论文地址:https://arxiv.org/abs/2104.00298
官方代码:https://github.com/google/automl/tree/master/efficientnetv2
参考链接:https://blog.csdn.net/qq_37541097/article/details/116933569
代码参考链接:https://github.com/google/automl/tree/master/efficientnetv2
前言
之前,用pytorch搭建了EfficientnetV1的分类模型的训练流程搭建,可参考链接EfficientnetV1训练,本篇文章主要用于用pytorch搭建EfficientnetV2的网络结构,之后,将在此基础上完成训练框架的搭建。
一、EfficientnetV2
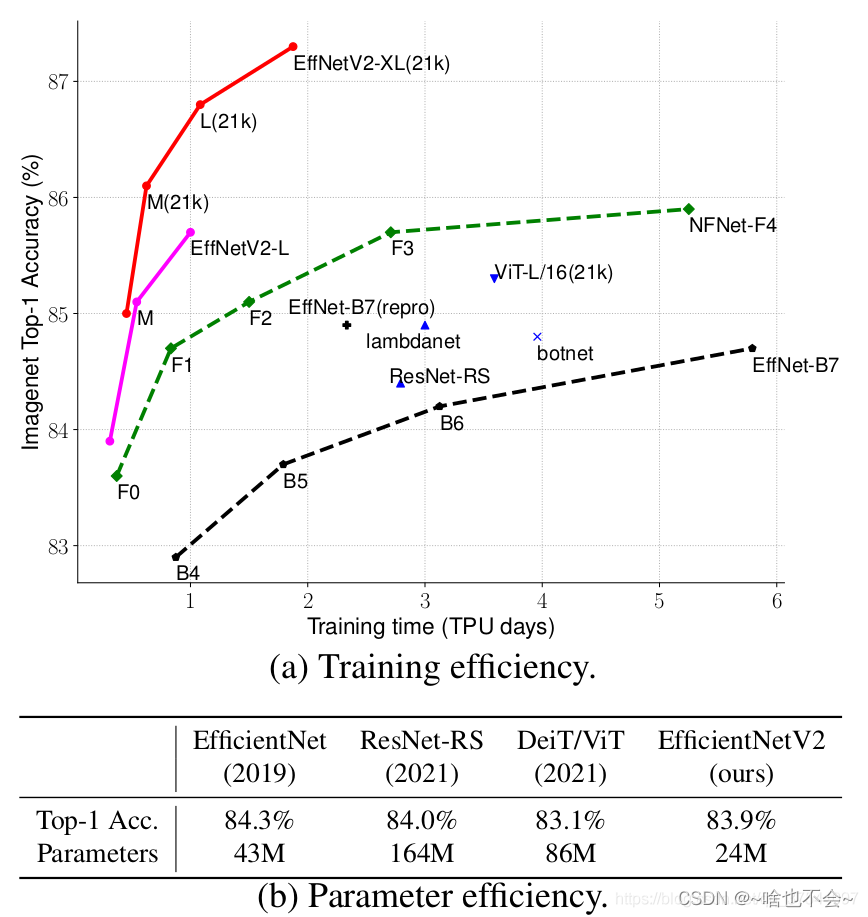
EfficientnetV1的效果是显而易见的,但是它关注的主要是准确率和参数量,而V2版本中把重心放在了训练和推理速度上。如图:
二、网络结构
EfficientnetV2有S、M、L、XL等版本,但是基本都是Fused_MBConv和MBConv的堆叠,这里我们仅展示论文中给出的S版本的结构图,如下:
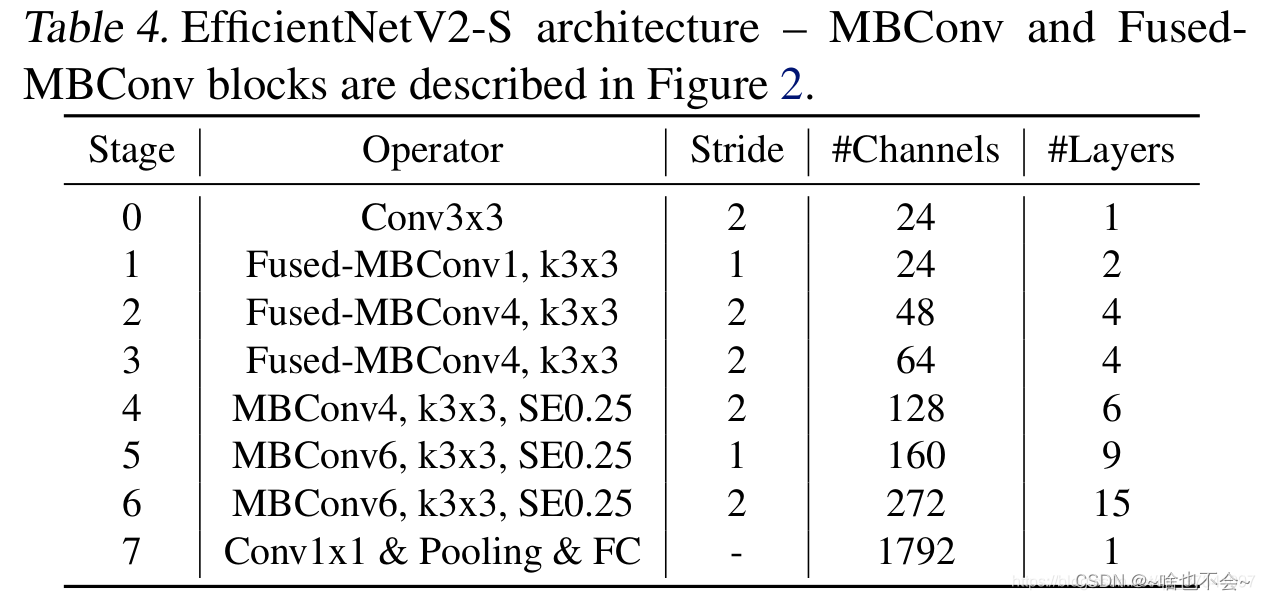
需要注意的是,这里面使用到得激活函数默认都是Silu,其余部分参数解释如下:
- k:卷积核大小
- stride:每个stage第一次出现的步长,除第一次外,其余的步长均为1。比如stage1里,会有2次Fused_MBConv堆叠,那么第一次的步长为2,第二次及其以后的步长为1.
- channels:输出通道数
- layers:堆叠次数
这里我们仅展示Fused_MBConv 和MBConv的代码,整体代码可以跳到三查看
1.Fused_MBConv
基本结构如下:
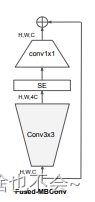
这里需要注意的是,虽然官方的结构图中有SE注意力机制,但是代码中并没有添加,所以这里也没有添加。代码如下:
#Fused_MBConv
class Fused_MBConv(nn.Module):
def __init__(self,in_ch,out_ch,k,s,drop_rate,expand=1):
'''
:param in_ch: 输入通道
:param out_ch: 输出通道
:param k: 卷积核大小
:param s: 步长
:param drop_rate: 神经元失活比例
:param expand: expand conv层的输出通道,注意,当expand=1时,没有expand conv
'''
super(Fused_MBConv, self).__init__()
self.expand,self.drop_rate=expand,drop_rate
expand_c = self.expand * in_ch
if self.expand==1:
self.pro_conv=Conv(in_ch,out_ch,k,s)
else:
self.expand_conv=Conv(in_ch,expand_c,k,s)
self.pro_conv=Conv(expand_c,out_ch,1,1,have_act=False) #这里没有激活函数
#当且仅当输入通道和输出通道相同时,并且s=1时才有shortcut
if in_ch==out_ch and s==1:
self.have_shortcut=True
else:
self.have_shortcut=False
#当且仅当shortcut为True并且drop_rote>0时使用dropout
if self.have_shortcut and self.drop_rate>0:
self.dropout=DropPath(drop_rate)
def forward(self,x):
if self.expand==1:
result=self.pro_conv(x)
else:
result=self.expand_conv(x)
result=self.pro_conv(result)
if self.have_shortcut:
#是否有dropout
if self.drop_rate>0:
result=self.dropout(result)
result+=x
return result
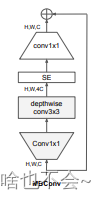
2.MBConv
基本结构如下:
代码如下:
#SE
class SE(nn.Module):
def __init__(self,in_ch,out_ch,se_rate):
'''
:param in_ch: 输入通道
:param out_ch: 输出通道
:param se_rate: SE比例
'''
super(SE, self).__init__()
squeeze_c=int(in_ch*se_rate)
self.conv1=nn.Conv2d(out_ch,squeeze_c,1)
self.act1=nn.SiLU()
self.conv2=nn.Conv2d(squeeze_c,out_ch,1)
self.act2=nn.Sigmoid()
def forward(self,x):
res=x.mean((2,3),keepdim=True)
res=self.act1(self.conv1(res))
res=self.act2(self.conv2(res))
return res*x
#MBConv
class MBConv(nn.Module):
def __init__(self,in_ch,out_ch,k,s,drop_rate,se_rate=0.25,expand=1,):
'''
:param in_ch: 输入通道
:param out_ch: 输出通道
:param k: 卷积核大小
:param s: 步长
:param drop_rate: 神经元失活比例
:param expand: expand conv层的输出通道,注意,当expand=1时,没有expand conv
:param se_rate: SE比例
'''
super(MBConv, self).__init__()
self.expand, self.drop_rate = expand, drop_rate
expand_c = self.expand * in_ch
self.expand_conv=Conv(in_ch,expand_c,1,1)
self.depwise_conv=Conv(expand_c,expand_c,k,s,expand_c)
#SE结构
self.se=SE(in_ch,expand_c,se_rate)
self.project_conv=Conv(expand_c,out_ch,1,1,1,False)
#dropout
# 当且仅当输入通道和输出通道相同时,并且s=1时才有shortcut
if in_ch == out_ch and s == 1:
self.have_shortcut = True
else:
self.have_shortcut = False
# 只有在使用shortcut连接时才使用dropout层
self.drop_rate = drop_rate
# 当且仅当shortcut为True并且drop_rote>0时使用dropout
if self.have_shortcut and self.drop_rate > 0:
self.dropout = DropPath(drop_rate)
def forward(self,x):
res=self.expand_conv(x)
res=self.depwise_conv(res)
res=self.se(res)
res=self.project_conv(res)
if self.have_shortcut:
#是否有dropout
if self.drop_rate>0:
res=self.dropout(res)
res+=x
return res
三、整体代码
这里的dropout代码直接用了参考代码里的函数,完整如下:
import torch.nn as nn
import torch
def drop_path(x, drop_prob: float = 0., training: bool = False):
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
#基本卷积块
class Conv(nn.Module):
def __init__(self,in_ch,out_ch,k,s,group=1,have_act=True):
