Two-Stage Grasping: A New Bin Picking Framework for Small Objects
摘要:本文提出了一种新的抓仓框架,两级抓取,旨在精确抓取杂乱的小物体。
- 在第一阶段进行了对象密度估计和粗糙抓取。
- 在第二阶段,需要进行精细的分割、检测、抓取和推送。
实现了一种小物体抓仓系统,展示了两级抓取的概念。实验证明了该框架的有效性。与传统的基于经典框架的基于视觉的抓取规划方法不同,本文提出的具有简单的视觉检测和规划的新框架可以解决挑选杂乱的小物体的挑战。
拾箱是机器人技术中的一个典型问题。
它的目标是从一个杂乱的箱子[1]中一个接一个地挑选出相同的物体。
近年来,由于其在现代物流[2,3]和服务业[4,5]中的广泛应用,引起了人们的广泛关注。尽管它的重要性和无处不在,垃圾箱仍然具有挑战性。
最近的箱子挑选解决方案使用基于学习的图像处理技术,如图像分割和姿态估计,来检测可以从箱子中挑选出一个项目的抓取。
- 例如,[2]使用语义分割系统和启发式吸抓生成算法从杂乱的对象中选择特定的项目。
- 抓取性能与语义分割质量有关,而吸力抓取质量受到点云分辨率和精度的影响。[6,7]引入了反射对象箱挑选方法和数据集。这些方法是基于场景重建和6D物体姿态估计。[8,9]在箱子选择场景中引入了基于视觉的对象识别和姿态回归解决方案。这些方法在选择正常尺寸的工业岩土方面取得了显著的效果
Problems of small object capture
- 首先,感知杂乱的小物体是具有挑战性的。目前最先进的图像分割方法仍然难以区分属于不同小实例的图像像素
- 物体姿态估计方法需要精确感知完整的点云或深度
- 小物体的尺寸和复杂的物体形状使得传感器分辨率和遮挡限制对姿态估计产生影响
Slovtion
为此,本文提出了一种新的垃圾箱抓取框架,即两级抓取。如名所示,从粗糙到精细有两个不同的抓取阶段,即感知-执行两次。
- 在“粗糙”阶段,一个或多个物品将被从垃圾桶中抓住,并放在一个托盘上。
- 在“精细”阶段,将从托盘中挑选一件物品。
两级抓取利用了软机器人抓持器[18-21]和机器人操作[22-27],并与不同的软机器人抓持器[18-21]、现有的分割方法[2,11,12]、姿态估计方法[8,9,13]和抓取检测方法[16]、[28-30]兼容。
此外,通过将拾箱分为两个阶段,视觉检测和抓物也分为粗糙阶段和精细阶段。无论在哪个阶段,视觉检测或目标抓取都比传统的单阶段工作流程更加可靠。所提出的两阶段拾箱框架为可靠、鲁棒、准确和兼容的小物体拾箱提供了一个很有前途的解决方案。
Three Steps in rough and fine stage:
- sensing
- planning
- execution
rough stage: 持器在小物体密度估计预测的位置大致从一个箱子中抓取一个或多个物品
fine stage: 抓取检测器通过专用的图像分割和碰撞检查,在操作托盘上寻找可行的抓取。
本文提出了两种仿真策略:超越和中断
Density Estimation of Cluttered Small Objects and Rough Grasping
给定一个RGB图像,该模块估计了图像中杂乱的相同小物体的密度。我们使用了一个全卷积网络(FCN)来以像素级的方式预测一个对象的密度图
在我们的实现中,我们使用U-Net 骨干网来预测每个像素的密度值

额外影响的因素:
i)环境光
ii)相机的位置
iii)物体的姿态

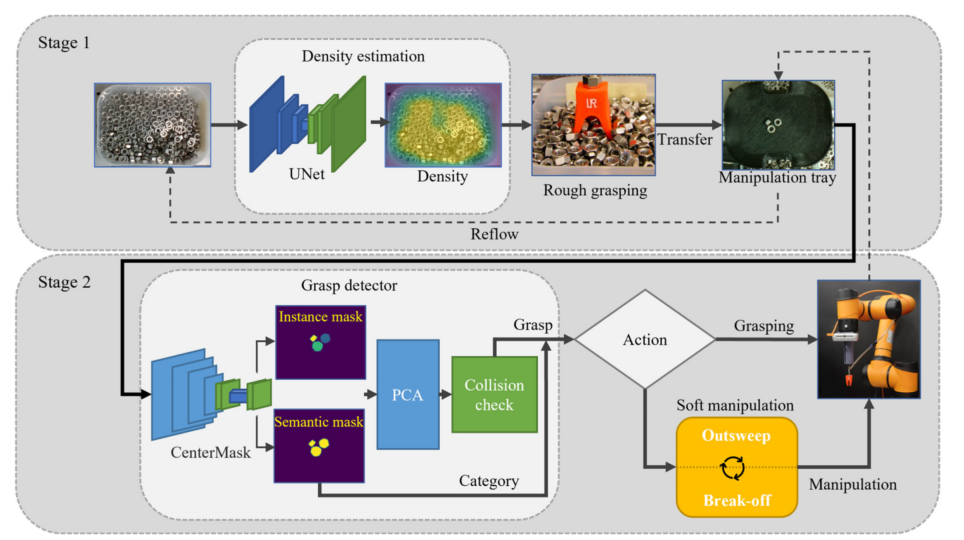
Grasp Detection
- The grasp detector first performs contour finding and PCA on the segmented image of the scene
- Secondly, contacts can be generated based on the orientation and
contour of each item - Thirdly, after generating contacts and grasps, collision checking is conducted by placing virtual fingerprints at every contact point and performing pixel-wise clearance checking
- Only grasps corresponding to isolated objects can survive. Finally, all collision-free and motion-feasible grasps and categories are passed to the task planner
Small Object Singulation by Soft Manipulation


Conclusion
- Soft manipulation algorithm to isolating clutter objects
- small object density estimation method
- Two small object singulation policies
Accurate instance segmentation of surgical instruments in robotic surgery: model refinement and cross-dataset evaluation
Purpose:机器人辅助微创手术中手术器械的自动分割在提高上下文感知方面发挥着基础作用。本文提出了一种基于改进的Mask R-CNN的实例分割模型,可以准确地分割手术器械并识别它们的类型。
Methods:我们将仪器分割任务重新构建为实例分割任务。然后,我们使用锚点优化和改进的区域提议网络来优化Mask R-CNN以进行仪器分割。此外,我们使用不同的采样策略进行跨数据集评估。
Background:
Robot-assisted minimally invasive surgery是一种新型的手术方法,它将机器人技术和微创手术相结合,可以减少手术创口,降低出血量,缩短住院时间,减轻患者痛苦。
该领域的研究主要包括机器人手术系统的开发和优化、手术操作的规范化和自动化、手术过程中的图像处理和分析等方面。近年来,一些新技术如深度学习和人工智能也被应用于该领域,取得了一定的成果。未来,Robot-assisted minimally invasive surgery有望成为外科手术的主流方式。
Challenges:
在RMIS(机器人辅助微创手术)这样的挑战性环境中,如视野狭窄和外科医生的高强度工作负荷[4],增强系统的自动上下文感知对于提高外科医生的表现和患者的安全性起着重要的作用。
- 不同手术器械的自动分割是实现RMIS智能上下文感知的基本要素[10],也是许多后续问题(如跟踪、姿态估计、动作识别[11])的先决条件。
然而,自动手术器械分割具有挑战性,因为手术情况复杂,包括运动模糊、反光、组织遮挡和气体等,如图1所示。此外,有限的内窥镜视野通常只显示器械的部分而不是整个器械,这进一步增加了区分它们的难度。
Model refinement based on mask R-CNN
Mask R-CNN已被提出作为一种简单、灵活和通用的对象实例分割框架[9]。
- 它引入了一个高效的RPN来生成基于提议的候选对象边界框的兴趣区域(RoIs)。
- RoIs与多尺度定义的锚点结合使用来预测边界框提议。我们优化了Mask R-CNN,用于手术器械分割,使用改进的RPN(I-RPN)和锚点配置。
Knowledge Supplyment:
- RPN是Region Proposal Network的缩写,是一种用于目标检测的神经网络,用于在图像中生成候选区域(region proposal),即一些可能包含目标的区域。RPN通常作为Faster R-CNN网络的一部分,用于生成候选区域并进行目标检测。在Mask R-CNN中,RPN还用于生成候选对象的兴趣区域(RoIs),以便进行对象实例分割。
- FPN是Feature Pyramid Network的缩写,是一种用于图像语义分割的神经网络,它可以从不同的尺度上提取图像的特征信息,从而更好地处理尺度变化和多尺度物体的情况。FPN通过从底层到高层逐步上采样得到特征金字塔,然后通过横向连接将不同层次的特征进行融合,得到更加丰富和准确的特征表达。FPN被广泛应用于目标检测和图像分割等领域,在提高模型性能的同时,还能减少模型的计算量和参数数量。

Robot & AR
-
人工智能的最新进展大大提高了许多任务,如手术程序的情况意识,和手术机器人的的自动化。
-
与此同时,AR旨在扩大手术环境,以促进外科医生的手术和决策,基于可视化和集成的附加信息,离线计算或实时。
-
AR在外科机器人控制台中配备了沉浸式视图,对新手外科医生的教育具有有效性,如果可以在术中采用,预计将非常有帮助。
不幸的是,到目前为止,人工智能和AR的优势还没有以一种合理的方式合并为机器人手术。人工智能和增强现实的有趣结合作为一个通用的话题出现,并已在许多应用中得到了例证
Background:
例如游戏[17]、驾驶员培训[18]、[19]和虚拟患者[20]、[21]等领域。在增强现实中赋予智能不仅可以提升虚拟体验,还可以在要求高的任务(如外科教育)中利用基于学习的算法的强大能力。然而,将人工智能和增强现实应用于外科机器人的尝试还很少。一些作者[22]-[24]提出使用计算机视觉模型定位感兴趣的解剖区域,然后将结果叠加在相机视图中。然而,这些解决方案只考虑了感知上的现有线索,没有揭示类人决策行为的光芒。
同时,强化学习(RL)被广泛认为是一种有效的技能学习方法[25]-[28],但其潜力在外科机器人领域中尚未得到充分利用。
探索这些问题的一个有趣场景是外科教育,在这种情况下,基于RL的智能代理应该推理外科任务并为新手生成建设性的指导方针。这种具体化的智能有望显著增加外科培训的可访问性并降低成本。在外科机器人平台上实现智能指导,以增强现实可视化的形式,还可以进一步提高可用性和用户体验,但如何实现这一目标仍不清楚。
dVRK平台是指“da Vinci Research Kit”,是由加拿大不列颠哥伦比亚大学机器人控制与感知实验室(The UBC Robotics and Control Laboratory)开发的一个机器人手术平台,用于研究和开发机器人手术技术。该平台基于Intuitive Surgical公司的da Vinci手术机器人系统,并进行了改进和优化,可以进行类似于da Vinci手术机器人的手术操作,并且提供了一些新的功能和接口,以便研究人员可以更好地探索机器人手术技术的潜力。dVRK平台是一个开源的、可定制的平台,可以通过ROS(Robot Operating System)进行控制和编程。
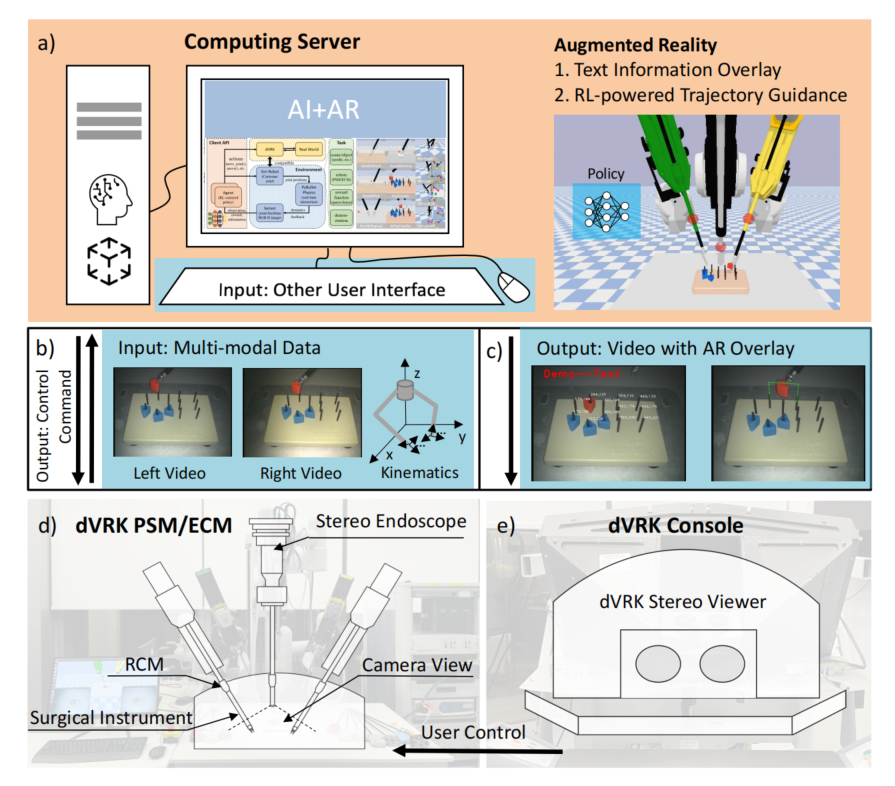
本文旨在无缝地将人工智能和增强现实相结合,通过实时AR可视化增强基于RL的器械运动轨迹,并使用da Vinci Research Kit(dVRK)实现外科教育场景的流程,如图1所示。
对于AI启用的分析,采用强化学习从专家演示和与环境的交互中学习策略。
