BigCode释出高效能程式码生成模型StarCoderBase,与为Python调校的StarCoder,效能超越GitHub Copilot初期版本所用的OpenAI code-cushman-001模型:
- BigCode昨晚发布了基于源代码和自然语言文本训练的编程语言生成模型StarCoder。其训练数据包含超过80种不同的编程语言,以及从github issues和commits以及notebooks中提取的文本。
- StarCoder的基座模型StarCoderBase拥有155亿个参数,支持80多种编程语言、8192个token的上下文。StarCoder是在基座模型上额外使用350亿Python语言的Token训练而成的。
Github地址:https://github.com/bigcode-project/starcoder
项目地址:https://www.bigcode-project.org/BigCodeProject
论文地址:https://drive.google.com/file/d/1cN-b9GnWtHzQRoE7M7gAEyivY0kl4BYs/view
体验地址:https://huggingface.co/spaces/bigcode/bigcode-playground

开放科学协作组织BigCode选在星战日,发布论文〈StarCoder : May the source be with you!〉,并释出150亿参数的大型语言模型StarCoderBase,以及进一步为Python调校的StarCoder模型。
两个模型皆使用大量GitHub上的授权程式码进行训练,是目前所有开放程式码生成模型中效能最佳的模型,甚至已经超过GitHub Copilot初期版本所使用的OpenAI code-cushman-001模型。
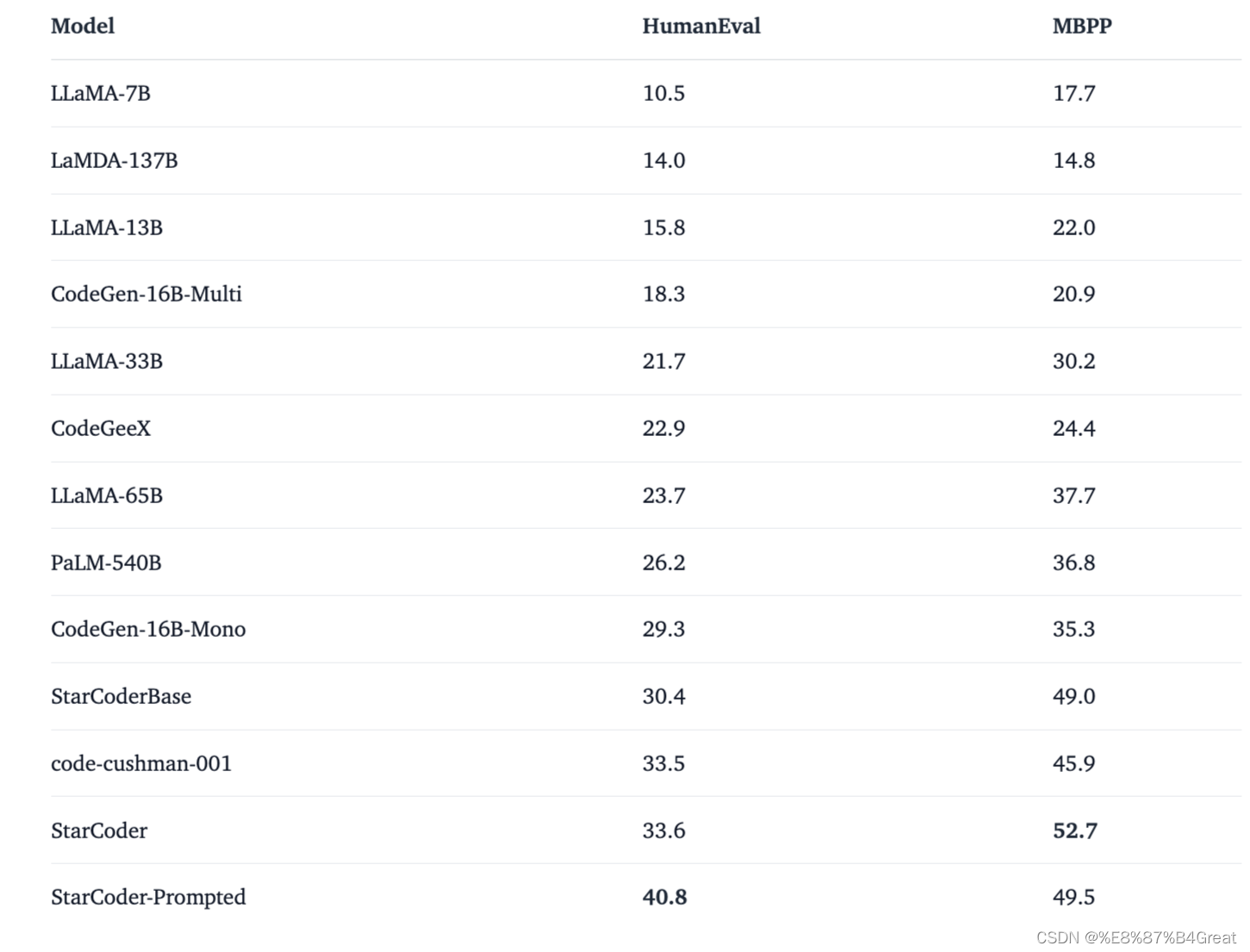
其评估结果表明,StarCoderBase优于所有支持多种编程语言的开放编程语言模型,并且媲美或优于OpenAI code-cushman-001模型。此外,StarCoder在Python上的性能优于所有经过微调的模型,在HumanEval上可以达到40% pass@1,并在其他编程语言上仍然保持其性能。
ServiceNow研究院与Hugging Face所合作成立的BigCode,是一个开放科学协作组织,该组织目标是负责任地开发程式码生成大型语言模型。在2022年底,BigCode先释出了一个仅有11亿参数的高效能程式语言模型SantaCoder,可生成和填充Python、Java与JavaScript程式码。SantaCoder模型虽小,但效能已经比起拥有67亿参数的InCoder,以及27亿参数的模型CodeGen-multi还要好。
StarCoderBase是更大型的程式码生成模型,开发团队使用大量的程式码训练,涵盖80多种程式语言、Git提交、GitHub问题和Jupyter笔记本,模型总共从1兆输入的文字单位(Token)中学习。开发团队另外用350亿个Python Token微调,生成StarCoder模型。
StarCoder模型的优点之一,是可以处理比其他大型语言模型更多的输入,可以接受高达8,000个Token,而这将能支援更多样的应用,像是经过一系列的对话指示,便可使StarCoder成为技术助理。而StarCoder也能胜任一般程式码生成模型所能达成的任务,像是自动完成程式码,遵循指令修改程式码,以及用自然语言解释程式码片段等。
开发团队将StarCoder与类似模型,以Python基准测试HumanEval进行测试,了解StarCoder与其他模型在能力上差异。实验发现,虽然无论是StarCoderBase还是StarCoder,模型规模都较PaLM、LaMDA和LLaMA小得多,但是表现却更好,并且也能比Salesforce CodeGen-16B-Mono和OpenAI code-cushman-001模型生成更好的结果。
由于StarCoder是一个多语言模型,因此开发团队也使用MultiPL-E基准测试进行比较,在多语言上,StarCoder表现比OpenAI code-cushman-001模型更好,并在资料科学DS-1000基准测试上,击败其他开放存取模型。