'''
:param in_ch: 输入通道
:param out_ch: 输出通道
:param k: 卷积核大小
:param s: 步长
:param group: 按通道卷积
:param have_act: 是否有激活函数
:return:
'''
super(Conv, self).__init__()
self.conv=nn.Conv2d(in_ch,out_ch,k,s,padding=k//2,groups=group)
self.bn = nn.BatchNorm2d(out_ch, eps=1e-3, momentum=0.1)
if have_act:
self.act = nn.SiLU()
else:
self.act=nn.Identity()
def forward(sellf,x):
x=sellf.conv(x)
out=sellf.act(sellf.bn(x))
return out
#Fused_MBConv
class Fused_MBConv(nn.Module):
def __init__(self,in_ch,out_ch,k,s,drop_rate,expand=1):
'''
:param in_ch: 输入通道
:param out_ch: 输出通道
:param k: 卷积核大小
:param s: 步长
:param drop_rate: 神经元失活比例
:param expand: expand conv层的输出通道,注意,当expand=1时,没有expand conv
'''
super(Fused_MBConv, self).__init__()
self.expand,self.drop_rate=expand,drop_rate
expand_c = self.expand * in_ch
if self.expand==1:
self.pro_conv=Conv(in_ch,out_ch,k,s)
else:
self.expand_conv=Conv(in_ch,expand_c,k,s)
self.pro_conv=Conv(expand_c,out_ch,1,1,have_act=False) #这里没有激活函数
#当且仅当输入通道和输出通道相同时,并且s=1时才有shortcut
if in_ch==out_ch and s==1:
self.have_shortcut=True
else:
self.have_shortcut=False
#当且仅当shortcut为True并且drop_rote>0时使用dropout
if self.have_shortcut and self.drop_rate>0:
self.dropout=DropPath(drop_rate)
def forward(self,x):
# print(x.shape)
if self.expand==1:
result=self.pro_conv(x)
else:
result=self.expand_conv(x)
result=self.pro_conv(result)
if self.have_shortcut:
#是否有dropout
if self.drop_rate>0:
result=self.dropout(result)
result+=x
# print(result.shape)
return result
#SE
class SE(nn.Module):
def __init__(self,in_ch,out_ch,se_rate):
'''
:param in_ch: 输入通道
:param out_ch: 输出通道
:param se_rate: SE比例
'''
super(SE, self).__init__()
squeeze_c=int(in_ch*se_rate)
self.conv1=nn.Conv2d(out_ch,squeeze_c,1)
self.act1=nn.SiLU()
self.conv2=nn.Conv2d(squeeze_c,out_ch,1)
self.act2=nn.Sigmoid()
def forward(self,x):
res=x.mean((2,3),keepdim=True)
res=self.act1(self.conv1(res))
res=self.act2(self.conv2(res))
