一、SimOTA理论介绍
这里我简单的介绍一下,在YOLOX中SimOTA的标签匹配策略主要分为了两个步骤:粗筛选和细筛选。
1、粗筛选
- ①其实anchor free和anchor base 差不多也是每个grid都要去预测anchor,如果这个anchor的中心点的如果落入了GT里,那这个anchor就是一个正样本。
- ②扩充正样本:如果anchor的中心点落入了以GT中心点为中心5*5的格子内,那这个anchor也是正样本。
- 如下图,红色为GT框,绿色为5*5的框,只要anchor的中心点落在二者并集范围内就是正样本。

这部分代码在get_in_boxes_info中。代码注释如下:
def get_in_boxes_info(
self,
gt_bboxes_per_image,
expanded_strides,
x_shifts,
y_shifts,
total_num_anchors,
num_gt,
):
# 8400个中心点 判断哪些在GT框内
expanded_strides_per_image = expanded_strides[0] # 每个stride
x_shifts_per_image = x_shifts[0] * expanded_strides_per_image # 真实图片的左上角x
y_shifts_per_image = y_shifts[0] * expanded_strides_per_image
x_centers_per_image = ( # 中心点x坐标 增加一个维度 并且 重复gt次 因为8400个 每一个都要和每一个gt的每一个去比较
(x_shifts_per_image + 0.5 * expanded_strides_per_image)
.unsqueeze(0)
.repeat(num_gt, 1)
) # [n_anchor] -> [n_gt, n_anchor]
# 中心点y坐标
y_centers_per_image = (
(y_shifts_per_image + 0.5 * expanded_strides_per_image)
.unsqueeze(0)
.repeat(num_gt, 1)
)
# 计算真实框的四边
# 左上角的x坐标
gt_bboxes_per_image_l = (
(gt_bboxes_per_image[:, 0] - 0.5 * gt_bboxes_per_image[:, 2])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
# 右上角的x坐标
gt_bboxes_per_image_r = (
(gt_bboxes_per_image[:, 0] + 0.5 * gt_bboxes_per_image[:, 2])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
# 左上角的y坐标
gt_bboxes_per_image_t = (
(gt_bboxes_per_image[:, 1] - 0.5 * gt_bboxes_per_image[:, 3])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
# 右下角的y坐标
gt_bboxes_per_image_b = (
(gt_bboxes_per_image[:, 1] + 0.5 * gt_bboxes_per_image[:, 3])
.unsqueeze(1)
.repeat(1, total_num_anchors)
)
b_l = x_centers_per_image - gt_bboxes_per_image_l
b_r = gt_bboxes_per_image_r - x_centers_per_image
b_t = y_centers_per_image - gt_bboxes_per_image_t
b_b = gt_bboxes_per_image_b - y_centers_per_image
bbox_deltas = torch.stack([b_l, b_t, b_r, b_b], 2) # 拼接
# 看最小值是否大于0 其实是判断8400个中心点哪些在目标框内
is_in_boxes = bbox_deltas.min(dim=-1).values > 0.0 # 把在目标框内的取出
is_in_boxes_all = is_in_boxes.sum(dim=0) > 0 # 在目标框内的 几个数 看有多少个
# in fixed center
# 这部分判断中心点在 5*5哪个区域中
center_radius = 2.5
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors
) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0]).unsqueeze(1).repeat(
1, total_num_anchors
) + center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors
) - center_radius * expanded_strides_per_image.unsqueeze(0)
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1]).unsqueeze(1).repeat(
1, total_num_anchors
) + center_radius * expanded_strides_per_image.unsqueeze(0)
c_l = x_centers_per_image - gt_bboxes_per_image_l
c_r = gt_bboxes_per_image_r - x_centers_per_image
c_t = y_centers_per_image - gt_bboxes_per_image_t
c_b = gt_bboxes_per_image_b - y_centers_per_image
center_deltas = torch.stack([c_l, c_t, c_r, c_b], 2)
is_in_centers = center_deltas.min(dim=-1).values > 0.0
is_in_centers_all = is_in_centers.sum(dim=0) > 0
# in boxes and in centers 取两者并集 5*5和GT的并集
is_in_boxes_anchor = is_in_boxes_all | is_in_centers_all