然后,系统可以根据当前观察推理未来行动。这种行为可以嵌入到教育过程中,其中自动预测的行动可以作为有用的信息来逐步指导学员的运动。
随后,如何有效地可视化信息变得非常重要,特别是在实时与机器人平台相结合时。我们将展示如何通过dVRK控制台在立体视频中叠加3D引导轨迹的可行性。
通过将从RL策略生成的轨迹的3D位置投影到dVRK控制台中的立体视频帧中,我们可以生动地观察到带有叠加轨迹的外科手术场景,以供教育目的。我们已经在典型的外科教育任务中实施和评估了我们的方法,即插销传递。
- 据我们所知,这是首次探索AI和AR的协同作用,利用基于RL的预测和基于dVRK的可视化实现外科教育场景。
在机器人手术中应用人工智能的研究自从2000年临床引入达芬奇手术系统以来已经积极进行了十年[29]。
已经发现了几个重要的研究主题,例如手术器械分割[31]、手势识别[6]、工作流程识别[1]和手术场景重建[32]。它们可以支持术中决策[33],并为手术培训和评估提供有价值的数据库[34]–[36]。
尽管有前途,但这些工作仅提供补充信息,没有构思手术计划,例如预测手术器械的轨迹。最近,强化学习的出现开启了一系列基于策略的学习策略[37]。
强化学习的有效性已经在手术手势分类[38]、手术场景理解[40]、机器人学习[27]、[42]等方面得到了揭示。
通过从专家演示中学习,强化学习代理可以根据手头的任务自动生成有意义的解决方案。例如,在[27]和[28]中,作者提出使用深度确定性策略梯度(DDPG)与行为克隆(BC)来进行双手针重新抓取和自主吸血的手术任务。两者都展示了令人鼓舞的结果,表明基于强化学习的框架可能潜在地减轻专家指导的要求[43]–[45]。
除此之外,也有一些工作将人工智能用于外科教育,如基于培训记录[46]-[48]提供指标和绩效反馈,并考虑到[49]-[51]的风格特征来区分专业水平。但很少有人考虑其在AR外科教育中的应用,在外科教育中,整合AR和人工智能需要生动、自动地指导学员。
- 鉴于上面介绍的RL的优越性,将RL作为一个重要的人工智能模块集成到AR中是非常诱人的,例如,一个决策者[52],[53],它鼓励AR系统客观地生成内容
增强现实已经应用于机器人手术的各种范例中[12]。在术中应用中,增强现实实时叠加以提供帮助:
(i)增强深度感知[54]-[56]
(ii)补偿触觉感知[57]
(iii)扩展视野[58]
(iv)提供更直观的人机界面[54],以及(v)注释有用的提示[59],[60]。
其他应用利用增强现实进行机器人手术培训[61]。增强现实在机器人手术中常用的显示媒介包括达芬奇控制台、计算机监视器和头戴式显示器[12]。对于手术教育目的而言,基于头戴式显示器的增强现实是一种有利的媒介,因为它可以为多个用户和环境提供3D显示和交互。Jarc等人将增强现实应用于类临床培训场景中,通过在受训者控制台上增强和叠加由导师控制的3D半透明工具作为指导[62]。进行了涉及七个导师-受训者配对的用户研究,他们展示了增强工具作为有效的指导方法。
- 然而,目前大多数增强现实系统还没有将人工智能作为生成和创建上下文感知信息的核心组件。
framework
- AI+AR计算服务器,如图2a所示):一台配备高端GPU,用于AR和AI算法部署,可从dVRK上的患者侧操作器(PSM)和内窥镜相机操作器(ECM)获取立体视频和运动学信息,接收输入从其他用户界面,培训和部署RL策略或其他AI框架,并输出增强的视频流到监控或其他显示设备。
- 内窥镜视频采集和运动学控制:如图2 b)和d)所示。dVRK在ECM上包含一个立体内窥镜,可以捕获立体视频流进行3D感知和感知。在这种情况下,我们用视频捕获卡从dVRK立体声内窥镜中采集视频信号,将视频信号转换为USB视频流,可以由计算机检索。通过使用dVRK机器人操作系统(ROS)包提供的应用程序编程接口(API),用户可以从dVRK上的两个PSM中获取运动学信息(包括工具尖端位置、速度、旋转),并输入运动学来控制PSM的运动。此外,psm还可以由用户在dVRK控制台中使用手直接控制。
- 使用dVRK控制台显示AR视频:如图2c所示)和e)。在dVRK控制台中配备了一个立体声查看器,用户可以在手术场景中通过计算机上覆盖的AR和AI信息来查看场景。立体查看器可以提供左右视图,人类可以感知手术视频和叠加的信息与3D的感觉。该功能后来在下一代的外科手术机器人中发展成为TilePro™[67],展示了应用于真正的机器人手术的潜在可能性。
Generating AI Guidance with Reinforcement Learning
我们的工作不是通过经验丰富的专家来指导新手,而是通过先进的强化学习自动产生指导。
考虑到SurRoL 在dVRK的演示和试验方面的有趣优势,我们尝试将其作为我们的核心AI模块,使用基于特定任务的RL算法学习和生成引导轨迹。
- SurRoL incorporates reinforcement learning to teach an
intelligent agent to take interactive actions so that the cumulative reward can be maximized.
SurRoL是指“Surrogate-assisted Robot Learning”,是一个基于代理模型的机器人学习框架,旨在解决机器人学习中的一些挑战,例如数据效率、泛化能力和安全性。该框架由加拿大不列颠哥伦比亚大学的机器人控制与感知实验室开发,其核心思想是使用代理模型来模拟真实环境中的机器人行为,从而减少对真实机器人的依赖,提高学习效率和安全性。SurRoL框架结合了深度学习、强化学习和元学习等技术,可以应用于各种机器人学习任务,例如机器人操作、路径规划和控制等。该框架还提供了一些实验平台和数据集,供研究人员使用和评估。SurRoL框架的目标是推动机器人学习技术的发展,并促进机器人在现实世界中的应用。
- 对于机器人手术,我们定义六个自由度,包括笛卡尔空间中的位置移动(dx、dy、dz)、在一个自上而下/垂直空间中的方向(dyaw/dpitch),以及下颚的开启状态(j≥0)或关闭状态(j<0)。
6D pose: 指的是物体在三维空间中的位置和方向,也称为"六自由度姿态"。它包括三个位置自由度(x、y、z轴上的位置)和三个方向自由度(物体绕x、y、z轴的旋转角度)。在机器人手术中,了解工具的6D姿态可以帮助机器人定位和操作工具,从而实现精确的手术。
强化学习的目标是找到策略π以生成动作at=π(st)。
为了促进学习过程,奖励rt被设置为基于目标的,其中成功函数f(st,g,at)通过检查at是否达到地面实际状态(例如3D位置和6D姿态)来确定奖励rt。
这种情况类似于手术教育中的尝试-反馈过程。
最后,目标策略π通过最大化实验期望Eπ[PTt=0γtrt]来学习,其中γ∈[0,1)表示折扣因子,以平衡代理人对远期和即期关注。具体而言,我们选择了一种称为“后见经验回放”(HER)[68]的样本高效学习算法,并将其与Q过滤行为克隆相结合。在实践中,我们将利用从脚本策略生成的少量演示数据作为模仿学习的演示。这种方法有很大的潜力,可以广泛应用于大量的手术数据中进行学习,然后为手术教育提供基于人工智能的指导。
Real-time 3D Visualization by Augmented Reality
- Different Coordinate System
- Human-involved Flexible Calibration
- Augmented 3D Overlaying
- Integrating AI and AR for Trajectory Guidance