在开始学习多线程与高并发的知识之前,我想先问一个问题:你平时在写代码的时候,有没有刻意的去思考如何压榨CPU性能?其实纵观整个编程的发展历史,其实就是一部对于CPU性能压榨的血泪史。
单进程人工切换
最早的编程其实就是一个纸带机,所谓变成就是在纸带上戳针眼儿,然后计算器去读取纸带上的针眼儿进行运算,想要切换执行的程序,只能等着人们将纸带拿走换成另一个纸带,CPU的性能浪费在等待人工的动作上(不过那时候CPU的性能也没高到哪里去,浪费也浪费不了多少)。
多进程批处理
后面人们学精了,在纸带上一次性写多个程序,让CPU一次性全部执行。但是这样对于CPU的利用率也没提高多少。因为排在前面的程序如果阻塞了,排在后面的程序依然无法执行,该等待还是要等待。
多进程并行处理
等到操作系统诞生之后,引入了并行处理的概念,把程序写在不同的内存位置上来回切换,这成为了OS对CPU性能压榨的通用手段。在OS的管理下,CPU无论计算的多快,也不会闲着。
多线程的诞生
随着程序发展的越来越复杂,同一个进程内部也会有很多不同的任务在并行执行。有的任务在刷新UI、有的任务在后台把数据保存到数据库.....这样就产生了线程的概念。线程是属于进程内部并行执行的不同任务路线,想要提高线程执行效率,这里面的知识体系非常的琐碎,和IO方面的知识混杂揉搓在一起,后面如果有空我会单独出一篇IO方面的讲解。、
纤程的引入
随着系统中线程起的越来越多,人们发现大量宝贵的资源都浪费在线程间来回的切换上,真正用于正经干活的资源都被大量占用浪费,于是便探索所谓的绿色线程,让用户自己来管理。也就是运行在用户空间, 无需经过内核空间的切换,使得这种资源上的切换非常的轻量级。人们把这种轻量级的绿色线程叫做纤程,也叫协程。

1、线程切换的本质
作为CPU来说有几个重要的组成单元:ALU,Register,PC 等。PC其实也算是寄存器的一种,用来存储到底执行到哪一条指令。当执行一个线程的时候后,线程中的指令会存放在PC中,数据存放在Register中,不同线程的切换就是将不同线程的指令、数据拿去给CPU做计算,这个线程算好了,再把下个线程的指令、数据拿给CPU。CPU其实是一个特别傻的东西,它就只会算,给我什么指令什么数据,我把结果给你算出来,别的什么都不管。至于现在执行的是谁的指令,算的是哪个线程的数据,CPU也不知道,这归操作系统管。

根据以上线程切换的本质,就会诞生一些比较好玩的问题:
单核CPU设定多线程是否有意义
一个核心在同一时间点只能运行一个线程,那么线程数多了还有没有意义呢?其实是非常有意义的,因为线程中不是所有的操作都是需要CPU进行计算的,比如有些数据算完以后需要进行网络的传输,要从数据库中查询或者保存.....这些都是不需要占用CPU的计算资源的,那么在等待做这些事情的时候,CPU也别闲着,就可以继续计算别的线程中的数据,充分利用CPU的资源,所以单核CPU设定多线程的意义不仅有,而且很大。
当然,这个其实和线程的类型也有关系。比如有的是CPU密集型的线程,就是绝大部分时间都在利用CPU做计算,这种线程对CPU的利用率比较高;有的是IO密集型的线程,就是绝大部分时间都在利用IO对数据进行输入输出,对CPU的需求不高,简单的消耗一些CPU的资源。当然绝大多数的线程时既有CPU计算,也有IO数据传输,针对性没有那么明显。
工作线程数是不是设置的越多越好
这个肯定都知道线程数不是越多越好,上面说过线程间的切换也是要消耗不小的资源,线程数过多的话,系统那点资源全浪费在线程间的切换上了。
package com.feenix.juc.c_000_threadbasic;
import java.text.DecimalFormat;
import java.util.Random;
import java.util.concurrent.CountDownLatch;
public class T01_MultiVSSingle_ContextSwitch {
//===================================================
private static double[] nums = new double[1_0000_0000];
private static Random r = new Random();
private static DecimalFormat df = new DecimalFormat("0.00");
static {
for (int i = 0; i < nums.length; i++) {
nums[i] = r.nextDouble();
}
}
private static void m1() {
long start = System.currentTimeMillis();
double result = 0.0;
for (int i = 0; i < nums.length; i++) {
result += nums[i];
}
long end = System.currentTimeMillis();
System.out.println("m1: " + (end - start) + " result = " + df.format(result));
}
//=======================================================
static double result1 = 0.0, result2 = 0.0, result = 0.0;
private static void m2() throws Exception {
Thread t1 = new Thread(() -> {
for (int i = 0; i < nums.length / 2; i++) {
result1 += nums[i];
}
});
Thread t2 = new Thread(() -> {
for (int i = nums.length / 2; i < nums.length; i++) {
result2 += nums[i];
}
});
long start = System.currentTimeMillis();
t1.start();
t2.start();
t1.join();
t2.join();
result = result1 + result2;
long end = System.currentTimeMillis();
System.out.println("m2: " + (end - start) + " result = " + df.format(result));
}
//===================================================================
private static void m3() throws Exception {
final int threadCount = 1024;
Thread[] threads = new Thread[threadCount];
double[] results = new double[threadCount];
final int segmentCount = nums.length / threadCount;
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
int m = i;
threads[i] = new Thread(() -> {
for (int j = m * segmentCount; j < (m + 1) * segmentCount && j < nums.length; j++) {
results[m] += nums[j];
}
latch.countDown();
});
}
double resultM3 = 0.0;
long start = System.currentTimeMillis();
for (Thread t : threads) {
t.start();
}
latch.await();
for (int i = 0; i < results.length; i++) {
resultM3 += results[i];
}
long end = System.currentTimeMillis();
System.out.println("m3: " + (end - start) + " result = " + df.format(result));
}
public static void main(String[] args) throws Exception {
m1();
m2();
m3();
}
}
从上面的程序中可以看出,适当的运用多个线程可以提高CPU的效率,缩短执行时间,但是过度的起多个线程,起不到提高效率、缩短执行效率的作用。
工作线程数(线程池中线程数量)设多少合适
国外有本书叫《Java并发编程实践》,这本书中给出了一个计算线程数的公式:

这个公式的准确性其实有待商榷,网上很多线程数计算公式也基本都是基于这个公式进行的说是改良也好,说是优化也罢。其实这个公式的意义怎么讲,面试大于实用吧。对于绝大多数的人来说,我怎么知道W是多少,C是多少?这个比值有几个人能一口说出?这个只能基于部署之后,经过大量的测试,一定程度的统计之后才能知道。
本身对于线程数的设定就不是脑子一热拍脑门就能决定的事,只有经过不断的测试,大量的数据结果作为支撑,才能寻找到最合适的线程数。
2、线程基础
创建线程的5种方法
1、继承Thread类,重写run方法;
// 创建线程
static class MyThread extends Thread {
@Override
public void run() {
System.out.println("Hello MyThread!");
}
}
// 启动线程
new MyThread().start();2、实现Runnable接口,重写run方法;
// 创建线程
static class MyRun implements Runnable {
@Override
public void run() {
System.out.println("Hello MyRun!");
}
}
// 启动线程
new Thread(new MyRun()).start();经常有人会问,方法1和方法2哪个方式更好?明显是方法2更加灵活一些,方法2实现了接口之后还可以去继承别的类,但是方法1继承了一个类之后就不能再去继承别的类了。
3、使用Lambda表达式
new Thread(() -> {
System.out.println("Hello Lambda!");
}).start();4、使用线程池
// 创建线程池
ExecutorService service = Executors.newCachedThreadPool();
// 线程中要执行的任务
service.execute(() -> {
System.out.println("Hello ThreadPool");
});
// 关闭线程池
service.shutdown();5、实现Callable接口,重写call方法,可以配合线程池使用
static class MyCall implements Callable<String> {
@Override
public String call() {
System.out.println("Hello MyCall");
return "success";
}
}
// 创建线程池
ExecutorService service = Executors.newCachedThreadPool();
// 启动线程
Future<String> future = service.submit(new MyCall());
String s = future.get();
System.out.println(s);
// 关闭线程池
service.shutdown();Callable这个接口是为了弥补Runnable接口没有返回值而推出的,线程执行完了之后的返回值它给你装在Future这类中(老外起名字还挺有意思,没执行可不就是未来~~)。需要注意的是,取值的这个方法是个阻塞类型的:String s = future.get(),到这之后就等着,什么时候拿到这个值什么时候继续往下走。
如果不想使用线程池的话,JDK的玩法有点绕了个圈子
static class MyCall implements Callable<String> {
@Override
public String call() {
System.out.println("Hello MyCall");
return "success";
}
}
FutureTask<String> task = new FutureTask<>(new MyCall());
Thread t = new Thread(task);
t.start();
System.out.println(task.get());先搞一个FutureTask类中传入实现了Callable的类,然后将这个FutureTask放进Thread类中,调用正常的start方法去起线程,返回值从task.get()中去取。稍微翻下源码就知道,FutureTask实现了RunnableFuture这个接口,而RunnableFuture又继承了Runnable, Future。也就是说它自己本身既有run方法能运行,又能将结果装在Future中,所以这个FutureTask用起来也是方便了很多。
Java的线程状态一共有6种:
1、NEW:线程刚刚创建,还没有启动;
2、RUNNABLE:可运行状态,由线程调度器可以安排执行,包括READY和RUNNING;
3、WAITING: 等待被唤醒;
4、TIMED WAITING:隔一段时间后自动唤醒;
5、BLOCKED: 被阻塞,正在等待锁;
6、TERMINATED: 线程结束;

值得一提的是,在线程等待锁的过程中,除了synchronized是处于BLOCKED的状态外,其它的都是WAITING状态,这两种状态其实比较容易混。老规矩,用一段代码看下线程相关的状态:
package com.feenix.juc.c_000_threadbasic;
import com.feenix.util.SleepHelper;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.LockSupport;
import java.util.concurrent.locks.ReentrantLock;
public class T04_ThreadState {
public static void main(String[] args) throws Exception {
//===================================================
Thread t1 = new Thread(() -> {
System.out.println("2: " + Thread.currentThread().getState());
for (int i = 0; i < 3; i++) {
SleepHelper.sleepSeconds(1);
System.out.print(i + " ");
}
System.out.println();
});
System.out.println("1: " + t1.getState());
t1.start();
t1.join();
System.out.println("3: " + t1.getState());
//===================================================
Thread t2 = new Thread(() -> {
try {
LockSupport.park();
System.out.println("t2 go on!");
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
t2.start();
TimeUnit.SECONDS.sleep(1);
System.out.println("4: " + t2.getState());
LockSupport.unpark(t2);
TimeUnit.SECONDS.sleep(1);
System.out.println("5: " + t2.getState());
//===================================================
final Object o = new Object();
Thread t3 = new Thread(() -> {
synchronized (o) {
System.out.println("t3 得到了锁 o");
}
});
new Thread(() -> {
synchronized (o) {
SleepHelper.sleepSeconds(5);
}
}).start();
SleepHelper.sleepSeconds(1);
t3.start();
SleepHelper.sleepSeconds(1);
System.out.println("6: " + t3.getState());
//===================================================
final Lock lock = new ReentrantLock();
Thread t4 = new Thread(() -> {
lock.lock(); //省略try finally
System.out.println("t4 得到了锁 o");
lock.unlock();
});
new Thread(() -> {
lock.lock();
SleepHelper.sleepSeconds(5);
lock.unlock();
}).start();
SleepHelper.sleepSeconds(1);
t4.start();
SleepHelper.sleepSeconds(1);
System.out.println("7: " + t4.getState());
//===================================================
Thread t5 = new Thread(() -> {
LockSupport.park();
});
t5.start();
SleepHelper.sleepSeconds(1);
System.out.println("8: " + t5.getState());
LockSupport.unpark(t5);
}
}
// --------------------------------------------------------------------------------------
package com.feenix.util;
import java.util.concurrent.TimeUnit;
public class SleepHelper {
public static void sleepSeconds(int seconds) {
try {
TimeUnit.SECONDS.sleep(seconds);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void sleepMilli(int i) {
try {
TimeUnit.MILLISECONDS.sleep(i);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
线程状态在Lock 和Synchronized两种状态下,代码中的Lock使用的是ReentrantLock,也就是JUC的锁,JUC的锁使用的是CAS来实现,说白了线程处于忙等待,是不会进入BLOCKED状态,而是处于WAITING状态,这也是为什么只有Synchronized加锁才会进入BLOCKED状态。
线程中断
和线程中断相关的方法不多,只有3个:
1、interrupt() :实例方法,设置线程中断标识位,相当于申请一下打断。至于到底要不要处理,怎么处理,这个由线程自己安排;
2、isInterrupted():实例方法,查询线程的中断标识位;
3、interrupted():静态方法,查询线程是否被中断过,并重置中断标识;
package com.feenix.juc.c_000_threadbasic;
import com.feenix.util.SleepHelper;
/**
* interrupt()与isInterrupted()
* 设置标志位 + 查询标志位
*/
public class T05_Interrupt_and_isInterrupted {
public static void main(String[] args) {
Thread t = new Thread(() -> {
for (; ; ) {
if (Thread.currentThread().isInterrupted()) {
System.out.println("Thread is interrupted!");
System.out.println(Thread.currentThread().isInterrupted());
break;
}
}
});
t.start();
SleepHelper.sleepSeconds(2);
t.interrupt();
}
}
用一个死循环去判断线程中是否有设置过中断标识位,如果有设置过中断标识,可以通过break将线程结束掉,这是一种比较优雅的让线程结束的方案。
思考一个问题:设中断标识位会不会将线程正在争抢锁的状态打断,会不会抛出异常?
package com.feenix.juc.c_000_threadbasic;
import com.feenix.util.SleepHelper;
/**
* interrupt与sleep() wait() join()
*/
public class T09_Interrupt_and_sync {
private static Object o = new Object();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
synchronized (o) {
SleepHelper.sleepSeconds(10);
}
});
t1.start();
SleepHelper.sleepSeconds(1);
Thread t2 = new Thread(() -> {
synchronized (o) {
}
System.out.println("t2 end!");
});
t2.start();
SleepHelper.sleepSeconds(1);
t2.interrupt();
}
}
t1启动之后先把锁拿到,然后去睡觉。注意,sleepSeconds这个方法是不会释放锁的,所以在10s内这把锁归t1所有。当t2去抢这把锁的时候,只能等待t1将锁释放之后才能抢到。此时调用t2.interrupt()这个方法,能不能将t2竞争锁的这个过程打断呢?很显然并不会,正在争抢锁的这个过程是不会被interrupt所干扰。
ReentrantLock的lock会被interrupt所干扰吗?
package com.feenix.juc.c_000_threadbasic;
import com.feenix.util.SleepHelper;
import java.util.concurrent.locks.ReentrantLock;
/**
* interrupt与sleep() wait() join()
*/
public class T10_Interrupt_and_lock {
private static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
lock.lock();
try {
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
System.out.println("t1 end!");
});
t1.start();
SleepHelper.sleepSeconds(1);
Thread t2 = new Thread(() -> {
lock.lock();
try {
} finally {
lock.unlock();
}
System.out.println("t2 end!");
});
t2.start();
SleepHelper.sleepSeconds(1);
t2.interrupt();
}
}
通过上面的代码可以发现,即使是通过ReentrantLock的lock方法来竞争锁,interrupt依然不能干扰争抢锁的这个过程。
那如果想要使用interrupt来中断正在竞争锁的线程,该怎么办呢?ReentrantLock其实有考虑到这点,提供了lockInterruptibly方法
package com.feenix.juc.c_000_threadbasic;
import com.feenix.util.SleepHelper;
import java.util.concurrent.locks.ReentrantLock;
/**
* interrupt与lockInterruptibly()
*/
public class T11_Interrupt_and_lockInterruptibly {
private static ReentrantLock lock = new ReentrantLock();
public static void main(String[] args) {
Thread t1 = new Thread(() -> {
lock.lock();
try {
SleepHelper.sleepSeconds(10);
} finally {
lock.unlock();
}
System.out.println("t1 end!");
});
t1.start();
SleepHelper.sleepSeconds(1);
Thread t2 = new Thread(() -> {
System.out.println("t2 start!");
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
System.out.println("t2 end!");
});
t2.start();
SleepHelper.sleepSeconds(1);
t2.interrupt();
}
}
这次t2在争抢锁的时候,使用的是lockInterruptibly方法,这方法听名字就知道是可被中断的,当被设置中断标识位之后,会抛出InterruptedException异常,抓住这个异常后具体要怎么处理,决定权还是交回到程序员自己手里。
线程结束
想要结束一个线程其实也没那么简单,最优雅的结束现成的方法就是让线程运行完自动结束。不过很多时候需要强制结束一个线程,就必须得调用结束线程相关的一些方法。
stop
package com.feenix.juc.c_001_00_thread_end;
import com.feenix.util.SleepHelper;
public class T01_Stop {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while (true) {
System.out.println("go on");
SleepHelper.sleepSeconds(1);
}
});
t.start();
SleepHelper.sleepSeconds(5);
t.stop();
}
}
听名字就非常的简单粗暴,什么都不管直接停掉,简单粗暴有效。不过也正是过于简单粗暴,这个方法现在已经被废弃掉,它可不管现在线程处于什么状态,不管线程有哪些数据交互,反正就直接把线程干掉。假设现在这个线程持有锁,stop方法会释放掉所有的锁,并不会做任何善后的工作,非常容易产生数据不一致的问题。
suspend / resume
package com.feenix.juc.c_001_00_thread_end;
import com.feenix.util.SleepHelper;
public class T02_Suspend_Resume {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while (true) {
System.out.println("go on");
SleepHelper.sleepSeconds(1);
}
});
t.start();
SleepHelper.sleepSeconds(5);
t.suspend();
SleepHelper.sleepSeconds(3);
t.resume();
}
}
suspend是线程暂停,resume是线程恢复,这俩方法和stop一样也是被废弃掉的方法。这两个方法看起来好像很好用的样子,让它暂停就暂停,让它继续就继续。但是本身存在的问题和stop差不多,在suspend暂停的时候如果本身持有锁,这锁是不会释放的,如果程序员忘记恢复线程的话,那这把锁可就永远不会被释放了,极易导致死锁问题。
volatile 设置标识位
package com.feenix.juc.c_001_00_thread_end;
import com.feenix.util.SleepHelper;
public class T03_VolatileFlag {
private static volatile boolean running = true;
public static void main(String[] args) {
Thread t = new Thread(() -> {
long i = 0L;
while (running) {
// wait recv accept
i++;
}
System.out.println("end and i = " + i);
});
t.start();
SleepHelper.sleepSeconds(1);
running = false;
}
}
interrupt 设置中断标识位
package com.feenix.juc.c_001_00_thread_end;
import com.feenix.util.SleepHelper;
/**
* interrupt是设定标志位
*/
public class T04_Interrupt_and_NormalThread {
public static void main(String[] args) {
Thread t = new Thread(() -> {
while (!Thread.interrupted()) {
//sleep wait
}
System.out.println("t1 end!");
});
t.start();
SleepHelper.sleepSeconds(1);
t.interrupt();
}
}
这应该是众多的方法中比较优雅的结束线程的做法了,这种方式和volatile类似,也是设定标识位。但是使用interrupt的时候,只需要在sleep、wait里面处理对应的InterruptedException,照样可以通过中间状态来结束这个线程。但是缺点也是一样,很难做到精确的控制。
3、并发编程的三大特性
可见性(visibility)
先来看一段程序运行的效果
/**
* volatile 关键字,使一个变量在多个线程间可见
* A B线程都用到一个变量,java默认是A线程中保留一份copy,这样如果B线程修改了该变量,则A线程未必知道
* 使用volatile关键字,会让所有线程都会读到变量的修改值
* <p>
* 在下面的代码中,running是存在于堆内存的t对象中
* 当线程t1开始运行的时候,会把running值从内存中读到t1线程的工作区,在运行过程中直接使用这个copy,并不会每次都去
* 读取堆内存,这样,当主线程修改running的值之后,t1线程感知不到,所以不会停止运行
* <p>
* 使用volatile,将会强制所有线程都去堆内存中读取running的值
* volatile并不能保证多个线程共同修改running变量时所带来的不一致问题,也就是说volatile不能替代synchronized
*/
package com.feenix.juc.c_001_01_Visibility;
import com.feenix.util.SleepHelper;
import java.io.IOException;
public class T01_HelloVolatile {
private static /*volatile*/ boolean running = true;
private static void m() {
System.out.println("m start");
while (running) {
// System.out.println("hello");
}
System.out.println("m end!");
}
public static void main(String[] args) throws IOException {
new Thread(T01_HelloVolatile::m, "t1").start();
SleepHelper.sleepSeconds(1);
running = false;
System.in.read();
}
}
通过对running这个变量值的改变,从而控制t1线程的输出。程序中的两个线程都会用到running这个变量值,t1线程会一直读取running的值,但实际上t1读取的是拷贝值。t1在需要使用running的时候,先将running的值读取到线程本地的缓存中,然后在每次while (running)判断的时候,都是从线程缓存中取值,而不是再去主内存中取值。
所以,当main线程执行running = false,其实改的也是自己线程中的缓存值。对于t1线程来说,你main线程改你的呗,关我t1什么事。t1中的缓存值一直不会去变,所以t1中的循环永远结束不了。
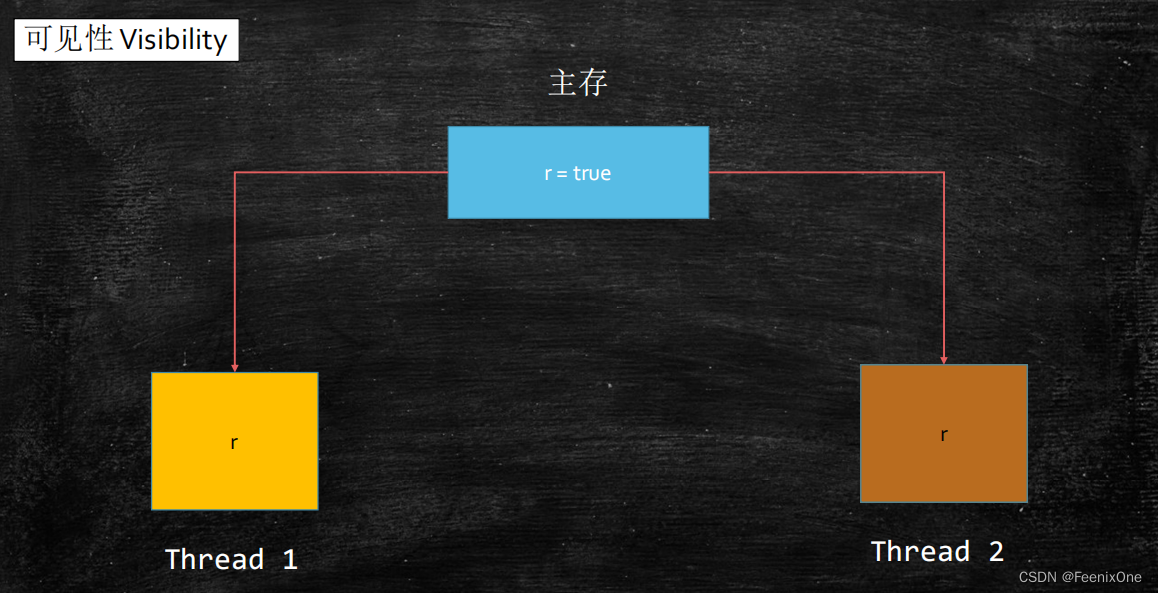
这就是线程的可见性,默认的情况下,一个线程修改了本地缓存值之后,其它的线程是看不见的。如果想要其它的线程看见, 只需将running变量用volatile来修饰即可。被volatile所修饰的变量,每次读取的值不是从线程本地去拿,而是去主内存中读取。main线程修改了running的值之后,立马刷新到主内存,t1读取running值也是从主内存中去拿,这样running值的变化立马可见。
保持线程的可见性是volatile的两大核心功能之一,另一个是禁止指令重排序。这个就是接下来并发编程的第二大特性有序性的核心内容。好,我们继续在深扒一下这个线程的可见性问题,如果想要线程间保持可见的话,除了volatile还有别的方法吗?看上面的程序,在while (running)循环中放开System.out.println("hello")的注释,会发现,当执行System.out.println("hello")一直在打印的过程中,即使running不使用volatile来修饰,while循环也是运行一会就结束了,这是为什么?
因为System.out.println("hello")触发了线程间的可见性机制。点进去源码中的实现,会发现方法中加了synchronized修饰
/**
* Prints a String and then terminate the line. This method behaves as
* though it invokes <code>{@link #print(String)}</code> and then
* <code>{@link #println()}</code>.
*
* @param x The <code>String</code> to be printed.
*/
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}可以简单的理解为,synchronized可以触发本地的缓存和主内存中数据进行刷新和同步。但是System.out.println这个方法也不要滥用,毕竟是有加锁的步骤,效率上的差别可不是一丁半点。如果是为了保证线程间的可见性,该用volatile还是要用volatile。
但是需要注意的是:volatile 引用类型(包括数组)只能保证引用本身的可见性,不能保证内部字段的可见性。
/**
* volatile 引用类型(包括数组)只能保证引用本身的可见性,不能保证内部字段的可见性
*/
package com.feenix.juc.c_001_01_Visibility;
import com.feenix.util.SleepHelper;
public class T02_VolatileReference {
private static class A {
boolean running = true;
void m() {
System.out.println("m start");
while (running) {}
System.out.println("m end!");
}
}
private volatile static A a = new A();
public static void main(String[] args) {
new Thread(a::m, "t1").start();
SleepHelper.sleepSeconds(1);
a.running = false;
}
}
通过上面的这小段代码运行,可以看到,即使A对象被volatile修饰,但是修改的是A对象内部的running,所以还是不可见。如果想要保证running可见的话,直接给running加上volatile修饰。
有序性(ordering)
在大致上明白了什么是并发编程的可见性之后,下一步来探讨另外一个特性:有序性。有没有想过,程序真的是按照“顺序”来执行的吗?来看这么一小段程序
package com.feenix.juc.c_001_03_Ordering;
import java.util.concurrent.CountDownLatch;
public class T01_Disorder {
private static int x = 0, y = 0;
private static int a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
for (long i = 0; i < Long.MAX_VALUE; i++) {
x = 0;
y = 0;
a = 0;
b = 0;
CountDownLatch latch = new CountDownLatch(2);
Thread one = new Thread(new Runnable() {
public void run() {
a = 1;
x = b;
latch.countDown();
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
latch.countDown();
}
});
one.start();
other.start();
latch.await();
String result = "第" + i + "次 (" + x + "," + y + ")";
if (x == 0 && y == 0) {
System.err.println(result);
break;
}
}
}
}在一个接近于死循环的循环中起两个线程,第一个线程将a = 1,x = b;第二个线程将b = 1,y = a。线程在执行的过程中是不可预知的,所以很有可能是先执行a = 1,b = 1,再执行x = b,y = a。所以两个线程中的四条执行语句,每次在循环里,理论上执行顺序应该是存在不同的排列组合,直到x == 0 && y == 0的时候,才会结束循环。

如果说不打断顺序的话,绝对不会出现x == 0 && y == 0的情况,当然这种情况非常少见,乱序的出现会有一定的概率可能会发生

为什么会出现乱序的问题呢?一句话概括,就是为了提高CPU的执行效率,压榨CPU性能。
前面说过每句代码的底层是由多条不同的指令组成,这些指令依次被读取到CPU中去执行,如果一定按照指令的顺序去执行这些指令的话,不是每一条指令都需要充分的利用CPU的计算性能,第一条指令执行完了,可能就要CPU一直等待着IO数据传输,然后再去执行下一条指令。
为了避免CPU有偷懒的时候,就会优先把下一条指令优先执行,说到底这是CPU为了提高执行效率所采取的优化机制。
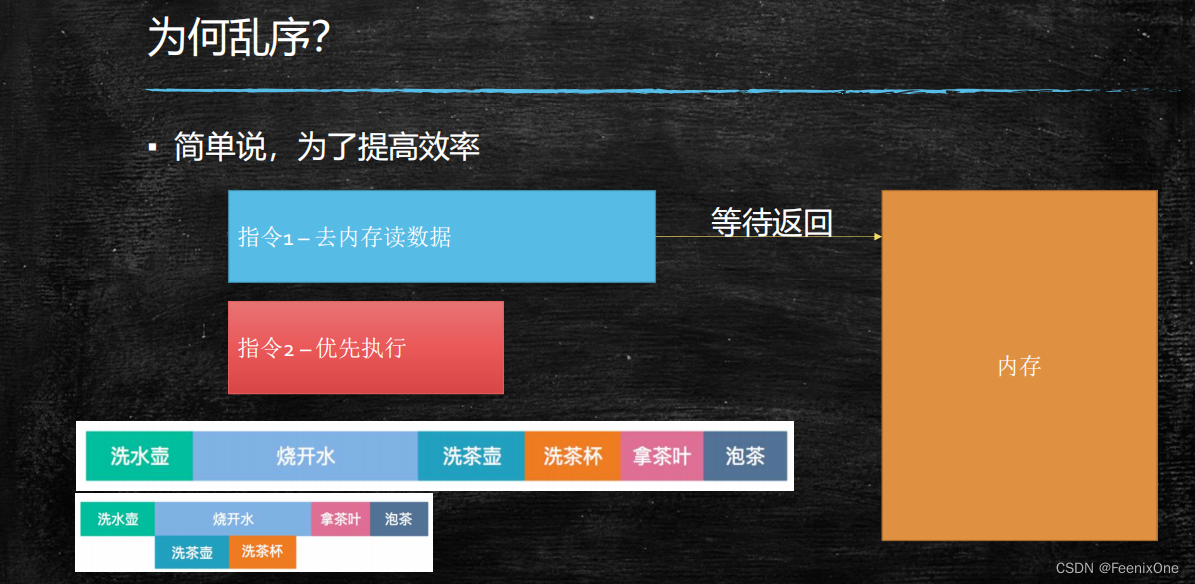
当然,乱序也不是随随便便哪两条指令都会发生的,前提必须是前后指令没有依赖关系,才会有可能会被换执行顺序,也就是所谓的不影响单线程的最终一致性(as-if-serial,好像是序列化串行执行的)。
在《Java并发编程实践》中,有这么一段经典的程序
package com.feenix.juc.c_001_03_Ordering;
public class T02_NoVisibility {
private static boolean ready = false;
private static int number;
private static class ReaderThread extends Thread {
@Override
public void run() {
while (!ready) {
Thread.yield();
}
System.out.println(number);
}
}
public static void main(String[] args) throws Exception {
Thread t = new ReaderThread();
t.start();
number = 42;
ready = true;
t.join();
}
}
这段小程序存在两大问题:
1、没有使用volatile修饰ready,保证线程间的可见性;
2、System.out.println(number),这句打印的结果有可能为0;因为number = 42和ready = true两句代码的执行间不存在依赖关系,所以这哥俩完全有可能发生乱序问题。但是要是自己做实验一直尝试的话,执行上千万次上亿次也不见得能见到一次;
this对象逸出问题
package com.feenix.juc.c_001_03_Ordering;
public class T03_ThisEscape {
private int num = 8;
public T03_ThisEscape() {
new Thread(() -> System.out.println(this.num)).start();
}
public static void main(String[] args) throws Exception {
new T03_ThisEscape();
System.in.read();
}
}
在上面的这段代码中,System.out.println(this.num)输出的结果,有可能不是8。因为private int num = 8;这句代码的汇编指令集有5句:
0 new #2 <T>
3 dup
4 invokespecial #3 <T.<init>>
7 astore_1
8 return
但是在执行到一半的时候,完全有可能4和7这两条指令会交换顺序,发生指令重排序的乱序问题。如果4和7发生了指令交换后,此时线程找到的m的值是初始化状态,也就是赋了默认值,还没有赋初始值的中间状态,此时输出的m的值就是默认值0,这就是this的逸出问题。
由于this逸出问题的存在,所以应该严令禁止在构造方法中起一个线程去执行任务,应该单独写一个方法来进行线程的启动,确保在构造方法完成之后再去执行线程中的任务。
禁止指令重排序规范
从JVM的角度来看,其实是对Java的汇编指令做了重排序的规范,这些规定一共有8条:
1、程序次序规则:同一个线程内,按照代码出现的顺序,前面的代码先行于后面的代码,准确的说是控制流顺序,因为要考虑到分支和循环结构;
2、管程锁定规则:一个unlock操作先行发生于后面(时间上)对同一个锁的lock操作;
3、volatile变量规则:对一个volatile变量的写操作先行发生于后面(时间上)对这个变量的读操作;
4、线程启动规则:Thread的start( )方法先行发生于这个线程的每一个操作;
5、线程终止规则:线程的所有操作都先行于此线程的终止检测。可以通过Thread.join( )方法结束、Thread.isAlive( )的返回值等手段检测线程的终止;
6、线程中断规则:对线程interrupt( )方法的调用先行发生于被中断线程的代码检测到中断事件的发生,可以通过Thread.interrupt( )方法检测线程是否中断;
7、对象终结规则:一个对象的初始化完成先行于发生它的finalize()方法的开始;
8、传递性:如果操作A先行于操作B,操作B先行于操作C,那么操作A先行于操作C;
在Oracle官网发布的Java语言规范中有详细的说明(我建议大家就不用真的去翻这东西了,不仅晦涩难懂,而且几乎是毫无实际编程用处.....),而且不管JVM是怎么规定的,Hotspot的实现简单粗暴一句指令直接搞定。
从更底层的CPU角度来说,不允许两条指令换顺序,就好比两个人排着队允许换位置一样,直接在这俩人中间加一个隔层就行了,这个隔层就是内存屏障(memory barrier,也称内存栅栏,这个称呼还真是形象)。内存屏障是特殊指令:看到这种指令,前面的必须执行完,后面的才能执行。每一种CPU对于内存屏障指令的实现都不一样,intel的CPU对于内存屏障有三条指令: lfence、 sfence和mfence。
但是JVM的实现并不是靠这个指令来实现,并不是针对不同的CPU使用不同CPU的特殊屏障指令。JVM作为一个规范,要求所有实现JVM规范的Java虚拟机,都应该实现自己的JVM级别的内存屏障。JVM要求任何的实现都必须具备这4条内存屏障:
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕;
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见;
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕;
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见;
这4条指令不存在实际的JVM汇编指令,JVM的规范只是要求实现这4种机制,至于具体用什么方式什么语言去实现不管,反正得实现了这样的机制就可以。
volatile是怎么实现禁止指令重排序
其实用volatile去修饰一个变量,从而保证指令的顺序行,这事儿吧听上去有点诡异。volatile毕竟只是修饰了一个变量,这个本身跟顺序好像没什么关系,所谓的volatile修饰产生的效果是

相当于用我volatile的时候,就必须自带对应的屏障,而正是带上的这个屏障从而保证顺序性。
Hotspot对于volatile的实现
感兴趣的话可以去翻一翻Hotspot的源码,有点麻烦的是Hotspot的源码要在Linux系统下编译,win环境下会出现各种各样的问题。
在bytecodeinterpreter.cpp这个文件中有这么一段代码:
int field_offset = cache->f2_as_index();
if (cache->is_volatile()) {
if (support_IRIW_for_not_multiple_copy_atomic_cpu) {
OrderAccess::fence();
}
.....
}也就是说,当判断有volatile修饰之后,调用了OrderAccess::fence()这个方法,具体实现为
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}首先,os::is_MP()这句的意思是判断CPU是不是多核,是多核就会调用 lock; addl 这倆汇编指令,AMD的还会$0,0(%%rsp),就是对rsp寄存器加了个0,其它的是对esp加个0。这句核心的地方是lock这个指令,lock指令用于在多处理器中执行指令时对共享内存的独占使用。它的作用是能够将当前处理器对应缓存的内容刷新到内存,并使其他处理器对应的缓存失效。另外还提供了有序的指令无法越过这个内存屏障的作用。
lock指定比较特殊,后面必须要跟一条指令,指的是当执行后面这条指令的时候,对总线或者缓存进行锁定。后面这条指令还不能是空指令,所以它就给某个寄存器加个0,相当于空操作,有点投机取巧的味道。
原子性(atomicity)
相较于可见性和有序性,原子性相对来说要复杂不少。老规矩,通过一小段代码来看结果:
package com.feenix.juc.c_001_sync_basics;
import java.util.concurrent.CountDownLatch;
public class T00_00_IPlusPlus {
private static long n = 0L;
public static void main(String[] args) throws Exception {
// Lock lock = new ReentrantLock();
Thread[] threads = new Thread[100];
CountDownLatch latch = new CountDownLatch(threads.length);
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
for (int j = 0; j < 10000; j++) {
// synchronized (T00_00_IPlusPlus.class) {
// lock.lock();
n++;
// lock.unlock();
// }
}
latch.countDown();
});
}
for (Thread t : threads) {
t.start();
}
latch.await();
System.out.println(n);
}
}
理论上最后的这个结果预期应该是一百万,可实际上只有三万多,原因就是:多线程访问同一个数据,会产生线程间的竞争,这就是经常说的竞争条件(race condition)。导致的结果就是并发访问之下产生的不期望出现的结果,也就是数据的不一致(unconsistency)。为什么会产生这样的情况,这就涉及到原子性这个东西了。
在执行n++这一句的时候,是要将内存的值读到CPU的寄存器中,加完了之后再写回内存。可还没有写回去之前,就有另一个线程读到了原值,将原值拿来再加一次。也就是,一个线程正在执行的操作,被另一个线程给打断了。 所以理论上,只要保证线程在操作的时候不被别的线程锁打断,那么就可以得到预期的正确的结果。而不被打断的这个操作,称之为原子操作。
原子性语句
那么另一个问题又来了,我怎么知道哪些语句的操作是原子性的,哪些不是?我们都知道,Java也好,C++也好,这些高级语言最终都变成机器语言让CPU去执行。机器语言翻译成人能看得懂得汇编语言,是不是汇编语言中的指令就一定是原子性的呢?也不是,即使是汇编语言,它执行的时候也是会被其它汇编所打断,所以对于CPU级别汇编,需要查询CPU的汇编手册。
对于Java来说,在JVM规范中规定了八大原子操作:
1、lock:主内存,标识变量为线程独占;
2、unlock:主内存,解锁线程独占变量;
3、read:主内存,读取内存到线程缓存(工作内存);
4、load:工作内存,read后的值放入线程本地变量副本;
5、use:工作内存,传值给执行引擎;
6、assign:工作内存,执行引擎结果赋值给线程本地变量;
7、store:工作内存,存值到主内存给write备用;
8、write:主内存,写变量值;
而回到上面说的问题,n++执行的时候,Java代码就这么一句,但是翻译成JVM指令却不少
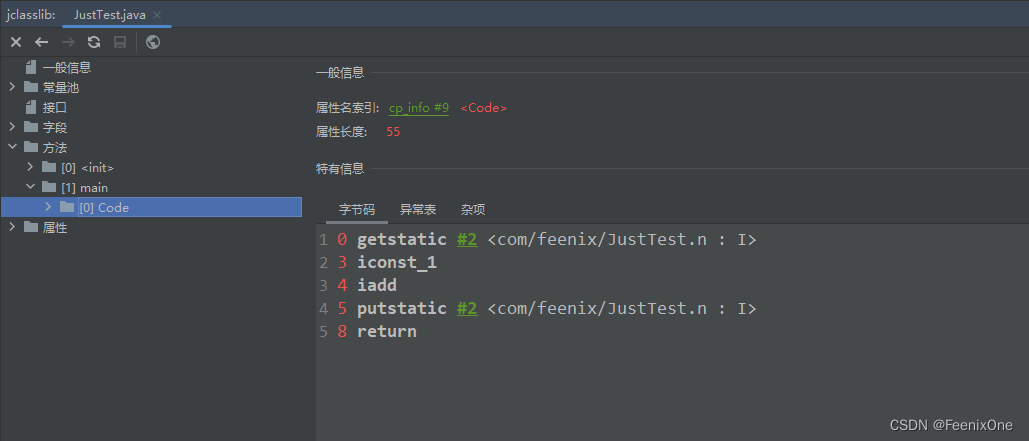
这些指定的操作过程中,完全有可能被其它线程所打断。但是这些只是JVM级别的指令,再往底层翻译成CPU级别的指令, 就会产生更多更细腻的指令,有可能这5条翻译完之后,直接成15条,那就更可能被别的线程打断了。所以,在不能确定那些操作是原子性,又需要对数据进行同步的时候,那么就需要有一种机制来保障这个操作是原子性的。
锁机制
为了保证原子性的操作,就需要对数据同步的区域加锁。加了锁之后,对于加锁区域中的操作就是一个整体不可打断。所谓的上锁,本质是什么呢?上锁的本质是把并发编程序列化,同时保障可见性。注意序列化并非其它程序一直没机会执行,而是有可能会被调度,但是抢不到锁,又回到BLOCKED或者WAITING状态(会导致synchronized锁升级)。
package com.feenix.juc.c_001_sync_basics;
import com.feenix.util.SleepHelper;
public class T00_02_SingleLockVSMultiLock {
private static Object o1 = new Object();
private static Object o2 = new Object();
private static Object o3 = new Object();
public static void main(String[] args) {
Runnable r1 = () -> {
synchronized (o1) {
System.out.println(Thread.currentThread().getName() + " start!");
SleepHelper.sleepSeconds(2);
System.out.println(Thread.currentThread().getName() + " end!");
}
};
Runnable r2 = () -> {
synchronized (o2) {
System.out.println(Thread.currentThread().getName() + " start!");
SleepHelper.sleepSeconds(2);
System.out.println(Thread.currentThread().getName() + " end!");
}
};
Runnable r3 = () -> {
synchronized (o3) {
System.out.println(Thread.currentThread().getName() + " start!");
SleepHelper.sleepSeconds(2);
System.out.println(Thread.currentThread().getName() + " end!");
}
};
new Thread(r1).start();
new Thread(r2).start();
new Thread(r3).start();
}
}
通过上锁来保证线程间的数据一致性,得上同一把锁,不然就是各玩各的,谁也好不了,一定是确保锁定同一把锁。
在细说锁的细节前,先了解几个基本的概念:
1、管程(monitor):管程指的就是那把锁,就是synchronized (T00_00_IPlusPlus.class) {.....}中的T00_00_IPlusPlus.class,操作系统叫它管程;
2、临界区(critical section):当持有锁的时候,所执行的这些代码。就是synchronized (T00_00_IPlusPlus.class) {.....}中的{.....}这些代码。如果临界区中的代码比较长,一般称为锁的粒度比较粗,反之,就是锁的粒度比较细。
平时很多时候,都会说:我锁定了一段代码。其实这个说法是有问题的,应该说:我锁定了一个对象,只有持有这把锁的时候,才能执行临界区中的这些代码。
3、悲观锁:悲观的认为这个操作会被别的线程打断。所以在执行代码前,一定要先加上一把锁;
4、乐观锁:乐观的认为这个操作不被别的线程打断,也叫自旋锁,本质上是CAS操作。有人叫它无锁,所以就诞生了一个很傻*的问题,无锁到底是不是一把锁.....神经病.....

通过Atomic类深入了解CAS操作
/**
* 解决同样的问题的更高效的方法,使用AtomXXX类
* AtomXXX类本身方法都是原子性的,但不能保证多个方法连续调用是原子性的
*/
package com.feenix.juc.c_018_00_AtomicXXX;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.atomic.AtomicInteger;
public class T01_AtomicInteger {
/*volatile*/ // int count1 = 0;
AtomicInteger count = new AtomicInteger(0);
/*synchronized*/ void m() {
for (int i = 0; i < 10000; i++)
// if count1.get() < 1000
count.incrementAndGet(); //count1++
}
public static void main(String[] args) {
T01_AtomicInteger t = new T01_AtomicInteger();
List<Thread> threads = new ArrayList<Thread>();
for (int i = 0; i < 100; i++) {
threads.add(new Thread(t::m, "thread-" + i));
}
threads.forEach((o) -> o.start());
threads.forEach((o) -> {
try {
o.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(t.count);
}
}
在这段代码中虽然多线程间没有使用synchronized加锁,每次在执行incrementAndGet()方法的时候,使用的就是CAS操作,具体的实现原来,看源码:
/**
* Atomically increments by one the current value.
*
* @return the updated value
*/
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}这个方法内部调用了Unsafe类的getAndAddInt方法,再进入这个方法内部:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}终于能看到调用了一个compareAndSwapInt方法,这个方法已经无法在深入查看实现,因为这个方法使用了native进行修饰,说明这是C++代码。虽然看不了具体的实现,但是刚刚从头过来,这些方法中确实没有使用synchronized进行加锁,也证明没有采用悲观锁策略。
通过Hotspot深入了解CAS操作
在Hotspot源码中找到 unsafe.cpp 这个文件,这个就是C++中的Unsafe这个类:
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe, jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END可以看到,一顿操作之后,在最后调用了 Atomic::cmpxchg(x, addr, e) 方法:
inline jint Atomic::cmpxchg(jint exchange_value, volatile jint* dest, jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}int mp = os::is_MP(); 这一句是判断是否是多核处理器(MP = multi processors)
LOCK_IF_MP 如果是多核处理器,上把锁 lock 住,后面接着 cmpxchgl ,这个是CPU在底层的原语,最终实现就是 lock cmpxchg 指令。上面说了想要知道一条指令是不是原子的,得去查询CPU的指令手册,不过很不幸的是,这条指令并不是原子操作,所以才需要加上 lock。这个lock从硬件层面来说,就是指令在执行的时候视情况采用缓存行锁或者总线锁。
所以从宏观上来说,代码角度,指令角度来说都是乐观锁,但是到CPU指令这个级别,最最底层的时候,还是得用上缓存行锁或者总线锁。总而言之,言而总之,在底层的微观角度还是逃不脱一把锁!
锁的效率
其实乐观锁的效率不一定比悲观锁快。悲观锁的线程每次在争抢锁的时候,系统会维护一个队列,当锁被一个线程所持有的时候,其余来争抢这把锁的线程都会进入这个队列。当线程在队列中的时候,其实是不会消耗系统资源的。而乐观锁采用的是自旋的操作,每次这些争抢锁的线程都过来转一圈,到我了没有啊,到我了没有啊,这个自旋的操作可是会消耗系统的资源。CPU既要消耗资源来运行这些线程的自旋循环,还要消耗资源进行这些线程间的切换。所以,其实乐观锁说起来是没有加一把实体的大锁,但是对系统资源的消耗其实比悲观锁还要严重。
所以,对于悲观锁和乐观锁的选择就需要根据不同的场景视具体情况而定:
1、当临界区中的代码比较长,锁的粒度比较粗,争抢锁的线程比较多,适合使用悲观锁;
2、当临界区中的代码比较短,锁的粒度比较细,争抢锁的线程比较少,适合使用乐观锁;
简单粗暴来说的话,直接无脑上 synchronized 就好。synchronized现在做了一系列的优化,内部的实现既有自旋锁,又有偏向锁,又有重量级锁,自己会根据不同的情况进行锁升级,效率上已经做的非常可以了。
锁升级概念
在JDK的早期版本,synchronized的实现是重量级的,二话不说先找OS申请一把锁给锁上,导致代码执行的效率非常低。后面经过优化,引入了锁升级的概念:
1、当第一个线程过来的时候,将这个线程的id记录在管程(synchronized锁住的对象)的对象头中,这叫做偏向锁。意思就是你是第一个来访问我的线程,我就把你记下来。等下来再来一个线程的时候,对比线程id,是同一个线程的话直接执行就完事儿了;
2、当来了很多线程争抢锁的时候,系统会将这些线程进行一个while循环,不断的来看下被持有的那把锁释放了没有,释放了没有.....这叫做自旋锁。默认的情况下自旋10次后,会升级成真正的重量级锁;
3、所谓的重量级锁就是去和OS申请真正的锁,进行锁定;
当 synchronized 进过这么多版本的优化之后,尤其是引入了锁升级的原理之后,大多数的情况下synchronized 并不比 Atomic 类的操作更慢。
4、JUC工具类
JUC是java.util.concurrent包的简称,在Java5.0添加,目的就是为了更好的支持高并发任务,让开发者进行多线程编程时减少竞争条件和死锁的问题。在此包中增加了在并发编程中很常用的工具类,用于定义类似于线程的自定义子系统,包括线程池,异步 IO 和轻量任务框架,还提供了设计用于多线程上下文中的 Collection 实现等。
LongAdder
package com.feenix.juc.c_018_00_AtomicXXX;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
import java.util.concurrent.atomic.LongAdder;
public class T02_AtomicVsSyncVsLongAdder {
private static final int THREAD_COUNT = 50;
private static final int LOOPS_COUNT = 100_0000;
static long count2 = 0L;
static AtomicLong count1 = new AtomicLong(0L);
static LongAdder count3 = new LongAdder();
public static void main(String[] args) throws Exception {
Thread[] threads = new Thread[THREAD_COUNT];
for (int i = 0; i < threads.length; i++) {
threads[i] =
new Thread(() -> {
for (int k = 0; k < LOOPS_COUNT; k++) count1.incrementAndGet();
});
}
long start = System.currentTimeMillis();
for (Thread t : threads) t.start();
for (Thread t : threads) t.join();
long end = System.currentTimeMillis();
// TimeUnit.SECONDS.sleep(10);
System.out.println("Atomic: " + count1.get() + " time " + (end - start));
//-----------------------------------------------------------
Object lock = new Object();
for (int i = 0; i < threads.length; i++) {
threads[i] =
new Thread(new Runnable() {
@Override
public void run() {
for (int k = 0; k < LOOPS_COUNT; k++)
synchronized (lock) {
count2++;
}
}
});
}
start = System.currentTimeMillis();
for (Thread t : threads) t.start();
for (Thread t : threads) t.join();
end = System.currentTimeMillis();
System.out.println("Sync: " + count2 + " time " + (end - start));
//----------------------------------
for (int i = 0; i < threads.length; i++) {
threads[i] =
new Thread(() -> {
for (int k = 0; k < LOOPS_COUNT; k++) count3.increment();
});
}
start = System.currentTimeMillis();
for (Thread t : threads) t.start();
for (Thread t : threads) t.join();
end = System.currentTimeMillis();
// TimeUnit.SECONDS.sleep(10);
System.out.println("LongAdder: " + count1.longValue() + " time " + (end - start));
}
static void microSleep(int m) {
try {
TimeUnit.MICROSECONDS.sleep(m);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
当所有的线程都去访问同一个数的时候,不加锁会出问题。但是如果使用 Atomic 相关类的时候,就不需要再通过加锁来保证数据的正确性。除此之外,还有一个用于多线程间数据累积的操作类 LongAdder。
在上面的程序中,通过三种不同的方式实现出来的效率分别为
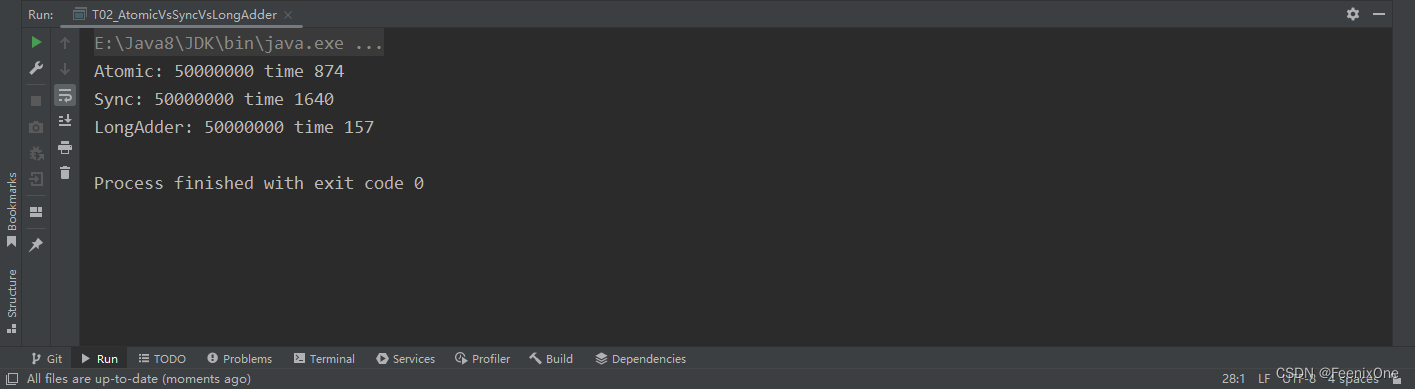
很明显可以看出,相比较于 synchronized 和 atomic,LongAdder简直是降维打击。 但是如果将循环的次数和线程的数量减少再来试验,那么LongAdder未必会有优势。LongAdder的内部做了一个类似于分段锁的概念:在它内部的时候,会把一个值放到一个数组里,比如说数组长度是4,最开始是0,1000个线程,0~250个线程锁在第一个数组元素里,251~500个线程锁在第二个数组元素里.....以此类推,每一个都往上递增算出来结果在加到一起。
ReentrantLock
ReentrantLock的字面意思是可重入锁,synchronized 本身就是可重入锁的一种,ReentrantLock设计的目的是用于替代 synchronized。什么叫可重入,意思就是我锁了一下之后,还可以对同样这把锁再锁一下,synchronized 必须是可重入的,不然的话子类调用父类是没法实现的。
package com.feenix.juc.c_020_juclocks;
import java.util.concurrent.TimeUnit;
public class T01_ReentrantLock1 {
synchronized void m1() {
for (int i = 0; i < 10; i++) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(i);
if (i == 2) m2();
}
}
synchronized void m2() {
System.out.println("m2 ...");
}
public static void main(String[] args) {
T01_ReentrantLock1 rl = new T01_ReentrantLock1();
new Thread(rl::m1).start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(rl::m2).start();
}
}
m1方法里面做了一个循环每次睡1秒钟,每隔一秒种打印一个。接下来调m2,是一个synchronized 方法,也是需要加锁的,我们来看主程序启动线程m1,一秒钟后再启动线程m2。分析下这个执行过程在第一个线程执行到一秒钟的时候第二个线程就会起来,假如我们这个锁是不可重入的会是什么情况,第一个线程申请这把锁,锁的这个对象,然后这里如果是第二个线程来进行申请的话,它start不了,必须要等到第一个线程结束了,因为这两个是不同的线程。两个线程之间肯定会有争用,可以在m1里面调用m2就可以,synchronized方法是可以调用synchronized方法的,说明锁是可重入的。
ReentrantLock是可以替代synchronized的,怎么替代呢,看如下代码
package com.feenix.juc.c_020_juclocks;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class T02_ReentrantLock2 {
Lock lock = new ReentrantLock();
void m1() {
try {
lock.lock(); //synchronized(this)
for (int i = 0; i < 10; i++) {
TimeUnit.SECONDS.sleep(1);
System.out.println(i);
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
void m2() {
try {
lock.lock();
System.out.println("m2 ...");
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
T02_ReentrantLock2 rl = new T02_ReentrantLock2();
new Thread(rl::m1).start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(rl::m2).start();
}
}
原来写 synchronized 的地方换写 lock.lock(),加完锁之后需要注意的是记得lock.unlock() 解锁。由于 synchronized 是自动解锁的,大括号执行完就结束了。lock就不行,lock必须得手动解锁,手动解锁一定要写在try...finally里面保证最好一定要解锁,不然的话上锁之后中间执行的过程有问题了,死在哪里别的线程就永远也拿不到这把锁了。
那么如果说 ReentrantLock 既然和 synchronized 差不多的话,那还要多此一举设计它有什么用。当然 ReentrantLock 有一些功能还是要比 synchronized 强大的,强大的地方在于可以使用 tryLock 进行尝试锁定,不管锁定与否,方法都将继续执行。synchronized 如果搞不定的话,它肯定就阻塞了,但是用 ReentrantLock 自己就可以决定你到底要不要wait。
package com.feenix.juc.c_020_juclocks;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class T03_ReentrantLock3 {
Lock lock = new ReentrantLock();
void m1() {
try {
lock.lock();
for (int i = 0; i < 10; i++) {
TimeUnit.SECONDS.sleep(1);
System.out.println(i);
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
void m2() {
/*
boolean locked = lock.tryLock();
System.out.println("m2 ..." + locked);
if(locked) lock.unlock();
*/
boolean locked = false;
try {
locked = lock.tryLock(5, TimeUnit.SECONDS);
System.out.println("m2 ..." + locked);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
if (locked) lock.unlock();
}
}
public static void main(String[] args) {
T03_ReentrantLock3 rl = new T03_ReentrantLock3();
new Thread(rl::m1).start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
new Thread(rl::m2).start();
}
}
上面这段程序,比如5秒钟内把程序执行完就可能得到这把锁,如果得不到就不行。由于第一个线程跑了10秒钟,所以你在第二个线程里申请5秒肯定是那不到的,把循环次数减少就可以能拿到了。
当然除了这个之外呢,ReentrantLock 还可以用 lock.lockInterruptibly() 这个方法,对 interrupt() 方法做出相应,可以被打断的加锁。
package com.feenix.juc.c_020_juclocks;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class T04_ReentrantLock4 {
public static void main(String[] args) {
Lock lock = new ReentrantLock();
Thread t1 = new Thread(() -> {
try {
lock.lock();
System.out.println("t1 start");
TimeUnit.SECONDS.sleep(Integer.MAX_VALUE);
System.out.println("t1 end");
} catch (InterruptedException e) {
System.out.println("interrupted!");
} finally {
lock.unlock();
}
});
t1.start();
Thread t2 = new Thread(() -> {
try {
//lock.lock();
lock.lockInterruptibly();
System.out.println("t2 start");
TimeUnit.SECONDS.sleep(5);
System.out.println("t2 end");
} catch (InterruptedException e) {
System.out.println("interrupted!");
} finally {
lock.unlock();
}
});
t2.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
t2.interrupt();
}
}
如果以这种方式加锁的话,可以调用一个 t2.interrupt(); 打断线程2的等待。 线程1 上来之后加锁,加锁之后开始没完没了的睡。被线程1拿到这把锁的话,线程2如果说在想拿到这把锁不太可能,拿不到锁它就会在那儿无休止的等着。如果使用原来的这种 lock.lock() 是打断不了它的,此时就可以用另外一种方式 lock.lockInterruptibly() 这个类可以被打断的,当要想停止线程2就可以用 interrupt() ,这也是 ReentrantLock 比 synchronized 好用的一个地方。
ReentrantLock还可以指定为公平锁,公平锁的意思是当 new 一个 ReentrantLock 的时候,可以传一个参数为true,这个true表示公平锁。
package com.feenix.juc.c_020_juclocks;
import java.util.concurrent.locks.ReentrantLock;
public class T05_ReentrantLock5 extends Thread {
private static ReentrantLock lock = new ReentrantLock(true);
public void run() {
for (int i = 0; i < 10; i++) {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + "获得锁");
} finally {
lock.unlock();
}
}
}
public static void main(String[] args) {
T05_ReentrantLock5 rl = new T05_ReentrantLock5();
Thread th1 = new Thread(rl);
Thread th2 = new Thread(rl);
th1.start();
th2.start();
}
}
值得注意的是,公平锁并不能100%完全保证当一个线程执行完了之后,必须是另外一个线程执行。想要实现这种方式,必须有线程间的通信才可以。这也是为什么上面的那段程序即使是指定了公平锁之后,仍然每次输出的结果都不一样的根本原因所在。
现在除了 synchronized 之外,多数内部都是用的都是CAS操作。聊这个AQS的时候实际上它内部用的是 park 和 unpark,也不是全都用的CAS操作。它还是做了一个锁升级的概念,只不过这个锁升级做的比较隐秘,在等待这个队列的时候如果拿不到的话,还是进入一个阻塞的状态,前面至少有一个CAS的状态,就不像原先就直接进入阻塞状态了。
CountDownLatch
CountDown 是倒数,Latch是门栓:倒数的一个门栓,5、4、3、2、1数到了,门栓就开了.....
package com.feenix.juc.c_020_juclocks;
import org.junit.jupiter.api.Test;
import java.util.concurrent.CountDownLatch;
public class T06_TestCountDownLatch {
public static void main(String[] args) {
usingJoin();
usingCountDownLatch();
}
private static void usingCountDownLatch() {
Thread[] threads = new Thread[100];
CountDownLatch latch = new CountDownLatch(threads.length);
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
int result = 0;
for (int j = 0; j < 10000; j++) result += j;
latch.countDown();
});
}
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("end latch");
}
private static void usingJoin() {
Thread[] threads = new Thread[100];
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(() -> {
int result = 0;
for (int j = 0; j < 10000; j++) result += j;
});
}
for (int i = 0; i < threads.length; i++) {
threads[i].start();
}
for (int i = 0; i < threads.length; i++) {
try {
threads[i].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("end join");
}
@Test
public void testCountDown() {
CountDownLatch latch = new CountDownLatch(3);
System.out.println(latch.getCount());
latch.countDown();
System.out.println(latch.getCount());
latch.countDown();
System.out.println(latch.getCount());
latch.countDown();
System.out.println(latch.getCount());
latch.countDown();
System.out.println(latch.getCount());
}
}
起了100个线程,接下来又来了个CountDownLatch,设定的总数量为100。意思就这是一个门栓,门栓上记了个数 threads.length 是 100。每一个线程结束的时候 latch.countDown(),然后所有线程 start(),再 latch.await(),最后结束。
那CountDown是干嘛使得呢?看 latch.await(),它的意思是说给我看住门,给我插住不要动。每个线程执行到 latch.await() 的时候这个门栓就在这里等着,并且记了个数是100。每一个线程结束的时候都会往下 CountDown,CountDown 是在原来的基础上减1,一直到这个数字变成0的时候门栓就会被打开,这就是它的概念,它是用来等着线程结束的。
当然用 join 也可以实现相同的功能,但是 CountDown 比它要灵活很多。用 join实际上不太好控制,必须要线程结束了才能控制。但是如果是一个门栓的话在线程里不停的 CountDown,在一个线程里就可以控制这个门栓什么时候往前走,用 join 只能是当前线程结束了才能自动往前走。
CyclicBarrier
CyclicBarrier意思是循环栅栏。这有一个栅栏,什么时候人满了就把栅栏推倒,哗啦哗啦的都放出去,出去之后扎栅栏又重新起来,再来人,满了,推倒之后又继续。
package com.feenix.juc.c_020_juclocks;
import java.util.concurrent.BrokenBarrierException;
import java.util.concurrent.CyclicBarrier;
public class T07_TestCyclicBarrier {
public static void main(String[] args) {
// CyclicBarrier barrier = new CyclicBarrier(20);
/*CyclicBarrier barrier = new CyclicBarrier(20, new Runnable() {
@Override
public void run() {
System.out.println("满人,发车");
}
});*/
CyclicBarrier barrier = new CyclicBarrier(20, () -> System.out.println("满人"));
for (int i = 0; i < 100; i++) {
new Thread(() -> {
try {
barrier.await();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (BrokenBarrierException e) {
e.printStackTrace();
}
}).start();
}
}
}
CyclicBarrier的概念比如说一个复杂的操作,需要访问数据库,或者需要访问网络,或者需要访问文件。有一种方式是顺序执行,挨个的都执行完,效率非常低,这是一种方式,还有一种可能性就是并发执行。原来是1、2、3顺序执行,并发执行是不同的线程去执行不同的操作,有的线程去数据库找,有的线程去网络访问,有的线程去读文件,必须是这三个线程全部到位了才能去进行,这个时候就可以用CyclicBarrier。
Phaser
Phaser它就更像是结合了 CountDownLatch 和 CyclicBarrier ,翻译一下叫阶段,这个稍微复杂一些。Phaser是按照不同的阶段来对线程进行执行,就是它本身是维护着一个阶段这样的一个成员变量,当前执行到那个阶段,是第0个,还是第1个阶段.....等等。每个阶段不同的时候这个线程都可以往前走,有的线程走到某个阶段就停了,有的线程一直会走到结束。程序中如果说用到分好几个阶段执行 ,而且有的必须得几个共同参与的一种情形的情况下可能会用到这个Phaser。
这个工具在日常的编码中极少用到,如果你有些过遗传算法,去解决这个问题的时候这个Phaser是有可能用的上。遗传算法是计算机来模拟达尔文的进化策略所发明的一种算法。我们自己模拟的一个小例子:模拟了一个结婚的场景,结婚是有好多人要参加的。因此,需要写一个类Person是一个Runnable可以new出来,扔给Thread去执行;模拟每个人要做一些操作,有这么几种方法:arrive() 到达、eat() 吃、leave() 离开、hug() 拥抱这么几个。作为一个婚礼来说它会分成好几个阶段,第一阶段大家好都得到齐了,第二个阶段大家开始吃饭, 三阶段大家离开,第四个阶段新郎新娘入洞房。每个人都有这几个方法,在方法的实现里头简单的睡个1s就当是业务处理了
package com.feenix.juc.c_020_juclocks;
import java.util.Random;
import java.util.concurrent.Phaser;
import java.util.concurrent.TimeUnit;
public class T09_TestPhaser2 {
static Random r = new Random();
static MarriagePhaser phaser = new MarriagePhaser();
static void milliSleep(int milli) {
try {
TimeUnit.MILLISECONDS.sleep(milli);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
phaser.bulkRegister(7);
for (int i = 0; i < 5; i++) {
new Thread(new Person("p" + i)).start();
}
new Thread(new Person("新郎")).start();
new Thread(new Person("新娘")).start();
}
static class MarriagePhaser extends Phaser {
@Override
protected boolean onAdvance(int phase, int registeredParties) {
switch (phase) {
case 0:
System.out.println("所有人都到齐了: " + registeredParties);
System.out.println();
return false;
case 1:
System.out.println("所有人都吃完了: " + registeredParties);
System.out.println();
return false;
case 2:
System.out.println("所有人都离开了: " + registeredParties);
System.out.println();
return false;
case 3:
System.out.println("婚礼结束,新郎新娘抱抱: " + registeredParties);
return true;
default:
return true;
}
}
}
static class Person implements Runnable {
String name;
public Person(String name) {
this.name = name;
}
public void arrive() {
milliSleep(r.nextInt(1000));
System.out.printf("%s 到达现场!\n", name);
phaser.arriveAndAwaitAdvance();
}
public void eat() {
milliSleep(r.nextInt(1000));
System.out.printf("%s 吃完!\n", name);
phaser.arriveAndAwaitAdvance();
}
public void leave() {
milliSleep(r.nextInt(1000));
System.out.printf("%s 离开!\n", name);
phaser.arriveAndAwaitAdvance();
}
private void hug() {
if (name.equals("新郎") || name.equals("新娘")) {
milliSleep(r.nextInt(1000));
System.out.printf("%s 洞房!\n", name);
phaser.arriveAndAwaitAdvance();
} else {
phaser.arriveAndDeregister();
// phaser.register()
}
}
@Override
public void run() {
arrive();
eat();
leave();
hug();
}
}
}宾客一共有五个人参加婚礼了,接下来新郎,新娘参加婚礼,一共七个人。它一 start 就好调用run() 方法,它会挨着牌的调用每一个阶段的方法。那好,在每一个阶段是不是得控制人数,第一个阶段得要人到期了才能开始,二阶段所有人都吃饭,三阶段所有人都离开,但是,到了第四阶段进入洞房的时候就不能所有人都干这个事儿了。所以,要模拟一个程序就要把整个过程分好几个阶段,而且每个阶段必须要等这些线程给干完事儿了才能进入下一个阶段。
ReadWriteLock
读写锁的概念其实就是共享锁和排他锁,读锁就是共享锁,写锁就是排他锁。那这个是什么意思,先要来理解这件事儿,读写有很多种情况,比如说数据库里的某条数据放在内存里读的时候特别多,而改的时候并不多。
举一个简单的栗子,公司的组织结构,想要显示这组织结构下有哪些人在网页上访问,所以这个组织结构被访问到会读,但是很少更改,读的时候多写的时候就并不多,这个时候好多线程来共同访问这个结构的话,有的是读线程有的是写线程,要求他不产生这种数据不一致的情况下我们采用最简单的方式就是加锁,我读的时候只能自己读,写的时候只能自己写,但是这种情况下效率会非常的底,尤其是读线程非常多的时候,那我们就可以做成这种锁,当读线程上来的时候加一把锁是允许其他读线程可以读,写线程来了我不给它,你先别写,等我读完你在写。读线程进来的时候我们大家一块读,因为你不改原来的内容,写线程上来把整个线程全锁定,你先不要读,等我写完你在读。
package com.feenix.juc.c_020_juclocks;
import com.feenix.util.SleepHelper;
import java.util.Random;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class T10_TestReadWriteLock {
static Lock lock = new ReentrantLock();
private static int value;
static ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
static Lock readLock = readWriteLock.readLock();
static Lock writeLock = readWriteLock.writeLock();
public static void read(Lock lock) {
lock.lock();
try {
SleepHelper.sleepSeconds(1);
System.out.println("read over!");
// 模拟读取操作
} finally {
lock.unlock();
}
}
public static void write(Lock lock, int v) {
lock.lock();
try {
SleepHelper.sleepSeconds(1);
value = v;
System.out.println("write over!");
// 模拟写操作
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
Runnable readR = () -> read(lock);
// Runnable readR = () -> read(readLock);
Runnable writeR = () -> write(lock, new Random().nextInt());
// Runnable writeR = () -> write(writeLock, new Random().nextInt());
for (int i = 0; i < 18; i++) new Thread(readR).start();
for (int i = 0; i < 2; i++) new Thread(writeR).start();
}
}
看程序中这个读写锁怎么用,有两个方法:read()读一个数据,write()写一个数据。read 这个数据的时候需要往里头传一把锁,这个传哪把锁自己定,我们可以传自己定义的全都是排他锁,也可以传读写锁里面的读锁或写锁。write的时候也需要往里面传把锁,同时需要传一个新值,在这里值里面传一个内容。模拟这个操作,读的是一个int类型的值,读的时候先上锁,设置一秒钟,完了之后read over,最后解锁unlock。再下面写锁,锁定后睡1000毫秒,然后把新值给value,write over后解锁,非常简单。
现在的问题是往里传这个 lock 有两种传法,第一种直接 new ReentrantLock() 传进去,分析下这种方法:主程序定义了一个 Runnable 对象,第一个是调用 read() 方法,第二个是调用 write() 方法同时往里头扔一个随机的值。然后起了18个读线程,起了两个写线程,这个两个要想执行完的话,我现在传的是一个 ReentrantLock,这把锁上了之后没有其他任何人可以拿到这把锁,而这里面每一个线程执行都需要1秒钟,在这种情况下必须得等20秒才能干完这事儿。
换了读写锁 new ReentrantReadWriteLock() 是 ReadWriteLock 的一种实现,在这种实现里头又分出两把锁来,一把叫 readLock,一把叫 writeLock。通过它的方法 readWriteLock.readLock() 来拿到 readLock 对象,读锁就拿到了。通过 readWriteLock.writeLock() 拿到 writeLock 对象。这两把锁在读的时候扔进去。因此,读线程是可以一起读的,也就是说这18个线程可以一秒钟完成工作结束。所以使用读写锁效率会大大的提升。
Semaphore
Semaphore的意思是信号灯,可以往里面传一个数,permits 是允许的数量,可以想着有几盏信号灯,一个灯里面闪着数字表示到底允许几个来参考这个信号灯。
package com.feenix.juc.c_020_juclocks;
import java.util.concurrent.Semaphore;
public class T11_TestSemaphore {
public static void main(String[] args) {
// 允许2个线程同时执行
Semaphore s = new Semaphore(1, true);
new Thread(() -> {
try {
s.acquire();
System.out.println("T1 running start...");
Thread.sleep(200);
System.out.println("T1 running end...");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
s.release();
}
}).start();
new Thread(() -> {
try {
s.acquire();
System.out.println("T2 running start...");
Thread.sleep(200);
System.out.println("T2 running end...");
s.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
}
}
s.acquire() 这个方法是阻塞方法,阻塞方法的意思是说大概acquire不到的话我就停在这,acquire的意思就是得到。如果我 Semaphore s = new Semaphore(1) 写的是1,我取一下,acquire一下他就变成0,当变成0之后别人是acquire不到的,然后继续执行,线程结束之后注意要s.release(),执行完该执行的就把他release掉,release又把0变回去1,还原化。
Semaphore的含义就是限流,比如说你在买票,Semaphore写5就是只能有5个人可以同时买票。acquire的意思叫获得这把锁,线程如果想继续往下执行,必须得从Semaphore里面获得一个许可,一共有5个许可,用到0了就得等着。
默认 Semaphore 是非公平的,new Semaphore(2, true) 第二个值传true才是设置公平。公平这个事儿是有一堆队列在那儿等着,大家伙过来排队。用这个车道和收费站来举例子,就是我们有四辆车都在等着进一个车道,当后面在来一辆新的时候,它不会超到前面去,要在后面排着这叫公平。所以说内部是有队列的,Reentrantlock、CountDownLatch、CyclicBarrier、Phaser、ReadWriteLock、Semaphore 还有后面要讲的 Exchanger 都是用同一个队列,同一个类来实现的,这个类叫AQS。
Exchanger
Exchanger的意思是交换器,顾名思义,通过这个工具可以在两个线程间交换数据
package com.feenix.juc.c_020_juclocks;
import java.util.concurrent.Exchanger;
public class T12_TestExchanger {
static Exchanger<String> exchanger = new Exchanger<>();
public static void main(String[] args) {
new Thread(() -> {
String s = "T1";
try {
s = exchanger.exchange(s);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ": " + s);
}, "t1").start();
new Thread(() -> {
String s = "T2";
try {
s = exchanger.exchange(s);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + ": " + s);
}, "t2").start();
}
}
第一个线程有一个成员变量叫s,然后exchanger.exchange(s),第二个也是这样,t1线程名字叫T1,第二个线程名字叫T2。到最后,打印出来你会发现它俩交换了一下。线程间通信的方式非常多,这只是其中一种。
可以把Exchanger想象成一个容器,这个容器有两个值,两个线程,有两个格的位置,第一个线程执行到 exchanger.exchange 的时候阻塞住。但是要注意这个 exchange 方法的时候是往里面扔了一个值,你可以认为把T1扔到第一个格子了,然后第二个线程开始执行,也执行到这句话了,exchange,把自己的这个值T2扔到第二个格子里。接下来这两个哥们儿交换一下,T1扔给T2,T2扔给T1,两个线程继续往前跑。exchange()只能是两个线程之间,交换这个东西只能两两进行。
LockSupport
在以前如果需要阻塞和唤醒某一个具体的线程有很多限制:
1、因为 wait() 方法需要释放锁,所以必须在 synchronized 中使用,否则会抛出异常IllegalMonitorStateException;
2、notify() 方法也必须在 synchronized 中使用,并且应该指定对象;
3、synchronized()、wait()、notify() 对象必须一致,一个 synchronized() 代码块中只能有一个线程调用 wait() 或 notify();
以上诸多限制,体现出了很多的不足,所以 LockSupport 的好处就体现出来了。在JDK1.6中的java.util.concurrent 的子包 locks 中引了 LockSupport 这个API。LockSupport 是一个比较底层的工具类,用来创建锁和其他同步工具类的基本线程阻塞原语。Java锁和同步器框架的核心 AQS: AbstractQueuedSynchronizer,就是通过调用 LockSupport .park() 和 LockSupport .unpark() 的方法,来实现线程的阻塞和唤醒的。
public class T13_TestLockSupport {
public static void main(String[] args) {
//使用lombda表达式创建一个线程t
Thread t = new Thread(()->{
for (int i = 0; i < 10; i++) {
System.out.println(i);
if(i == 5) {
//使用LockSupport的park()方法阻塞当前线程t
LockSupport.park();
}
try {
//使当前线程t休眠1秒
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
//启动当前线程t
t.start();
}
}从以上的小程序中,我们不难看出 LockSupport 使用起来的是比较灵灵活的,没有了所谓的限制。分析一下代码的执行过程:首先使用 Lambda 表达式创建了线程对象 " t " ,然后通过 " t " 对象调用线程的启动方法 start(),然后再看线程的内容。在for循环中,当 i 的值等于 5 的时候,调用了 LockSupport 的 park() 方法使当前线程阻塞,注意看方法并没有加锁,就默认使当前线程阻塞了,由此可以看出 LockSupprt.park() 方法并没有加锁的限制。
public class T13_TestLockSupport {
public static void main(String[] args) {
//使用lombda表达式创建一个线程t
Thread t = new Thread(()->{
for (int i = 0; i < 10; i++) {
System.out.println(i);
if(i == 5) {
//使用LockSupport的park()方法阻塞当前线程t
LockSupport.park();
}
try {
//使当前线程t休眠1秒
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
//启动当前线程t
t.start();
//唤醒线程t
LockSupport.unpark(t);
}
}分析一下上面这段代码:只需要在第一个小程序的主线程中,调用 LockSupport 的 unpark() 方法,就可以唤醒某个具体的线程。这里指定了线程 " t " ,代码运行以后结果显而易见,线程并没有被阻塞,成功唤醒了线程 " t " 。在这里还有一点,需要我们来分析一下:在主线程中线程 " t " 调用了 start() 方法以后,因为紧接着执行了 LockSupport 的 unpark() 方法,所以也就是说,在线程 " t "还没有执行还没有被阻塞的时候,已经调用了 LockSupport 的 unpark() 方法来唤醒线程 " t " ,之后线程 " t "才启动调用了 LockSupport 的 park() 来使线程 " t " 阻塞,但是线程 " t " 并没有被阻塞。由此可以看出,LockSupport 的 unpark() 方法可以先于 LockSupport 的 park() 方法执行。
public class T13_TestLockSupport {
public static void main(String[] args) {
//使用lombda表达式创建一个线程t
Thread t = new Thread(()->{
for (int i = 0; i < 10; i++) {
System.out.println(i);
if(i == 5) {
//调用LockSupport的park()方法阻塞当前线程t
LockSupport.park();
}
if(i == 8){
//调用LockSupport的park()方法阻塞当前线程t
LockSupport.park();
}
try {
//使当前线程t休眠1秒
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
//启动当前线程t
t.start();
//唤醒线程t
LockSupport.unpark(t);
}
}分析一下上面这段代码:在第二个小程序的基础上又添加了一个 if 判断。在 i 等于 8 的时候再次调用 LockSupport 的 park() 方法来使线程 " t " 阻塞。可以看到线程被阻塞了,原因是 LockSupport 的 unpark() 方法就像是获得了一个“令牌”,而 LockSupport 的 park() 方法就像是在识别“令牌”。当主线程调用了 LockSupport.unpark(t) 方法也就说明线程 " t " 已经获得了”令牌”。当线程 " t " 再调用 LockSupport 的 park() 方法时,线程 " t " 已经有令牌了,这样就会马上再继续运行,也就不会被阻塞了。但是当 i 等于 8 的时候线程 " t " 再次调用了 LockSupport 的 park() 方法使线程再次进入阻塞状态,这个时候“令牌”已经被使用作废掉了,也就无法阻塞线程 " t " 了。而且如果主线程处于等待“令牌”状态时,线程 " t " 再次调用了 LockSupport 的 park() 方法,那么线程 " t "就会永远阻塞下去,即使调用unpark()方法也无法唤醒了。
由以上三段代码可以总结得出以下几点:
1、LockSupport 不需要 synchornized 加锁就可以实现线程的阻塞和唤醒;
2、LockSupport.unpartk() 可以先于 LockSupport.park( )执行,并且线程不会阻塞;
3、如果一个线程处于等待状态,连续调用了两次 park() 方法,就会使该线程永远无法被唤醒;
LockSupport 中 park() 和 unpark() 方法的实现原理:park() 和unpark() 方法的实现是由 Unsefa 类提供的,而 Unsefa 类是由 C 和 C++ 语言完成的。其实原理也是比较好理解,它主要通过一个变量作为一个标识,变量值在 0 和 1 之间来回切换。当这个变量大于 0 的时候线程就获得了“令牌”,从这一点不难知道,其实 park() 和 unpark() 方法就是在改变这个变量的值,来达到线程的阻塞和唤醒。
5、从两道面试题深入理解JUC
面试题1
淘宝曾经出过这么一道面试题来考察多线程相关的知识:实现一个容器,提供两个方法:add、size。写两个线程:线程1,添加10个元素到容器中;线程2,实时监控元素个数,当个数到5个时,线程2给出提示并结束。
synchronized实现
通过 new 一个 ArrayList,在自定义的 add 方法直接调用 list 的 add 方法,在自定义的 size 方法直接调用 list 的 size方法,想法很简单。首先小程序化了这个容器,接下来启动了 t1 线程,t1 线程中做了一个循环,每次循环就添加一个对象,加一个就打印显示一下到第几个了,然后给了1秒的间隔,在t2线程中写了了一个 while 循环,实时监控着集合中对象数量的变化,如果数量达到 5就结束 t2 线程。
public class T01_WithoutVolatile {
List lists = new ArrayList();
public void add(Object o) {
lists.add(o);
}
public int size() {
return lists.size();
}
public static void main(String[] args) {
T01_WithoutVolatile c = new T01_WithoutVolatile();
new Thread(() -> {
for(int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add " + i);
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t1").start();
new Thread(() -> {
while(true) {
if(c.size() == 5) {java
break;
}
}
System.out.println("t2 结束");
}, "t2").start();
}
}方法并没有按预期的执行,注意看 t2 线程中 c.size() 这个方法。当对象添加以后,ArrayList 的size() 方肯定是要更新的。当 t1 线程中的 size() 方法要更新的时候,还没有更新 t2 线程就读了,这个时候 t2 线程读到的值就与实际当中加入的值不一致了。所以得出两结论:1、这个方案没有加同步;2、while(true) 中的 c.size() 方法永远没有检测到,没有检测到的原因是线程与线程之间是不可见的。
public class T02_WithVolatile {
volatile List lists = new LinkedList();
public void add(Object o) {
lists.add(o);
}
public int size() {
return lists.size();
}
public static void main(String[] args) {
T02_WithVolatile c = new T02_WithVolatile();
new Thread(() -> {
for(int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add " + i);
/*try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}*/
}
}, "t1").start();
new Thread(() -> {
while(true) {
if(c.size() == 5) {
break;
}
}
System.out.println("t2 结束");
}, "t2").start();
}
}public class T03_NotifyHoldingLock {
//添加volatile,使t2能够得到通知
volatile List lists = new ArrayList();
public void add(Object o) {
lists.add(o);
}
public int size() {
return lists.size();
}
public static void main(String[] args) {
T03_NotifyHoldingLock c = new T03_NotifyHoldingLock();
final Object lock = new Object();
// 需要注意先启动t2再启动t1
new Thread(() -> {
synchronized(lock) {
System.out.println("t2 启动");
if(c.size() != 5) {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("t2 结束");
}
}, "t2").start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
new Thread(() -> {
System.out.println("t1 启动");
synchronized(lock) {
for(int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add " + i);
if(c.size() == 5) {
lock.notify();
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "t1").start();
}
}这一版的改进用了锁的方式,利用 wait() 和 notify(),通过给 object 对象上锁然后调用 wait() 和notify() 实现这道面试题。分析一下:首先 List 集合实现的 add 和 size 方法不多做解释,把重点放在mian方法上。main方法里创建了 object 对象,让后起了两个线程 t1 和 t2,t1 用来增加对象,t2用来监控集合添加的对象个数。在 t2 线程给 object 对象加锁,然后判断集合对象的个数为 5 的时候,就调用 wait() 方法阻塞 t2 线程,并给出相应提示。t1 线程里给 object 对象加锁,通过 for 循环来给集合添加对象,当对象添加到 5 个的时候,唤醒 t2 线程来完成对象个数的监控,这里需要保证先启动的是第二个线程,让它直接进入监控状态,以完成实时监控。
但是运行后就会发现,这种写法也是行不通的,原因是 notify() 方法不释放锁。当 t1 线程调用了notify() 方法后,并没有释放当前的锁,所以 t1 还是会执行下去。待到 t1 执行完毕,t2 线程才会被唤醒接着执行,这个时候对象已经不只有 5 个了,所以这个方案也是行不通的。
public class T04_NotifyFreeLock {
volatile List lists = new ArrayList();
public void add(Object o) {
lists.add(o);
}
public int size() {
return lists.size();
}
public static void main(String[] args) {
T04_NotifyFreeLock c = new T04_NotifyFreeLock();
final Object lock = new Object();
new Thread(() -> {
synchronized (lock) {
System.out.println("t2 启动");
if (c.size() != 5) {
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("t2 结束");
lock.notify();
}
}, "t2").start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
new Thread(() -> {
System.out.println("t1 启动");
synchronized (lock) {
for (int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add " + i);
if (c.size() == 5) {
lock.notify();
try {
lock.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}, "t1").start();
}
}继续在上一版的基础上做一些小改动,分析一下执行流程:首先 t2 线程执行,判断到 list 集合里的对象数量没有 5 个。t2 线程被阻塞了,接下来 t1 线程开始执行,当循环添加了 5 个对象后,唤醒了 t2 线程,重点在于上一版的代码中说过 notify() 方法是不会是释放锁的,所以在 notify() 以后,又紧接着调用了 wait() 方法阻塞了 t1 线程,实现了t2线程的实时监控。t2 线程执行结束,打印出相应提示,最后调用 notify() 方法唤醒t1线程,让t1线程完成执行,看过执行结果,发现这一版终于完成了面试题的功能成功运行。
CountDownLatch实现
public class T05_CountDownLatch {
volatile List lists = new ArrayList();
public void add(Object o) {
lists.add(o);
}
public int size() {
return lists.size();
}
public static void main(String[] args) {
T05_CountDownLatch c = new T05_CountDownLatch();
CountDownLatch latch = new CountDownLatch(1);
new Thread(() -> {
System.out.println("t2 启动");
if (c.size() != 5) {
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("t2 结束");
}, "t2").start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
new Thread(() -> {
System.out.println("t1 启动");
for (int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add " + i);
if (c.size() == 5) {
latch.countDown();
}
/*try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}*/
}
}, "t1").start();
}
}用 CountDownLatch 来完成这一题的需求,来分析代码的执行流程:首先不难看出和上一版的写法大同小异。同样是 list 集合实现 add 和 size 方法,两个线程 t1 和 t2。t1 线程里是循环添加对象,t2 里是实时监控,不同点在于没有了锁,采用了 await() 方法替换了 t2 线程和 t1 线程中的wait() 方法。执行流程是创建门闩对象 latch,t2 线程开始启动,判断到对象不等于 5,调用 await() 方法阻塞 t2 线程,t1 线程开始执行添加对象,当对象增加到5个时,打开门闩让 t2 继续执行。
执行结果看似没什么大问题,但是当把休眠1秒这段带代码,从t1线程里注释掉以后,会发现出错了:原因是在 t1 线程里,对象增加到 5 个时,t2 线程的门闩确实被打开了。但是 t1 线程马上又会接着执行,之前是 t1 会休眠 1 秒,给 t2 线程执行时间。但当注释掉休眠 1 秒这段带代码,t2 就没有机会去实时监控了。所以这种方案来使用门闩是不可行的。但是如果非得使用门闩,还要求在对象数量为 5 的时候把t2线程打印出来,如何实现呢?
public class T05_CountDownLatch {
volatile List lists = new ArrayList();
public void add(Object o) {
lists.add(o);
}
public int size() {
return lists.size();
}
public static void main(String[] args) {
T05_CountDownLatch c = new T05_CountDownLatch();
CountDownLatch latch = new CountDownLatch(1);
new Thread(() -> {
System.out.println("t2 启动");
if (c.size() != 5) {
try {
latch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("t2 结束");
}, "t2").start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
new Thread(() -> {
System.out.println("t1 启动");
for (int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add " + i);
if (c.size() == 5) {
latch.countDown();
try {
latch.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t1").start();
}
}很容易理解,只需要在 t1 线程打开 t2 线程门闩的时候,让它再给自己加一个门闩就可以了。
LockSupport实现
public class T06_LockSupport {
volatile List lists = new ArrayList();
public void add(Object o) {
lists.add(o);
}
public int size() {
return lists.size();
}
public static void main(String[] args) {
T06_LockSupport c = new T06_LockSupport();
CountDownLatch latch = new CountDownLatch(1);
Thread t2 = new Thread(() -> {
System.out.println("t2 启动");
if (c.size() != 5) {
LockSupport.park();
}
System.out.println("t2 结束");
}, "t2");
t2.start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
new Thread(() -> {
System.out.println("t1 启动");
for (int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add " + i);
if (c.size() == 5) {
LockSupport.unpark(t2);
}
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t1").start();
}
}这段代码采用了 LockSupport 来实现,与之前的小程序也是大同小异,不同的只是改变了线程阻塞和唤醒所使用的方法。但是这段代码其实也是有不足的地方:当注释掉 t1 线程中休眠 1 秒方法的时候,程序就出错了。原因是在 t1 线程调用 unpark() 方法唤醒 t2 线程的时候,t1线程并没有停止,就会造成 t2 线程无法及时的打印出提示信息。怎么解决呢?
public class T07_LockSupport_WithoutSleep {
volatile List lists = new ArrayList();
public void add(Object o) {
lists.add(o);
}
public int size() {
return lists.size();
}
static Thread t1 = null, t2 = null;
public static void main(String[] args) {
T07_LockSupport_WithoutSleep c = new T07_LockSupport_WithoutSleep();
t1 = new Thread(() -> {
System.out.println("t1 启动");
for (int i = 0; i < 10; i++) {
c.add(new Object());
System.out.println("add " + i);
if (c.size() == 5) {
LockSupport.unpark(t2);
LockSupport.park();
}
}
}, "t1");
t2 = new Thread(() -> {
// System.out.println("t2 启动");
// if (c.size() != 5) {
LockSupport.park();
// }
System.out.println("t2 启动");
LockSupport.unpark(t1);
}, "t2");
t2.start();
t1.start();
}
}在 t1 线程调用 unpark()方法唤醒 t2 线程的时候,紧接着调用 park() 方法使 t1 线程阻塞,然后在 t2 线程打印信息结束后调用 unpark() 方法唤醒t1线程。
Semaphore实现
public class T08_Semaphore {
volatile List lists = new ArrayList();
public void add(Object o) {
lists.add(o);
}
public int size() {
return lists.size();
}
static Thread t1 = null, t2 = null;
public static void main(String[] args) {
T08_Semaphore c = new T08_Semaphore();
Semaphore s = new Semaphore(1);
t1 = new Thread(() -> {
try {
s.acquire();
for (int i = 0; i < 5; i++) {
c.add(new Object());
System.out.println("add " + i);
}
s.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
t2.start();
t2.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
try {
s.acquire();
for (int i = 5; i < 10; i++) {
System.out.println(i);
}
s.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t1");
t2 = new Thread(() -> {
try {
s.acquire();
System.out.println("t2 结束");
s.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t2");
// t2.start();
t1.start();
}
}这里是通过 Semaphore 来实现,大体的执行流程大体是这样的:创建一个 Semaphore 对象,设置只能有 1 个线程可以运行。首先线程 1 开始启动,调用 acquire() 方法限制其它线程运行,在 for 循环添加了 4 个对象以后,调用 s.release() 表示其它线程可以运行。这个时候 t1 线程启动 t2 线程,调用 join() 把 CPU 的控制权交给 t2 线程,t2 线程打印出提示信息,并继续输出后来的对象添加信息。当然了这个方案看起来很牵强,但的确实现了这个效果,思路是好的可以用做参考。
面试题2
写一个固定容量同步容器,拥有 put 和 get 方法,以及 getCount 方法,能够支持 2 个生产者线程以及10个消费者线程的阻塞调用,非常经典的生产者和消费者问题。
synchronized实现
public class MyContainer1<T> {
final private LinkedList<T> lists = new LinkedList<>();
final private int MAX = 10;
private int count = 0;
public synchronized void put(T t) {
while (lists.size() == MAX) {
try {
// this.notifyAll()
this.wait(); //effective java
} catch (InterruptedException e) {
e.printStackTrace();
}
}
lists.add(t);
++count;
this.notifyAll(); // 通知消费者线程进行消费
}
public synchronized T get() {
T t = null;
while (lists.size() == 0) {
try {
//this.notifyAll()
this.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
t = lists.removeFirst();
count--;
this.notifyAll(); // 通知生产者进行生产
return t;
}
public static void main(String[] args) {
MyContainer1<String> c = new MyContainer1<>();
// 启动消费者线程
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 5; j++) {
System.out.println(c.get());
}
}, "c" + i).start();
}
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 启动生产者线程
for (int i = 0; i < 2; i++) {
new Thread(() -> {
for (int j = 0; j < 25; j++) {
c.put(Thread.currentThread().getName() + " " + j);
}
}, "p" + i).start();
}
}
}在这段代码中,创建了一个 LinkedList 集合用于保存 “馒头”,定义了 MAX 变量来限制馒头的总数,定义了 count 变量用来判断生产了几个 “馒头”和消费了几个 “馒头”。在 put() 方法中,首先判断 LinkedList 集合中“馒头”是否是 MAX 变量的值,如果是启动所有消费者线程,反之开始生产 “馒头”。在 get() 方法中,首先判断是否还有 “馒头”,也就是 MAX 的值是否为0,如果为 0 通知所有生产者线程开始生产 “馒头”,反之不为 0 “馒头”数就继续减少。
需要注意的点是:为什么要加 synchronized,因为我们 ++count 生产了3个 “馒头”,当还没来得及加的时候,count 值为 2 的时候,另外一个线程读到的值很可能是 2,并不是 3,所以不加锁就会出问题。接着来看 main 方法中通过 for 循环分别创建了 2 个生产者线程生产分别生产 25 “馒头”,也就是50个馒头,10 个消费者线程每个消费者消费 5 个 “馒头”,也就是 50 个 “馒头”,首先启动消费者线程,然后启动生产者线程。
第二个要注意的点是:用的是 notifyAll() 来唤醒线程的。notifyAll() 方法会叫醒等待队列的所有方法。我们都知道,用了锁以后就只有一个线程在运行,其他线程都得 wait(),不管有多少个线程,这个时候被叫醒的线程有消费者的线程和生产者的线程,所有的线程都会争抢这把锁。比如说我们是生产者线程,生产满了,满了以后我们叫醒消费者线程。可是很不幸的是,它同样的也会叫醒另外一个生产者线程,假如这个生产者线程难道了这把锁刚才第一个生产者释放的这把锁,拿到了以后,它又 wait() 一遍,wait() 完以后,又叫醒全部的线程,然后又开始争抢这把锁。其实从这个意义上来讲,生产者的线程 wait 的时候是没有必要去叫醒别的生产者的,能不能只叫醒消费者线程,就是生产者线程只叫醒消费者线程,消费者线程只负责叫醒生产者线程,这样能实现吗?其实很简单,换把锁就行。
ReentrantLock实现
public class MyContainer2<T> {
final private LinkedList<T> lists = new LinkedList<>();
final private int MAX = 10; // 最多10个元素
private int count = 0;
private Lock lock = new ReentrantLock();
private Condition producer = lock.newCondition();
private Condition consumer = lock.newCondition();
public void put(T t) {
lock.lock();
try {
while (lists.size() == MAX) {
producer.await();
}
lists.add(t);
++count;
consumer.signalAll(); // 通知消费者线程进行消费
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
public T get() {
T t = null;
lock.lock();
try {
while (lists.size() == 0) {
consumer.await();
}
t = lists.removeFirst();
count--;
producer.signalAll(); // 通知生产者进行生产
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
return t;
}
public static void main(String[] args) {
MyContainer2<String> c = new MyContainer2<>();
// 启动消费者线程
for (int i = 0; i < 10; i++) {
new Thread(() -> {
for (int j = 0; j < 5; j++) {
System.out.println(c.get());
}
}, "c" + i).start();
}
try {
TimeUnit.SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 启动生产者线程
for (int i = 0; i < 2; i++) {
new Thread(() -> {
for (int j = 0; j < 25; j++) {
c.put(Thread.currentThread().getName() + " " + j);
}
}, "p" + i).start();
}
}
}上面这段代码换成了 ReentrantLock,它与 synchronized 最大区别在于它可以有两种 Condition 条件,在 put() 方法里是生产者线程,生产者线程 lock() 最后 unlock() 不多说,一但 MAX 达到峰值的时候是 producer.await(),最后是 consumer.signalAll(),就是说在 producer 的情况下阻塞的,叫醒的时候只叫醒 consumer;在 get() 方法里是消费者线程,一但集合的 size 空了,我是consumer.await(),然后我只叫醒 producer,这就是 ReentrantLock 的含义。它能够精确的指定哪些线程被叫醒。
注意是哪些不是哪个。Lock 和 Condition的本质是在 synchronized 里调用 wait() 和 notify() 的时候,它只有一个等待队列。如果 lock.newCondition() 的时候,就变成了多个等待队列,Condition的本质就是等待队列个数,以前只有一个等待队列,现在 new 了两个 Condition,一个叫 producer一个等待队列出来了,另一个叫 consumer 第二个的等待队列出来了。当使用 producer.await() 的时候,指的是当前线程进入 producer 的等待队列,使用 producer.signalAll() 指的是唤醒 producer这个等待队列的线程,consumer 也是如此。
所以上面的这段代码就很容易理解了,在生产者线程里叫醒 consumer 等待队列的线程也就是消费者线程,在消费者线程里叫醒 producer 待队列的线程也就是生产者线程,这段代码的思路就是这样了。
6、浅谈 AQS 设计
AQS 的全称为 Abstract Queued Synchronizer,这个类在 java.util.concurrent.locks 包下面。AQS 是一个用来构建锁和同步器的框架,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器, 比如前面提到的 ReentrantLock、CountDownLatch、CyclicBarrier、Semaphore.....等等皆是基于 AQS 来实现的。当然,我们自己也能利用 AQS 构造出符合我们自己需求的同步器。
AQS 队列又可以称为 CLH 队列,AQS 的核心就是一个被 volatile 修饰的整型变量 state,这个state 所代表的意思随子类来定。比如在 ReentrantLock 中,刚才 state 的值是0,当获得了之后它会变成1,就表示当前线程得到了这把锁,什么时候你释放完了,state又会从1变回0,说明当前线程释放了这把锁,所以这个state 的 0 和 1 就代表了加锁和解锁。
所以这个 state 的值是根据子类不同的实现取不同的意义,这个 state 的值的基础之上,它的下面跟着一个队列,这个队列是 AQS 自己内部所维护的队列,这个队列里边每一个所维护的都是 node 一个节点,它在哪里呢?在AQS这个类里,属于AQS的内部类。在这个 node 里最重要的一项是里面保留了一个 Thread 线程,所以这个队列是个线程队列。而且还有两个 prev 和 next 分别是前面的节点和后面的节点。所以 AQS 里边的队列是这样子的:一个一个的 node,node里装的是线程 Thread。这个 node 它可以指向前面的这一个,也可以指向后面的这一个,所以叫双向链表。所以AQS的核心是一个 state,以及监控这个 state 的双向链表。每个链表里面有个节点,这个节点里边装的是线程,哪个线程得到了 state 这把锁,哪个线程要等待,都要进入这个队列。
当其中一个 node 得到了 state 这把锁,就说明这个 node 里的线程持有这把锁,所以当 acquire(1)上来以后看到这个 state 的值是0,那就直接拿到 state 这个把锁。对于非公平来说上来就抢,抢不着就进队列里 acquireQueued(),怎么是抢到呢?先得到当前线程,然后获取 state 的值,如果state 的值等于0,用 compareAndSetState(0,acquire) 方法尝试把state的值改为1,假如改成了 setExclusiveOwnerThread() 把当前线程设置为独占 state 这把锁的状态,说明已经得到这把锁。而且这个把锁是互斥的,得到以后,其它线程是得不到的,因为其它线程再来的时候这个 state 的值已经变成 1 了。如果说当前线程已经是独占 state 这把锁了,就往后加个 1 就表示可重入了。
回想一下AQS数据结构图,它有一个 int 类型的数叫 state,然后在 state 下面排了一个队列,这个队列是个双向的链表有一个 head 和一个 tail。现在要往这个队列中加一个节点,应该得加到这个队列的末端是不是,它是怎么做到的呢?
首先把 tail 记录在 oldTail 里,oldTail 指向这个 tail 了。如果 oldTail 不等于空,它会把我们这个新节点的前置节点设置在这个队列的末端。接下来再次用到CAS操作,把我们这个新的节点设置为tail。整段代码看似繁琐,其实很简单,就是要把当前要加进等待者队列的线程的节点加到等待队列的末端。这里提一点,加到末端为什么要用 CAS 操作呢?因为 CAS 效率高,这个问题关系到AQS 的核心操作,理解了这一点,就理解了 AQS 为什么效率高。这个增加线程节点操作,如果没有成功,那么就会不断的试,一直试到这个 node 节点被加到线程队列末端为止。也就是说,其它的节点也加到线程队列末端了,无非就是等着其它的线程都加到末端了,我加最后一个,不管怎么样我都要加到线程末端去为止。
到这里就可以总结得出,AQS 的核心就是用 CAS 去操作 head 和 tail,就是说用 CAS 操作代替了锁整条双向链表的操作。
AQS为什么效率这么高
假如你要往一个链表上添加尾巴,尤其是好多线程都要往链表上添加尾巴,仔细想想看用普通的方法怎么做?首先要加锁这一点是肯定的。因为多线程,要保证线程安全,一般的情况下,会锁定整个链表(Sync)。新线程来了以后,要加到尾巴上,这样很正常。但是锁定整个链表的话,锁的粒度太粗。所以这里它用的并不是锁定整个链表的方法,而是只观测 tail 这一个节点就可以了。
通过 compareAndAetTail(oldTail,node) 方法,其中 oldTail 是它的预期值。假如说想把当前线程设置为整个链表尾巴的过程中,另外一个线程来了,它插入了一个节点,那么仔细想一下 Node oldTail = tail; 的整个 oldTail 还等于整个新的 Tail 吗?应该不等于了吧,说明中间有线程被其它线程打断了;如果还是等于原来的oldTail,就说明没有线程被打断,那就接着设置尾巴。只要设置成功,compareAndAetTail(oldTail,node) 方法中的参数 node 就做为新的 Tail了。所以用了 CAS 操作就不需要把原来的整个链表上锁,这也是 AQS 在效率上比较高的核心。
为什么是双向链表
其实要添加一个线程节点的时候,需要看一下前面这个节点的状态,如果前面的节点是持有线程的过程中,这个时候就得在后面等着;如果说前面这个节点已经取消掉了,那就应该越过这个节点,不去考虑它的状态,所以需要看前面节点状态的时候,就必须是双向的。
VarHandle
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
public final void acquire(int arg) {
// 判断是否得到锁
if(!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE),arg)) {
selfInterrupt();
}
}
private Node addWaiter(Node mode) {
// 获取当前要加进来的线程的node(节点)
Node node = new Node(mode);
for(;;) {
// 回想一下AQS数据结构图
Node oldTail = tail;
if(oldTail != null) {
// 把新节点的前置节点设置在等待队列的末端
node.setPrevRelaved(oldTail);
// CAS操作,把我们这个新节点设置为tail末端
if(compareAndAetTail(oldTail,node)){
oldTail.next = node;
return node;
}
} else {
initializeSuncQueue();
}
}
}
final void setPrevRelaved(Node p){
PREV.set(this,p);
}
private static final VarHandle PREV;
static {
try{
MethodHandles.Lookup l = MethodHandles.lookup():
PREV = l.findVarHandle(Node.class,"prev",Node.class);
}catch(ReflectiveOperationException e){
throw new ExceptionInInitializerError(e);
}
}
}看这句代码 node.setPrevRelaved(oldTail),具体实现是 PREV.set(this,p),而这个 PREV 就是一个 VarHandle 类型的变量 private static final VarHandle PREV;
这个 VarHandle 是JDK1.9 之后才引入,Var 意思是变量,Handle 意思是句柄。比如写了一句代码叫 Object o= new Object(),new了一个Object,这个时候内存里有一个小的引用o,指向一段大的内存。这个内存里是 new 的那个 Object 对象。这个VarHandle指的就是这个“引用”。
如果VarHandle代表所谓的“引用”,那么 VarHandle 所代表的这个值 PREV 是不是也就是这个“引用”呢?当然是了。那本来已经有一个 o 指向这个 Object 对象了,为什么还要用另外一个引用也指向这个对象?先来看一段代码
public class T01_HelloVarHandle {
int x = 8;
private static VarHandle handle;
static {
try {
handle = MethodHandles.lookup().findVarHandle(T01_HelloVarHandle.class, "x", int.class);
} catch (NoSuchFieldException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
T01_HelloVarHandle t = new T01_HelloVarHandle();
System.out.println((int)handle.get(t));
handle.set(t,9);
System.out.println(t.x);
handle.compareAndSet(t, 9, 10);
System.out.println(t.x);
handle.getAndAdd(t, 10);
System.out.println(t.x);
}
}在这段代码中,定义了一个 int 类型的变量 x,然后定义了一个 VarHandle 类型的变量 handle,在静态代码块里设置了 handle 指向 T01_HelloVarHandle 类里的 x 变量的引用。换句话说就是通过这个 handle 也能找到这个x,就可以通过这个 handle 来操作这个x的值。
在 main 方法里,创建了 T01_HelloVarHandle 对象叫 t,这个 t 对象里有一个 x,里面还有个handle,这个 handle 也指向这个 x。既然 handle 指向 x,当然可以 (int) handle.get(t) 拿到这个 x的值就是8。还可以通过 handle.set(t, 9) 来设置这个 t 对象的 x 值为9。读写操作很容易理解,因为 handle 指向了这个变量,但是最关键的是通过这个 handle 可以做什么事呢?
handle.compareAndSet(t, 9, 10) 这个方法做原子性操作,通过 handle.compareAndSet(t,9,10) 把9 改成 10,这是原子性的操作。但是通过 x = 100 ,它会是原子性的吗?当然 int 类型是原子性的,但是 long 不是原子性的,所以通过这个 handle 可以做一些 compareAndSet 操作。譬如 x=x+10,这肯定不是原子操作。当在写这句话的时候,要做到线程安全的话是需要加锁的。但是如果通过 handle 是不需要的。所以这就是为什么会有 VarHandle,VarHandle除了可以完成普通属性的原子操作,还可以完成原子性的线程安全的操作,这也是VarHandle的含义。
在 JDK1.9 之前要操作类里边的成员变量的属性,只能通过反射完成,用反射和用 VarHandle 的区别在于,VarHandle 的效率要高的多,反射每次用之前要检查,VarHandle不需要,VarHandle可以理解为直接操纵二进制码,所以 VarHandle 的效率比反射高的多。
7、从ThreadLocal原理了解四大引用类型
ThreadLocal
Thread是线程,Local意思是本地,线程本地到底是什么意思呢?老规矩,先来看一段代码
public class ThreadLocal1 {
static Person p = new Person();
public static void main(String[] args) {
new Thread(() -> {
SleepHelper.sleepSeconds(1);
p.name = "zhangcuishan";
}).start();
new Thread(() -> {
SleepHelper.sleepSeconds(2);
System.out.println(p.name);
}).start();
}
}
class Person {
String name = "xiexun";
}从这段代码中可以看到这个小程序里定义了一个 Person 类,类里面定义了一个 String 类型的变量name,name的值为“xiexun”。在 ThreadLocal1 这个类里,实例化了这个 Person 类,然后在 main 方法里创建了两个线程,第一个线程打印了 p.name,第二个线程把 p.name 的值改为了“zhangcuishan”,两个线程访问了同一个对象。
最后的结果肯定是打印出了“zhangcuishan”而不是“xiexun”,因为原来的值虽然是“xiexun”,但是有一个线程 1 秒终之后把它变成“zhangcuishan”,另一个线程两秒钟之后才打印出来,那它一定是变成“zhangcuishan”。这件事很正常,但是有的时候想让这个对象每个线程里都做到自己独有的一份,在访问这个对象的时候,一个线程要修改内容的时候要联想另外一个线程,怎么做呢?
public class ThreadLocal2 {
static ThreadLocal<Person> tl = new ThreadLocal<>();
public static void main(String[] args) {
new Thread(() -> {
SleepHelper.sleepSeconds(1);
tl.set(new Person("zhangcuishan"));
System.out.println(tl.get());
tl.remove();
}).start();
new Thread(() -> {
SleepHelper.sleepSeconds(2);
System.out.println(tl.get());
}).start();
}
static class Person {
public Person(String name) {
this.name = name;
}
String name = "xiexun";
}
}在这段代码中,用到了 ThreadLocal。看 main 方法中第二个线程,这个线程在 1 秒终之后往 tl 对象中设置了一个 Person 对象。虽然访问的仍然是这个 tl 对象,第一个线程在两秒钟之后去 get 获取 tl 对象里面的值,第二个线程是 1 秒钟之后往 tl 对象里 set 了一个值。从多线程普通的角度来讲,既然一个线程往里边 set 了一个值,另外一个线程去 get 这个值的时候应该是能 get 到才对。但是 1 秒的时候 set 了一个值,2 秒的时候去拿这个值是拿不到的。
原因是如果用 ThreadLocal 的时候,里边设置的这个值是线程独有的,就是说这个线程里用到这个ThreadLocal 的时候,只有自己去往里设值,设值的是只有自己线程里才能访问到的 Person,而另外一个线程要访问的时候,设值也是自己线程才能访问到的 Person,这就是 ThreadLocal 的含义。
用途搞定了之后来看看这是怎么实现的,往 tl 对象里设置了一个 Person,但是设好了以后,另一个线程为什么就是读取不到呢?还是得瞅一眼 ThreadLocal 的源码。
ThreadLocal源码
public class ThreadLocal<T> {
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
map.set(this, value);
} else {
createMap(t, value);
}
}
}我们先来看一个 ThreadLocal 源码的 set 方法,ThreadLocal 往里边设值的时候,首先拿到当前线程,这个 set 方法里多了一个容器 ThreadLocalMap,这个容器是一个 map,是一个 key / value 键值对。其实这个值就是设置到了 map 里面,而且这个 map 是什么样的,key 设置的是 this,value 设置的是我们想要的那个值。这个 this 就是当前对象 ThreadLocal,value就是 Person 类,这么理解就行了。如果 map 不为空的情况下就设置进去就行了,如果为空就新建一个 map。
public class ThreadLocal<T> {
public void set(T value) {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
map.set(this, value);
} else {
createMap(t, value);
}
}
ThreadLocalMap getMap(Thread t){
return t.threadLocals;
}
}回过头来再看这个 map,ThreadLocalMap map = getMap(t),看看这个map到底在哪里,点击到了 getMap 这个方法看到,它的返回值是 t.threadLocals。进入这个 t.threadLocals,就会发现ThreadLocalMap 这个东西居然是在 Thread 这个类里,所以说这个 map 是在 Thred 类里的。
public class Thread implements Runnable{
ThreadLocal.ThreadLocalMap threadLocals = null;
}所以,map 的 set 方法其实就是设置当前线程里面的map:Thread.currentThread.map(ThreadLocal, person)
Person 类被 set 到了当前线程里的某一个 map 里面去了。当 set 了一个值以后,为什么其它线程访问不到?我们注重“当前线程”这个段话,所以 t1 线程 set 了一个 Person 对象到自己的 map 里,t2 线程去访问的也是自己的属于 t2 线程的 map,所以是读不到值的。在使用 ThreadLocal 的时候,用 set 和 get 就完全的把线程隔离开了,就是每一个线程里面所特有的,其它的线程是没有的。
为什么要用 ThreadLocal
声明式事务是要通过数据库的,Spring 结合 Mybatis 是可以把整个事务写在配置文件中,而这个配置文件里的事务,它实际上是管理了一系列的方法。譬如:第 1 个方法写了去配置文件里拿到数据库连接Connection;第 2 个、第 3 个都是一样去拿数据库链接,然后声明式事务可以把这几个方法合在一起,视为一个完整的事务。如果说在这些方法里,每一个方法拿的连接,它拿的不是同一个对象,这些东西能形成一个完整的事务吗?Connection会放到一个连接池里边,如果第 1 个方法拿的是第 1 个 Connection,第 2 个拿的是第 2 个,第 3 个拿的是第 3 个,这东西能形成一个完整的事务吗?百分之一万的不可能,没听说过不同的 Connection 还能形成一个完整的事务的。那么怎么保证这么多 Connection 之间保证是同一个 Connection 呢?把这个 Connection 放到这个线程的本地对象里 ThreadLocal 里面,以后再拿的时候,实际上是从 ThreadLocal 里拿的,第 1 个方法拿的时候就把 Connection 放到 ThreadLocal 里面,后面的方法要拿的时候,从ThreadLocal 里直接拿,不从线程池拿。
强引用(Normal Reference)
Java的引用类型分为四种,分别是:强、软、弱、虚。在说这个引用类型之前,先来了解一个基础知识
public class M {
@Override
protected void finalize() throws Throwable {
System.out.println("finalize");
}
}Normal Reference,翻译过来应该叫普通引用,也就是所谓的强引用。只要有一个应用指向这个对象,垃圾回收器一定不会回收它。为什么不会回收?因为有引用指向,所以不会回收,只有当没有引用指向的时候才会回收。
public class T01_NormalReference {
public static void main(String[] args) throws IOException {
M m = new M();
System.gc(); //DisableExplicitGC
System.in.read();
}
}在上面这段代码中,new 了一个 M 出来,然后使用 System.gc() 显式的调用一下垃圾回收,让垃圾回收尝试一下,看能不能回收这个M。需要注意的是,要在最后阻塞住当前线程。因为System.gc() 是跑在别的线程里边的。如果main线程直接退出了,那整个程序就退出了,那 gc 不gc 就没有什么意义了。所以要阻塞当前线程,调用了 System.in.read() 阻塞方法,它没有什么含义,只是阻塞当前线程的意思。阻塞当前线程就是让当前整个程序不会停止,程序运行起来会发现,程序永远不会输出。因为这个 M 是有一个小引用 m 指向它。只要有引用指向它,它肯定不是垃圾,不是垃圾的话一定不会被回收。
如果想要被回收,只需要 m = null。意思就是不会再有引用指向这个 M 对象了,也就是说把 m 和new M() 之间的引用给打断了,不再有关联了。这个时候再运行程序,就会输出 finalize,说明M对象被回收了。
public class T01_NormalReference {
public static void main(String[] args) throws IOException {
M m = new M();
m = null;
System.gc(); //DisableExplicitGC
System.in.read();
}
}软引用(Soft Reference)
软引用的含义就是当有一个对象(或是字节数组)被一个软引用所指向的时候,只有系统内存不够用的时候,才会回收它。
public class T02_SoftReference {
public static void main(String[] args) {
SoftReference<byte[]> m = new SoftReference<>(new byte[1024*1024*10]);
System.out.println(m.get());
System.gc();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(m.get());
// 再分配一个数组,heap将装不下,这时候系统会垃圾回收,先回收一次,如果不够,会把软引用干掉
byte[] b = new byte[1024*1024*15];
System.out.println(m.get());
}
}在运行这段代码之前,先设置一下堆内存最大为20MB(-Xms20M -Xmx20M),如果不设置永远不会回收的。当第三次调用 m.get() 输出的时候,输出的值为null。
整个堆内存最多只能放20MB,第一次创建字节数组的时候分配了10MB,这个时候堆内存是能分配下的,所以调用了 gc 来做回收是无法回收的,因为堆内存够用;第二次创建字节数组的时候分配了15MB,这个时候对内存的内存已经不够15MB,得清理。清理的时候既然内存不够用,就会把软引用给干掉,然后再分配15MB内存。这个时候再去 get 第一个字节数组就会得到null。这是就是软引用的含义,软引用的这个特性就很适合做缓存用。
举个栗子,当从内存里边读一个大图片,用完了之后就没什么用了。可以放在缓存在那里,要用的时候直接从内存里边拿。但是由于这个大图片占的空间比较大,如果不用的话,别的也要用这块空间,这时候就可以使用软引用来把它干掉。
弱引用(Weak Reference)
弱引用的意思是,只要遭遇到 gc 就会回收。软引用是只有内存空间不够了才会回收它,因此软引用的生存周期还是比较长的。但是弱引用只要垃圾回收,看到这个引用是一个特别弱的引用指向的时候,就直接把它给干掉。
public class T03_WeakReference {
public static void main(String[] args) {
WeakReference<M> m = new WeakReference<>(new M());
System.out.println(m.get());
System.gc();
System.out.println(m.get());
ThreadLocal<M> tl = new ThreadLocal<>();
tl.set(new M());
tl.remove();
}
}WeakReference<M> m = new WeakReference<>(new M()),这里 new 了一个对象这是第一点。m 指向的是一个弱引用,这个弱引用里边有一个引用,是弱弱的指向了 new 出来的另外一个 M 对象,然后通过 m.get() 来打印这个 M 对象。接下来 gc 调用垃圾回收,如果它没有被回收,接下来get 还能拿到,反之则不能。
运行程序后看到,第一次打印出来了,第二次打印之前调用了 gc,所以第二次打印出了null值。小m 指向这个弱引用对象,这个弱引用对象里边有一个弱弱的引用指向了另外一个大 M 对象。但这个大 M 对象垃圾回收一来就把它干掉了,那么把它创建出来有什么用呢?作用就在于,如果有另外一个强引用指向了这个弱引用之后,只要这个强引用消失掉,这个弱引用就要去被回收。只要这个强引用消失掉,就不用管这个弱引用,这个弱引用也一定是被回收了,通常来说,弱引用一般用在容器里较多。
用最典型的一个应用就是前面刚刚介绍的 ThreadLocal,来看一段代码
public class T03_WeakReference {
public static void main(String[] args) {
WeakReference<M> m = new WeakReference<>(new M());
System.out.println(m.get());
System.gc();
System.out.println(m.get());
ThreadLocal<M> tl = new ThreadLocal<>();
tl.set(new M());
tl.remove();
}
}在 main 线程里有一个线程的局部变量叫 tl,tl 指向 new 出来了一个 ThreadLoal 对象,这是一个强引用没问题。然后又往 ThreadLocal 里放了一个对象,实际上是放到了当前线程的一个threadLocals 变量里面,这个threadLocals 变量指向的是一个Map。也就是把这个 M 对象给放到了这 Map 里面。它的 key 是 ThreadLocal 对象,value 是 M 对象。往 ThreadLocal 里面 set 的时候,先拿到当前线程,然后拿到当前线程里面的 Map,然后通过这个 Map 把 ThreadLocal 对象给set 进去。这个 map.set(this, value) 方法中的 this 是谁?自然是 ThreadLocal 对象,set 进去的时候往里面放了 Entry,这个 Entry 是从弱引用 WeakReference 继承出来的。
public class ThreadLocal<T> {
public void set(T value) {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取当前线程的Map
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
}
ThreadLocalMap getMap(Thread t){
return t.threadLocals;
}
private void set(ThreadLocal<?> key, Object value) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.ge
if (k == key) {
e.value = value;
return;
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
tab[i] = new Entry(key, value);
int sz = ++size;
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
}也就是说有一个Entry,它的父类是 WeakReference,这个 WeakReference 里面装的是ThreadLocal 对象。也就是说这个 Entry 一个 key 一个 value,而这个 Entry 的 key 的类型是ThreadLocal,由于这个 Entry 是从 ThreadLocal 继承的,在 Entry 构造的时候调用了 super(k),k 指的就是 ThreadLocal 对象,那么 WeakReference 不就相当于 new WeakReference key吗?
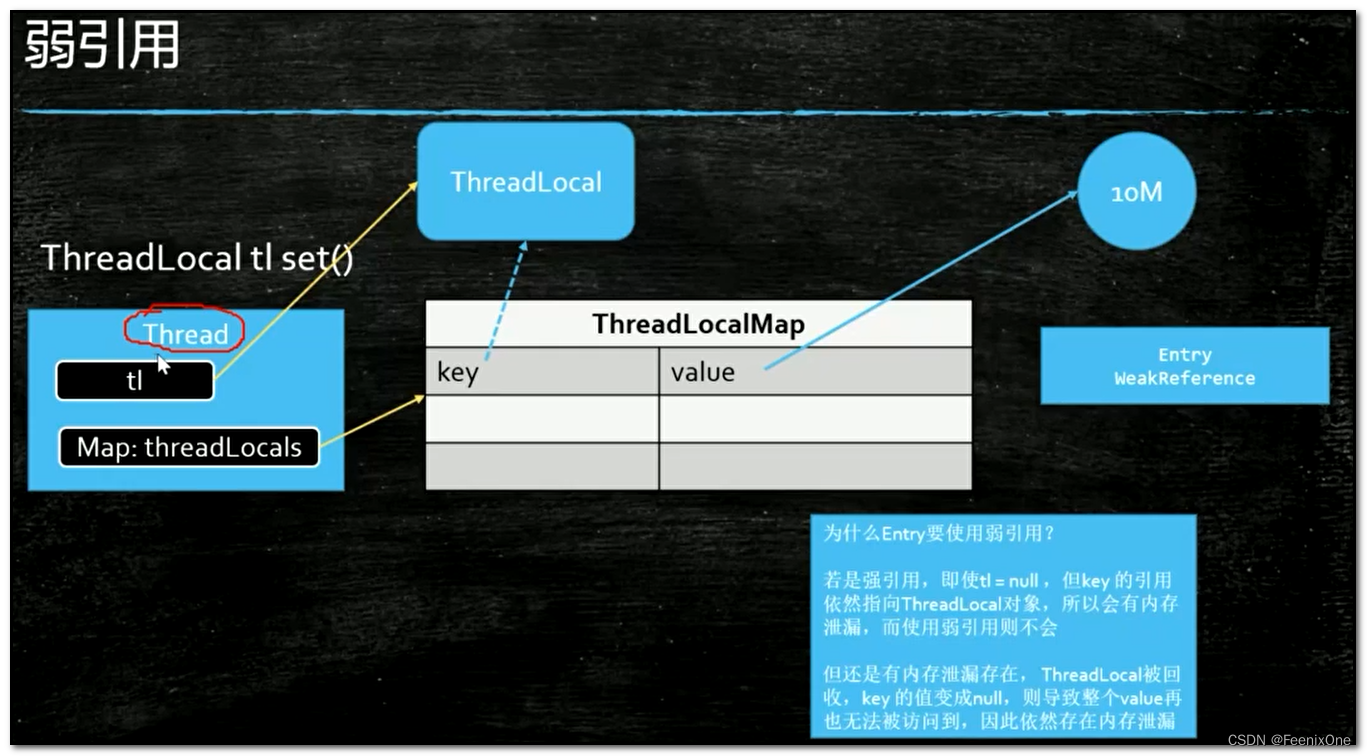
从图中看出,这里 tl 是一个强引用指向这个 ThreadLocal 对象,而 Map 里的 key 是通过一个弱引用指向了一个 ThreadLocal 对象。假设这是个强引用,当 tl 指向这个 ThreadLocal 对象消失的时候,tl 是个局部变量,方法结束它就消失了,当 tl 消失之后,如果这个 ThreadLocal 对象还被一个强引用的 key 指向的时候,这个ThreadLocal对象能被回收吗?肯定不行。而且由于这个线程有很多线程是长期存在的,比如这个是一个服务器线程,7*24小时一年 365 天不间断运行,那么不间断运行的时候,这个 tl 会长期存在,这个 Map 会长期存在,这个 Map 的 key 也会长期存在。这个 key 长期存就会导致 ThreadLocal 对象永远不会被消失,直接产生内存泄漏。但是这个key是弱引用,当这个引用消失的时候,GC一来弱引用就会自动就会回收,这也是为什么用弱引用的原因。
关于 ThreadLocal 还有一个问题, 当 tl 这个强引用消失了,key 的指向也被回收了。可是这个 key指向了一个 null 值,但是这个 threadLocals 的 Map 是永远存在的。相当于说 key / value 键值对,key 是 null 的,value 指向的东西,还能访问到吗?肯定不能。如果访问不到了,Map 越积攒越多,越来越多,它还是会内存泄漏。所以务必记住:当 ThreadLocal 里面的对象不用了,一定要remove 掉,不然最终还是可能会产生内存泄漏!
虚引用(Phantom Reference)
虚引用就是管理堆外内存的。首先第一点,这个虚引用的构造方法至少都是两个参数的,第二个参数还必须是一个队列。虚引用日常编码基本用不到,如果有机会写JVM虚拟机的话,或许有机会可以用到。
public class T04_PhantomReference {
private static final List<Object> LIST = new LinkedList<>();
private static final ReferenceQueue<M> QUEUE = new ReferenceQueue<>();
public static void main(String[] args) {
PhantomReference<M> phantomReference = new PhantomReference<>(new M(), QUEUE);
new Thread(() -> {
while (true) {
LIST.add(new byte[1024 * 1024]);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt();
}
System.out.println(phantomReference.get());
}
}).start();
new Thread(() -> {
while (true) {
Reference<? extends M> poll = QUEUE.poll();
if (poll != null) {
System.out.println("--- 虚引用对象被jvm回收了 ---- " + poll);
}
}
}).start();
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printSackTrace();
}
}
}
在上面这段代码中创建了一个 List 集合用于模拟内存溢出,还创建了一个 ReferenceQueue 引用队列。在 main 方法里创建一个虚引用对象 PhantomReference,虚引用 phantomReference 对象指向了一个 new 出来的 PhantomReference对象,这个对象里面可以访问两个内容:第一个内容是它又通过一个特别虚的引用指向了我们 new 出来的一个 M 对象;第二个内容是它关联了一个Queue(队列)。垃圾回收的时候,虚引用被回收掉,就会装到这个队列里。让你接收到一个通知,什么时候你检测到这个队列里面如果有一个引用存在,就说明这个虚引用被回收了。虚引用指向的任何一个对象,垃圾回收二话不说上来就把这个 M 对象给干掉。当 M 对象被干掉的时候,往这个Queue 里放进一个值给你通知。
这段代码的意思就是,程序运行前先设置好了堆内存的最大值,然后看第一个线程启动以后,它会不停的往 List 集合里分配对象。什么时候内存占满了,触发垃圾回收的时候,另外一个线程就不断的监测这个队列里边的变动,如果有就说明这个虚引用被放进去了,就说明被回收了。
在第一个线程启动后就会看到,无论怎么 get 这个 phantomReference 里面的值,它输出的都是null,虚引用和弱引用的区别就在于,弱引用里边有值,get 的时候还是能 get 出来,但是虚引用get 里边的值是 get 不到。
拿不到这里边的值它能用来干什么?就是为了给一个通知,通知的时候放到队列里。那这个虚引用到底有啥用?写JVM的时候怎么用呢?当检测到队列里边有虚引用指向这个东西被回收的时候做出相应的处理。
经常会有一种情况,NIO 里边有一个比较新的 Buffer 叫 DirectByteBuffer 直接内存,直接内存是不被JVM直接管理的内存,而是被操作系统管理,又叫做堆外内存。这个 DirectByteBuffer 是可以指向堆外内存的。如果 DirectByteBuffer 设为null,垃圾回收器也不能回收 DirectByteBuffer,因为它指向内存都没在堆里,没有办法回收。当 DirectByteBuffer 被设为 null 的时候,可以用虚引用来处理:当检测到虚引用被垃圾回收器回收的时候,做出相应处理去回收堆外内存。

Netty里边分配内存的时候,用的就是堆外内存,那么堆外内存想做到自动的垃圾回收,可以检测虚引用里的 Queue,什么时候 Queue 检测到 DirectByteBuffer 被回收了,这个时候就去清理堆外内存。是 C 和 C++ 语言写的虚拟机的话,使用 del 和 free 这个两个函数,它们也是 C 和 C++ 提供的。Java里面现在也提供了堆外内存回收,回收的类叫Unsafe。这个类在JDK1.8的时候可以用Java的反射机制来用它,但是JDK1.9以后它被加到包里了,普通人用不了。但 JUC 的一些底层有很多都用到了这个类,这个 Unsafe 类里面有两个方法:allocateMemory 方法直接分配内存也就是分配堆外内存;freeMemory 方法回收内存也就是手动回收内存。这和 C 和 C++ 里边一样直接分配内存,必须得手动回收。
8、并发容器

容器牵扯的东西比较多,容器嘛那就是往里面装东西,肯定牵扯到数据结构,数据结构肯定要牵扯到算法。还有一点就是容器本身的一个组织结构也是常见的,再一点它又牵扯到高并发,典型的一个重灾区。容器这章得用好多个维度来讲才能理解的比较透彻。
Java从接口层面区分的比较明确,两大接口:Map 是一对一对的;Collection 是一个一个的,在它里面又分三大类。在大概十年前,那会儿 Collection 只分两大类:List 和 Set,Queue 是后来加入的接口,而这个接口专门就是为高并发准备的,所以这个接口对高并发来说才是最重要的。
容器发展历史
最开始Java1.0容器里只有两个:第一个叫Vector可以单独的往里扔;还有一个是Hashtable可以一对一对往里扔的。Vector相对于实现了List接口,Hashtable实现了Map接口。但是这个两个容器在1.0设计的时候稍微有点问题,这两个容器设计成了所有方法默认都是加synchronized的,这是它最早设计不太合理的地方。多数的时候程序只有一个线程在工作,所以在这种情况下完全是没有必要加synchronized。因此最开始的时候设计的性能比较差,后来有意识到了这一点,在Hashtable之后又添加了HashMap,HashMap就是完全的没有加锁,一个是二话没说就加锁,一个是完全没有加锁。那么怎么才可以让这个HashMap既可以用于不需要锁的环境,又可以用于需要锁的环境呢? 所以它又添加了一个方法叫做Collections,相当于这个容器的工具类,这个工具类里有一个方法叫synchronizedMap,这个方法会把它变成加锁的版本。所以,HashMap其实有两个版本,即可加锁,也可无锁。Vector 和 Hashtable 自带锁,基本不用。
Map
SynchronizedHashMap 和 ConcurrentHashMap
用 SynchronizedMap 这个方法,给 HashMap 手动加锁。它的源码是自己做了一个 Object,然后每次都是 SynchronizedObject,严格来讲它和 Hashtable 效率上区别不大
public class T03_TestSynchronizedHashMap {
static Map<UUID, UUID> m = Collections.synchronizedMap(new HashMap<UUID, UUID>());
static int count = Constants.COUNT;
static UUID[] keys = new UUID[count];
static UUID[] values = new UUID[count];
static final int THREAD_COUNT = Constants.THREAD_COUNT;
static {
for (int i = 0; i < count; i++) {
keys[i] = UUID.randomUUID();
values[i] = UUID.randomUUID();
}
}
static class MyThread extends Thread {
int start;
int gap = count/THREAD_COUNT;
public MyThread(int start) {
this.start = start;
}
@Override
public void run() {
for(int i=start; i<start+gap; i++) {
m.put(keys[i], values[i]);
}
}
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
Thread[] threads = new Thread[THREAD_COUNT];
for(int i=0; i<threads.length; i++) {
threads[i] =
new MyThread(i * (count/THREAD_COUNT));
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
long end = System.currentTimeMillis();
System.out.println(end - start);
System.out.println(m.size());
//-----------------------------------
start = System.currentTimeMillis();
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j = 0; j < 10000000; j++) {
m.get(keys[10]);
}
});
}
for(Thread t : threads) {
t.start();
}
for(Thread t : threads) {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
end = System.currentTimeMillis();
System.out.println(end - start);
}
}ConcurrentHashMap 是多线程里面真正常用的,多线程用的基本就是它。ConcurrentHashMap 提高效率主要提高在读上面,由于它往里插的时候内部又做了各种各样的判断,本来是链表,到 1.8 之后又变成了红黑树,然后里面又做了各种各样的CAS操作,所以往里插的数据的效率是要更低一些。HashMap 和 Hashtable 虽然说读的效率会稍微低一些,但是它往里插的时候检查的东西特别的少,就加个锁然后往里一插。所以,关于效率还是看实际当中的需求。
从Vector到Queue
下面这么一段代码模拟售票的情形,写法比较简单,先用一个List把这些票全装进去,往里面装10000张票。然后起10个线程模拟10个窗口对外销售,只要size大于零,只要还有剩余的票时就一直往外卖,卖一张就remove一次。
public class TicketSeller1 {
static List<String> tickets = new ArrayList<>();
static {
for(int i=0; i<10000; i++) tickets.add("票编号" + i);
}
public static void main(String[] args) {
for(int i=0; i<10; i++) {
new Thread(()->{
while(tickets.size() > 0) {
System.out.println("销售了--" + tickets.remove(0));
}
}).start();
}
}
}到最后一张票的时候,好几个线程执行到这里都发现了size大于零,所有线程都往外买了一张票,但是只有一个线程拿到了这张票,其它的线程拿到的都是空值,就是所谓超卖的现象,没有加锁,线程不安全。
Vector
Vector内部是自带锁的,去看它源码就会看到很多方法都是直接上synchronized,二话不说先加上锁。所以用Vector的时候请放心它一定是线程安全的。100张票,10个窗口,读这个程序还是有问题的,还是不对。
public class TicketSeller2 {
static Vector<String> tickets = new Vector<>();
static {
for(int i=0; i<1000; i++) tickets.add("票编号" + i);
}
public static void main(String[] args) {
for(int i=0; i<10; i++) {
new Thread(()->{
while(tickets.size() > 0) {
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("销售了--" + tickets.remove(0));
}
}).start();
}
}
}为了线程的安全,就是当调用size方法的时候加了锁,调用remove的时候也加了锁,可是在这两个中间没有加锁。好多个线程还会判断依然这个size还是大于0的,大家伙又超卖了。
虽然用了这个加锁的容器,由于在调用这个并发容器的时候,只是调用了其中的两个原子方法,所以在外层还得在加一把锁synchronized (tickets),继续判断size,售出去不断的remove,这个就没有问题了,它会踏踏实实的往外销售,但不是效率最高的方案。
public class TicketSeller3 {
static List<String> tickets = new LinkedList<>();
static {
for(int i = 0; i < 1000; i++) {
tickets.add("票编号" + i);
}
}
public static void main(String[] args) {
for(int i = 0; i < 10; i++) {
new Thread(() -> {
while(true) {
synchronized(tickets) {
if(tickets.size() <= 0) {
break;
}
try {
TimeUnit.MILLISECONDS.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("销售了--" + tickets.remove(0));
}
}
}).start();
}
}
}ConcurrentLinkedQueue
效率最高的就是使用Queue,这是最新的一个接口,主要目标就是为了高并发而设计,就是为了多线程而诞生。所以,以后考虑多线程这种单个元素的时候多考虑Queue。
public class TicketSeller4 {
static Queue<String> tickets = new ConcurrentLinkedQueue<>();
static {
for(int i = 0; i < 1000; i++) {
tickets.add("票编号" + i);
}
}
public static void main(String[] args) {
for(int i = 0; i < 10; i++) {
new Thread(() -> {
while(true) {
String s = tickets.poll();
if(s == null) break;
else System.out.println("销售了--" + s);
}
}).start();
}
}
}这里使用的是ConcurrentLinkedQueue,然后里面并没有说加锁,直接调用poll方法,意思就是从tickets中取值,这个值什么时候取空了就说明里面的值已经没了。while(true)不断的往外销售,一直到突然伸手去取票发现里面没了,那这个窗口就可以关了不用卖票了。poll方法是对于多线程访问的时候比较友好的方法,它的源码是得到queue上的头部,脑袋这个元素,得到并且去除掉这个值,如果脑袋已经是空就返回null。
BlockingQueue
BlockingQueue的概念重点是在Blocking上,Blocking阻塞,Queue队列,是一个阻塞队列。提供了一系列的方法,可以在这些方法的基础之上做到让线程实现自动的阻塞。
Queue里面所提供的一些对多线程比较友好的接口:第一个就是 offer 接口,对应的是原来的那个add方法;第二个提供了 poll 取数据;第三个提供了 peek 拿出来这个数据。
offer是往里头添加,加进去没加进去结果会返回一个布尔类型的返回值,和原来的 add 区别在于如果加不进去了是会抛异常的。所以一般的情况下用的最多的 Queue 里面都用offer,会有返回值知道结果。peek 的概念是去取,但并不会 remove 掉,poll是取并且 remove 掉,而且这几个对于BlockingQueue 来说也确实是线程安全的操作。
BlockingQueue 在 Queue的基础上又添加了两个方法:put,take。这两个方法是真真正正的实现了阻塞。pu t往里装,如果满了的话这个线程会阻塞住;take往外取,如果空了的话线程会阻塞住。所以,BlockingQueue 天生就实现了生产者与消费者容器模型。
LinkedBlockingQueue
LinkedBlockingQueue,体现Concurrent的这个点在哪里呢,它是用链表实现的BlockingQueue,是一个无界队列,可以一直装到内存满了为止。
public class T05_LinkedBlockingQueue {
static BlockingQueue<String> strs = new LinkedBlockingQueue<>();
static Random r = new Random();
public static void main(String[] args) {
new Thread(() -> {
for (int i = 0; i < 100; i++) {
try {
strs.put("a" + i); //如果满了,就会等待
TimeUnit.MILLISECONDS.sleep(r.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "p1").start();
for (int i = 0; i < 5; i++) {
new Thread(() -> {
for (;;) {
try {
System.out.println(Thread.currentThread().getName() + " take -" + strs.take()); //如果空了,就会等待
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "c" + i).start();
}
}
}在这段代码里,第1个线程是往 LinkedBlockingQueue 里 put 了100个字符串,a 开头 i 结尾,每put 一个的时候睡 1 秒钟。然后又起了 5 个线程不断的从里面 take,空了就阻塞等待,什么时候有了就再取出来。
ArrayBlockingQueue
ArrayBlockingQueue是有界的,可以指定一个固定的值10,这个容器的容量就是10。当往容器中装东西的时候,一旦容器满了put方法就会阻塞住,此时再调用add方法就会报异常。可以使用offer方法的返回值来判断到底加没加成功,offer还有另外一个写法,可以指定一个时间尝试着往里面加1秒钟,1秒钟之后如果加不进去就返回。
public class T06_ArrayBlockingQueue {
static BlockingQueue<String> strs = new ArrayBlockingQueue<>(10);
static Random r = new Random();
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < 10; i++) {
strs.put("a" + i);
}
// strs.put("aaa");
// strs.add("aaa");
// strs.offer("aaa");
strs.offer("aaa", 1, TimeUnit.SECONDS);
System.out.println(strs);
}
}DelayQueue
DelayQueue可以实现在时间上的排序,在Queue中的任务会按照自身设定的等待时间进行排序。
public class T07_DelayQueue {
static BlockingQueue<MyTask> tasks = new DelayQueue<>();
static Random r = new Random();
static class MyTask implements Delayed {
String name;
long runningTime;
MyTask(String name, long rt) {
this.name = name;
this.runningTime = rt;
}
@Override
public int compareTo(Delayed o) {
if (this.getDelay(TimeUnit.MILLISECONDS) < o.getDelay(TimeUnit.MILLISECONDS))
return -1;
else if (this.getDelay(TimeUnit.MILLISECONDS) > o.getDelay(TimeUnit.MILLISECONDS))
return 1;
else
return 0;
}
@Override
public long getDelay(TimeUnit unit) {
return unit.convert(runningTime - System.currentTimeMillis(), TimeUnit.MILLISECONDS);
}
@Override
public String toString() {
return name + " " + runningTime;
}
}
public static void main(String[] args) throws InterruptedException {
long now = System.currentTimeMillis();
MyTask t1 = new MyTask("t1", now + 1000);
MyTask t2 = new MyTask("t2", now + 2000);
MyTask t3 = new MyTask("t3", now + 1500);
MyTask t4 = new MyTask("t4", now + 2500);
MyTask t5 = new MyTask("t5", now + 500);
tasks.put(t1);
tasks.put(t2);
tasks.put(t3);
tasks.put(t4);
tasks.put(t5);
System.out.println(tasks);
for (int i = 0; i < 5; i++) {
System.out.println(tasks.take());
}
}
}DelayQueue也是BlockingQueue的一种,用于阻塞的队列。这个阻塞队列装任务的时候要求任务类必须实现Delayed接口,Delayed中需要做一个比较的方法compareTo,队列中时间等待越短的就会优先得到运行。所以需要通过compareTo做一个比较 ,这样就会有一个排序规则。
实现Comparable接口重写 compareTo方法来确定你这个任务之间是怎么排序的。通过getDelay取值得出Delay多长时间。往里头装任务的时候首先拿到当前时间,在当前时间的基础之上指定在多长时间之后这个任务要运行。一般的队列是先进先出,这个是按时间进行排序,也就是按紧迫程度进行排序。使用场景上可以按照时间进行任务调度,本质上是一个PriorityQueque。
PriorityQueue
DelayQueue本质上用的是一个PriorityQueue,PriorityQueue是从AbstractQueue继承的。PriorityQueue特点是它内部往里装的时候并不是按顺序往里装的,而是内部进行了一个排序。按照优先级,最小的优先。内部的实现结构是一个二叉树,这个二叉树可以认为是堆排序里面的那个最小堆值排在最上面。
public class T07_01_PriorityQueque {
public static void main(String[] args) {
PriorityQueue<String> q = new PriorityQueue<>();
q.add("c");
q.add("e");
q.add("a");
q.add("d");
q.add("z");
for (int i = 0; i < 5; i++) {
System.out.println(q.poll());
}
}
}SynchronousQueue
SynchronousQueue容量为0,意思就是这是一个不能装东西的容器。SynchronousQueue是专门用来两个线程之间传内容,给线程下达任务。之前有介绍过一个容器叫Exchanger,本质上这俩容器的概念是一样的。
public class T08_SynchronusQueue {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> strs = new SynchronousQueue<>();
new Thread(() -> {
try {
System.out.println(strs.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}).start();
// strs.add("aaa");
strs.put("aaa");
System.out.println(strs.size());
}
}在上面这段代码中,起了一个线程等着take,Queue里面没有值一定是take不到,就会一直阻塞等着。当主线程put之后就可以取出来。take到了值之后就可以打印出来。最后这个容器的size一定是0,打印出aaa来这个没问题。
当把主线程的put注释掉,起的线程就会在这阻塞永远等着。如果调用add方法直接就报错,原因是满了。本身这个容器为的空间就是0,不可以往里面装东西。SynchronousQueue和其它的Queue很重要的区别就是不能往里头装东西,只能用来阻塞式的put调用,要求是前面得有线程等着拿这个东西,然后才可以往里装。但容量为0,说白了就是要递到另外一个的手里才可以。
这个SynchronousQueue看似没有用,其实不然,SynchronousQueue在线程池里用处特别大,很多的线程取任务,互相之间进行任务的一个调度的时候用的都是它。
TransferQueue
Transfer意思是传递,实际上是前面各种各样Queue的一个组合,它可以给线程间来传递数据,但相较于SynchronousQueue的只能传递一个,TransferQueue做成列表可以传好多个。而且它添加了一个方法叫transfer,如果用put就相当于一个线程来了往里一装它就走了,但transfer就是装完在这等着,阻塞等线程来把它取走再回去干它自己的事情。譬如一个订单等付账完成了之后,才可以给客户反馈。
public class T09_TransferQueue {
public static void main(String[] args) throws InterruptedException {
LinkedTransferQueue<String> strs = new LinkedTransferQueue<>();
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " - " + strs.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "AssistantThread1").start();
strs.transfer("aaa");
/*strs.put("aaa");*/
/*new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + " - " + strs.take());
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "AssistantThread2").start();*/
}
}CopyOnWrite
CopyOnWrite 的意思叫写时复制,是一个在并发的时候经常使用的一个类,分为CopyOnWriteList、CopyOnWriteSet。
public class T02_CopyOnWriteList {
public static void main(String[] args) {
List<String> lists =
// new ArrayList<>(); //这个会出并发问题!
// new Vector();
new CopyOnWriteArrayList<>();
Random r = new Random();
Thread[] ths = new Thread[100];
for(int i=0; i<ths.length; i++) {
Runnable task = new Runnable() {
@Override
public void run() {
for(int i=0; i<1000; i++) lists.add("a" + r.nextInt(10000));
}
};
ths[i] = new Thread(task);
}
runAndComputeTime(ths);
System.out.println(lists.size());
}
static void runAndComputeTime(Thread[] ths) {
long s1 = System.currentTimeMillis();
Arrays.asList(ths).forEach(t -> t.start());
Arrays.asList(ths).forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
long s2 = System.currentTimeMillis();
System.out.println(s2 - s1);
}
}这段代码里用了一个List容器,一个一个元素往里装。可以用ArrayList、Vector。但是ArrayList会出并发问题,因为多线程访问没有锁,这时可以用CopyOnWriteArrayList。这个CopyOnWrite解释一下,看这个名字就知道,写的时候进行复制。原理非常简单,需要往里面加元素的时候,把里面的元素先复制出来。在很多情况下,写其实比较少,读的操作反而很多。在这个时候就可以考虑CopyOnWrite这种方式来提高效率,因为写的时候不加锁。Vector写的时候也加锁,读的时候也加锁。而CopyOnWriteList在读的时候不加锁,写的时候会在原来的基础上拷贝一个,拷贝的时候扩展出一个新元素来,然后把新添加的元素扔到最后位置,于此同时把指向老的容器的一个引用指向新的,这个写法就是写时复制。这里只是演示了一个写线程,没有模拟读线程,CopyOnWrite写的效率比较低,因为每次写都要复制。
9、经久不衰的问题-生产者与消费者
这是华为的一道面试题,原题只是一道填空题,后来很多公司开始考这道题:两个线程,第一个线程是从1到26,第二个线程是从A到一直到Z,让这两个线程做到同时运行,交替输出,顺序打印。最终打印结果是A1B2C3.....Z26,或者1A2B3C......26Z。
LockSupport解法
用LockSupport其实是最简单的:让一个线程输出完了之后停止,然后让另外一个线程输出完了之后停止,两个线程交替运行就算完事儿。
public class T02_00_LockSupport {
static Thread t1 = null, t2 = null;
public static void main(String[] args) throws Exception {
char[] aI = "1234567".toCharArray();
char[] aC = "ABCDEFG".toCharArray();
t1 = new Thread(() -> {
for(char c : aI) {
System.out.print(c);
LockSupport.unpark(t2); // 叫醒T2
LockSupport.park(); // T1阻塞
}
}, "t1");
t2 = new Thread(() -> {
for(char c : aC) {
LockSupport.park(); // t2阻塞
System.out.print(c);
LockSupport.unpark(t1); // 叫醒t1
}
}, "t2");
t1.start();
t2.start();
}
}定义两个数组,两个线程。第一个线程拿出数组里面的每一个数字来打印,打印完叫醒t2,然后自己阻塞。另外一个线程上来之后自己先park,打印完叫醒线程t1。两个线程就这么交替来交替去就搞定。
synchronized解法
首先调用wait和notify的时候,wait线程阻塞,notify叫醒其他线程。调用这两个方法的时候必须要进行synchronized锁定。定义一个锁的对象new Object(),第一线程上来先锁定,锁定完后开始输出,输出第一个数字完之后叫醒第二个,然后自己wait。思路其实一样,其实这个和LookSupport的park、unpark是非常类似的,这里面最容易出错的就是把整个数组都打印完了要记得notify,因为这两个线程里面终归最后有一个线程在wait阻塞停止不动。
public class T06_00_sync_wait_notify {
public static void main(String[] args) {
final Object o = new Object();
char[] aI = "1234567".toCharArray();
char[] aC = "ABCDEFG".toCharArray();
new Thread(() -> {
synchronized (o) {
for(char c : aI) {
System.out.print(c);
try {
o.notify();
o.wait(); //让出锁
} catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify(); //必须,否则无法停止程序
}
}, "t1").start();
new Thread(() -> {
synchronized (o) {
for(char c : aC) {
System.out.print(c);
try {
o.notify();
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t2").start();
}
}如果要保证t2在t1之前打印,也就是说保证首先输出的是A而不是1,就得保证第一个线程先运行,办法也是非常多。可以使用自旋的方式,设置一个boolean类型的变量,t2刚开始不是true。如果说t2没有true的话,t1线程就wait,要求t2必须先true才能执行。还有一种写法就是t2先wait,然后t1先输出,输出完了之后notify;还有一种写法用CountDownLatch也可以。
public class T07_00_sync_wait_notify {
private static volatile boolean t2Started = false;
// private static CountDownLatch latch = new C(1);
public static void main(String[] args) {
final Object o = new Object();
char[] aI = "1234567".toCharArray();
char[] aC = "ABCDEFG".toCharArray();
new Thread(()->{
// latch.await();
synchronized (o) {
while(!t2Started) {
try {
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
for(char c : aI) {
System.out.print(c);
try {
o.notify();
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t1").start();
new Thread(()->{
synchronized (o) {
for(char c : aC) {
System.out.print(c);
// latch.countDown()
t2Started = true;
try {
o.notify();
o.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
o.notify();
}
}, "t2").start();
}
}ReentrantLock解法
用一个ReentrantLock,调用它的newCondition,上来之后先lock相当于synchronized上锁,打印完之后signal叫醒另一个当前的等待,最后condition.signal()相当于notify(),这种写法相当于synchronized的一个变种。
public class T08_00_lock_condition {
public static void main(String[] args) {
char[] aI = "1234567".toCharArray();
char[] aC = "ABCDEFG".toCharArray();
Lock lock = new ReentrantLock();
Condition condition = lock.newCondition();
new Thread(() -> {
try {
lock.lock();
for(char c : aI) {
System.out.print(c);
condition.signal();
condition.await();
}
condition.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}, "t1").start();
new Thread(()->{
try {
lock.lock();
for(char c : aC) {
System.out.print(c);
condition.signal();
condition.await();
}
condition.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}, "t2").start();
}
}但是能写出两个Condition的情况就会好很多。在一把锁的等待队列里有好多线程,这时去notify的话实际上要找出一个让它运行。如果要notifyAll的话,是让所有线程都醒过来去争用这把锁看谁能抢的到,谁抢到了就让这个线程运行。但是这里不能去要求哪一类或者哪一个线程单独醒过来,完全可以来两种的Condition,Condition本质上是一个等待队列 ,其中一个线程在这个等待队列上,另一个线程在另外一个等待队列上。
public class T09_00_lock_condition {
public static void main(String[] args) {
char[] aI = "1234567".toCharArray();
char[] aC = "ABCDEFG".toCharArray();
Lock lock = new ReentrantLock();
Condition conditionT1 = lock.newCondition();
Condition conditionT2 = lock.newCondition();
new Thread(() -> {
try {
lock.lock();
for(char c : aI) {
System.out.print(c);
conditionT2.signal();
conditionT1.await();
}
conditionT2.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}, "t1").start();
new Thread(() -> {
try {
lock.lock();
for(char c : aC) {
System.out.print(c);
conditionT1.signal();
conditionT2.await();
}
conditionT1.signal();
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}, "t2").start();
}
}如果说用两个Condition就可以精确的指定某个等待队列里的线程醒过来去执行任务。第一线程conditionT2.signal(),叫醒第二个里面的线程,然后第一个线程让它等待,第二个就是叫醒第一个线程,第二个放到这个等待队列里。相当于放了两个等待队列,t1在这个等待队列里,t2在另一个等待队列里,在t1完成了之后叫醒t2,指定这个队列的线程醒过来。
CAS自旋式解法
在这里用一个自旋式的写法,就是没有锁,使用CAS的写法,这个写法用了enum。最终哪个线程要运行只能取两个值,T1和T2。定义了一个ReadyToRun的变量,刚开始的时候是T1,类似于定义一个信号灯,这个信号灯要么就是T1要么就是T2,只能取这个两个值不能取别的。
public class T03_00_cas {
enum ReadyToRun {T1, T2}
static volatile ReadyToRun r = ReadyToRun.T1;
public static void main(String[] args) {
char[] aI = "1234567".toCharArray();
char[] aC = "ABCDEFG".toCharArray();
new Thread(() -> {
for (char c : aI) {
while (r != ReadyToRun.T1) {}
System.out.print(c);
r = ReadyToRun.T2;
}
}, "t1").start();
new Thread(() -> {
for (char c : aC) {
while (r != ReadyToRun.T2) {}
System.out.print(c);
r = ReadyToRun.T1;
}
}, "t2").start();
}
}开始的时候这个信号灯上显示的是T1,就可以走一步。首先判断是不是T1啊,如果不是就占用CPU在这循环等待,如果是T1就打印,然后把r值变成T2进行下一次循环。下一次循环上来之后判断这个r是不是T1,不是T1就有在这转圈玩儿,而第二个线程发现它变成T2了,变成T2了下面的线程就会打印A,打印完了之后又把这个r变成了T1,就这么交替交替。写volatile是保证线程的可见性,用enum类型,就是防止它取别的值,用一个int类型或者布尔也都可以。
再来看一个BlockingQueue的玩法,BlockingQueue可以支持多线程的阻塞操作,put的时候满了就会阻塞住,take的时候如果没有也会阻塞住。利用这个特点来了两个BlockingQueue,这两个BlockingQueue都是ArrayBlockingQueue数组实现。但是数组的长度是1,相当于用了两个容器,这两个容器里头放两个值,第一个线程打印出1来了就在这边放一个,我这边OK了,该你了;而另外一个线程一直盯着这个事,它就去take,take里面没有值的时候在这里阻塞等待,等什么时候这边打印完了,take到了就打印这个A,打印完了A之后就往第二个里面放一个OK,第一个线程也去take第二个容器里面的OK,什么时候take到了就接着往下打印。
public class T04_00_BlockingQueue {
static BlockingQueue<String> q1 = new ArrayBlockingQueue(1);
static BlockingQueue<String> q2 = new ArrayBlockingQueue(1);
public static void main(String[] args) throws Exception {
char[] aI = "1234567".toCharArray();
char[] aC = "ABCDEFG".toCharArray();
new Thread(() -> {
for(char c : aI) {
System.out.print(c);
try {
q1.put("ok");
q2.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t1").start();
new Thread(() -> {
for(char c : aC) {
try {
q1.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.print(c);
try {
q2.put("ok");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "t2").start();
}
}其实使用这种实现,执行起来效率非常低,它里面有各种各样的同步判断,了解一下就可以了,基本上正常写代码也不会用这种写法。
TransferQueue解法
使用TransferQueue来解决这个问题,第一个线程上来先take,相当于它先做消费者,就在这个Queue里等着,看看有没有其它线程往里扔。第二个线程先transfer,直接将A扔进去。第一个线程就把这个拿出来打印,打印完之后又进行transfer,将1扔进去。第二个线程 take出来1进行打印。这个写法相当于两个线程将自己的一个数字或者是字母交到一个队列里让对方去打印。
public class T13_TransferQueue {
public static void main(String[] args) {
char[] aI = "1234567".toCharArray();
char[] aC = "ABCDEFG".toCharArray();
TransferQueue<Character> queue = new LinkedTransferQueue<Character>();
new Thread(() -> {
try {
for (char c : aI) {
System.out.print(queue.take());
queue.transfer(c);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t1").start();
new Thread(()->{
try {
for (char c : aC) {
queue.transfer(c);
System.out.print(queue.take());
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "t2").start();
}
}PipedStream解法
PipedInputStream和一个PipedOutputStream配合使用,相当于两个线程间通信,一个线程有一个OutputStream,对应另一个线程有一个InputStream;同样的第二个线程要往第一个线程写的话,第一个线程也得有一个InputStream,第二个线程也还得有一个OutputStream。最后要求第一个线程的input1和第二个线程的output2连接connect起来,互相之间传递消息,这边搞定了告诉另一边儿,另一边儿搞定了告诉这边,回合制。
public class T10_00_PipedStream {
public static void main(String[] args) throws Exception {
char[] aI = "1234567".toCharArray();
char[] aC = "ABCDEFG".toCharArray();
PipedInputStream input1 = new PipedInputStream();
PipedInputStream input2 = new PipedInputStream();
PipedOutputStream output1 = new PipedOutputStream();
PipedOutputStream output2 = new PipedOutputStream();
input1.connect(output2);
input2.connect(output1);
String msg = "Your Turn";
new Thread(() -> {
byte[] buffer = new byte[9];
try {
for(char c : aI) {
input1.read(buffer);
if(new String(buffer).equals(msg)) {
System.out.print(c);
}
output1.write(msg.getBytes());
}
} catch (IOException e) {
e.printStackTrace();
}
}, "t1").start();
new Thread(() -> {
byte[] buffer = new byte[9];
try {
for(char c : aC) {
System.out.print(c);
output2.write(msg.getBytes());
input2.read(buffer);
if(new String(buffer).equals(msg)) {
continue;
}
}
} catch (IOException e) {
e.printStackTrace();
}
}, "t2").start();
}
}10、线程池
说到线程池,核心接口是Executor接口,里面只定义了一个execute方法。ExecutorService接口继承了Executor接口,AbstractExecutorService抽象类实现ExecutorService接口,最后ThreadPoolExecutor继承AbstractExecutorService类真正实现类线程池的各种使用。
Executor
* The {@code Executor} implementations provided in this package
* implement {@link ExecutorService}, which is a more extensive
* interface. The {@link ThreadPoolExecutor} class provides an
* extensible thread pool implementation. The {@link Executors} class
* provides convenient factory methods for these Executors.
*
* <p>Memory consistency effects: Actions in a thread prior to
* submitting a {@code Runnable} object to an {@code Executor}
* <a href="package-summary.html#MemoryVisibility"><i>happen-before</i></a>
* its execution begins, perhaps in another thread.