return res*x
#MBConv
class MBConv(nn.Module):
def __init__(self,in_ch,out_ch,k,s,drop_rate,se_rate=0.25,expand=1,):
'''
:param in_ch: 输入通道
:param out_ch: 输出通道
:param k: 卷积核大小
:param s: 步长
:param drop_rate: 神经元失活比例
:param expand: expand conv层的输出通道,注意,当expand=1时,没有expand conv
:param se_rate: SE比例
'''
super(MBConv, self).__init__()
self.expand, self.drop_rate = expand, drop_rate
expand_c = self.expand * in_ch
self.expand_conv=Conv(in_ch,expand_c,1,1)
self.depwise_conv=Conv(expand_c,expand_c,k,s,expand_c)
#SE结构
self.se=SE(in_ch,expand_c,se_rate)
self.project_conv=Conv(expand_c,out_ch,1,1,1,False)
#dropout
# 当且仅当输入通道和输出通道相同时,并且s=1时才有shortcut
if in_ch == out_ch and s == 1:
self.have_shortcut = True
else:
self.have_shortcut = False
# 只有在使用shortcut连接时才使用dropout层
self.drop_rate = drop_rate
# 当且仅当shortcut为True并且drop_rote>0时使用dropout
if self.have_shortcut and self.drop_rate > 0:
self.dropout = DropPath(drop_rate)
def forward(self,x):
res=self.expand_conv(x)
res=self.depwise_conv(res)
res=self.se(res)
res=self.project_conv(res)
if self.have_shortcut:
#是否有dropout
if self.drop_rate>0:
res=self.dropout(res)
res+=x
return res
class EfficientnetV2(nn.Module):
def __init__(self,model_type,class_num,drop_connect_rate=0.2,se_rate=0.25):
'''
:param model_type: 网络结构,可选s,m,l
:param class_num: 类倍数
:param drop_connect_rate: 最大的神经元失活比例
:param se_rate: SE结构中使用的节点比例
'''
super(EfficientnetV2, self).__init__()
self.class_num=class_num
#根据结构类型进行参数确定
if model_type=="S" or model_type=="s":
# [[每层重复的次数,该层对应的expand,k,s,in_ch,out_ch,conv_type]]
# conv_type为0表示Fused_MBConv,为1表示MBConv
repeat_expand_list=[[2,1,3,1,24,24,0],
[4,4,3,2,24,48,0],
[4,4,3,2,48,64,0],
[6,4,3,2,64,128,1],
[9,6,3,1,128,160,1],
[15,6,3,2,160,256,1]]
elif model_type=="M" or model_type=="m":
# [[每层重复的次数,该层对应的expand,k,s,in_ch,out_ch,conv_type]]
# conv_type为0表示Fused_MBConv,为1表示MBConv
repeat_expand_list = [[3, 1,3,1,24,24,0],
[5, 4,3,2,24,48,0],
[5, 4,3,2,48,80,0],
[7, 4,3,2,80,160,1],
[14, 6,3,1,160,176,1],
[18, 6,3,2,176,304,1],
[5,6,3,1,304,512,1]]
elif model_type == "L" or model_type == "l":
# [[每层重复的次数,该层对应的expand,k,s,in_ch,out_ch,conv_type]]
# conv_type为0表示Fused_MBConv,为1表示MBConv
repeat_expand_list = [[4, 1,3,1,32,32,0],
[7, 4,3,2,32,64,0],
[7, 4,3,2,64,96,0],
[10, 4,3,2,96,192,1],
[19, 6,3,1,192,224,1],
[25, 6,3,2,224,384,1],
[7,6,3,1,384,640,1]]
#第一个卷积层
self.conv1=Conv(3,repeat_expand_list[0][4],3,2)
#backbone
blocks=[]
num=0 #同于确定expand—Conv的输出通道数
total_num=sum(i[0] for i in repeat_expand_list)
for repeat_expand in repeat_expand_list:
# repeat,expand=repeat_expand[0],repeat_expand[1] #某层堆叠次数,expand参数
if repeat_expand[-1]==0:
for r in range(repeat_expand[0]):
drop_rate=drop_connect_rate * num / total_num
in_ch=repeat_expand[4] if r==0 else repeat_expand[5]
s=repeat_expand[3] if r==0 else 1
blocks.append(Fused_MBConv(in_ch,repeat_expand[5],repeat_expand[2],s,drop_rate,repeat_expand[1]))
num+=1
else:
for r in range(repeat_expand[0]):
drop_rate = drop_connect_rate * num / total_num
in_ch=repeat_expand[4] if r==0 else repeat_expand[5]
s = repeat_expand[3] if r == 0 else 1
blocks.append(MBConv(in_ch, repeat_expand[5], repeat_expand[2],s, drop_rate,se_rate,repeat_expand[1]))
num += 1
self.block=nn.Sequential(*blocks)
#class head
heads=[]
features=1280
head_conv=Conv(repeat_expand_list[-1][5],features,1,1)
avg=nn.AdaptiveAvgPool2d(1)
flatten=nn.Flatten()
heads.append(head_conv)
heads.append(avg)
heads.append(flatten)
if drop_connect_rate > 0:
drop_out = nn.Dropout(drop_connect_rate, inplace=True)
heads.append(drop_out)
linear=nn.Linear(features,self.class_num)
heads.append(linear)
self.head=nn.Sequential(*heads)
def forward(self,x):
res=self.conv1(x)
res=self.block(res)
res=self.head(res)
return res
整体看下来的话, 大体和参考代码里的代码差不多,只是改成了自己觉得方便的封装格式。
总结
以上就是本篇的全部内容,想更加了解网络结构的话,可以去看下大佬的讲解视频,讲的很清楚,也感谢大佬贡献的代码。如本篇文章发现有不对的地方,欢迎评论区指正。另外,训练部分的代码将在几天后发布。