因为最近在学习与使用Spark,所以对一些基础概念与术语做一些梳理。用来加深映像同时方便后续复习
spark是一个基于内存的分布式计算框架,可无缝集成于现有的Hadoop生态体系。主要包括四大组件:Spark Streaming、Spark SQL、Spark MLlib和Spark GraphX。
Spark运行中涉及到的一些基础概念如下:
-
mater:主要是控制、管理和监督整个spark集群
-
client:客户端,将用应用程序提交,记录着要业务运行逻辑和master通讯。
-
Application:用户自定义的Spark程序,用户提交后,Spark为App分配资源将程序转换并执行。
-
sparkContext:spark应用程序的入口,负责调度各个运算资源,协调各个work node上的Executor。主要是一些记录信息,记录谁运行的,运行的情况如何等。这也是为什么编程的时候必须要创建一个sparkContext的原因了。
-
Driver Program:每个应用的主要管理者,每个应用的老大,有人可能问不是有master么怎么还来一个?因为master是集群的老大,每个应用都归老大管,那老大疯了。因此driver负责具体事务运行并跟踪,运行Application的main()函数并创建sparkContext。
-
RDD:spark的核心数据结构,可以通过一系列算子进行操作,当Rdd遇到Action算子时,将之前的所有的算子形成一个有向无环图(DAG)。再在spark中转化成为job,提交到集群执行。一个app可以包含多个job
-
worker Node:集群的工作节点,可以运行Application代码的节点,接收mater的命令并且领取运行任务,同时汇报执行的进度和结果给master,节点上运行一个或者多个Executor进程。
-
exector:为application运行在workerNode上的一个进程,该进程负责运行Task,并且负责将数据存在内存或者磁盘上。每个application都会申请各自的Executor来处理任务。‘

图1- spark运行架构图
spark应用(Application)执行过程中涉及到的概念:
-
Task(任务):RDD中的一个分区对应一个task,task是单个分区上最小的处理流程单元。
-
TaskSet(任务集):一组关联的,但相互之间没有Shuffle依赖关系的Task集合。
-
Stage(调度阶段):一个taskSet对应的调度阶段,每个job会根据RDD的宽依赖关系被切分很多Stage,每个stage都包含 一个TaskSet。
-
job(作业):由Action算子触发生成的由一个或者多个stage组成的计算作业。
-
application:用户编写的spark应用程序,由一个或者多个job组成,提交到spark之后,spark为application分派资源,将程序转换并执行。
-
DAGScheduler:根据job构建基于stage的DAG,并提交stage给TaskScheduler。
-
TaskScheduler:将Taskset提交给Worker Node集群运行并返回结果。
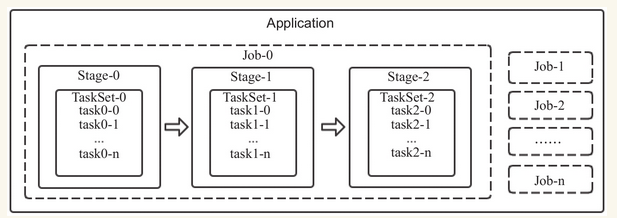
从上图中可以看出:一个Application可以由一个或者多个job组成,一个job可以由一个或者多个stage组成,其中stage是根据宽窄依赖进行划分的,一个stage由一个taskset组成,一个TaskSET可以由一个到多个task组成。