文章目录
学习代码
https://github.com/xu1211/spark-test
Spark
大数据计算框架
- 特点:比hadoop快
hadoop每次计算中间结果存入hdfs磁盘,使用时再次磁盘读取
Spark是基于内存计算的
Spark提供了6大组件:
Spark Core
Spark SQL:sql和结构化数据处理
Spark Streaming:流处理
Spark MLlib:机器学习
Spark GraphX:图形处理
SparkR:R 语言包
Spark Core 概念
SparkContext
应用启动时创建的Spark上下文对象
一个JVM只能运行一个SparkContext
能够让 Spark程序 通过资源管理器(Resource Manager)访问Spark集群
- SparkConf
创建SparkContext前应该创建SparkConf
SparkConf指导了spark如何在集群上去请求资源,同时也控制了每个work node的上的container的数目、内存大小和core的数量。
//创建 SparkConf
val conf = new SparkConf().setAppName("WordCount")
//创建 SparkContext
val sc = new SparkContext(conf)
资源管理器
可以是Spark Standalone,Yarn或者Apache Mesos。
单机使用时,Spark还可以采用最基本的local模式。
Spark支持三种分布式部署方式,分别是standalone、spark on mesos和 spark on YARN
RDD
只读 弹性 分布式 数据集
只读:不能修改,每次需要创建新的RDD
弹性:容错性:可以重新计算,可缓存持久化
分布式:存储在不同节点
创建方式
- 从对象
val no = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val RDD1 = sc.parallelize(no)
// map()函数 :pairRDD 键值对RDD
val RDD2 = no.map(data => (data * 2))
- 从文件
val txtRDD = sc.textFile("data.txt")
var hFile = sc.textFile("hdfs://localhost:9000/inp")
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder.appName("AvgAnsTime").master("local").getOrCreate()
val jsonRDD = spark.read.json("path/of/json/file").rdd
val dataRDD = spark.read.csv("path/of/csv/file").rdd
val dataRDD = spark.read.textFile("path/of/text/file").rdd
分区
创建RDD时指定 并行度、分区数量
//设置10个分区
sc.parallelize(data, 10)
分区数据并行计算
尽可能使得分区的个数,等于集群核心数目或者倍数
一般要求每个CPU处理2到4个分区
缓存/持久化 机制
为了防止重复计算,手动 对关键RDD进行持久化 到本地 内存或磁盘
进程结束后会被清空
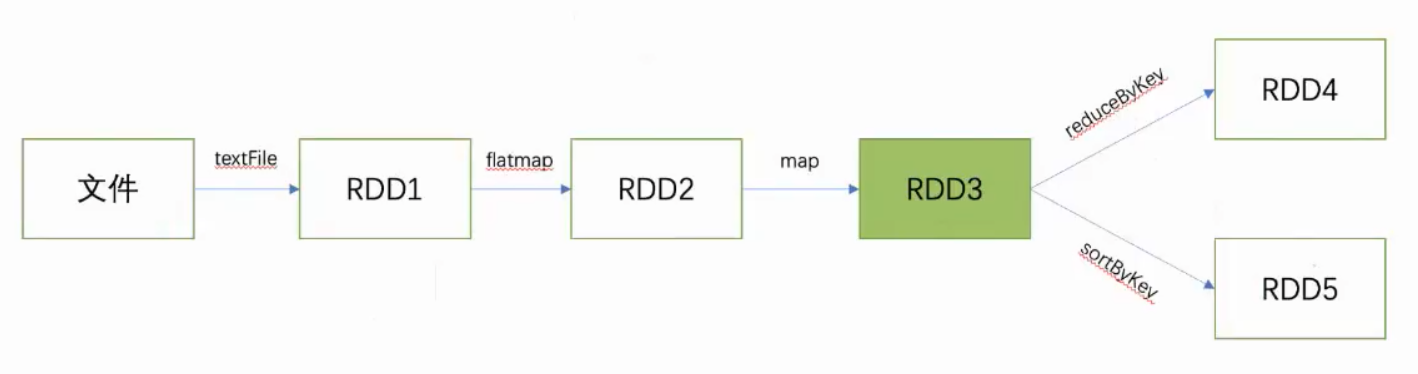
例:持久化RDD3,进行RDD5计算时就不需要重新计算RDD1与RDD2了
RDD3.persist(StorageLevel.MEMORY_ONLY)
//persist(StorageLevel.MEMORY_ONLY)的简写
RDD3.cache()
//清除缓存
RDD3.unpersist()
- StorageLevel 持久化存储级别
- MEMORY_ONLY 仅内存(最快、默认、放弃溢出部分数据)
- 仅磁盘
- 内存+磁盘
- 仅内存 +容错副本
- 内存+磁盘 +容错副本
- 仅内存 +序列化存储
- 内存+磁盘 +序列化存储
检查点CheckPiont
对RDD快照到文件系统
SparkContext.setCheckpointDir(directory: String)
RDD.checkpoint()
防止故障:在程序发生崩溃的时候,Spark可以恢复此数据,并从停止的任何地方开始
可被其他spark程序使用
算子
把一个RDD转换为另一个RDD
分类
- Tranformation 转化算子
以RDD做为输入参数,然后输出一个或者多个RDD;过程不会修改输入RDD。
转换算子是惰性的,不会立刻执行,遇到行动算子一起执行
Map()
flatMap()
Filter()
distinct()
union()
intersection()
subtract()
cartesian()
groupBy()
join()
- Action 行动算子
数据的计算部分
count()
reduce()
collect()
依赖
rdd窄依赖、宽依赖
窄依赖:当前RDD的计算只依赖上一个RDD的一个分区
宽依赖:当前RDD的计算依赖上一个RDD的所有分区,需要上一个RDD全部分区处理完成操作后才能计算
task、Executor
Executor是spark任务(task)的执行单元
负责执行分配给它的Task。task执行完之后executor就会把结果发送给驱动程序
Stage划分
划分计算阶段,一组task任务称为一个Stage
- 划分方法
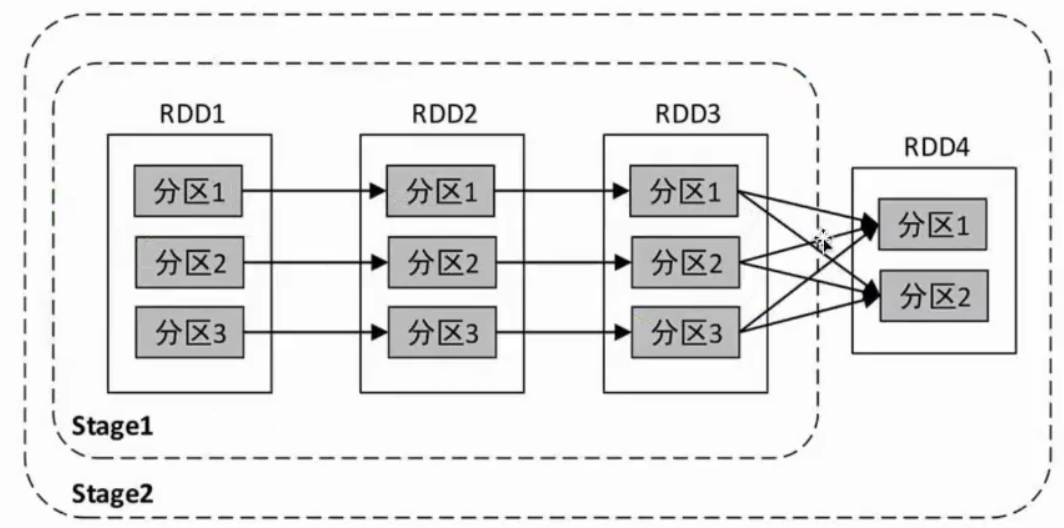
遇到宽依赖前的所有RDD划分为一个Stage,把窄依赖的task划分到一组
窄依赖Stage可以由多个task并行计算
例:
Stage1可以由3个task并行计算
Stage1计算完成后才能进行Stage2
- Stage分类
- ShuffleMapStage
Stage处理完后,进行Shuffle操作 - ResultStage
Stage处理完后,进行result输出操作
- ShuffleMapStage
DAG有向无环图
利用这些依赖关系把Job所有stage串连起来形成一个有向无环图
解决 Hadoop MapReduce 框架的局限性
- 不知道接下来会有哪些Map Reduce
- 每一步的输出结果,都会持久化到硬盘或者 HDFS 上
DAG,可以优化计算计划,比如减少 shuffle 数据。
DAG的工作流程:
- 解释器
Spark 通过使用Scala解释器解释代码,并会对代码做一些修改。 - operator graph 算子图
在Spark控制台中输入代码时,Spark会创建一个 operator graph 算子图, 来记录各个操作。 - DAG scheduler
当一个 RDD 的 Action 动作被调用时, Spark 就会把这个 operator graph 提交到 DAG scheduler 上。 - Stage
DAG Scheduler 会把 operator graph 分为各个 stage。 一个 stage 包含基于输入数据分区的task。DAG scheduler 会把各个操作连接在一起。 - Task Scheduler
这些 Stage 将传递给 Task Scheduler。Task Scheduler 通过 cluster manager 启动任务。Stage 任务的依赖关系, task scheduler 是不知道的。 - Worker执行
在 slave 机器上的 Worker 们执行 task。
共享变量
广播变量(broadcast variable)
累加器(accumulator)
Spark程序开发
- 创建SparkContext 对象
- 创建RDD
- 算子计算RDD
- 输出结果
- 关闭SparkContext
执行
-
命令行窗口
bin/spark-shell
自动生成SparkContext 对象 sc -
提交jar包运行
bin/spark-submit --class className xxx.jar
Spark Streaming
批处理的流式(实时)计算框架
原理是把输入数据以某一时间间隔批量的处理,当批处理间隔缩短到秒级时,便可以用于处理实时数据流
- 输入输出

输入:Kafka、Flume、HDFS和Kinesis等各种来源的实时输入数据
输出:HDFS、Databases等
微批次
Spark Streaming 对待数据是粗粒度的处理方式:即一次处理一小批数据
其他框架往往采用细粒度的处理模式:即依次处理一条数据
Spark Streaming接收这些实时输入数据流,会将它们按批次划分,然后交给Spark引擎处理

DStream 离散流
代表了一个持续不断的数据流
本质上表示RDD的序列。任何对DStream的操作都会转变为对底层RDD的操作

创建
- 使用数据源产生的数据流创建DStream,
- 在已有的DStream上使用一些操作来创建新的DStream。