# 这个取得是GT和5*5的交集 粗筛选完毕
is_in_boxes_and_center = (
is_in_boxes[:, is_in_boxes_anchor] & is_in_centers[:, is_in_boxes_anchor]
)
return is_in_boxes_anchor, is_in_boxes_and_center
2、细筛选
在细筛选之前我们将粗筛选的正样本去计算损失,每一个anchor 去计算其相对与每一个gt box的分类损失cls_loss、位置损失iou_loss。根据这两个损失我们会得到一个cost矩阵。
代码如下:
cost = (
pair_wise_cls_loss # BCE计算的分类损失和目标置信度损失
+ 3.0 * pair_wise_ious_loss # IOU定位损失
+ 100000.0 * (~is_in_boxes_and_center) # 如果不是正样本那它的损失巨大
)
计算损失,得到cost矩阵后。比如我们得到了1147个正样本,有3个GT框。
- ①1147个正样本和每个GT框取计算IOU值,每个GT框取top10的IOU的正样本。
- ②将这10个正样本的IOU值加在一起。像下面这副图。

- ③加在一起的IOU值像下取整,得到的数,就是每个GT框新得到的正样本的个数,比如上图,GT1要匹配三个正样本,GT2匹配四个,GT3匹配3个。
- ④编码:将所有正样本编为0(30个),上一步匹配到的正样本(3+4+3)编为1,如下表:
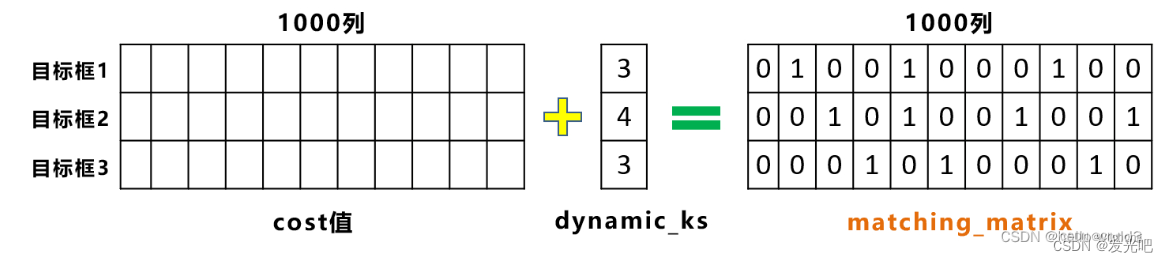 - ⑤可以发现GT1和GT2共用了一个anchor,此时看这个anchor和GT1和GT2的cost值,将cost值小的那个编码为1,大的那个置0。
- ⑤可以发现GT1和GT2共用了一个anchor,此时看这个anchor和GT1和GT2的cost值,将cost值小的那个编码为1,大的那个置0。
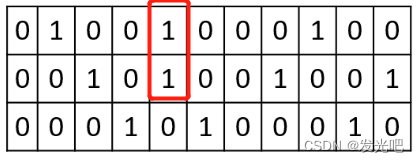
经过以上步骤,每个GT就得到了最终的正样本,即为编码为1的位置为正样本。
这部分代码如下(真的不太好理解):
def dynamic_k_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
# 比如经过粗筛选此时正样本的个数为1157个 10个GT
# cost [10,1157] 计算10GT个和所有正样本的cost
# pair_wise_ious [10,1157] 要计算这个10个和所有正样本的IOU
# gt_classes [10] 10个GT的类别
# num_gt
# fg_mask [8400] 1157个ture 其余为False
# Dynamic K
# ---------------------------------------------------------------
matching_matrix = torch.zeros_like(cost, dtype=torch.uint8) # [10,1157]个0 占位
ious_in_boxes_matrix = pair_wise_ious
n_candidate_k = min(10, ious_in_boxes_matrix.size(1)) # 就是10
topk_ious, _ = torch.topk(ious_in_boxes_matrix, n_candidate_k, dim=1) # 从大到小排序取前10个IOU [10,10] 10个GT取前十个正样本
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1) # torch.clamp 的意思是让它不小于1
# 得到比如[6,4,5,7,9,8,9,5,8,9] 这10个数是每个GT要选择的正样本个数
dynamic_ks = dynamic_ks.tolist()
for gt_idx in range(num_gt): # num_gt=10,第一个 gt_idx=0,cost[0],k=dynamic_ks[0], 也就是第一个GT会有六个iou最大正样本 这六个从小到大排列
_, pos_idx = torch.topk( # pos_idx = ([28,776,40,41,27,766]) 这个6个的索引值
cost[gt_idx], k=dynamic_ks[gt_idx], largest=False
)
matching_matrix[gt_idx][pos_idx] = 1 # 将上面6个的占位变为1
del topk_ious, dynamic_ks, pos_idx
anchor_matching_gt = matching_matrix.sum(0) # [10,1157] 每一列的数相加 看是否有一个正样本被两个gt共用的情况
if (anchor_matching_gt > 1).sum() > 0:
_, cost_argmin = torch.min(cost[:, anchor_matching_gt > 1], dim=0) # 取cost最小的正样本
matching_matrix[:, anchor_matching_gt > 1] *= 0 # 这一列所有的数先全为0
matching_matrix[cost_argmin, anchor_matching_gt > 1] = 1 # cost最小的正样本为1
fg_mask_inboxes = matching_matrix.sum(0) > 0 # 每一列相加 >0 ,是正样本的anchor变为Ture [1,1157] 有70个为true
num_fg = fg_mask_inboxes.sum().item() # 正样本的个数
fg_mask[fg_mask.clone()] = fg_mask_inboxes # 8400中正样本中ture的个数由1157变为70
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0) # 每个正样本对应的GT框的索引 [70]
# fg_mask_inboxes是70个正样本 也就是 每一列中最大的那个数为1 argmax返回最大的那个 就是1对应的GT
gt_matched_classes = gt_classes[matched_gt_inds] # 每个正样本对应的类别
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[ # 每个正样本和真实框对应的iou matching_matrix就是0 1矩阵 70个1
fg_mask_inboxes
]
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds