背景
俗话说,温故而知新。chatGPT效果太惊艳了!简直就是碾压的效果。但是还要有希望,先拾取,再创新。先了解,再超越吧。
ps: 再刷最后一遍算法题思路。顺便基于chatGPT3.5感受一下大模型的魔力。
数组与指针的区别
在C/C++中,数组和指针是既相互关联又有区分的两个概念。当我们声明一个数组时,其数组名也是一个指针,该指针指向数组的第一个元素。我们可以通过一个指针来访问数组,但是C/C++没有记录数组的大小,因此用指针来访问数组中的元素时,程序员要确保没有超出数组的边界。
数组与指针的区别。运行下面的代码,请问输出是什么?
int GetSize(int data[])
{
return sizeof(data);
}
int _tmain()
{
int data1[]={1,2,3,4,5};
int size1=sizeof(data1);
int *data2=data1;
int size2=sizeof(data2);
int size3=GetSize(data1);
printf("%d, %d, %d\n", size1, size2, size3);
}答案是输出“20,4,4”。
data1是一个数组,sizeof(data1)是求数组的大小。这个数组包含5个数字,每个整数占4字节,因此占用20字节。
data2声明为指针,尽管它指向数组data1的第一个数字,本质仍是一个指针。在32位系统上,对任意指针求sizeof,得到的结果都是4。
在C/C++中,当数组作为函数的参数进行传递时,数组就自动退化为同类型的指针。因此,虽然函数GetSize的参数data被声明为数组,但它会退化为指针,size3的结果仍是4。
数组中重复的数字

方法1: 给输入数组排序,然后从排序数组找到重复的数字。给长度为n的数组排序时间复杂度O(nlogn)。
方法2: 构建哈希表,依次扫描该数组,每扫描一个数字,可以用O(1)的时间判断哈希表是否已经包含该数字。时间复杂度是O(n), 但是增加了存储哈希表的空间复杂度O(n)。
方法3:数组的数字是0~n-1,如果没有重复数组,数字i就是下标为i的位置。如果有重复数字,某个i的位置会有多个数,就找到了答案。遍历数组,让各个数各安其位。
以数组{2,3,1,0,2,5,3}为例说明。
{2,3,1,0,2,5,3}
{1,3,2, 0,2,5,3} 数组第0个位置是2,数组第2个位置是1,两个位置的值互换
{3,1,2,0,2,5,3} 位置0,1的值互换
{0,1,2,3,2,5,3} 位置0,3的值互换
位置0,1,2,3都是各就其位了,遍历来到位置4,值为2,下标为2的地方已经有一个2了,所以发生了重复,找到了一个答案,退出程序。
如下是方法3的实现代码,尽管有一个二重循环,但是每个数字最多交换两次就能找到属于它自己的位置,因此总的时间复杂度是O(n)。另外所有操作直接在输入数组上进行,不需要额外分配内存,所以空间复杂度为O(1)。
bool duplicate(int numbers[], int length, int* duplication)
{
if(numbers ==nullptr || length<=0)
{
return false;
}
for(int i=0; i<length; ++i)
{
if(numbers[i]<0 || numbers[i]>length-1)
return false;
}
for(int i=0; i<length; ++i)
{
while(numbers[i]!=i)
{
if(numbers[i]==numbers[numbers[i]])
{
*duplication =numbers[i];
return true;
}
int temp=numbers[i];
numbers[i]=numbers[temp];
numbers[temp]=temp;
}
}
return false;
}不修改数组找出重复的数字

思路1:
创建一个长度为n+1的辅助数组,然后逐一把原数组的每个数字复制到辅助数组。如果原数组中被幅值的数字是m,则把它复制到辅助数组下标为m的位置。这样就容易发现那个数字是重复的,但是该方案需要O(n)的辅助空间。
思路2:
把从1~n的数字从中间数字m分为两部分,前面一半为1~m,后面一半为m+1 ~n。如果1~m的数字数目超过m,那么这一半的区间里一定包含重复的数字;否则,另一半m+1~n区间一定包含重复的数字。我们可以继续把重复数字的区间一分为二,直到找到一个重复的数字。这个过程和二分查找算法很类似,只是多了一步统计区间里数字的数目。
如长度为8的数组{2,3,5,4,3,2,6,7}为例分析查找过程。根据题意,长度为8个数组所有数字都在1~7的范围内。中间数字4把1~7范围分成两端,一段是1~4,另一段是5~7。接下来统计1~4这个区间数字出现的次数,一共出现5次,因此1~4中一定有重复的数字。
接下来再把1~4范围一分为二,一段是1,2 两个数字,另一段是3,4两个数字。数字1或2出现了两次。再统计3或4一共出现了3次,这意味着3,4两个数字一定有一个重复了,我们再统计这两个数字分别出现的次数,接着发现数字3出现了两次,是一个重复的数字。
上述思路用如下代码实现:
int getDuplication(const int* numbers, int length)
{
if(numbers == nullptr || length <= 0)
return -1;
int start = 1;
int end = length - 1;
while(end >= start)
{
int middle = ((end - start) >> 1) + start;
int count = countRange(numbers, length, start, middle);
if(end == start)
{
if(count > 1)
return start;
else
break;
}
if(count > (middle - start + 1))
end = middle;
else
start = middle + 1;
}
return -1;
}
int countRange(const int* numbers, int length, int start, int end)
{
if(numbers == nullptr)
return 0;
int count = 0;
for(int i = 0; i < length; i++)
if(numbers[i] >= start && numbers[i] <= end)
++count;
return count;
}
思路2是按照二分查找的想法,如果输入长度是n的数组,那么函数countRange将被调用O(logn)次,每次需要O(n)的时间,因此总的时间复杂度是O(nlogn),空间复杂度是O(1)。和思路1的O(n)辅助空间的算法相比,是属于以时间换空间。
需要指出,该算法不能保证找到所有重复的数字。
二维数组中的查找
在一个二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序,请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数
比如下面二维数组中查找7,返回true; 查找5,由于数组中不包含该数字,则返回false
[[1 2 8 9]
[2 4 9 12]
[4 7 10 13]
[6 8 11 15]]
思路:
可以先用具体的矩形查找过程寻找规律,发现:首先选取数组中右上角的数字,如果该数字是要查找的数字,则结束查找;如果该数字大于要查找的数字,则剔除该数字所在的列;如果该数字小于要查找的数字,则剔除改数字所在的行。也就是说,如果要查找的数字不在数组的右上角,则每次在数组的查找范围中剔除一行或者一列,这样每一步都可以缩小查找范围,直到要查找的数字被找到,或者查找范围为空。
bool Find(int* matrix, int rows, int columns, int number)
{
bool found = false;
if(matrix != nullptr && rows > 0 && columns > 0)
{
int row = 0;
int column = columns - 1;
while(row < rows && column >=0)
{
if(matrix[row * columns + column] == number)
{
found = true;
break;
}
else if(matrix[row * columns + column] > number)
-- column;
else
++ row;
}
}
return found;
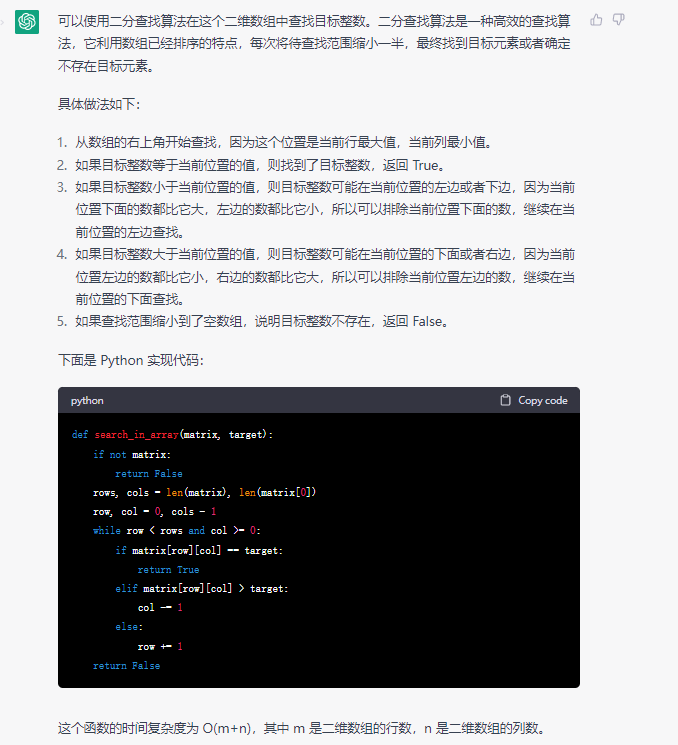
}彩蛋:chatGPT做算法
把这个题目,丢给chatGPT,理解能力真的太强了,如下是它的回答: