计算图与动态图机制
计算图与动态图机制
计算图
| 1、什么是计算图? |
什么是计算图?
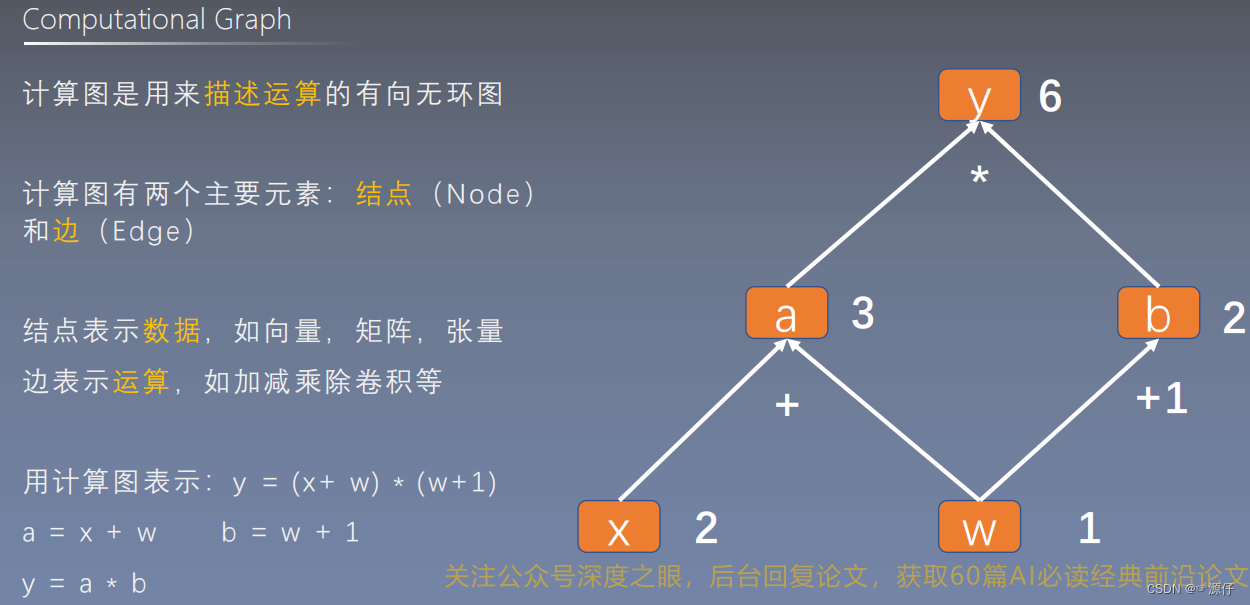
| 2、计算图与梯度求导 |
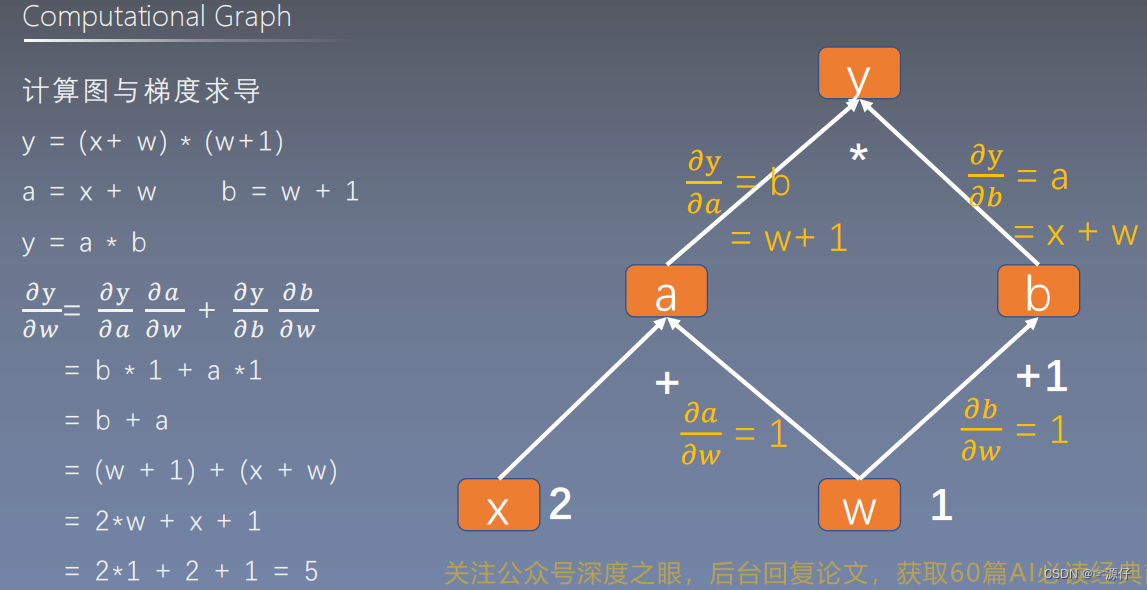
用代码验证一下上面图片的例子:
import torch
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x) # retain_grad()
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
print(w.grad)
OUT:
tensor([5.])
| 3、叶子结点 |
什么是叶子节点?
- 答:就是用户创建的结点称为叶子结点,如X 与 W
- is_leaf : 表示张量是否为叶子节点。
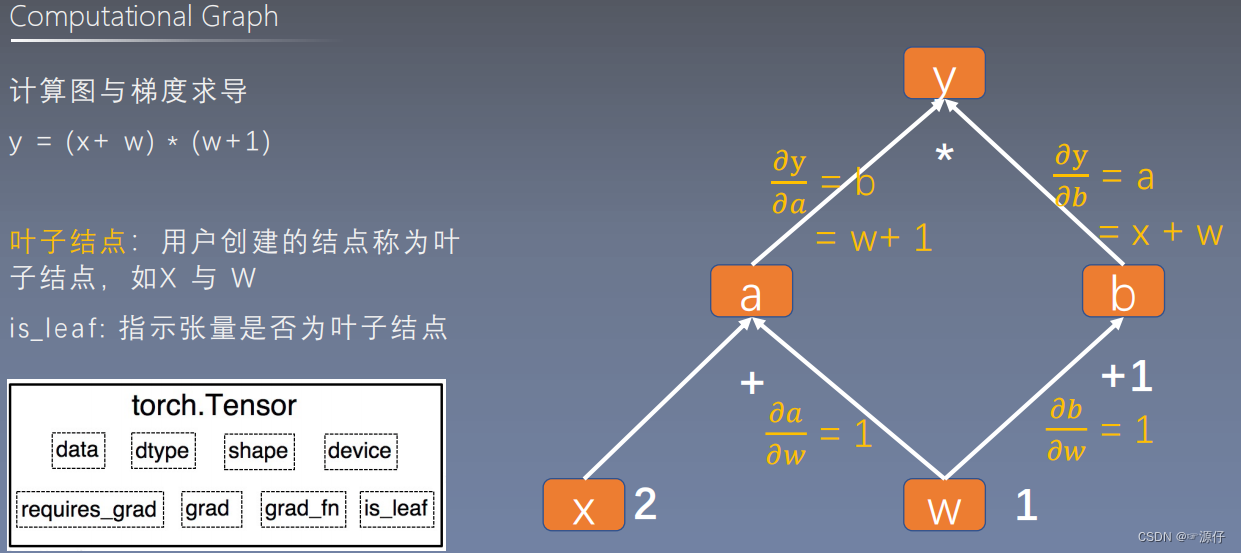
用代码查看上述计算图哪些为叶子节点:
import torch
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x) # retain_grad()
# a.retain_grad() # 执行 retain_grad()会保留非叶子节点的梯度
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
# print(w.grad)
# 查看叶子结点
print("w是is_leaf ? : {}\nx是is_leaf ? : {}\na是is_leaf ? : {}\nb是is_leaf ? : {}\ny是is_leaf ? : {}\n".format(w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf))
# 查看梯度
print("\nw gradient = {}\nx gradient = {}\na gradient = {}\nb gradient = {}\n y gradient = {}\n".format(w.grad, x.grad, a.grad, b.grad, y.grad))
OUT:
w是is_leaf ? : True
x是is_leaf ? : True
a是is_leaf ? : False
b是is_leaf ? : False
y是is_leaf ? : False
w gradient = tensor([5.])
x gradient = tensor([2.])
a gradient = None
b gradient = None
y gradient = None
由上述对各个节点求梯度的代码结果我们可以得出叶子节点的作用:
- 节约内存空间,为什么这么说呢?
- 由上述代码的结果可知,只有叶子节点(w和x)的梯度保存到内存空间,所以能输出出来,而非叶子节点(a、b、y)的导数都被清除了,所以输出为None。
如果想保留非叶子节点的梯度:使用retain_grad()即可保留
retain_grad() # 执行 retain_grad()会保留非叶子节点的梯度
grad_fn: 记录创建该张量时所用的方法
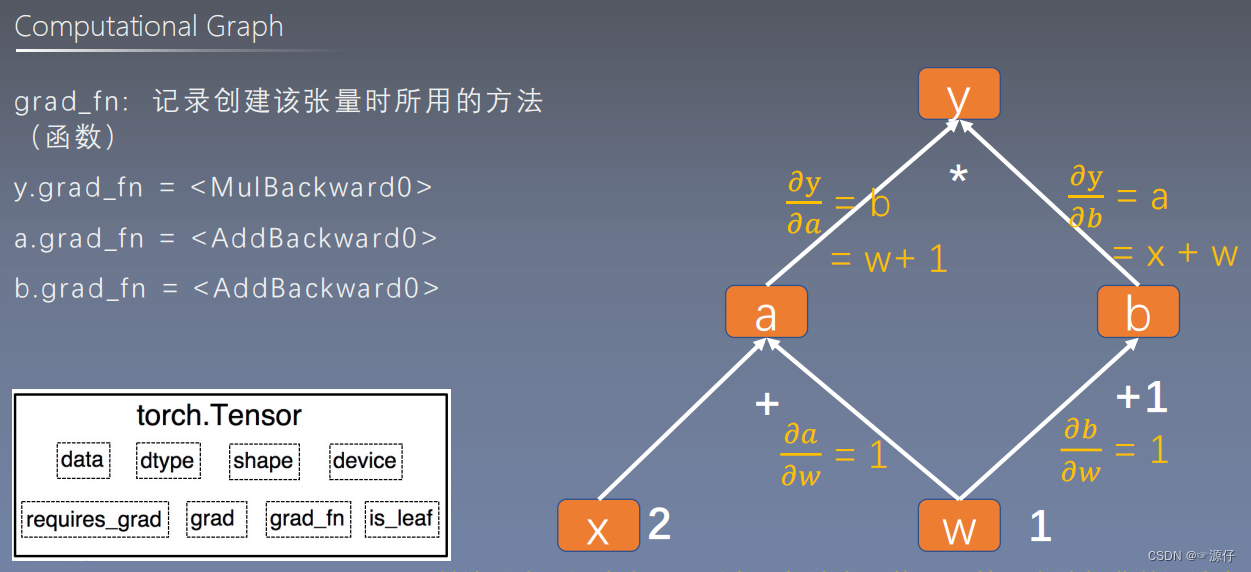
import torch
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x) # retain_grad()
a.retain_grad() # 执行 retain_grad()会保留非叶子节点的梯度
b = torch.add(w, 1)
y = torch.mul(a, b)
y.backward()
# print(w.grad)
# 查看叶子结点
# print("w是is_leaf ? : {}\nx是is_leaf ? : {}\na是is_leaf ? : {}\nb是is_leaf ? : {}\ny是is_leaf ? : {}\n".format(w.is_leaf, x.is_leaf, a.is_leaf, b.is_leaf, y.is_leaf))
# 查看梯度
# print("\nw gradient = {}\nx gradient = {}\na gradient = {}\nb gradient = {}\ny gradient = {}\n".format(w.grad, x.grad, a.grad, b.grad, y.grad))
# 查看 grad_fn
print("w的grad_fn: {}\nx的grad_fn: {}\na的grad_fn: {}\nb的grad_fn: {}\ny的grad_fn: {}\n".format(w.grad_fn, x.grad_fn, a.grad_fn, b.grad_fn, y.grad_fn))
OUT:
w的grad_fn: None
x的grad_fn: None
a的grad_fn: <AddBackward0 object at 0x00000188C0B7BC50>
b的grad_fn: <AddBackward0 object at 0x00000188C0B7BC88>
y的grad_fn: <MulBackward0 object at 0x00000188C0D215C0>
由上述代码的结果可知:grad_fn:是保存每个节点是通过什么运算得到的。如
a的grad_fn: <AddBackward0 object at 0x00000188C0B7BC50>
a : 是由加法运算得到的,并保存在0x00000188C0B7BC50这个地址。
动态图vs 静态图

静态图: 如我们报了一个旅游团队,我们游玩的路线就是固定的。也就是我们先确定了整体旅游线路,再游玩,这中被称为静态。
动态图: 如我们自己买机票,我们先去新加波,再去台湾省,再去日本市,但到了新加坡有人推荐先去日本市,所以我们决定改变路线,先去日本市东京县玩一玩,这就是动态,我们随时可以调整模型。