最近点对问题,大概意思平面有n个点,求距离最近的两个点对的距离(可用平面分治解决绝大部分情况)
首先如果一个一个比较,那就是n的二次方复杂度,那很多情况都会超时
我们考虑使用分治法,大概思路就是将这个平面分成两半(横的分竖的分都行,这里讲的是根据横坐标竖着分)
注意我们这个不是按照(最前的x坐标 + 最后的x坐标)/ 2这么分,因为这样可能会递归深度退化,我们应该按照最中间的那个点的x坐标来分,这样保证每次递归,点的数量都减半。
分治思路就是把点按x坐标分成两半,有两种情况:
(1)若两点同在左半边或右半边时的最小距离
(2)若两点分别在左半边和右半边时的最小距离
对于(1)我们递归的结果返回就能得到,我们重点考虑(2)
对于我们从(1)中得到的最小距离,我们记为 d ,我们只需考虑两点距离小于 d 的情况(且这两点在左右两边),所以距离中间点的 x坐标差 大于等于d的点我们可以不考虑,并且我们不再需要考虑同边
对于处理(2)大概讲三条思路(只有deal函数中处理(2)方法是不同的,为了节省篇幅,后面两种只写了修改后的deal函数)
第一种:对于每个离中间点的 x坐标差 小于 d 的左边点,我们遍历每个离中间点的 x坐标差 小于 d 的 右边点,取距离最小值返回即可

【相当于我们对于 左边虚线内的所有点 遍历一次 右边虚线内所有点,由于 d 的值会不断减小,所以不用担心遍历太多次。】
缺点:我们遍历了一些 y坐标差 大于等于 d 的不可能为最小距离的多余情况
代码如下(这种在P1429中所耗 687ms / 3.62MB / 1.52KB )
#include <iostream>
#include <stdio.h>
#include <algorithm>
#include <math.h>
#define INF (double)1e18
using namespace std;
pair<double, double> data[200005];
bool cmp(pair<double, double> p1, pair<double, double> p2)
{
if(p1.second == p2.second)
{
return p1.first < p2.second;
}
return p2.second < p2.second;
}
double dist(pair<double, double> p1, pair<double, double> p2)
{
double num = (p1.first - p2.first) * (p1.first - p2.first) + (p1.second - p2.second) * (p1.second - p2.second);
return sqrt(num);
}
double deal(int q, int t)
{
if(t - q == 1)
{
return INF;
}
double a = deal(q, (q + t) / 2);
double b = deal((q + t) / 2, t);
double x_mid = data[(q+t)/2].first;
double d = min(a, b);
int i = upper_bound(data + q, data + (q + t) / 2, make_pair(x_mid - d, INF)) - data;
int jj = upper_bound(data + (q + t) / 2, data + t, make_pair(x_mid + d, INF)) - data;
for(; i < (q + t) / 2; i++)
{
for(int j = (q + t) / 2; j < jj; j++)
{
if(data[i].first - data[j].first >= d)
{
break;
}
else
{
d = min(d, dist(data[i], data[j]));
}
}
}
return d;
}
int main()
{
int N;
scanf("%d", &N);
for(int i = 0; i < N; i++)
{
scanf("%lf %lf", &data[i].first, &data[i].second);
}
sort(data, data + N);
double jg = deal(0, N);
printf("%.4lf\n", jg);
}
第二种:我们在递归处理的同时,按 y坐标 进行归并排序
这样的话我们无法判断直接判断哪个点的 x坐标 离中间点的 横坐标 距离小于 d ,所以我们遍历所有点,当点的 x坐标 在距离中间点的 横坐标 距离小于 d 时进行处理,处理方法为,对一定范围的点,进行遍历比较,如下图
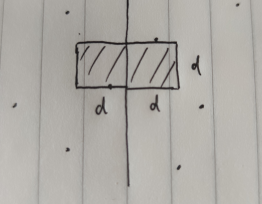
【相当于我们对于所有点遍历一次,如果 x坐标 在范围内,我们便对阴影区域进行遍历,由于有 d 的限制,所以除去自身,该矩形阴影内最多还有 5 个点。】
缺点:我们遍历了所有点,有 x坐标 距离中间点横坐标超过 d 的多余情况
代码如下(这种在P1429中所耗 1.19s / 8.03MB / 1.45KB )
double deal(int q, int t)
{
if(t - q == 1)
{
return INF;
}
double x_mid = data[(q+t)/2].first;
double a = deal(q, (q + t) / 2);
double b = deal((q + t) / 2, t);
double d = min(a, b);
inplace_merge(data + q, data + (q + t) / 2, data + t, cmp);
vector<int> dian;
for(int i = q; i < t; i++)
{
if(data[i].first <= x_mid - d || data[i].first >= x_mid + d)
{
continue;
}
for(int j = dian.size() - 1; j >= 0; j--)
{
if(data[i].second - data[dian[j]].second >= d)
{
break;
}
d = min(d, dist(data[i], data[dian[j]]));
}
dian.push_back(i);
}
return d;
}
第三种:因为同边的点的最小值已经求出为 d ,所以不用 同边 的之间再次比较,所以我们可以分开两个vector容器分别存左边和右边的 x坐标 在范围内的点
但是这种会产生一种问题,如果在 中间点的横坐标 的点,我们不知道它属于左边还是右边,所以我们左右两边都得存放,且要和左右两边都比较一次
这种优化很不明显,甚至当在中间点的横坐标上的点多了的时候会退化,且原本范围内也就只用匹配最多五次,改了也就省了一两次匹配,还增加了大量代码量
缺点多着
代码如下( 1.58s / 8.07MB / 2.25KB )
double deal(int q, int t)
{
if(t - q == 1)
{
return INF;
}
double x_mid = data[(q+t)/2].first;
double a = deal(q, (q + t) / 2);
double b = deal((q + t) / 2, t);
double d = min(a, b);
inplace_merge(data + q, data + (q + t) / 2, data + t, cmp);
vector<int> right;
vector<int> left;
for(int i = q; i < t; i++)
{
if(data[i].first <= x_mid - d || data[i].first >= x_mid + d)
{
continue;
}
if(data[i].first <= x_mid)
{
left.push_back(i);
for(int j = right.size() - 1; j >= 0; j--)
{
if(i == left[j])
{
continue;
}
if(data[i].second - data[right[j]].second >= d)
{
break;
}
else
{
d = min(d, dist(data[i], data[right[j]]));
}
}
}
if(data[i].first >= x_mid)
{
right.push_back(i);
for(int j = left.size() - 1; j >= 0; j--)
{
if(i == left[j])
{
continue;
}
if(data[i].second - data[left[j]].second >= d)
{
break;
}
else
{
d = min(d, dist(data[i], data[left[j]]));
}
}
}
}
return d;
}