simOTA 出现在YOLOX中,是作为正样本匹配,能达到自动分析一个Gt 需要匹配哪些正样本。要解决的问题就是M个正样本如何分配给N个Gt 框去做预测的优化问题。
步骤大致是先进行正样本的预筛选,然后通过计算预选框与gt 框的代价矩阵,
1、正样本预筛选
与 FCOS 类似,YOLOX 是基于Anchor-Free 的。对落在Gt 框中的特征点预测位置的样本为正样本。
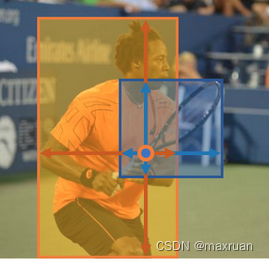
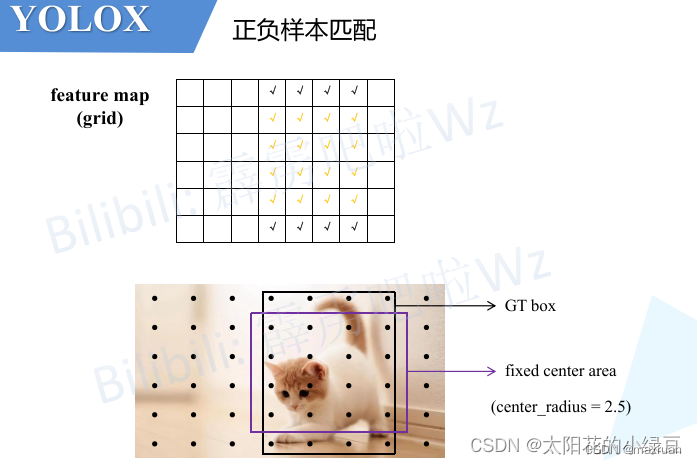
2、Cost 代价矩阵计算
Cost 公示如下:
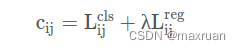
即一个候选框i与一个gt框的代价函数为三部分组成,
1、分类准确度
2、回归准确度
3、是否在GT Bbox与fixed center area交集内。
lamda 为一个超参数,论文中取 3.0 。
cost = pair_wise_cls_loss + 3.0 * pair_wise_ious_loss + 100000.0 * (~is_in_boxes_and_center)
is_in_boxes_and_center 表示特征点是否在fixed center area内,如果不再,cost 将会很大,因此会优选选取在fixed center area 内部的点。
SimOTA就是根据 cost 来选取匹配的正样本,减少匹配过程产生的代价。
如果将全图特征点参加匹配,那么匹配代价意义不大,因为cost很大,因此需要像FCOS一样,取gt box 中心附近固定区域的优质正样本参与计算,在匹配过程产生的cost较小。
3、样本与真值匹配
构建筛选出的样本和所有Gt的 cost 矩阵 和 IOU 矩阵:
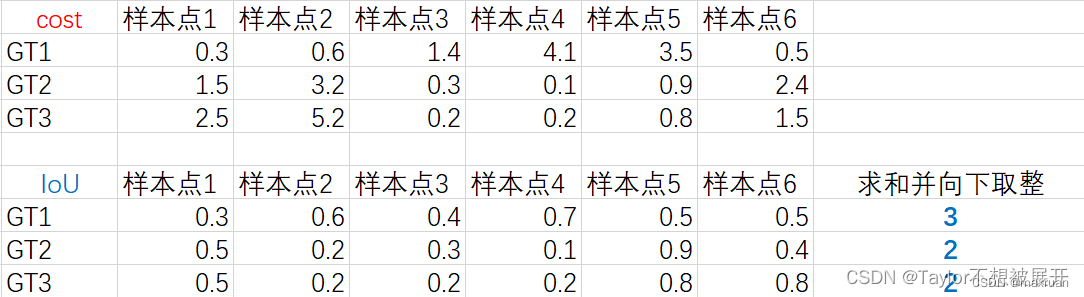
1、IOU矩阵决定当前Gt选取多少个正样本:
将所有与当前Gt匹配的正样本求IOU后进行求和并向下取整,得到 dynamic_k。
2、Cost矩阵决定当前Gt匹配哪些正样本:
得到 dynamic_k后,选择Cost较小的前dynamic_k个样本作为当前匹配。例如Gt1 选择样本1、2、6匹配。
3、同一个样本被同时分到多个Gt情况:
我们知道,同一个正样本只能负责预测一个Gt真值,否则模型不会知道它到底向哪个方向收敛,造成混乱。
如果同一正样本被分配到不同的Gt真值,则选择Cost 较小的Gt真值负责预测。例如样本3 被同时分配给了GT2 和 GT3,那么最终样本3 由GT3 匹配。
最后结果即:
GT1 :样本 1、2、6
GT2: 样本 4
GT2: 样本 3