title:Hierarchical Reasoning Based on Perception Action Cycle for Visual Question Answering
基于感知动作循环的层次推理用于视觉问答
文章目录
摘要
基于感知动作循环的分层推理框架( HIPA )来处理VQA任务。
- 它将多模态的推理过程与感知动作循环( PAC )相融合,解释了人类对周围世界的学习机制。
- 它通过推理的三个阶段来理解视觉模态:对象层面的注意力、组织和解释。它通过词汇层面的注意力、解释和条件化来理解语言情态。
- 随后,视觉和语言模式在整个框架中以循环和分层的方式相互依赖地解释。 为了进一步评估视觉和语言特征,我们认为相同答案的图像-问题对最终应该具有相似的视觉和语言特征。因此,我们使用余弦相似度的标准差和曼哈顿距离等指标进行视觉和语言特征评估实验。我们发现,与其他VQA框架相比,在我们的框架中使用PAC提高了标准偏差。
- 为了进一步评估,我们还在视觉关系检测(VRD)任务上测试了新提出的HIPA。该方法在TDIUC和VRD数据集上获得了最先进的结果,在VQA 2.0数据集上获得了具有竞争力的结果。
我们引入了一种基于感知动作周期(HIPA)框架的分层推理来解决VQA问题。新型HIPA在模仿人类的学习机制——感知行动周期(PAC)方面更进一步。PAC发生时,信息流从环境到人类大脑的感觉结构,然后到运动结构,然后回到环境。在人类大脑的感觉和运动结构的每一个层次上都有反馈连接,以促进它们之间的交流。这种知觉(感觉结构)和动作(运动结构)之间的循环依赖关系可以描述为:“人类必须感知环境才能移动,但他们也必须移动才能感知”(Rully & Florian, 2013)。这种动态学习通过将视觉模态视为一种感知,将语言模态视为一种动作,符合我们的VQA问题。语态被认为是一种动作,因为问题中包含激活大脑动作运动皮层区域的动作词。此外,在我们的视觉质量问题中,我们遵循人类感知的心理过程来理解视觉形态。人类感知的心理过程是通过以下方式进行的:(i)发现显著的显著特征(注意),(ii)将显著的视觉特征组织成有意义的结构(组织),以及(iii)解释视觉结构并理解它们(解释)(琼,2017)。提出的框架HIPA采用知觉的心理过程来处理视觉模态,分为三个阶段:注意、组织和解释。另一方面,语言情态的形成经历三个阶段:注意、解释和条件作用。
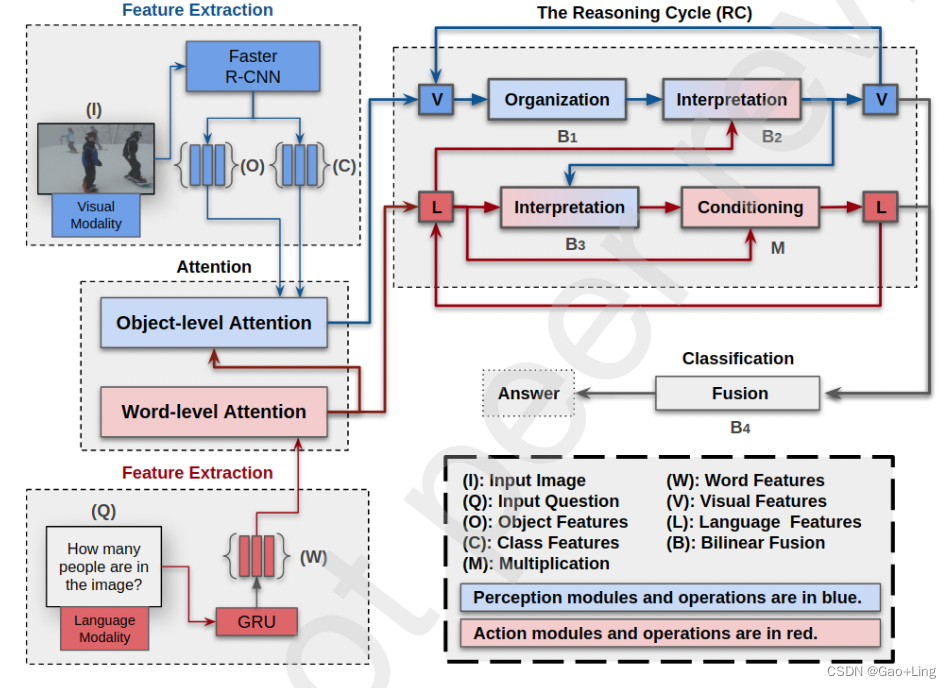
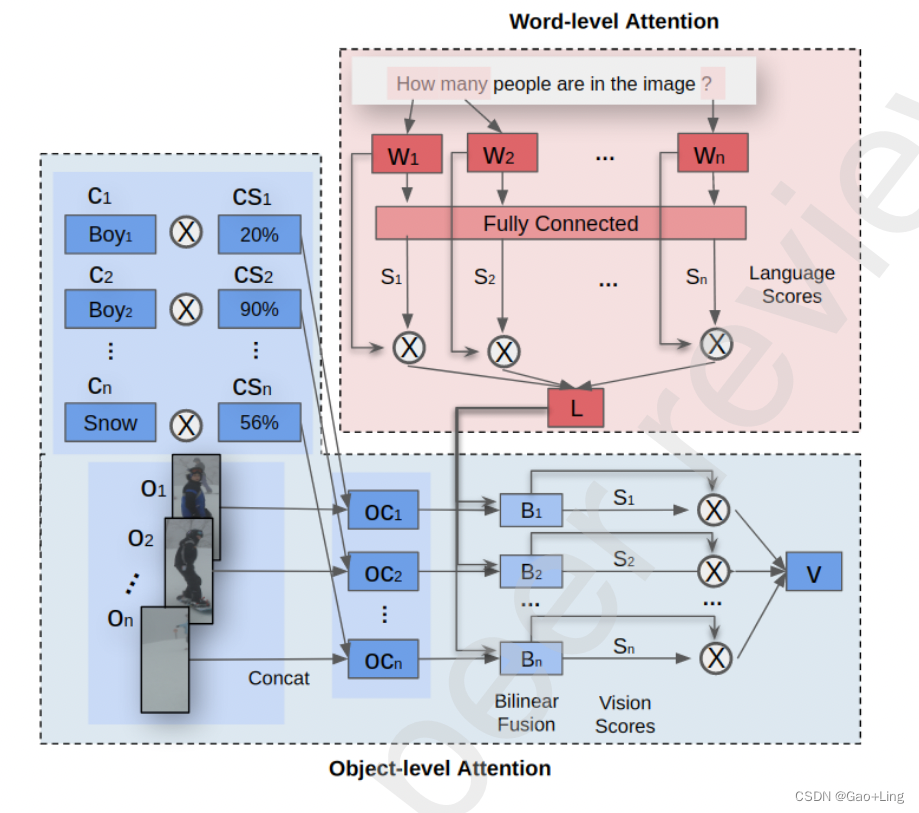
如图所示,所提出的框架HIPA一般分为四个模块:
- 特征提取(包括Faster R-CNN和门控循环单元(GRU))、
- 注意力(包括对象级注意力和词级注意力)、
- 推理周期
- 分类
我们以循环和分层的方式模拟了PAC机制,特别是在注意力和推理循环模块中。在图1中,PAC机构的感知模块和动作模块分别用蓝色和红色表示。我们结合人类知觉的心理过程,在对象层面的注意和推理模块中处理视觉模态。
如图1所示,视觉情态的推理过程包括三个阶段:对象级注意、组织和解释。
-
