本文提出一种提出了一种新的训练范式,可以在没有边界框注释或图像级别类标签的情况下进行目标检测。
论文链接:https://arxiv.org/pdf/2303.15149.pdf
代码链接:http://www.pinakinathc.me/sketch-detect/
自史前时代起,素描图就被人类用来表达和记录各种物体,它们所具有的表现力即使在语言面前仍然是无与伦比的——回想一下你想要用笔和纸(或Zoom白板)把一个想法画下来的那一刻。过去十年里,以素描为核心的研究也蓬勃发展,涵盖了从传统任务如分类和合成到更具体的素描任务如建模视觉抽象、风格转移和连续笔画拟合,以及一些有趣的应用,如将素描转换为分类器。
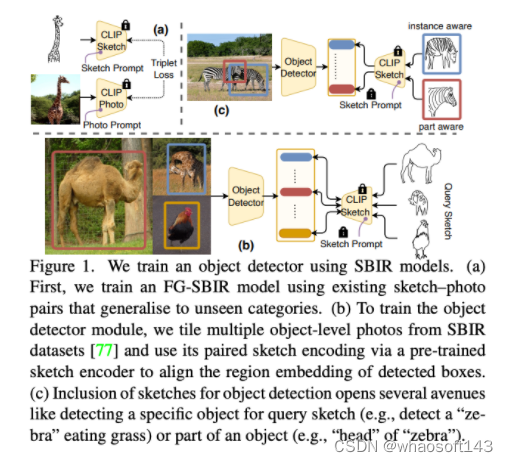
然而,素描的表现力仅以素描为基础的图像检索(SBIR)形式被探索,尤其是细粒度变体。取得了巨大的进展,最近的系统已经达到了商业适应的成熟阶段,这是对培养素描表现力可以产生实际影响的大力证明。在本文中,作者提出看一个问题——人类素描对于目标检测这一基本视觉任务有什么作用?因此,作者设想的结果是一个基于素描的目标检测框架,它可以根据你画的内容来检测,也就是说,它可以根据你想要表达的方式来检测。例如,在上图中画一个“斑马吃草”的素描应该会从一群斑马中检测出“那只”斑马(实例感知检测),同时还可以让你自由地指定部位(部位感知检测),因此,如果你只想要“斑马”的“头”部,那就画一个头部就可以了。
作者提出的方法并没有从头开始设计一个素描启用的目标检测模型,而是展示了一个直观的基础模型(如CLIP)和现成的SBIR模型之间的协同作用,可以相当优雅地解决这个问题——CLIP提供模型泛化,SBIR填补(素描→照片)的差距。具体来说,我们通过为两种模态分别学习独立的提示向量来改进CLIP,以构建素描和照片编码器(共同的SBIR模型中的分支)。更具体地说,在训练期间,可学习的提示向量被预置到CLIP的ViT骨干网络的第一个Transformer层的输入序列中,同时保持其余部分不变。因此,我们将模型泛化注入到了学习的素描和照片分布中。接下来,我们设计了一个训练范式,以适应学习的编码器进行目标检测,使检测到的框的区域嵌入与来自SBIR的素描和照片嵌入对齐。这使我们的目标检测器可以在不需要来自辅助数据集的附加训练照片的情况下进行训练。
为了使我们的基于素描的object detector更有趣也更通用,方法进一步规定它也可以以零样本的方式工作。为此,我们按照的方法,将目标检测从预定义的固定集设置扩展到开放词汇设置。具体来说,我们用原型学习替换目标检测器中的分类头,其中编码去query素描特征作为support set(或原型)。接下来,在弱监督的目标检测(weakly supervised object detection,WSOD)设置下进行CE loss训练,覆盖所有可能的类别或实例的原型。然而,虽然SBIR是使用对象级素描/照片对进行训练的,但目标检测是在图像级别(多类别)上进行的。因此,为了使用SBIR训练目标检测器,我们还需要弥合对象和图像级特征之间的差距。为此,我们使用了一种数据增强技巧,它非常简单但对于抗数据集噪声和推广到未知类别非常有效——方法随机从SBIR数据集中选择n = {1, .. . , 7}张照片,并在一个空白画布上任意平铺它们(类似于CutMix)。
方法
我们提出了一种新的训练范式,可以在没有边界框注释或图像级别类标签的情况下进行目标检测。相反,我们使用基于草图的图像检索进行监督。因此,论文需要完成三个级别的任务:(i) 细粒度对象检测——使用草图中的细粒度视觉提示指定感兴趣的区域。(ii) 类别级别的对象检测——通过草图指定被检测实例的类别。(iii) 部分级别的对象检测——检测指定的部分(例如,“马”的“头”和“腿”)。
background

