序自有的文件描述符,且两者之间不可有空白符。也就是"0<"不能写成"0 <",在命令行中空白符极其敏感,会做字符串切割,那么就会认为"0"是前一个命令的参数,而不是所谓的文件描述符。
很多时候,其实可以将重定向操作符对接起来。假设使用ls ./ /xxxx来打印两个目录下的内容,/xxxx是一个不存的目录,就会报错。那么就可以加上参数 ls ./ /xxxx 1> ls01.out 2> ls02.out,将正常打印的内容输入到ls01.out中,将报错打印的内容输入到ls02.out中,让两个不同的输出流写入到各自的文件中。

也可以让这些内容输入到一个文件中,ls ./ /xxxx 1> ls03.out 2> ls03.out,这个输出默认是覆盖,而不是追加。所以这个命令执行之后,ls03.out文件中就只会有标准输出的内容。

更进一步,可以直接让2指向1,再让1指向一个输出文件。ls ./ /xxxx 2>& 1 1> ls04.out,这里注意一个语法上的问题。如果重定向描述符右边放的是一个文件描述符,就需要在重定向描述符右边先加上一个&。这是一个硬性约束,如果没有这个&,系统则会认为将错误输出到1这个文件中。

但是这么写依然会出现报错的问题,这是因为重定向描述符绑定是有顺序的。2>& 1这一句是2指向1,然后在执行1> ls04.out这一句是1指向ls04.out文件。也就是2先指向1的位置,1再指向文件的位置,那么1就是变了位置,但是2指向的还是1原来的位置,所以此时就会报错。那么就需要将这两个命令的顺序颠倒过来即可:ls ./ /xxxx 1> ls04.out 2>& 1,这样执行完之后就是既有错误的输出,也有正常的输出。

这就是重定向描述符的基本语法及使用。好了,说完了这个重定向之后,再来介绍管道。通过两个指令:head、tail来说明管道是个什么东西。首先,head -10可以显示文件的前10行,tail -10可以显示文件的后10行。

那现在要求只显示文件的第10行,要怎么显示?这时候就需要管道出马。先将文件的前10行全部取出,在通过管道交给下一个命令将前10行的最后一行取出,就可以得到文件的第10行。

所谓管道,就是前面的输出作为后面的输入,这是管道的基本特性。
Linux系统的基本使用
代码块
使用一对花括号,可以将多句指令一次性执行。指令与指令间使用";"进行隔离,并且花括号内收尾都使用空格

父子进程
通过 /bin/bash 可以从当前进程衍生出子进程,在通过 exit 可以退出当前进程

有了这个基本的知识之后,问题来了,在父进程中,定义一个变量,使用子进程还能取出来吗?答案显然是不可以,这个在操作系统中叫进程隔离

正是由于存在这种进程隔离的机制,所以才诞生了export,使得变量可以被导出,被其它进程访问

这也正是为什么在安装JDK等软件的时候,需要在/etc/profile文件中使用export命令来定义环境变量。否则当启动子进程之后,便无法再访问这些在父进程中定义好的环境变量。
然后结合管道再来更深入一些理解父子进程:管道可以衔接输入和输出,但是你要知道,这个bash命令是解释执行的。就是当bash看到 "{ a=9; echo "pneumonoultramicroscopicsilicovolcanoconiosis"; } | cat"这个命令之后,发现这个命令中有管道|。于是在管道的左右两边各启一个子进程,并让两个进程的输入输出通过管道对接。对接完之后,左边的子进程执行"{ a=9; echo "pneumonoultramicroscopicsilicovolcanoconiosis"; }",右边的子进程执行cat,将左边子进程的输入进行输出。但是由于操作系统的进程隔离级别很高,子进程中对a=9的操作,在父进程中看不到,整个命令执行完依旧回到父进程,所以在父进程中a还是1。

顺着这个知识点,好玩的来了,如此说来,执行"echo $$ | cat "应该是打印出管道左边子进程的ID号,但事实却并非如此。但是通过"echo $BASHPID | cat "的方式打印出来的就是管道左边子进程的ID号,这又是为什么?

原因就在于$$的优先级是高于管道,而$BASHPID的优先级则低于管道。 当命令中有$$存在的时候,由于$$的优先级高于管道,于是先将$$的值替换为当前的进程ID号也就是6853(这一步骤叫参数扩展),然后再执行管道,再在左边启新的子进程。但是这个时候$$已经被替换成了6853,即便是子进程,那也是输出"6853"这个字符串交给右边的子进程打印。
而"echo $BASHPID | cat "命令中由于管道的优先级较高,先执行管道,左边启了子进程,然后执行"$BASHPID"这个时候取的就是子进程的ID号,所以右边子进程打印的就是左边的子进程ID号。
管道的高阶特性
有了前面的那些铺垫之后,现在来看一个命令:{ echo $BASHPID; read x; } | { cat; echo $BASHPID; read y; }。这个命令按下回车执行之后,立刻窗口就会阻塞住,然后重新开一个终端窗口,查看6853这个ID号相关的进程情况:


可以看到基于父进程 6853 起了两个子进程27966和27967,应该就是一个左边,一个右边。然后分别来到这两个子进程的fd目录下

27966 对应的子进程的描述符是1(输出),27967 对应的子进程的描述符是0(输入),那么很显然,27966 就是管道左边的子进程,27967 就是管道右边的子进程。
磁盘IO模型与PageCache页缓存
在平时写代码的时候,有没有想过为什么bufferedIO比普通IO更快?这就涉及到PageCache相关。PageCache的诞生为了优化IO性能,优先走内存,但是会造成丢失数据的问题。PaheCache,又称pcache,中文名称为页高速缓冲存储器,简称页缓存。PageCache的大小为一页,通常为4K。在Linux读写文件时,它用于缓存文件的逻辑内容,从而加快对磁盘上映像和数据的访问。
在Linux系统中使用 sysctl -a | grep dirty 查询PageCache相关的设置参数,重点有这么几个:
vm.dirty_background_ratio = 90
可用内存占用到90%的时候,后台起一个线程异步调用kernel由内存刷写到硬盘上,新的数据还可继续写入内存
vm.dirty_ratio = 90
可用内存占用到90%的时候,程序阻塞同步调用kernel由内存刷写到硬盘上,新的数据已经不能再继续写入内存
vm.dirty_writeback_centisecs = 500
每过多久的时间将内存中的脏页刷写到硬盘上,时间单位:1/100s
vm.dirty_expire_centisecs = 3000
脏页的生命周期,可以存活多久,时间单位:1/100s
我们知道,Java程序运行在JVM中,JVM在Linux系统看来也是一个普通的程序进程,通过设置的参数可以跟操作系统申请Heap的大小。
1、堆上分配:在使用ByteBuffer.allocate(1024);申请空间的时候,是将字节数组分配到Heap上,本质上这段空间还是由JVM进行管理;
2、堆外分配:如果使用ByteBuffer.allocateDirect(1024);申请空间,则是直接分配到JVM的Heap外空间,由操作系统直接管理;
相对于堆上分配,堆外分配的性能会更高一些。如果在逻辑代码中,使用的Object可以自行控制,可以给它序列化转成字节数组,就可以直接开辟堆外分配空间。可如果这个Object不是自己能控制的,是别人的第三方jar包先转成的字节数组,就应该使用堆上分配来开辟空间。
除此之外,还有一个对象叫FileChannel,有一个map方法,通过这个方法会分配出一个MappedByteBuffer:
FileChannel rafchannel = raf.getChannel();
MappedByteBuffer map = rafchannel.map(FileChannel.MapMode.READ_WRITE, 0, 4096);
map.put("@@@".getBytes());
这不是系统调用,但是数据会直接映射到内核的PageCache。曾经是需要out.write()这样的系统调用,才能让程序的数据进入内核的PageCache,也就是必须有用户态内核态切换。但是通过mmap的内存映射,依然是内核的pagecache体系所约束的。换言之,依然会存在丢失数据的问题。
package com.feenix.system.io;
import org.junit.Test;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
public class OSFileIO {
static byte[] data = "123456789\n".getBytes();
static String path = "/root/feenix/out.txt";
public static void main(String[] args) throws Exception {
switch (args[0]) {
case "0":
testBasicFileIO();
break;
case "1":
testBufferedFileIO();
break;
case "2":
testRandomAccessFileWrite();
/*case "3":
whatByteBuffer();*/
default:
}
}
// 最基本的file写
public static void testBasicFileIO() throws Exception {
File file = new File(path);
FileOutputStream out = new FileOutputStream(file);
while (true) {
/*Thread.sleep(10);*/
out.write(data);
}
}
// 测试buffer文件IO
// jvm 8kB syscall write(8KBbyte[])
public static void testBufferedFileIO() throws Exception {
File file = new File(path);
BufferedOutputStream out = new BufferedOutputStream(new FileOutputStream(file));
while (true) {
/*Thread.sleep(10);*/
out.write(data);
}
}
// 测试文件NIO
public static void testRandomAccessFileWrite() throws Exception {
RandomAccessFile raf = new RandomAccessFile(path, "rw");
raf.write("hello mashibing\n".getBytes());
raf.write("hello seanzhou\n".getBytes());
System.out.println("write------------");
System.in.read();
raf.seek(4);
raf.write("ooxx".getBytes());
System.out.println("seek---------");
System.in.read();
FileChannel rafchannel = raf.getChannel();
//mmap 堆外 和文件映射的 byte not objtect
MappedByteBuffer map = rafchannel.map(FileChannel.MapMode.READ_WRITE, 0, 4096);
map.put("@@@".getBytes()); //不是系统调用 但是数据会到达 内核的pagecache
//曾经我们是需要out.write() 这样的系统调用,才能让程序的data 进入内核的pagecache
//曾经必须有用户态内核态切换
//mmap的内存映射,依然是内核的pagecache体系所约束的!!!
//换言之,丢数据
//你可以去github上找一些 其他C程序员写的jni扩展库,使用linux内核的Direct IO
//直接IO是忽略linux的pagecache
//是把pagecache 交给了程序自己开辟一个字节数组当作pagecache,动用代码逻辑来维护一致性/dirty。。。一系列复杂问题
System.out.println("map--put--------");
System.in.read();
// map.force(); // flush
raf.seek(0);
ByteBuffer buffer = ByteBuffer.allocate(8192);
// ByteBuffer buffer = ByteBuffer.allocateDirect(1024);
int read = rafchannel.read(buffer); //buffer.put()
System.out.println(buffer);
buffer.flip();
System.out.println(buffer);
for (int i = 0; i < buffer.limit(); i++) {
Thread.sleep(200);
System.out.print(((char) buffer.get(i)));
}
}
@Test
public void whatByteBuffer() {
/*ByteBuffer buffer = ByteBuffer.allocate(1024); 分配在heap上*/
ByteBuffer buffer = ByteBuffer.allocateDirect(1024); // 分配在heap外
System.out.println("postition: " + buffer.position());
System.out.println("limit: " + buffer.limit());
System.out.println("capacity: " + buffer.capacity());
System.out.println("mark: " + buffer);
buffer.put("123".getBytes());
System.out.println("-------------put:123......");
System.out.println("mark: " + buffer);
buffer.flip(); //读写交替
System.out.println("-------------flip......");
System.out.println("mark: " + buffer);
buffer.get();
System.out.println("-------------get......");
System.out.println("mark: " + buffer);
buffer.compact();
System.out.println("-------------compact......");
System.out.println("mark: " + buffer);
buffer.clear();
System.out.println("-------------clear......");
System.out.println("mark: " + buffer);
}
}
总之计算机的操作系统没有绝对的数据可靠性,设计PageCache的目的就是为了减少硬件IO的调用,优先使用内存来提高效率。 Kafka也会丢数据,Redis也会丢数据,如果为了追求最高的可靠性而舍弃掉PageCache机制,即便能忍受频繁的IO带来的效率问题,但是单点故障问题依旧会造成数据问题。这也是为什么现代化架构设计都要有主从复制、HA高可用机制,为什么Kafka、ElasticSearch都要设有副本的概念。
从TCP/IP协议到Socket编程
TCP(Transmission Control Protocol)是一种面向连接的、可靠的、基于字节流的传输层通信协议,由IETF的RFC 793定义。TCP旨在适应支持多网络应用的分层协议层次结构。 连接到不同但互连的计算机通信网络的主计算机中的成对进程之间依靠TCP提供可靠的通信服务。这种连接不是物理的两边插着网线,而是通过无线数据传输建立三次握手(syn → syn+ack → ack)。在三次握手之后,双方都要在kernel级开辟资源。
而socket,定义叫套接字,非常的晦涩难懂。对网络中不同主机上的应用进程之间进行双向通信的端点的抽象。一个套接字就是网络上进程通信的一端,提供了应用层进程利用网络协议交换数据的机制。简单直白来说,可以理解成是一个四元组:客户端IP地址、客户端端口号、服务端IP地址、服务端端口号,它也是内核级的。要怎么理解这个所谓的四元组?假设:客户端IP地址:AIP,客户端端口号:APORT,服务端IP地址:XIP,服务端端口号:XPORT,客户端拿着自己的AIP+APORT连接到服务端的XIP+XPORT,建立起来的这一条清晰的、唯一的连接就是socket连接。
虽然这个socket连接是唯一的,通过这个socket连接,客户端可以找到唯一的服务端,甚至是端口都找的明明白白。但是,这个端口到底分配给哪个进程用,这个就得由操作系统分配一个文件描述符,也就是FD。需要将这个FD给到某一个具体的进程,这个FD就是从程序内部在使用流的时候的代表,而这个FD在Java里面就被封装成了 Socket 对象。得到这个 Socket 对象之后,最终是要拿来读写,也就是输入流和输出流。说白了,就是程序通过文件描述符FD来找到一个唯一的socket连接。假设FD1代表的是AIP+CPORT → XIP+XPORT,FD2代表的是AIP+BPORT → XIP+XPORT,FD3代表的是AIP+BPORT → XIP+YPORT,那么程序通过读取不同的FD来获取不同的socket连接中传输的数据。
光说不练假把式,接下来用一段代码在Linux中跑起来看看:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.InetSocketAddress;
import java.net.ServerSocket;
import java.net.Socket;
public class SocketIOPropertites {
//server socket listen property:
private static final int RECEIVE_BUFFER = 10;
private static final int SO_TIMEOUT = 0;
private static final boolean REUSE_ADDR = false;
private static final int BACK_LOG = 2;
//client socket listen property on server endpoint:
private static final boolean CLI_KEEPALIVE = false;
private static final boolean CLI_OOB = false;
private static final int CLI_REC_BUF = 20;
private static final boolean CLI_REUSE_ADDR = false;
private static final int CLI_SEND_BUF = 20;
private static final boolean CLI_LINGER = true;
private static final int CLI_LINGER_N = 0;
private static final int CLI_TIMEOUT = 0;
private static final boolean CLI_NO_DELAY = false;
/*StandardSocketOptions.TCP_NODELAY
StandardSocketOptions.SO_KEEPALIVE
StandardSocketOptions.SO_LINGER
StandardSocketOptions.SO_RCVBUF
StandardSocketOptions.SO_SNDBUF
StandardSocketOptions.SO_REUSEADDR*/
public static void main(String[] args) {
ServerSocket server = null;
try {
server = new ServerSocket();
server.bind(new InetSocketAddress(9090), BACK_LOG);
server.setReceiveBufferSize(RECEIVE_BUFFER);
server.setReuseAddress(REUSE_ADDR);
server.setSoTimeout(SO_TIMEOUT);
} catch (IOException e) {
e.printStackTrace();
}
System.out.println("server up use 9090!");
try {
while (true) {
System.in.read(); //分水岭:
// 代码走到这里的时候,此时正在阻塞等待,别的客户端此时也可以连接到这个PORT号,三次握手、开辟资源啥的
// 但是虽然有四元组,但是这个端口号分配给哪个进程还没有确定,因为还没有server.accept()
// 这个就得由操作系统分配一个文件描述符,也就是FD
// 需要将这个FD给到某一个具体的进程,这个FD就是从程序内部在使用流的时候的代表
// 而这个FD在Java里面就被封装成了 Socket 对象
Socket client = server.accept(); //阻塞的,没有 -1 一直卡着不动 accept(4,
System.out.println("client port: " + client.getPort());
client.setKeepAlive(CLI_KEEPALIVE);
client.setOOBInline(CLI_OOB);
client.setReceiveBufferSize(CLI_REC_BUF);
client.setReuseAddress(CLI_REUSE_ADDR);
client.setSendBufferSize(CLI_SEND_BUF);
client.setSoLinger(CLI_LINGER, CLI_LINGER_N);
client.setSoTimeout(CLI_TIMEOUT);
client.setTcpNoDelay(CLI_NO_DELAY);
//client.read //阻塞 没有 -1 0
new Thread(
() -> {
try {
InputStream in = client.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
char[] data = new char[1024];
while (true) {
int num = reader.read(data);
if (num > 0) {
System.out.println("client read some data is :" + num + " val :" + new String(data, 0, num));
} else if (num == 0) {
System.out.println("client readed nothing!");
continue;
} else {
System.out.println("client readed -1...");
System.in.read();
client.close();
break;
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
).start();
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
server.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}编译java文件,并使用java命令运行起来:
javac SocketIOPropertites.java && java SocketIOPropertites

使用 netstat -natp 查看,9090这个端口目前还没有任何连接:

在开一个窗口监测这个端口网络传输的数据包:tcpdump -nn -i ens33 port 9090

这个作为服务端就算是启动好了,现在再来新开一台虚拟机作为客户端,客户端运行的程序来连接服务端:
import java.io.*;
import java.net.Socket;
public class SocketClient {
public static void main(String[] args) {
try {
Socket client = new Socket("192.168.126.129", 9090);
client.setSendBufferSize(20);
client.setTcpNoDelay(true);
OutputStream out = client.getOutputStream();
InputStream in = System.in;
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
while (true) {
String line = reader.readLine();
if (line != null) {
byte[] bb = line.getBytes();
for (byte b : bb) {
out.write(b);
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}编译java文件,并使用java命令运行起来:
javac SocketClient.java && java SocketClient

客户端运行起来之后,就会去连接服务端,服务端没有按回车键,就一定还是在System.in.read();那里阻塞着,此时再来看 tcpdump 打印出的信息,也是能看到kernel级数据包3次握手的过程:

用 netstat 来看,kernel级也看到了连接建立成功的四元组:
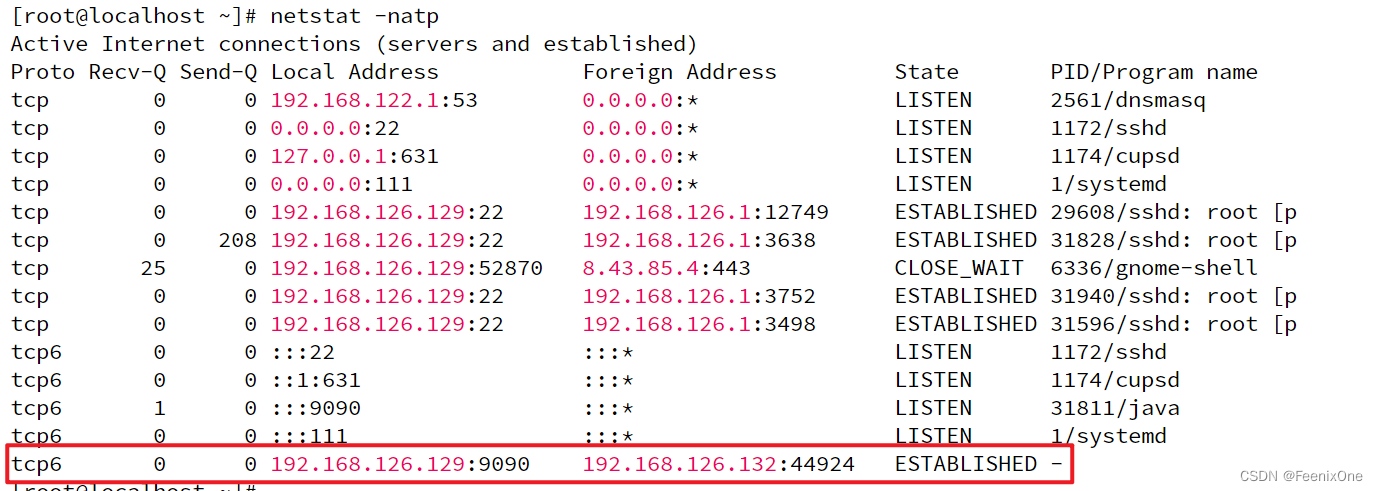
有意思的来了,虽然连接已经建立成功,但是 PID/Program name 这一列显示为-,也就是说这个连接现在还没有分配给某一个具体的进程。
客户端虚拟机再多开几个终端窗口,多跑几个SocketClient,可以看到多个客户端连接握手

并且这些连接都是在kernel级尚未分配给具体的进程

然后使用客户端给服务端发送消息,通过 netstat -natp 可以看到数据都是成功传递的,几个kernel之间倒是玩的很开心

目前来看是已经有两个客户端和服务端成功建立起连接,如果现在再来第三个、第四个客户端也要和服务端建立同样的连接,会发现已经无法建立更多的有效连接,因为在服务端的代码中,已经告诉操作系统,服务端只能同时伺候两个客户端的连接,再多就忙不过来了:
private static final int BACK_LOG = 2;
.....
ServerSocket server = null;
server.bind(new InetSocketAddress(9090), BACK_LOG);
只有当数据全都接受之后,也就是服务端按下回车,accpet之后,将数据指定给具体的进程获取完之后,不再阻塞着了,才有精力继续处理别的客户端发来的数据传输:


再来看看这个timeout是干啥用的:
private static final int SO_TIMEOUT = 0;
private static final int CLI_TIMEOUT = 0;
server = new ServerSocket();
.....
server.setSoTimeout(SO_TIMEOUT);
.....
client.setSoTimeout(CLI_TIMEOUT);
服务端设置timeout时间,在监听的时候,对accept设置一个超时时间,时间到了之后阻塞等待就会抛出异常,代码继续往下走,还能回来继续;客户端设置timeout时间,就是在读取客户端数据的时候,也会有超时时间的限制,从而保证不会有恶意的链接无意义消耗双方资源。
这些配置项都是在socket级别进行的配置,都是在kernel的TCP协议栈中,跟JVM无关,是Linux操作系统去做的,现在这些还是关联到TCP协议的选项参数。
窗口机制与拥塞控制
继续来看这个TCP通讯的数据抓包信息,当客户端和服务端建立起三次握手之后。在连接建立的时候,双方会商量很多事情。在数据包中会各自带上自身的序列号(seq),服务端在回应客户端的时候,会在自身的ack中将客户端的序列号seq+1,并且也会带上自己的序列号。最关键的还会带上窗口大小。
如果有学过流式计算,肯定会对滑动窗口不陌生。在基本协议中,客户端给服务端一个数据,服务端收到后返回客户端确认;然后客户端再给服务端一个数据,服务端收到后再返回客户端确认.....首先需要知道的是,数据包应该多大比较合适?从ifconfig打印的信息中可以看出

mut指的就是网卡发送数据包的总大小,也就是从ens33这块网卡发送出去的数据包大小为1500字节。在抓包的数据中有一个options [mss 1460,sackOK,TS val 3511501320 ecr 0,nop,wscale 7],里面的mss 1460指的是数据的真实大小。
当需要传输的数据较大时,肯定是要切成很多个数据包依次发出,如果按照上面所说的基本协议发送,发一个数据包等一个确认,发一个数据包等一个确认,无疑是一件极度浪费效率的事情。所以就诞生了窗口机制:在三次握手的时候,双方会根据自身的配置、资源、缓冲区大小来进行协商窗口的大小。

客户端向服务端第一次握手的时候,张口就来窗口大小为:win 29200
服务端向客户端第二次握手的时候,勉为其难说只能给你:win 1152
客户端向服务端第三次握手的时候,最终协商的窗口大小为:win 229

后续在实际发送数据的时候,双方一致会告诉对方我这边窗口还有多大的位置。那么发送方就可以根据对方窗口剩余的空间,一次性酌量多发送一些数据包过去。接收方收到之后,再给发送方回复确认,确认信息中包含剩余的窗口大小,发送方收到之后,再继续发送.....大大缩短了数据包发送的等待时间,提高数据包发送的效率,解决了数据包发送拥塞等待的问题。
如果接收方的窗口已经被填满了,回复确认的信息中就会告诉发送方已经没有窗口余量,接收到信息的发送方就会将自身发送阻塞住等待接收方将数据处理一些窗口中有多余的空量可以继续接受数据包,接收方会再次告诉发送方可以继续发送了,此时发送方再继续发送数据包给接收方。这个叫拥塞控制,有了拥塞控制的约束,发送方就不会一直玩命地给接收方发送数据,因为当窗口里堆满了接收的数据,接收方又来不及处理,此时发送方继续发送过来的数据就只能被丢弃处理。
Socket编程TCP/IP数据包发送参数
来看下客户端这边的3个参数
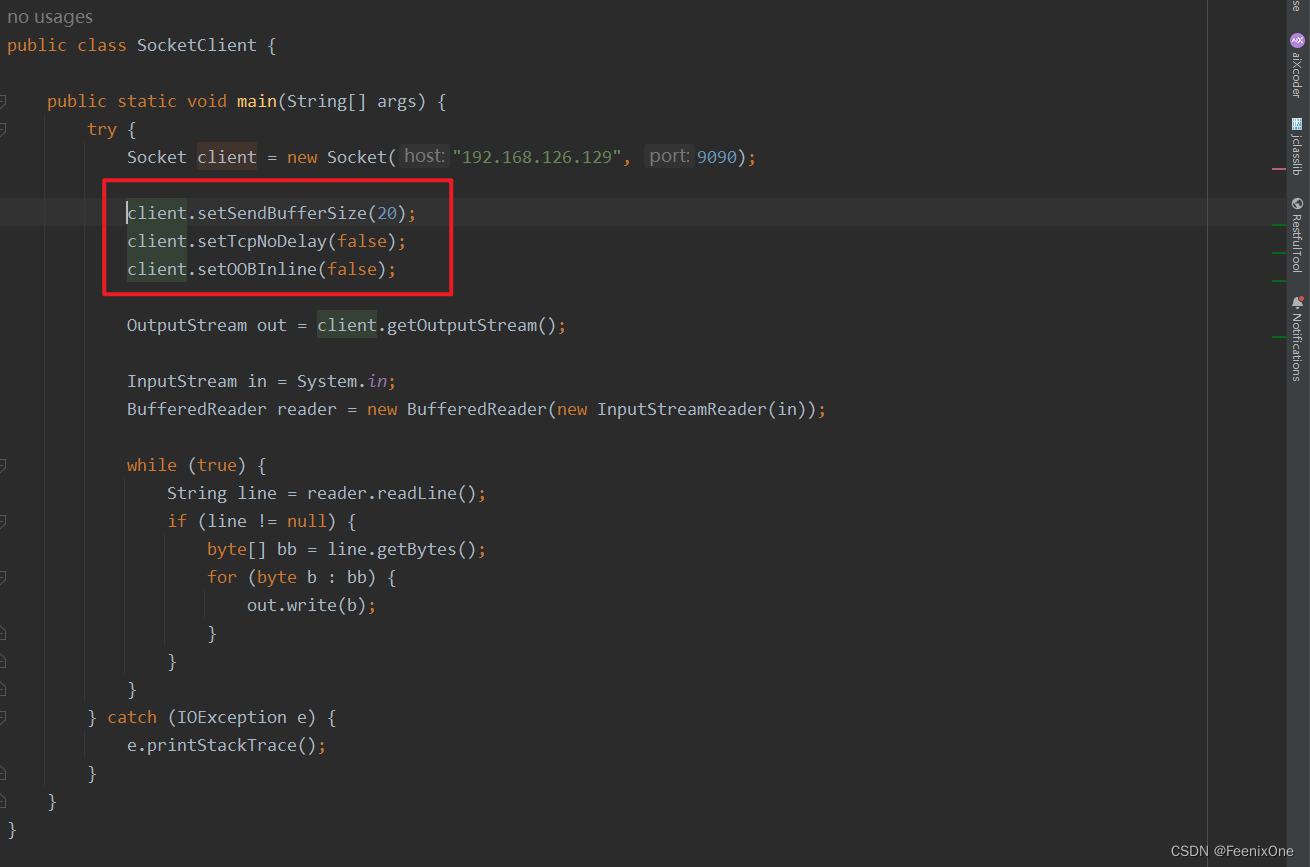
client.setSendBufferSize(20);
设置发送的缓冲区大小为20个字节
client.setTcpNoDelay(false);
设置非延迟发送为false,如果发送的数据量比较小,本地先攒一波,等量够了再发出去
client.setOOBInline(false);
将数据的第一个字节立马发出
先将客户端和服务端双方建立连接,然后服务端按下回车,接受客户端数据处理:

然后有意思的就来了,使用客户端给服务端发送数据,即便发送的数据包超过20个字节,也可以一次性发送完毕,也就是说一个数据包的大小是可以超过buffer缓冲区的大小。


client.setTcpNoDelay(true);
设置非延迟发送为true,本地不用攒数据了,有了数据就直接发走


数据量小的时候没什么区别,但是数据量起来之后,就能看到如果着急发送数据,不想等这个本地缓冲的优化,可以让数据包立刻发出。其实这个延时也真别小看,真要等起来的话系统的吞吐量很容易就下去了。所以没有最好的方案,只有最适合的方案,按照自身的业务去选择最合适的。
再来看这个参数:client.setOOBInline(true);


这个选项最明显的区别,就是每次数据包发送的时候,不会着急忙慌先将数据包的第一个字节先发送出去。这个小小的优化在于先将少量的数据先发送出去,如果对方没有给回应的话,剩下的包就不用继续发送出去。
还有一个参数是设置客户端的keepalive:
private static final boolean CLI_KEEPALIVE = true;
.....
client.setKeepAlive(CLI_KEEPALIVE);
keepalive指的是,当双方建立成功建立了连接之后,如果很久没有相互说话,要怎么确定对方还活着呢?有可能机器宕机,有可能运营商瘫痪,甚至有可能整个城市都被炸了.....在这种情况下,基于TCP/IP协议提出的keepalive(区别于HTTP协议提出的keepalive,也不是LVS负载均衡的keepalived,这三者不要混为一谈):即使双方没有真正的数据传输,也会周期性的发送检测数据来确实对方是否还活着,这样会对之后的资源把控和性能效率提供一定的帮助。
网络IO模型发展
先来看一段客户端的代码,将Java层面做的事情转化为Linux系统级的调用做了哪些事情
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
public class SocketIO {
public static void main(String[] args) throws Exception {
ServerSocket server = new ServerSocket(9090, 20);
System.out.println("step1 >> new ServerSocket(9090) ");
while (true) {
Socket client = server.accept(); // 阻塞
System.out.println("step2 >> client\t" + client.getPort());
new Thread(new Runnable() {
Socket ss;
public Runnable setSS(Socket s) {
ss = s;
return this;
}
@Override
public void run() {
try {
InputStream in = ss.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
while (true) {
System.out.println(reader.readLine());
}
} catch (IOException e) {
e.printStackTrace();
}
}
});
/*new Thread(() -> {
InputStream in = null;
try {
in = client.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
while (true) {
String dataline = reader.readLine(); // 阻塞
if (null != dataline) {
System.out.println(dataline);
} else {
client.close();
break;
}
}
System.out.println("客户端断开");
} catch (IOException e) {
e.printStackTrace();
}
}).start();*/
}
}
}无论是那种IO模型,只要是想通过网络IO和外界通信,app和kernel之间一定会经过系统调用。在上述的代码中,翻译成系统调用的角度来看:
Java代码:
ServerSocket server = new ServerSocket(9090, 20);
对应的系统调用为:
1、int socket(int domain, int type, int protocol);
返回值是个整型数字,如果执行成功的的话,返回的就是socket的文件描述符。执行成功之后,下一步调用bind;
2、int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
将返回的文件描述符和端口号进行绑定,绑定成功则返回0,错误则返回-1。绑定成功之后,下一步调用listen;
3、int listen(int sockfd, int backlog);
监听端口,有没有客户端进行连接
当有客户端连接之后,服务端会对连接进行处理,Java代码:
Socket client = server.accept();
对应的系统调用为:
4、int accept4(int sockfd, struct sockaddr *addr, socklen_t *addrlen, int flags);
接受的客户端的连接,完成两端连接的完整
起新的线程去接受客户端传输的数据,Java代码:
new Thread(new Runnable() {
Socket ss;
public Runnable setSS(Socket s) {
ss = s;
return this;
}
@Override
public void run() {
try {
InputStream in = ss.getInputStream();
BufferedReader reader = new BufferedReader(new InputStreamReader(in));
while (true) {
System.out.println(reader.readLine());
}
} catch (IOException e) {
e.printStackTrace();
}
}
});
对应的系统调用为:
5、int clone(int (*fn)(void *), void *child_stack, int flags, void *arg, ... /* pid_t *ptid, void *newtls, pid_t *ctid */ );
主线程clone出一个线程
6、ssize_t recv(int sockfd, void *buf, size_t len, int flags);
使用clone出的线程进行数据的接受
在这种BIO的模型下,因为是阻塞式的IO模型,主线程一直阻塞着监听有谁来连接、有谁来连接,自身无法在进行数据接受的处理。所以每次当有新的客户端连接进来的时候,主线程就会起一个新的线程去处理这个新的连接,而不是自身去处理这个连接。如果主线程自身来处理客户端的连接,那么除非等到这个连接处理结束之后,才能去处理其它的客户端连接。
C10K问题,及网络路由条目Bug
所谓C10K问题,指的是:服务器如何支持10k个并发连接,也就是concurrent 10000 connection,这也是C10K这个名字的由来。由于硬件成本的大幅度降低和硬件技术的进步,如果一台服务器能够同时服务更多的客户端,那么也就意味着服务每一个客户端的成本大幅度降低。从这个角度来看,c10k问题显得非常有意义。(关于C10K的前世今生,感兴趣的可以详细看下这篇介绍:http://www.kegel.com/c10k.html)
随着互联网普及率大大提高,用户群体几何倍增长。互联网不再是单纯地浏览www网页,逐渐开始进行交互,而且应用程序的逻辑也变得更复杂。从简单的表单提交,到即时通信和在线实时互动,C10K的问题才体现出来了。因为每一个用户都必须与服务器保持连接,才能进行实时数据交互。诸如Facebook这样的网站,同一时间的并发TCP连接很可能已经过亿。
早期的腾讯QQ也同样面临C10K问题,只不过他们是用了UDP这种原始的包交换协议来实现的,绕开了这个难题,当然过程肯定是痛苦的。如果当时有epoll技术,他们肯定会用TCP。众所周之,后来的手机QQ、微信都采用TCP协议。
这时候问题就来了,最初的服务器都是基于线程模型的。正如上面一小段程序模拟的BIO模型,每新到来一个TCP连接,就需要分配1个线程。线程又是操作系统最昂贵的资源,一台机器无法创建很多线程。如果是C10K,就要创建1万个线程,那么就单机而言,操作系统是无法承受的,往往出现效率低下、甚至完全瘫痪。
老规矩,还是会使用一小段代码来模拟一下C10K的问题,然后我们再来细说该怎么逐步优化。先将上文提到的SocketIOPropertites作为服务端启动,然后再启动一个窗口使用tcpdump查看进行抓包信息。服务端这边准备好之后,直接使用IDEA启动这个C10K的模拟程序:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.SocketChannel;
import java.util.LinkedList;
public class C10Kclient {
public static void main(String[] args) {
LinkedList<SocketChannel> clients = new LinkedList<>();
InetSocketAddress serverAddr = new InetSocketAddress("192.168.126.129", 9090);
// for 循环55000次
// 每循环一次会有相同IP地址和不同端口号的客户端
// 连接相同IP地址和相同端口号的服务端
// 相当于是用win的单机单线程,对同一个服务端发起110000次的连接
for (int i = 10000; i < 65000; i++) {
try {
// 每循环一次准备两个客户端
SocketChannel client1 = SocketChannel.open();
SocketChannel client2 = SocketChannel.open();
// 这个IP地址是VMWare虚拟机在计算机上安装的虚拟网卡IP地址
client1.bind(new InetSocketAddress("192.168.126.1", i));
client1.connect(serverAddr);
clients.add(client1);
// 这个IP地址是计算机的物理网卡IP地址
client2.bind(new InetSocketAddress("192.168.31.134", i));
client2.connect(serverAddr);
clients.add(client2);
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("clients >> " + clients.size());
try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}
}客户端的启动之后,可以看到服务端这边的连接情况好像有点不是很对劲的样子

按照代码里面写的,应该每个端口有两个连接到服务端才对,而且客户端这边还超时报错

win发送请求的时候,会拿着192.168.31.134作为原IP地址,目标IP地址是192.168.126.129。理论上只要双方可以ping通就可以成功创建连接才对,可为什么没有创建成功呢?
使用route -n查看服务端的路由表

服务端Linux的网卡地址是192.168.126.129,子网掩码是255.255.255.0,也就是说网络号是192.168.126.0,通过这个Linux可以直接访问126这个网络。但是和192.168.31.134却不是直连关系,在路由表中压根没有这个路由条目,那就只能走默认网关,以192.168.126.2为下一跳。而192.168.126.2就是VMWare虚拟机中VMnet8这块虚拟网卡的网关
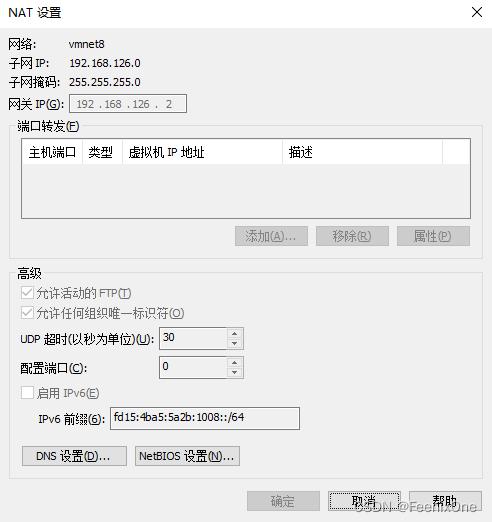
这个网络适配器叫NAT,就是win上的一个进程进行的网络地址转换。进来Linux的时候,数据包的原地址是192.168.31.134,目标地址是192.168.126.129;但是返回给客户端的数据包下一跳走的是192.168.126.2,所以返回的数据包经过NAT地址转换(会将192.168.126.129换成192.168.126.2)就变成原地址是192.168.126.2,目标地址是192.168.31.134。win拿到数据包后发现目标地址不是原先发出的原地址,就会将数据包丢弃,永远无法成功建立连接。
其实解决起来并不复杂,win上的VMWare虚拟机在计算机上安装的虚拟网卡,IP地址为192.168.126.1,也就是说win上是有192.168.126.1这个地址的。那么只要下一跳不走192.168.126.2,走192.168.126.1回到win上,win就会认回这个数据包建立连接。
route add -host 192.168.31.134 gw 192.168.126.1
因为Linux自身地址是192.168.126.129,返回的数据包经过自身同局域网的win网卡192.168.126.1作为下一跳回到win上即可。
BIO模型下Linux系统连接创建慢的原因
通过以上的小实验,可以看到在Linux的服务端中成功创建连接的速度很慢。我们都知道,客户端的连接过来之后,先是和服务端三次握手,握手之后就会调用kernel中的系统调用创建socket。主线程中是个死循环一直在accept,每一次客户端的连接过来都会起新的线程去处理这个连接。起这个新的线程的过程中,会调用kernel的clone系统调用来得到这个新的线程。又要进行线程资源的克隆,又要调用kernel创建新的线程,这两步都是非常消耗资源的事情。
如果说线程的创建占用了大量的资源,那么要是将线程池化,从线程池中去获取线程的话,会不会能提高效率呢。如果在线程数不多的情况下,确实可以。可是放在C10K的场景下, 有上万个线程等着切换分配资源,本身线程的切换自身就是一件很消耗资源的操作,在如此大量线程数的场景下挨个去切换线程,不仅不会加快效率,甚至速度上会更加拉胯。
想要彻底的解决这个问题,就得从根源抓起。慢是因为BIO的阻塞所导致,确切的说是因为kernel提供的系统调用就是阻塞式的,所以就需要kernel提供一种新的非阻塞式的系统调用。
看Linux提供的socket相关的系统调用:man 2 socket

从BIO到NIO
基于Linux提供的系统调用,JDK也有提供了相应的nio的包。但是JDK中的nio和系统调用的SOCK_NONBLOCK不是一个nio。NIO从操作系统角度来说是NON_BLOCKING的意思,从JDK的角度来说是NEW_IO的意思,一个区别于BIO的全新IO模型。用代码来模拟一下NIO的服务端:
import java.net.InetSocketAddress;
import java.net.StandardSocketOptions;
import java.nio.ByteBuffer;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.util.LinkedList;
public class SocketNIO {
public static void main(String[] args) throws Exception {
LinkedList<SocketChannel> clients = new LinkedList<>();
// 服务端开启监听,接受客户端
ServerSocketChannel ss = ServerSocketChannel.open();
ss.bind(new InetSocketAddress(9090));
// 设置为true >> 就是原先的BIO模型
// 设置为false >> 就是全新的NIO模型
ss.configureBlocking(false);
/*ss.setOption(StandardSocketOptions.TCP_NODELAY, false);
StandardSocketOptions.TCP_NODELAY
StandardSocketOptions.SO_KEEPALIVE
StandardSocketOptions.SO_LINGER
StandardSocketOptions.SO_RCVBUF
StandardSocketOptions.SO_SNDBUF
StandardSocketOptions.SO_REUSEADDR*/
while (true) {
// 无实际意义,保证每1s循环一次
/*Thread.sleep(1000);*/
// 接受客户端的连接,此时主线程不会一直阻塞着
// 调用完accept之后就会立刻返回结果,可能接收到,可能没接收到
// 如果没有接收到客户端,系统调用就会返回-1,Java层面就是返回null
// 如果有接收到客户端,系统调用就会返回这个客户端的文件描述符fd,Java层面就是封装成了对象
SocketChannel client = ss.accept();
if (client == null) {
System.out.println("null.....");
} else {
// 将客户端也设置为非阻塞
client.configureBlocking(false);
System.out.println("client's port: " + client.socket().getPort());
clients.add(client);
}
ByteBuffer buffer = ByteBuffer.allocateDirect(4096);
// 遍历已经成功建立的客户端连接,进行数据读写
// 因为是非阻塞的IO模型,主线程不需要一直傻等着accept返回
// 之前在BIO的时代,需要起新的线程去处理每个连接的数据传输
// 如今在NIO的时代,主线程自身就可以处理每个连接的数据传输
for (SocketChannel channel : clients) {
int num = channel.read(buffer);
if (num > 0) {
buffer.flip();
byte[] bytes = new byte[buffer.limit()];
buffer.get(bytes);
String str = new String(bytes);
System.out.println(channel.socket().getPort() + " : " + str);
buffer.clear();
}
}
}
}
}服务端程序启动之后,服务端开启监听,接受客户端。关键的一步:ss.configureBlocking(false);也就是设置为非阻塞模型。此时主线程在每次循环的时候接受客户端的连接就不会一直阻塞着。调用完accept之后就会立刻返回结果,可能接收到,可能没接收到。如果没有接收到客户端,系统调用就会返回-1,Java层面就是返回null。如果有接收到客户端,系统调用就会返回这个客户端的文件描述符fd,Java层面就是封装成了对象。
继续使用C10K来模拟客户端的连接。可以明显看到使用给了NIO模型之后,省略了线程资源的克隆和新线程的创建,连接建立的速度要比BIO快很多。但感觉上似乎还是差点意思,快是快了,但快的还不够。于是,便诞生了多路复用器。
从NIO到多路复用器
在NIO模型下,虽然一个主线程可以对接所有的事情。但是每一个操作还是需要去和内核交互,触发系统调用,这些都是软件程序主动的。无论是接受每一个客户端的数据,还是尝试去读取有没有客户端连接。NIO是一个单线程的模型,所有客户端的连接都需要主线程去循环遍历一个一个处理,也就是说每循环一次的成本都是O(n)。从这个角度上来讲,当客户端连接数达到C10K这个规模之后,主线程循环一次,就要进行10000次的系统调用,有数据吗,有数据吗.....但实际上真正有数据来的连接大多数情况下并不多,或许也就三五条有数据过来,剩下绝大部分是没有数据过来的,这种调用是没有意义的,纯纯的浪费系统资源。这里提一嘴,系统调用里面会牵扯到软中断,然后切换用户态和内核态,保护现场、恢复线程,进程调度等等一系列事情,还是比较复杂的,所以成本比较高。这里还是涉及到挺深的计算机组成和操作系统原理方面的知识,后面有时间我会详细讲解一下。
那么换一种思路来考虑这个问题。连接中的数据有没有到达,kernel是第一个先知道的。如果每次询问kernel的时候,不仅仅只问某一个连接的数据到没到,而是问所有的连接中有哪些连接是有了数据的。这就达到了通过一次调用访问所有的路的状态,就实现了多路被一个调用复用了,这就是大名鼎鼎的多路复用器。
多路的路指的就是每一个成功建立的连接,在知道哪些路中有数据之后,由程序自己对有数据的连接进行处理。在这种模型下,只要程序自己读写,那么这种IO模型就是同步的。注意,这里说的是IO模型是同步的,不是说读完了IO状态后的数据处理方式是同步还是异步。既然说到这个,就再对IO模型的同步/异步梳理一下:所谓同步指的就是程序自己对IO中的数据进行读写;而异步指的就是由kernel对IO中的数据进行读写(就是在进程中开辟一个buffer,kernel自己将数据读写到这个buffer中,不再需要程序去调用kernel的系统调用read/recv对数据进行读写)。
在Linux系统中,提供了诸如select、poll以及epoll这些具体的系统调用接口来实现多路复用器。poll可以看成是对select的一个升级,二者基本相似,略有差别,而epoll与前二者相比则是截然不同的全新设计。
select
Linux文档(man 2 select)中对其的介绍是

这里有一个需要注意的点是这个FD_SETSIZE的大小,有人说是1024,有人说是2048,这个数值指的就是多路复用器的路的数量,一次性最多能遍历多少条路。

所以现在Linux中select基本已经不怎么使用了,主要就是可以询问的路数有限:
int select(int nfds, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
最后一个参数*timeout指的是等待的时间(单位:毫秒),为0就一直阻塞等待着,不为0有设定一个时间的话,超过这个时间之后就不在等待,先处理别的事情去,等下一个循环再回来再调用这个多路复用器继续询问状态。
这个过程在程序代码中的具体实现,应该是先来一个while循环,不断的去调用select,将想要询问状态的fds作为参数传入,返回的就是那些有数据的fds。然后程序再调用read/recv去对fds中的数据进行读写。在每一次while的循环中,只调用了一次select系统调用,所以复杂度从NIO的O(n)降为O(1),然后掉read/recv的复杂度为O(m),m就是返回的有数据的fds的数量。
poll
poll相对于select最显著的区别就是取消了1024的路数限制,Linux文档(man 2 poll)中对其的介绍是

从文档中也可以看出,它也是一个单独的系统调用,没有多个系统调用进行组合:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
什么时候想问了,就把这些*fds文件描述符传进来,调用完把那些有数据的fds返回,和select一样也支持设置时间参数来控制超时限制。
select/poll是一个相对容易实现的,并且不同操作系统kernel的具体实现方式约束很少的一种系统调用。而epoll要求kernel中具备一定的实现,在Linux中叫epoll,在Unix中叫kqueue,这两种都是基于IO事件的通知行为。说白了只要遵守POSIX标准(对select的标准叫pselect,Linux遵循pselect标准的具体实现是select,别的操作系统不一定叫select),任何操作系统本身都可以实现select这种多路复用器。
无论是NIO,还是select/poll这种多路复用器,其实都是要遍历所有的IO来询问状态。只是在NIO中,这个遍历过程的成本在用户态和内核态的切换;而在select/poll中,这个遍历的过程仅触发了一次系统调用(也就是用户态和内核态的切换),将多个fds传递给kernel,kernel重新根据用户这次调用传过来的fds,将其对应的IO一一遍历,并返回有数据的fds。
基于select/poll模型下对于IO的全量遍历,也使得这种多路复用器的弊端非常明显:
1、每次调用select/poll时都要反复传递fds;
2、每次kernel被调用之后,针对该次调用,都会触发一个遍历fds全量的复杂度;
正是由于select/poll中存在的这些问题,于是便诞生了epoll。但是在介绍epoll之前,先插入一个小小的知识点:操作系统的中断处理。如果这个只是不搞明白,epoll将很难彻底理解清楚。
中断处理
中断包括硬中断和软中断,是指计算机运行过程中,出现某些意外情况需主机干预时,机器能自动停止正在运行的程序并转入处理新情况的程序,处理完毕后又返回原被暂停的程序继续运行。
整个操作系统可理解为一个由中断驱动的死循环,其他所有事情都是由操作系统提前注册的中断机制和其对应的中断处理函数完成,点击鼠标和键盘,执行一个程序,都是用中断的方式来通知操作系统来处理这些事件,当没有任何需要操作系统处理的事件时,它就停在死循环里。
app调用kernel中的方法,这种属于软中断(或者叫陷阱),CPU读取了app中的一个指令(这个指令就是CPU指令集中的),而一般这个指令都是以int开头。kernel初始化的时候,维护了一张中断向量表,这张表用一个字节来存放,也就是一共最多有255种。假设CPU读到了int 80指令,就会去中断向量表中查询第80号指定,然后执行相应的操作。
硬中断是与系统相连的外设(比如网卡、硬盘)自动产生的。主要是用来通知操作系统系统外设状态的变化。比如当网卡收到数据包的时候,就会发出一个中断。通常所说的中断指的是硬中断,而IO中断也属于硬中断的一种。
客户端发送的数据从到达服务端的网卡,网卡中会开辟一个buffer空间,当buffer中的数据满了之后就会发起一次IO中断,打断CPU将网卡buffer中的数据读取,写入内存中的DMA。DMA是kernel中的网卡驱动被激活之后,在内存中开辟的一个空间,这个空间的地址会直接与网卡相绑定,可以理解成是专门给网卡开辟的绿色通道。当客户端连接的数量达到一定量级,发起中断次数过于频繁,CPU会专门用一个时间周期对网卡进行主动轮询,而不是被动打断。
中断会产生回调callback,可以抽象成基于event的事件概念,那么在回调后就会对事件进行处理。在epoll之前的callback中的处理:只是完成了将网卡发来的数据走一下kernel网络的协议栈(从物理层到传输控制层),最终关联到fd的buffer中。所以在某一时间从app询问kernel某一个或者某些fd是否有数据可读写,就会有状态返回。
epoll
Linux文档中对于epoll系统调用的描述共有种:

前面说到,每次调用select/poll时都要反复传递fds,如果kernel可以开辟一个空间,将第一次传入的fds存下,就无需再每次调用的时候反复传递fds,这就是epoll_create做的事情。调用epoll_create成功之后会返回一个fd,而这个fd代表的就是kernel开辟的一个内核空间,这个空间中会放一个红黑树。

拿到返回的fd之后,就会频繁的调用epoll_ctl:
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
这个方法中的几个参数大致指的就是:
int epfd:就是调用epoll_creat返回的fd;
int op:在内核空间中要做的事情。文档中也有给出相应的操作:EPOLL_CTL_ADD-添加、EPOLL_CTL_MOD-修改、EPOLL_CTL_DEL-删除;
int fd:操作的具体的文件描述符。是正在listen的socket,还是已经建立成功的socket;
struct epoll_event *event:具体关注的事件,是READ还是WRITE;

最后调用epoll_wait,等待着有状态事件的返回。kernel中会维护一个链表,伴随着kernel基于中断处理完红黑树中fd的buffer、状态等之后,继续把有状态的fd拷贝到链表中。所以程序只要调用epoll_wait就能及时取走有状态的fd的结果集,得到fd的结果集之后,程序再自行去根据fd进行数据的读写处理。所以,epoll_wait本质上也是同步模型。
在select/poll时代,每次调用都要传递全量的fds。而程序调用epoll_wait的时候,无需传递任何的fds,因为在调用epoll_create的时候kernel已经记住了有哪些fds。epoll_wait相较于select/poll而言,不仅不传参,而且不会触发文件描述符的全量遍历。从这个角度来说,epoll_wait这一步的调用等同于select/poll的调用。
Java底层Selector对象
多路复用器在Java中被封装成Selector对象,来看具体的演示代码和注释:
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.Set;
public class SocketMultiplexingSingleThreadv1 {
private ServerSocketChannel server = null;
private Selector selector = null; // Linux下先定义一个多路复用器
int port = 9090;
/**
* Linux下默认是使用epoll多路复用器,可以通过参数设置,在poll和epoll之间进行切换
* epoll:-Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.EPollSelectorProvider
* poll:-Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.PollSelectorProvider
*/
public void initServer() {
try {
server = ServerSocketChannel.open();
server.configureBlocking(false); // 设置为非阻塞
server.bind(new InetSocketAddress(port)); // 绑定端口号
// 如果多路复用器使用的是epoll,这一步相当于是调用epoll_create
selector = Selector.open();
// 服务端注册多路复用器
// 如果多路复用器使用的是select/poll,会在JVM中开辟一个数组,将fd放进去
// 如果多路复用器使用的是epoll,这一步相当于是epoll_ctl,将上一步epoll_create返回的fd传入
server.register(selector, SelectionKey.OP_ACCEPT);
} catch (IOException e) {
e.printStackTrace();
}
}
public void start() {
initServer();
System.out.println("服务器启动了.....");
try {
while (true) {
Set<SelectionKey> keys = selector.keys();
System.out.println("keys.size():" + keys.size());
// 调用多路复用器,但多路复用器有很多种:select、poll、epoll
// 如果多路复用器使用的是select/poll,就是调用kernel的select方法
// 如果多路复用器使用的是epoll,这一步相当于是epoll_wait
// 参数可以带阻塞时间,没有时间就是0不阻塞
while (selector.select() > 0) {
// 返回的有状态的fd集合
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iter = selectionKeys.iterator();
// 无论调用的是哪一种多路复用器,都只能返回状态
// 程序自身还得一个一个的去处理它们的R/W,同步模型好辛苦!
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove(); // 如果不移除,会重复循环处理
if (key.isAcceptable()) {
// 如果要去接受一个新的连接
// accept接受连接且返回新连接的fd,那新的fd怎么办
// 在select/poll下,因为它们内核没有开辟空间,只能在JVM中保存
// 在epoll下,可以通过epoll_ctl把新的客户端fd注册到内核空间
acceptHandler(key);
} else if (key.isReadable()) {
// 在当前线程,这个方法可能会阻塞,如果阻塞了十年.....
// 所以,这就是为什么提出了 IO THREADS
// 我们所熟知的Redis、Tomcat 8/9等等,都会在IO和具体的读写上进行解耦分层处理
readHandler(key);
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public void acceptHandler(SelectionKey key) {
try {
ServerSocketChannel ssc = (ServerSocketChannel) key.channel();
SocketChannel client = ssc.accept(); // accept接受客户端
client.configureBlocking(false);
ByteBuffer buffer = ByteBuffer.allocate(8192); // 开辟buffer空间,缓存读写的数据
// 和服务端的处理一样
// 如果多路复用器使用的是select/poll,会在JVM中开辟一个数组,将fd放进去
// 如果多路复用器使用的是epoll,这一步相当于是epoll_ctl,将上一步epoll_create返回的fd传入
client.register(selector, SelectionKey.OP_READ, buffer);
System.out.println("-------------------------------------------");
System.out.println("新客户端:" + client.getRemoteAddress());
System.out.println("-------------------------------------------");
} catch (IOException e) {
e.printStackTrace();
}
}
public void readHandler(SelectionKey key) {
SocketChannel client = (SocketChannel) key.channel();
ByteBuffer buffer = (ByteBuffer) key.attachment();
buffer.clear();
int read = 0;
try {
while (true) {
read = client.read(buffer);
if (read > 0) {
buffer.flip();
while (buffer.hasRemaining()) {
client.write(buffer);
}
buffer.clear();
} else if (read == 0) {
break;
} else {
client.close();
break;
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
SocketMultiplexingSingleThreadv1 service = new SocketMultiplexingSingleThreadv1();
service.start();
}
}接下来将这套代码搬到Linux上跑起来,看下在不同的多路复用器中具体的系统调用是怎样。先来看下poll模型下,需要用到一个新的工具来帮助查看系统调用和进程接收的信号:strace。
strace是一个非常有用的诊断、指导和调试工具。系统管理员、诊断专家和故障解决人员将发现,对于解决源代码不易获得的程序的问题,这是非常宝贵的,因为它们不需要重新编译以跟踪它们。学生、黑客和过分好奇的人会发现,通过跟踪甚至是普通程序,可以了解到大量关于系统及其系统调用的信息。程序员会发现,由于系统调用和信号是发生在用户/内核界面上的事件,因此仔细检查该边界对于错误隔离、健全性检查和尝试捕获竞争条件非常有用。strace运行时它拦截并记录进程调用的系统调用和进程接收的信号。每个系统调用的名称、参数及其返回值都打印在标准错误上或打印到使用-o选项指定的文件中。
利用strace命令进行系统调用的监测,并设置成使用poll模型:
strace -ff -o poll java -Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.PollSelectorProvider SocketMultiplexingSingleThreadv1
服务端开启之后,再开一个窗口使用nc localhost 9090模拟客户端连接,然后给服务端发送一些数据,此时再看当前目录下,就会生成很多以poll....开头的文件,这就是strace将系统调用打印成文本输出。打开其中一个,具体来看有哪些系统调用,和前面说的是否一致(蓝色文字为strace输出的系统调用内容)。
建立socket连接,返回文件描述符:
socket(AF_INET, SOCK_STREAM, IPPROTO_IP) = 6
设置非阻塞,这一步相当于Java代码中的server.configureBlocking(false):
fcntl(6, F_SETFL, O_RDWR|O_NONBLOCK) = 0
绑定端口号,这一步相当于Java代码中的server.bind(new InetSocketAddress(port)):
bind(6, {sa_family=AF_INET6, sin6_port=htons(9090), sin6_flowinfo=htonl(0), inet_pton(AF_INET6, "::", &sin6_addr), sin6_scope_id=0}, 28) = 0
监听连接:
listen(6, 50)
这一步相当于Java代码中的while (selector.select() > 0) {.....,循环遍历建立成功的连接:
poll([{fd=7, events=POLLIN}, {fd=6, events=POLLIN}], 2, -1) = 1 ([{fd=6, revents=POLLIN}])
在循环中进行数据接受的处理:
accept(6, {sa_family=AF_INET6, sin6_port=htons(55364), sin6_flowinfo=htonl(0), inet_pton(AF_INET6, "::1", &sin6_addr), sin6_scope_id=0}, [28]) = 9
对客户端连接进行非阻塞操作:
fcntl(9, F_SETFL, O_RDWR|O_NONBLOCK) = 0
继续处理循环中的客户端,到这一步终于找到一点多"路""复用"器的感觉:
poll([{fd=7, events=POLLIN}, {fd=6, events=POLLIN}, {fd=9, events=POLLIN}], 3, -1) = 1 ([{fd=9, revents=POLLIN}])
具体对数据的读取调用:

看过了poll模型下的系统调用之后,同样的一套代码,再将参数设置成使用epoll模型下,看看系统会进行那些系统调用(绿色文字为strace输出的系统调用内容):
strace -ff -o epoll java -Djava.nio.channels.spi.SelectorProvider=sun.nio.ch.EPollSelectorProvider SocketMultiplexingSingleThreadv1
建立socket连接,返回文件描述符:
socket(AF_INET, SOCK_STREAM, IPPROTO_IP) = 6
设置非阻塞,这一步相当于Java代码中的server.configureBlocking(false):
fcntl(6, F_SETFL, O_RDWR|O_NONBLOCK) = 0
绑定端口号,这一步相当于Java代码中的server.bind(new InetSocketAddress(port)):
bind(6, {sa_family=AF_INET6, sin6_port=htons(9090), sin6_flowinfo=htonl(0), inet_pton(AF_INET6, "::", &sin6_addr), sin6_scope_id=0}, 28) = 0
epoll的文件描述符:
epoll_create(256) = 7
添加监听的文件描述符:
epoll_ctl(7, EPOLL_CTL_ADD, 8, {EPOLLIN, {u32=8, u64=139874199928840}}) = 0
这一步相当于Java代码中的while (selector.select() > 0) {.....,循环遍历建立成功的连接:
epoll_wait(7, [{EPOLLIN, {u32=6, u64=139874199928838}}], 1024, -1) = 1
在循环中进行数据接受的处理:
accept(6, {sa_family=AF_INET6, sin6_port=htons(55368), sin6_flowinfo=htonl(0), inet_pton(AF_INET6, "::1", &sin6_addr), sin6_scope_id=0}, [28]) = 10
对客户端连接进行非阻塞操作:
fcntl(10, F_SETFL, O_RDWR|O_NONBLOCK) = 0
再次添加另一个监听的文件描述符,到这一步和上面一样开始体现出多"路""复用"器的感觉:
epoll_ctl(7, EPOLL_CTL_ADD, 10, {EPOLLIN, {u32=10, u64=139874199928842}}) = 0
手写基于多路复用器的多线程IO处理
通过上面的知识点,基本上常见的几种IO模型算是说的明明白白,连底层实现也扒出来看了。但是这些理论知识基本上都是基于单线程处理IO的情况下,一个线程的能力毕竟是有限的,想要提高效率多线程必然是绕不开的话题。既然说到多线程,就得换一个思路:在单线程的时候,每个线程都要监听、接受、处理客户端读写数据。虽然在多线程的时候,通过线程数来均衡客户端的处理,但是每个线程还是逃不了要去监听、接受、处理客户端读写数据,有没有更高的提高效率方案呢?假设将监听、接受、处理数据这些功能拆开,让某一个线程专门去监听,然后接收到的客户端分配给其它线程进行数据处理,这样各司其职,就不需要每一个线程都去做大多数时候基本上毫无意义的监听事情,只要专心去处理数据读取即可。那么按照这个思路,来实现一版基于多路复用器的多线程IO处理。
写之前先规划一下主要的骨架:
1、准备一个主线程MainThread,在主线程中不做任何关于IO和业务的处理,通过主线程来孵化出其它的IO线程和业务处理线程;
2、创建一个多路复用器的线程SelectorThread,每一个线程对应一个Selector。在多线程的情况下,并发客户端被分配到多个Selector上。注意,每个客户端只绑定到其中一个Selector上,从而保证每个Selector负责一部分的客户端,各个Selector之间不会对某一个线程产生交互问题;
3、那么线程多了以后,具体每个客户端到底怎么绑定,就需要一个ThreadGroup来进行管理;
MainThread
/**
* 准备一个主线程MainThread
* 在主线程中不做任何关于IO和业务的处理
* 通过主线程来孵化出其它的IO线程和业务处理线程
*/
public class MainThread {
public static void main(String[] args) {
// 在主线程中创建一个或多个IO线程
// 当只有1个线程的时候,既要负责监听,又要负责读写
// 当有多个线程的时候,一个Leader负责监听分配,其余的Worker负责读写
// 但是在SelectorThreadGroup中的分配算法是很拉胯的轮询
// 这样就会势必造成有一个线程既是Leader,也是Worker,所以要避免简单的轮询
SelectorThreadGroup leader = new SelectorThreadGroup(3);
SelectorThreadGroup worker = new SelectorThreadGroup(3);
// Leader持有Worker的引用
// Boss里选一个线程注册listen,触发bind
// 使得这个不选中的线程得持有WorkerGroup的引用
// 未来只要accept得到client之后
// 就可以从worker中next出一个线程分配
leader.setWorker(worker);
// 将监听的server注册到某一个Selector中
leader.bind(9999);
}
}SelectorThread
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.*;
import java.util.Iterator;
import java.util.Set;
import java.util.concurrent.LinkedBlockingQueue;
/**
* 创建一个多路复用器的线程SelectorThread
* 每一个线程对应一个Selector
* 在多线程的情况下,并发客户端被分配到多个Selector上
* 注意,每个客户端只绑定到其中一个Selector上
* 从而保证每个Selector负责一部分的客户端
* 各个Selector之间不会对某一个线程产生交互问题
*/
public class SelectorThread implements Runnable {
Selector selector = null;
LinkedBlockingQueue<Channel> lbq = new LinkedBlockingQueue<>();
SelectorThreadGroup stg;
SelectorThread(SelectorThreadGroup stg) {
try {
this.stg = stg;
selector = Selector.open();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
public void run() {
while (true) {
try {
System.out.println("before select:" + Thread.currentThread().getName() + ",selector key size:" + selector.keys().size());
// 阻塞,没有传参就会一直等待有状态的线程返回,有传参就是指定阻塞等待的时间
// 如果在其它地方调用selector.wakeup()方法,就会跳出当前阻塞
int nums = selector.select();
System.out.println("after select:" + Thread.currentThread().getName() + ",selector key size:" + selector.keys().size());
// 处理selectKeys
if (0 < nums) {
Set<SelectionKey> keys = selector.selectedKeys();
Iterator<SelectionKey> iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
// 接收客户端之后,要将客户端注册到哪里呢?
if (key.isAcceptable()) {
acceptHandler(key);
} else if (key.isReadable()) {
readHandler(key);
} else if (key.isWritable()) {
}
}
}
// 处理一些task
if (!lbq.isEmpty()) {
Channel c = lbq.take();
if (c instanceof ServerSocketChannel) {
ServerSocketChannel server = (ServerSocketChannel) c;
server.register(selector, SelectionKey.OP_ACCEPT);
} else if (c instanceof SocketChannel) {
SocketChannel client = (SocketChannel) c;
ByteBuffer buffer = ByteBuffer.allocateDirect(4096);
client.register(selector, SelectionKey.OP_READ, buffer);
}
}
} catch (IOException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
// 客户端读取处理
public void readHandler(SelectionKey key) {
System.out.println("readHandler方法被调起.....");
ByteBuffer buffer = (ByteBuffer) key.attachment();
SocketChannel client = (SocketChannel) key.channel();
buffer.clear();
while (true) {
try {
// 读取到了多少字节
int num = client.read(buffer);
if (0 < num) {
// 将读到的内容翻转,然后直接写出
buffer.flip();
while (buffer.hasRemaining()) {
client.write(buffer);
}
buffer.clear();
} else if (0 == num) {
// 没有读取到内容,直接跳出即可
break;
} else if (0 > num) {
// 客户端断开异常
System.out.println("client[" + client.getRemoteAddress() + "]已断开");
key.cancel();
break;
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
// 接收客户端
public void acceptHandler(SelectionKey key) {
System.out.println("acceptHandler方法被调起.....");
ServerSocketChannel server = (ServerSocketChannel) key.channel();
try {
SocketChannel client = server.accept();
client.configureBlocking(false);
// 选择一个多路复用器,并将客户端注册其中
stg.nextSelector(client);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
public void setWorker(SelectorThreadGroup stgWorker) {
this.stg = stgWorker;
}
}ThreadGroup
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.channels.Channel;
import java.nio.channels.ClosedChannelException;
import java.nio.channels.SelectionKey;
import java.nio.channels.ServerSocketChannel;
import java.util.concurrent.atomic.AtomicInteger;
public class SelectorThreadGroup {
SelectorThread[] sts;
ServerSocketChannel server = null;
AtomicInteger xid = new AtomicInteger(0);
SelectorThreadGroup stg = this;
public void setWorker(SelectorThreadGroup stg) {
this.stg = stg;
}
SelectorThreadGroup(int threadCount) {
sts = new SelectorThread[threadCount];
for (int i = 0; i < threadCount; i++) {
sts[i] = new SelectorThread(this);
new Thread(sts[i]).start();
}
}
public void bind(int port) {
try {
server = ServerSocketChannel.open();
server.configureBlocking(false);
server.bind(new InetSocketAddress(port));
// server该注册到哪一个Selector上呢?
nextSelector(server);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* ServerSocketServerSocketChannel和SocketChannel都可以复用这个方法
* 所以参数直接传递二者的父类Channel即可
*/
public void nextSelector(Channel channel) {
try {
if (channel instanceof ServerSocketChannel) {
SelectorThread st = next();
st.lbq.put(channel);
st.setWorker(stg);
st.selector.wakeup();
} else {
// 在主线程中,取到堆里的SelectorThread对象
SelectorThread st = nextV2();
// 通过队列传递数据
st.lbq.add(channel);
// 通过打断阻塞,让对应的线程在自己打断后完成注册Selector
st.selector.wakeup();
}
} catch (InterruptedException e) {
}
}
private SelectorThread next() {
int index = xid.incrementAndGet() % sts.length;
return sts[index];
}
public void nextSelectorV2(Channel channel) {
try {
if (channel instanceof ServerSocketChannel) {
sts[0].lbq.put(channel);
sts[0].selector.wakeup();
} else {
SelectorThread st = nextV2();
st.lbq.add(channel);
st.selector.wakeup();
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
private SelectorThread nextV2() {
int index = xid.incrementAndGet() % stg.sts.length;
return stg.sts[index];
}
}
程序跑起来,多连接几个客户端进来,可以看到[0、1、2]线程为一组,作为Leader,[3、4、5]线程为一组,作为Worker。客户端进来的连接全都是被Leader组中的线程1给监听到,然后分配到[3、4、5]线程组上循环。
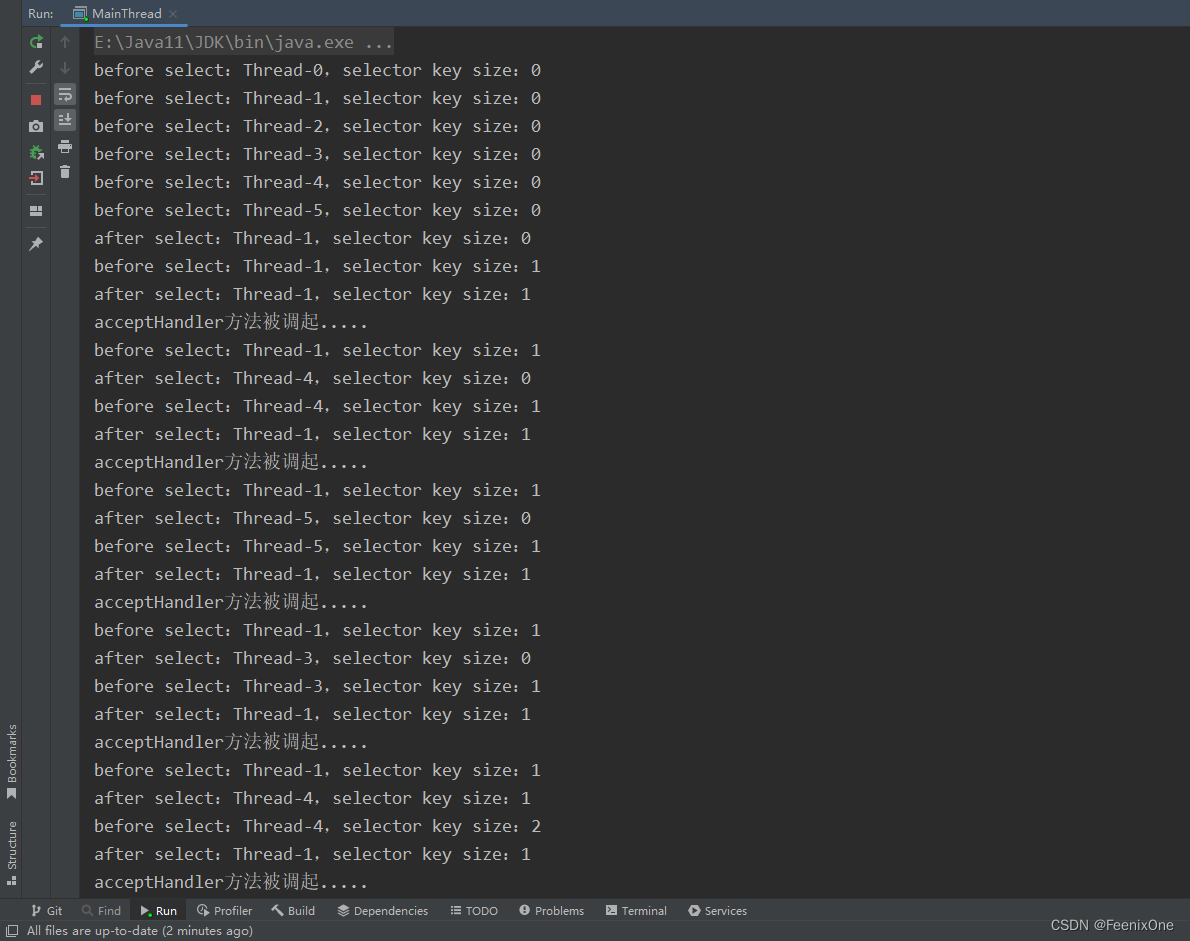
看着好像很熟悉是不是,没错,netty的核心基本也是这么干的,上面程序的设计思路基本和Netty的架构图多少也能对得上一些
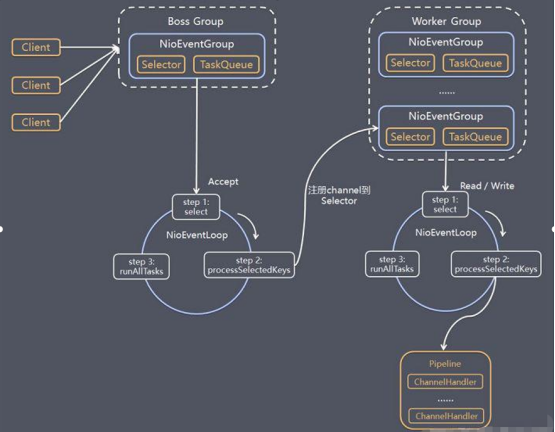
IO模型的讲解到这里基本就告一段落了,关于Netty的一切,下一篇不见不散.....