一方面,对语言情态的理解分为三个不同的阶段:关注问题中最相关的单词(词级注意),解释与图像相关的语言特征(解释),以及将被解释的多情态特征调节到语言情态上(条件作用)。其中有两个注意力模块,即语言词级注意力模块和视觉对象级注意力模块。问题Q被输入到GRU中,然后GRU词嵌入W通过词级注意力模块将这些嵌入聚合到语言特征L中。词级注意力模块计算每个词的注意力分数,然后取词嵌入的加权和。
-
另一方面,将图像I输入Faster R-CNN,获得对象特征O和类特征C。然后,视觉对象级注意力模块将O和C连接起来,并为每个对象及其类分配一个分数。视觉特征V是连接的对象及其类的加权和。
-
在注意模块之后,进行推理循环,以迭代地理解视觉和语言模式,如图1所示。推理循环在聚集的特征V和L上迭代,以模拟PAC人类学习机制的分层性质。
为了视觉理解,推理循环将V与自身融合,组织成更有意义的视觉特征,以方便所有视觉特征之间的交互。
接下来,它根据语言特征L对它们进行解释。在语言理解的情况下,推理循环首先根据语言特征L对应的视觉特征V对它们进行解释。然后它对L进行解释,以保持问题的核心特征。 -
最后,经过多次推理循环,提出的框架HIPA通过合并视觉和语言特征对正确答案进行分类。
我们在两个不同的VQA数据集上评估我们的框架:**VQA 2.0**和**TDIUC**。我们对HIPA的每个功能进行了广泛的消融研究,特别是在注意力模块和推理周期上。此外,我们在视觉关系检测(VRD)任务上评估了我们的方法,以进一步评估对视觉模态特征的理解。我们将组织模块合并到VRD框架中,该框架对各种可视对象之间的关系进行了分类。此外,我们使用余弦相似度和曼哈顿距离的标准偏差来评估推理周期产生的视觉和语言特征。我们认为,具有相同答案的图像-问题对最终应该具有相似的视觉和语言特征。因此,标准偏差很好地表明了特征之间有多接近,以及在推理周期后异常值出现的频率。与其他框架相比,我们的框架显示出较低的标准偏差。定性研究主要在注意模块和使用余弦相似度评分和注意图评估特征的推理循环中进行。
主要贡献
- 受PAC机制的启发,HIPA遵循一种分层模式,通过对两种模态使用注意力模块来独立地解释视觉和语言特征,然后将聚合的特征传递到推理循环中。
- 受人类感知心理过程的启发,HIPA提出将视觉理解分为注意、组织和理解三个阶段。视觉理解的划分促进了对视觉特征的框架理解。
- 我们使用余弦相似度和曼哈顿距离的标准差作为视觉和语言特征的评价指标。与其他VQA框架相比,提出的HIPA获得了更好的标准差分数。
- 本文提出的方法在TDIUC和VRD数据集上取得了先进的性能,并且在VQA 2.0数据集上具有竞争力的结果
HIPA框架
3.1. Visual and language features extraction
从Faster R - CNN模块和GRU模块中提取视觉初始特征和语言初始特征。
3.2. The implementation of perception action cycle (PAC)感知动作循环
在初步提取视觉和语言特征后,注意力模块和通过PAC原理对两种模态进行理解的推理循环,如图1所示。语言模态被加工为动作,而视觉模态被认为是感知。视觉特征最初通过object-level attention module,只关注相关的object,然后通过organization module获得更有意义和可理解的模式,以便模型可以学习如何根据语言特征来解释它们。对于语言特征的理解,语言特征被送入word-level attention module,随后根据视觉特征进行解释。被解释的语言特征随后在其上一个时间步特征的基础上进行条件化,以保持显著的语言特征。
2种attention
注意力阶段通过两个注意力模块(object-level attention module和word-level attention module)关注视觉和语言模态中最相关的实体。
- 对于语言模态,使用word-level attention module,通过为每个单词分配一个分数来找到最相关的单词。它随后在单词维度上应用了一个加权和函数。聚合后的语言特征记为L。
- 对于视觉模态,有3个初始视觉特征:objects( O )、classes( C )和confidence scores( CS ),它们从Faster R - CNN模块中获得。为了获得最终的视觉特征V,对这三个特征进行了利用。如公式所示。( 6 ),
object-level attention module将( C )与其对应的( CS )相乘,便于丢弃置信度分数较低的类。随后,乘法的输出与它们对应的对象特征( O )串联,以提升整体视觉特征( 最终结果记为OC ):
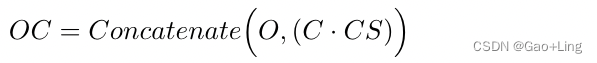
双线性融合模块被作为获取visual attention scores的引导机制。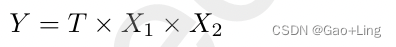
双线性融合的输出(Y)是一个关系向量,编码并捕获两个输入向量X1和X2之间的相关性。T∈RI × J × K是将输入映射到输出Y的可学习张量。
OC的注意力分数( sn∈S)由language and visual modalities的关系向量( R )获得:
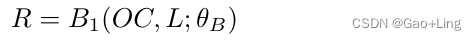
visual attention scores( S )通过使用全连接层从关系向量( R )中计算:
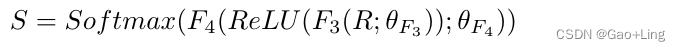
双线性融合函数记为Bn ( · ),全连接层记为Fn ( · ),其中n为第n个。
final aggregated visual features最终的聚合视觉特征( V )是通过object维度上的加权和函数得到的:
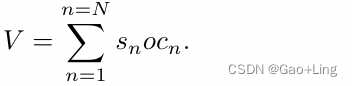
Reasoning cycle推理循环
推理循环是一个循环模块,主要负责视觉和语言模态的相互联系。
对于视觉模态的理解,视觉特征( V )最初被组织成更有意义和可理解的特征。之后,模型学习如何根据语言特征来解释这些特征。
对于语言模态而言,语言特征( L )是相对于其对应的视觉特征直接解释的。然后,以t - 1时刻的语言特征为条件,对t时刻的语言特征进行解释。由于视觉模态和语言模态在VQA任务中的角色差异,语言模态需要条件功能来保持问题的关键意义和意图。推理循环迭代两种模态,并将它们的理解联系起来。这种视觉特征的循环连接提高了对语言特征的理解,反之亦然。
推理循环模块 RC ( · )如下,其中t表示时间步长:
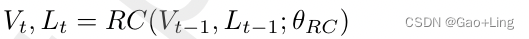
Comprehension of visual features 视觉特征的理解
推理循环中对视觉特征的理解分为两个阶段。首先,推理循环模块使用双线性融合模块将视觉特征组织成更有意义的特征。它被用来组织视觉特征,以捕获所有其他视觉特征之间的关系。如前所述,双线性融合以两个向量作为输入来计算关系向量。在推理循环的组织阶段,双线性融合模块以Vt−1为第一输入,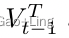 为第二输入。双线性融合产生了一个视觉关系向量,它编码了所有视觉特征的关系和相互作用。推理循环中的组织步骤如下:
为第二输入。双线性融合产生了一个视觉关系向量,它编码了所有视觉特征的关系和相互作用。推理循环中的组织步骤如下:
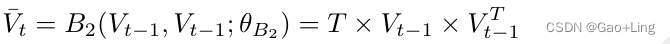
其中θB2为可训练参数。在经典方法中,视觉特征通过全连接层投射到嵌入空间。然而,我们利用双线性融合的建模能力来促进视觉特征之间的相互作用。
解读阶段interpretation phase是理解视觉模态的下一步。在这一阶段,我们解释和捕获了关于他们的语言特征的重要视觉相关性。双线性融合模块B3编码两种模态的相互作用:
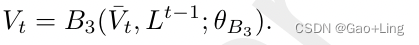
visual features和Language features的融合有助于根据相应的问题学习复杂且相关的视觉特征。
Comprehension of language features 语言特征的理解
Language features与visual features略有不同,因为它们在VQA任务中需要不同的理解水平。在视觉形态中,有一些视觉objects和features可能包含与问题的答案无关的内容。然而,这与language modality不一样,language modality中的每个词在理解问题和给出正确答案方面都起着重要的作用。因此,在推理过程中,对语言形态的理解分为解释和条件反射两个阶段。
在第一阶段,框架解释language features,并通过双线性融合模块捕获它们与相应视觉特征的交互。随后,该框架通过一个乘法函数,在前一个时间步长(Lt−1)的language features上,对某个时间步长(Lt)的解释语言特征进行限制。限制阶段避免了对问题意义有贡献的重要特征的不必要损失。语言理解的两个阶段如下:
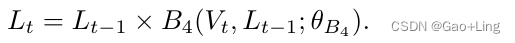
3.3. Classification Module
框架的最后阶段,聚合的视觉和语言特征被合并在一起,以获得每个可能答案的得分。