*
* @since 1.5
* @author Doug Lea
*/
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}Executor,顾名思义执行者,只定义了一个execute执行方法,传入的参数也就是执行的东西是Runnable,它是一个接口,可以有无数的实现。没有线程池的时候,想起一个线程只能new一个Thread然后去重写它的Run方法.start才可以运行。就算是写了一个Runnable也必须得new一个Thread出来,这种定义和运行是固定的。虽然说现在还是需要去new一个Thread,但是不用亲自去指定每一个Thread,它的运行的方式可以去自定义,至于怎么去定义的就看怎么实现Executor的接口。
ExecutorService
ExecutorService又是什么意思呢,它是从Executor继承,不仅实现了Executor可以去执行一个任务之外,还完善了整个任务执行器的一个生命周期。就拿线程池来举栗子,一个线程池里面一堆的线程,当执行完一个任务之后该线程怎么结束,线程池定义了这样一些个方法:
结束:void shutdown();
立刻结束:List<Runnable> shutdownNow();
是否结束:boolean isShutdown();
是不是整体都执行完毕:boolean isTerminated();
等着结束,等多长时间,时间到了还不结束的话他就返回false:
boolean awaitTermination(long timeout, TimeUnit unit) throws InterruptedException;
ExecutorService定义了一些个线程的线程池的生命周期的东西,扩展了Executor接口,真正的线程池的接口是在ExecutorService的这个基础上来实现。ExecutorService还定义了submit接口用于提交任务,执行任务是直接拿过来马上运行,而submit提交任务是扔给线程池。什么时候运行由线程池来决定,相当于是异步执行,线程只要往线程池中一扔就不管了。既然都不用管了什么时候给个运行的结果呢,这里面就涉及了比较新的类:比如说Future、RunnableFuture、FutureTask.....所以在这里要拓展一些线程的基础的概念,早期定义一个线程的任务只能去实现Runnable接口,JDK1.5之后增加了Callable这个接口。
Callable
看一下Callable的文档,这个接口和java.lang.Runnable类似,那为什么有了Runnable还要有Callable,因为Callable有一个返回值,call这个方法相当与Runnable里面的run方法,而Runnable里的方法没有返回值。当一个线程执行一个计算任务,最后得返回一个结果,这个叫Callable,把返回的结果存储起来,计算完了通知就可以,不需要像原来线程池中调用run方法阻塞等待着。所以有了这个Callable之后就有了很多种新鲜的玩法,Callable是什么,他类似于Runnable,不过Callable可以有返回值。
/**
* A task that returns a result and may throw an exception.
* Implementors define a single method with no arguments called
* {@code call}.
*
* <p>The {@code Callable} interface is similar to {@link
* java.lang.Runnable}, in that both are designed for classes whose
* instances are potentially executed by another thread. A
* {@code Runnable}, however, does not return a result and cannot
* throw a checked exception.
*
* <p>The {@link Executors} class contains utility methods to
* convert from other common forms to {@code Callable} classes.
*
* @see Executor
* @since 1.5
* @author Doug Lea
* @param <V> the result type of method {@code call}
*/
@FunctionalInterface
public interface Callable<V> {
/**
* Computes a result, or throws an exception if unable to do so.
*
* @return computed result
* @throws Exception if unable to compute a result
*/
V call() throws Exception;
}Future
再来看一个接口Future,当Callable被执行完了之后结果会封装到Future里面。Future的意思是未来。未来任务执行完之后可以把结果放到这里面,所以Future代表的是未来执行完的一个结果。
public class T06_00_Future {
public static void main(String[] args) throws InterruptedException, ExecutionException {
FutureTask<Integer> task = new FutureTask<>(() -> {
TimeUnit.MILLISECONDS.sleep(500);
return 1000;
});
new Thread(task).start();
System.out.println(task.get());
}
}其实更灵活的一个用法是FutureTask,即是一个Future同时又是一个Task,Callable只能执行一个任务,不能作为一个Future来用。这个FutureTask相当于自身可以作为一个任务来用,同时这个任务完成之后的结果也存在于这个对象里。FutureTask实现了RunnableFuture,而RunnableFuture既实现了Runnable又实现了Future,所以它即是一个任务又是一个Future。所以FutureTask是更好用的一个类,后面还会有WorkStealingPool、ForkJoinPool.....这些个基本上是会用到FutureTask类的。
CompletableFuture
了解了上面那些东西之后,可以介绍一个CompletableFuture。这玩意儿底层特别复杂,但是用法非常灵活,可以组合各种各样的不同的任务,然后等这些任务执行完产生一个结果进行一个组合,底层用的是ForkJoinPool。
举个栗子,用户网购买东西都会进行一个价格比较,而你这边提供了一个服务,就是到淘宝上去看看这个东西卖多少钱,然后我再另启动一个线程去京东上找这个东西卖多少钱,再启动一个线程去拼多多上找。最后汇总一下这三个地方各售卖的价格,然后用户再来选去哪里买。
public class T06_01_CompletableFuture {
public static void main(String[] args) throws ExecutionException, InterruptedException {
long start, end;
/*start = System.currentTimeMillis();
priceOfTM();
priceOfTB();
priceOfJD();
end = System.currentTimeMillis();
System.out.println("use serial method call! " + (end - start));*/
start = System.currentTimeMillis();
CompletableFuture<Double> futureTM = CompletableFuture.supplyAsync(()->priceOfTM());
CompletableFuture<Double> futureTB = CompletableFuture.supplyAsync(()->priceOfTB());
CompletableFuture<Double> futureJD = CompletableFuture.supplyAsync(()->priceOfJD());
CompletableFuture.allOf(futureTM, futureTB, futureJD).join();
CompletableFuture.supplyAsync(()->priceOfTM())
.thenApply(String::valueOf)
.thenApply(str-> "price " + str)
.thenAccept(System.out::println);
end = System.currentTimeMillis();
System.out.println("use completable future! " + (end - start));
try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}
private static double priceOfTM() {
delay();
return 1.00;
}
private static double priceOfTB() {
delay();
return 2.00;
}
private static double priceOfJD() {
delay();
return 3.00;
}
/*private static double priceOfAmazon() {
delay();
throw new RuntimeException("product not exist!");
}*/
private static void delay() {
int time = new Random().nextInt(500);
try {
TimeUnit.MILLISECONDS.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.printf("After %s sleep!\n", time);
}
}这段代码模拟了一个去别的地方取价格的一个方法,首先去别的地方访问会花好长时间,因此写了一个delay() 随机睡一段时间,表示要联网爬虫爬结果这个时间,打印了一下睡了多少时间之后才拿到结果的。如拿到天猫上的结果是1块钱,淘宝上结果是2块钱,京东上结果是3块钱,总而言之是经过网络爬虫爬过来的数据分析出来的多少钱。然后需要模拟一下怎么拿到怎么汇总,第一种写法就是注释的这种写法,就是挨着写,假设跑天猫跑了10秒,跑淘宝拍了10秒,跑京东跑了5秒,一共历时25秒才算出来。但是如果用不同的线程并行的执行,计算拢共花费的时间只有10秒。
ThreadPoolExecutor线程池核心参数
目前JDK提供了两种类型的线程池,ThreadPoolExecutor和ForkJoinPool,这两种是不同类型的线程池,干的事儿不一样。Fork意思是分,一个大的任务分开计算,最后的结果汇总这叫Join。很久以前那会儿计算机的算力还没有今天这么变态,NASA探索宇宙需要计算的数据实在是太多了,计算机算不过来,于是NASA把需要计算的气象或者宇宙中产生各种各样的数据进行一个分片,一大块儿数据分成一小片一小片的,向全球发出请求,利用别人计算机空余的时间来帮忙计算。这就是早期ForkJoinPool的一个雏形。
ThreadPoolExecutor继承了AbstractExecutorService,相当于线程池的执行器,就是往ThreadPoolExecutor里面扔任务,让ThreadPoolExecutor去运行,在阿里巴巴的研发手册中明确规定线程池一定要自定义,而定义一个线程池就要知道核心的7大参数:
1、corePoolSoze:线程池最开始被创建出之后里面的核心线程数;
2、maximumPoolSize:核心线程都被用完了之后,线程能扩展到最多的线程数是多少;
3、keepAliveTime:生存时间。意思是线程有多长时间没干活了请把它归还给操作系统;
4、unit:生存时间单位。TimeUnit中的变量,时、分、秒.....
5、workQueue:任务队列。就是之前提到的BlockingQueue,各种各样的BlockingQueue都可以往里面扔;
6、threadFactory:线程工厂。这个参数需要实现ThreadFactory接口,这个接口只有一个方法叫newThread,所以它的作用就只是产生线程。通过这种方式产生自定义的线程,默认产生的是defaultThreadFactory,而defaultThreadFactory产生线程的时候有几个特点。new出来的时候指定了group制定了线程名字,然后指定的这个线程绝对不是守护线程,设定好线程的优先级。自己可以定义产生的到底是什么样的线程,指定线程名叫什么;
7、handler:拒绝策略。当线程池中的线程已经被分配完了,此时来了新的任务已经没有可用使用的线程,就需要将这个任务给拒绝掉。至于怎么拒绝,这就是拒绝策略来指定。JDK默认提供了4种不同的拒绝策略,了解即可,实际开发中都是根据具体的业务情况自定义不同的拒绝策略。
这4种默认的拒绝策略分别是:
1、Abort:抛异常;
2、Discard:扔掉,不抛异常;
3、DiscardOldest:扔掉排队时间最久的;
4、CallerRuns:调用者处理服务;
public class T05_00_HelloThreadPool {
static class Task implements Runnable {
private int i;
public Task(int i) {
this.i = i;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Task " + i);
try {
System.in.read();
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return "Task{" +
"i=" + i +
'}';
}
}
public static void main(String[] args) {
ThreadPoolExecutor tpe = new ThreadPoolExecutor(2, 4, 60, TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(4),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 8; i++) {
tpe.execute(new Task(i));
}
System.out.println(tpe.getQueue());
tpe.execute(new Task(100));
System.out.println(tpe.getQueue());
tpe.shutdown();
}
}JDK提供的线程池
SingleThreadPool
看名字就知道这个线程池里面只有一个线程,只有一个线程的线程池可以保证扔进去的任务是顺序执行的。为什么会有单线程的线程池?其实作用还挺大,首先可以保证线程池是有任务队列的;其次,线程池可以帮助管理线程的生命周期。
public class T07_SingleThreadPool {
public static void main(String[] args) {
ExecutorService service = Executors.newSingleThreadExecutor();
for (int i = 0; i < 5; i++) {
final int j = i;
service.execute(() -> {
System.out.println(j + " " + Thread.currentThread().getName());
});
}
}
}CachedPool
从源码实际上看其实就是是new了一个ThreadPoolExecutor,没有设置核心线程,最大线程数可以达到整型最大值,然后60秒钟没有人理就会被回收,任务队列用的是SynchronousQueue,没有指定线程工厂,使用默认线程工厂,也没有指定拒绝策略,使用默认拒绝策略的。
/**
* Creates a thread pool that creates new threads as needed, but
* will reuse previously constructed threads when they are
* available. These pools will typically improve the performance
* of programs that execute many short-lived asynchronous tasks.
* Calls to {@code execute} will reuse previously constructed
* threads if available. If no existing thread is available, a new
* thread will be created and added to the pool. Threads that have
* not been used for sixty seconds are terminated and removed from
* the cache. Thus, a pool that remains idle for long enough will
* not consume any resources. Note that pools with similar
* properties but different details (for example, timeout parameters)
* may be created using {@link ThreadPoolExecutor} constructors.
*
* @return the newly created thread pool
*/
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}可以看出CachedThreadPool的特点,就是来一个任务起一个线程,当然前提是线程池里面有线程存在而且还没有到达60秒钟的回收时间。如果有线程存在,就用现有的线程池,但是在有新的任务来的时候,如果其他线程忙就起一个新的。分析一下这个CachedThreadPool,用的任务队列是synchronousQueue,它是一个手递手容量为空的Queue,就是来一个东西必须得有一个线程把这个东西拿走,不然提交任务的线程从这阻塞住了。synchronousQueue还可以扩展为多个线程的手递手,多个生产者多个消费者都需要手递手叫TransferQueue。这个CachedThreadPool就是这样一个线程池,来一个新的任务就必须马上执行,没有线程空着就new一个线程。生产环境是不会推荐使用这种线程池,原因是线程会启动的特别多,基本接近于没有上限的。
public class T08_CachedPool {
public static void main(String[] args) throws InterruptedException {
ExecutorService service = Executors.newCachedThreadPool();
System.out.println(service);
for (int i = 0; i < 2; i++) {
service.execute(() -> {
try {
TimeUnit.MILLISECONDS.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
});
}
System.out.println(service);
TimeUnit.SECONDS.sleep(80);
System.out.println(service);
}
}
FixedThreadPool
fixed的意思是固定的,就是固定的一个线程数,FixedThreadPool指定一个参数,到底有多少个线程,核心线程和最大线程都是固定的,因为最大线程和核心线程都是固定的就没有回收之说。所以给指定成0,这里用的是LinkedBlockingQueue。
public class T09_FixedThreadPool {
public static void main(String[] args) throws InterruptedException, ExecutionException {
long start = System.currentTimeMillis();
getPrime(1, 200000);
long end = System.currentTimeMillis();
System.out.println(end - start);
final int cpuCoreNum = 4;
ExecutorService service = Executors.newFixedThreadPool(cpuCoreNum);
MyTask t1 = new MyTask(1, 80000); //1-5 5-10 10-15 15-20
MyTask t2 = new MyTask(80001, 130000);
MyTask t3 = new MyTask(130001, 170000);
MyTask t4 = new MyTask(170001, 200000);
Future<List<Integer>> f1 = service.submit(t1);
Future<List<Integer>> f2 = service.submit(t2);
Future<List<Integer>> f3 = service.submit(t3);
Future<List<Integer>> f4 = service.submit(t4);
start = System.currentTimeMillis();
f1.get();
f2.get();
f3.get();
f4.get();
end = System.currentTimeMillis();
System.out.println(end - start);
}
static class MyTask implements Callable<List<Integer>> {
int startPos, endPos;
MyTask(int s, int e) {
this.startPos = s;
this.endPos = e;
}
@Override
public List<Integer> call() throws Exception {
List<Integer> r = getPrime(startPos, endPos);
return r;
}
}
static boolean isPrime(int num) {
for (int i = 2; i <= num / 2; i++) {
if (num % i == 0) return false;
}
return true;
}
static List<Integer> getPrime(int start, int end) {
List<Integer> results = new ArrayList<>();
for (int i = start; i <= end; i++) {
if (isPrime(i)) results.add(i);
}
return results;
}
}看一下上面这个FixedThreadPool的小例子,用一个固定的线程池有一个好处就是可以进行并行的计算。FixedThreadPool是确实可以让任务来并行处理,从而真真正正的提高效率。方法isPrime判断一个数是不是质数,然后写了另外一个getPrime方法,指定一个起始的位置,一个结束的位置。将中间的质数拿出来一部分,主要是为了把任务给切分开。计算从1一直到200000这么一些数里面有多少个数是质数。在启动了一个固定大小的线程池,然后在分别来计算,分别把不同的阶段交给不同的任务,扔进去submit是异步的,拿到get的时候才知道里面到底有多少个,全部get完了之后相当于所有的线程都知道结果了,最后计算一下时间,用这两种计算方式就能比较出来到底是并行的方式快还是串行的方式快。
ScheduledPool
ScheduledPool是定时任务线程池,隔一段时间之后这个任务会执行。从源码可以看出,new一个ScheduledThreadPool的时候返回的是ScheduledThreadPoolExecutor,然后在ScheduledThreadPoolExecutor里面调用了super,它的super又是ThreadPoolExecutor,它本质上还是ThreadPoolExecutor,所以并不是别的,参数还是ThreadPool的7个参数,这是专门给定时任务用的这样的一个线程池。
/**
* Creates a new {@code ScheduledThreadPoolExecutor} with the
* given core pool size.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @throws IllegalArgumentException if {@code corePoolSize < 0}
*/
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}其实它这里面有一些好用的方法,比如:scheduleAtFixedRate,间隔多长时间在一个固定的频率上来执行一次这个任务,可以通过这样的方式灵活的对于时间上的一个控制,第一个参数(Delay)第一个任务执行之前需要往后面推多长时间;第二个(period)间隔多长时间;第三个参数是时间单位;
public class T10_ScheduledPool {
public static void main(String[] args) {
ScheduledExecutorService service = Executors.newScheduledThreadPool(4);
service.scheduleAtFixedRate(() -> {
try {
TimeUnit.MILLISECONDS.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName());
}, 0, 500, TimeUnit.MILLISECONDS);
}
}ForkJoinPool
ForkJoinPool这种线程池,适合把大任务切分成一个一个的小任务去运行,小任务还是觉得比较大,再切,不一定是两个,也可以切成三个四个。切完这个任务执行完了要进行一个汇总。当然也不是所有的子任务都需要返回值的,只不过大多数情况是需要进行一个结果的汇总,子任务汇总到父任务,父任务最终汇总到根任务,最后就得到了所有的结果,这个过程叫join,因此这个线程池就叫做ForkJoinPool。
原来定义任务的时候是从Runnable来继承,而在实现ForkJoinPool的时候需要定义成为特定的类型 ,类型必须得能进行分叉的任务,所以得是一种特殊类型的任务ForkJoinTask,但是实际当中这个ForkJoinTask比较原始,可以用RecursiveAction。第一种叫RecursiveAction递归,为什么叫递归,是因为我们大任务可以切成小任务,小任务还可以切成小任务,一直可以切到满足条件为止,这其中隐含了一个递归的过程,因此叫RecursiveAction,是不带返回值的任务。
public class T12_ForkJoinPool {
static int[] nums = new int[1000000];
static final int MAX_NUM = 50000;
static Random r = new Random();
static {
for (int i = 0; i < nums.length; i++) {
nums[i] = r.nextInt(100);
}
System.out.println("---" + Arrays.stream(nums).sum()); // stream api
}
static class AddTask extends RecursiveAction {
int start, end;
AddTask(int s, int e) {
start = s;
end = e;
}
@Override
protected void compute() {
if (end - start <= MAX_NUM) {
long sum = 0L;
for (int i = start; i < end; i++) sum += nums[i];
System.out.println("from:" + start + " to:" + end + " = " + sum);
} else {
int middle = start + (end - start) / 2;
AddTask subTask1 = new AddTask(start, middle);
AddTask subTask2 = new AddTask(middle, end);
subTask1.fork();
subTask2.fork();
}
}
}
static class AddTaskRet extends RecursiveTask<Long> {
private static final long serialVersionUID = 1L;
int start, end;
AddTaskRet(int s, int e) {
start = s;
end = e;
}
@Override
protected Long compute() {
if (end - start <= MAX_NUM) {
long sum = 0L;
for (int i = start; i < end; i++) {
sum += nums[i];
}
return sum;
}
int middle = start + (end - start) / 2;
AddTaskRet subTask1 = new AddTaskRet(start, middle);
AddTaskRet subTask2 = new AddTaskRet(middle, end);
subTask1.fork();
subTask2.fork();
return subTask1.join() + subTask2.join();
}
}
public static void main(String[] args) throws IOException {
/*ForkJoinPool fjp = new ForkJoinPool();
AddTask task = new AddTask(0, nums.length);
fjp.execute(task);*/
T12_ForkJoinPool temp = new T12_ForkJoinPool();
ForkJoinPool fjp = new ForkJoinPool();
AddTaskRet task = new AddTaskRet(0, nums.length);
fjp.execute(task);
long result = task.join();
System.out.println(result);
/*System.in.read();*/
}
}代码中new了一个数组,这个数组长度为100万,这个数组里面装了很多数,这些数都是通过Random来new出来的,下面要对一堆数进行总和的计算。如果用单线程来计算可以这样来计算:Arrays.stream(nums).sum() 搞定,这是单线程时间会比较长,可以进行多线程的计算,就像之前写过的FixedThreadPool,现在可以用ForkJoinPool来做计算,在计算的时候要去最小的任务片,这个数是不超过5万个数就不用再分了。RecursiveAction这个任务是用来做总和的,由于这里面是把数组进行了分片,所以定义了一个起始的位置和一个结束的位置,然后来进行compute。如果说这个数组里面的分片数量要比那个定义最小数量少。就直接进行计算就行,否则的话中间在砍掉一半,砍完了之后把当前任务在分成两个子任务,然后在让两个子任务进行分叉进行fork。这些任务有自己的一些特点,就是背后的后台线程 ,所以需要通过一个阻塞操作让当前的main函数不退出,不然的话它一退出所有线程全退出了,这个是叫做没有返回值的任务。
有返回值的任务可以从RecursiveTask继承,看AddTaskRet方法。
WorkStealingPool
这个WorkStealingPool是另外一种线程池,核心非常简单,每一个线程都有自己单独队列,所以任务不断往里扔的时候它会在每一个线程的队列上不断的累积,让某一个线程执行完自己的任务之后就回去另外一个线程上面偷,你给我一个拿来我用,所以这个叫WorkStealing。
那到底这种这种线程池的方式和之前介绍的共享同一个任务队列,本质上哪个更好呢?就原来这种方式如果有某一个线程被占了好长好长时间,然后这个任务特别重,一个特别大的任务,其他线程只能空着,没有办法帮到任务特别重的线程。但是这种就更加灵活一些,要是任务特别重的时候,有另外一个任务要清的,没关系可以分一点儿任务给其它线程。
public class T11_WorkStealingPool {
public static void main(String[] args) throws IOException {
ExecutorService service = Executors.newWorkStealingPool();
System.out.println(Runtime.getRuntime().availableProcessors());
service.execute(new R(1000));
service.execute(new R(2000));
service.execute(new R(2000));
service.execute(new R(2000)); //daemon
service.execute(new R(2000));
// 由于产生的是精灵线程(守护线程、后台线程),主线程不阻塞的话,看不到输出
System.in.read();
}
static class R implements Runnable {
int time;
R(int t) {
this.time = t;
}
@Override
public void run() {
try {
TimeUnit.MILLISECONDS.sleep(time);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(time + " " + Thread.currentThread().getName());
}
}
}看这个源码,实际上new了一个ForkJoinPool,所以本质上也是一个ForkJoinPool。
/**
* Creates a work-stealing thread pool using all
* {@link Runtime#availableProcessors available processors}
* as its target parallelism level.
* @return the newly created thread pool
* @see #newWorkStealingPool(int)
* @since 1.8
*/
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}自定义拒绝策略
拒绝策略自定义非常的简单,只要实现RejectedExecutionHandler接口,重写rejectedExecution方法即可。在rejectedExecution方法中实现具体的拒绝逻辑处理。
public class T14_MyRejectedHandler {
public static void main(String[] args) {
ExecutorService service = new ThreadPoolExecutor(4, 4,
0, TimeUnit.SECONDS, new ArrayBlockingQueue<>(6),
Executors.defaultThreadFactory(),
new MyHandler());
}
static class MyHandler implements RejectedExecutionHandler {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
// log("r rejected")
// save r kafka / mysql / redis
// try 3 times
if (executor.getQueue().size() < 10000) {
//try put again();
}
}
}
}