首先论文介绍了关于这些目标检测方法的一些背景:
-
该框架包括两个模块——目标检测和基于草图的图像检索。
-
Faster-RCNN 是一种最先进的有监督目标检测框架。因此本文主要采用Faster-RCNN的结构来完成训练。也就是说是两阶段的结构。
-
基准的基于草图的图像检索框架使用草图/照片特征提取器和三元组损失进行训练。
-
通过使用硬三元组和类别鉴别器损失,扩展了跨类别的细粒度基于草图的图像检索。
Weakly Supervised Object Detection

Localising Object Regions with Query Sketch

Prompt Learning for Generalised SBIR

Bridging Object-Level and Image-Level

虽然 SBIR 是使用单个对象级别的草图/照片对进行训练的,但object detection是针对图像级别(多个object)的数据进行操作的。为了使用 SBIR 训练对象检测器,我们需要弥合这种对象和图像级别之间的gap。我们的解决方案非常简单 - 通过在 SBIR 数据集中随机平铺 n = {1,...,7} 个对象级别的照片来合成大小为 (H × W) 的annotation。
实验

本文使用的数据是标准对象检测数据集,例如 PASCAL-VOC 和 MS-COCO。本文中提出的方法使用基于草图的图像检索进行监督,训练对象检测而无需边界框注释或图像级别的类标签。

上表展示了两种类型的基于草图的图像检索(SBIR)模型的定量性能:零样本类别级别 SBIR(CL-SBIR)和跨类别细粒度 SBIR(CC-FGSBIR)。表格展示了 CL-SBIR 的平均精度(mAP)和精度为200(P@200),以及 CC-FGSBIR 的1和5的准确率。表格根据所使用的训练数据百分比分为三个部分:100%、70%和50%。每个部分展示了三个模型的性能:GRL、VKD和Ours。GRL和VKD是现有的 SBIR 模型,而 Ours 是本文中提出的模型。每个部分的第一行显示了 GRL 模型的性能,第二行显示了 VKD 模型的性能,第三行显示了提出的模型(Ours)的性能。在所有三个部分中,提出的模型均优于 GRL 和 VKD 模型。表格中以粗体突出显示了提出模型的性能。表格还包括缩写诸如 GRL、VKD 和 CCD,分别代表梯度反转层、视觉知识蒸馏和交叉字幕解码器等技术,用于提高 SBIR 模型的性能。总的来说,该表显示了提出的模型在零样本设置中的性能优于现有的 SBIR 模型,在该设置下,模型未在被测试的特定类别上进行过训练。
本论文通过引入一个基于草图的对象检测框架,克服了固定集合分类器在有监督和弱监督场景的局限性。该模型根据所绘制的草图进行检测,无需知道测试时期望哪个类别(zero-shot),也无需额外的边界框(fully supervision)和类标签(weak supervision)。论文展示了一种基于现有草图模型(例如 SBIR)和基础模型(例如 CLIP)之间的直观协同作用,而不是从头开始设计模型。这些草图模型已经能够优雅地解决任务- CLIP 提供模型泛化能力,而 SBIR 则用于弥合(草图→照片)之间的差距。该模型通过调整对象检测的学习编码器来进行训练,使检测到的框的区域嵌入与 SBIR 中的草图和照片嵌入对齐。whaosoft aiot http://143ai.com
这篇论文的局限性在于它目前将多个查询草图视为独立的query embedding,这可能不适用于检测具有有意义的空间对齐的多个对象的复杂场景。未来的工作可以使用最近引入的FS-COCO数据集中的复杂草图将细粒度对象检测扩展到语义分割。
本文提出的基于草图的对象检测框架是根据所绘制的草图进行检测,通过在草图中使用细粒度的视觉线索指定感兴趣的区域,允许进行精细的对象检测。该模型无需知道在测试时期望哪个类别(零样本),也无需额外的边界框或类标签。该模型是通过组合基础模型(如 CLIP)和用于基于草图图像检索(SBIR)的现有草图模型构建的。该模型通过调整对象检测的学习编码器进行训练,使检测到的框的区域嵌入与 SBIR 中的草图和照片嵌入对齐。在标准对象检测数据集(如 PASCAL-VOC 和 MS-COCO)的零样本设置下,本文提出的方法在评估时优于有监督(SOD)和弱监督对象检测器(WSOD)。