目录
LOD是一种基于层次变换的方法,是Level Of Details的缩写,即细节层次,由Clark于1976年首次提出,已广泛用于计算机图形的实时3D技术中。
G-PCC提出了利用LOD对点云属性压缩的方法,现阶段LOD在点云压缩中的主要作用是属性信息的预测编码。
G-PCC标准中属性编码LOD划分方法如下
一、LOD生成
原理
LOD生成过程(如图1)是根据计算曼哈顿(manhadun)距离和用户自定义距离的关系将点云数据中各点重新组织成一系列的层次
。 (曼哈顿距离介绍见:曼哈顿(Manhattan)距离_点云渣的博客-CSDN博客)。用户自定义距离
,并且需满足以下两个条件:
1.
2.
LOD算法实现步骤如下:
1. 将所有点标记为未访问,并将访问点集表示为V,初始状态时,V设置为空。
2. 该步骤是循环遍历的过程,每次遍历得到一个空间划分的子层。细化层次生成过程如下:
1)循环遍历所有点
2) 如果已访问当前点,则忽略该点
3) 否则,计算当前点到集合V的最小距离D
4) 如果距离D小于,则忽略当前点
5) 如果 D >= , 则当前点标记为已访问,并添加到
和 V
6) 重复此过程,直到遍历所有点
3. 将空间子层进行合并,得到每一层LOD空间划分的结果,第层的LOD划分,即
是根据空间子层
、
、... 、
的并集得到的。
4. 重复此过程,直到生成所有LOD或访问完所有点。
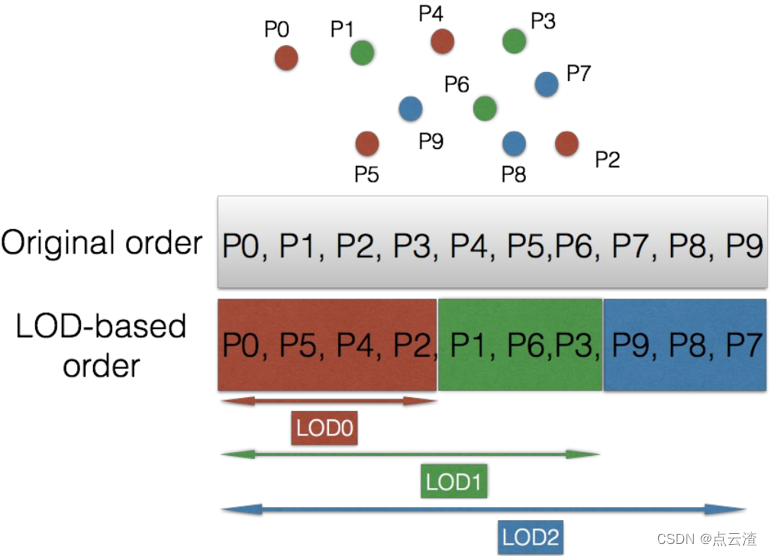
图1 (源自mpeg-pcc标准文档)
代码实现
待续
二、LOD生成的可扩展复杂性实现
原理
为了提供提升方案的可扩展复杂性实现,G-PCC引入了:
(1)使用自下而上的方法来构建LOD,而不是自上而下的技术;
(2)使用近似最近邻搜索替代精确最近邻搜索加速LOD的构建;
(3) 使用了莫顿码 (莫顿码原理见:莫顿码(Morton code)介绍_点云渣的博客-CSDN博客)
设 ,
是与点云相关联的位置集合,设
,
为与
相关联的莫顿码。
和
为两个用户自定义参数,分别指定初始采样距离和LOD之间的距离比。(
)
首先,根据相关的莫顿码按升序对点进行排序。假设 是根据这个过程排序的点索引数组。算法迭代进行,对每次迭代k,提取属于
的点,并从
开始构建直到将所有点分配给LOD。
算法执行过程如下:
1. 初始化采样距离D为:
2. 对于每次迭代k(k = 0...LOD层数)。设 L(k)是属于第k各LOD点的索引集合,O(k)是属于高于k的点的集合。L(k) 和 O(k) 的计算如下:
(1)if k = 0, L(k) = {} else L(k) = L(k-1)
(2)O(k) = {}
3. 按顺序遍历存储在数组 中的索引。每次选择索引 i 并计算 i 到 O(k)的最近SR1点的距离。SR1是用户定义的参数,用于控制最近邻居搜索的准确性。例如,SR1可以选择为8、16或64。SR1的值越小,计算复杂度和最近邻搜索的准确性就越低。如果到SR1点的距离中的任何一个小于D,则将 i 添加到数组L(k),否则,将 i 添加到数组O(k)中。
4. 迭代所有点,直到遍历完中所有索引。在这个阶段,计算L(k)和O(k)用于构建与L(k)相关的预测器。设R(k) =L(k) - L(k-1) 是需要添加到LOD(k-1)以获得LOD(k)的点的集合。我们希望在O(k)中找到 i 的h个近邻 (h为用户自定义参数,用于控制预测的邻居的最大数量),并计算与 i 相关的预测权重
。算法执行过程如下:
(1)初始化计数器 j = 0
(2)对于 R(k) 中的每个点 i ,
1)设 是与 i 相关联的Morton码,设
是与数组O(k)的第 j 个元素相关联的
Morton码。
2)当(Mi ≥ Mj ∧ ( j < SizeOf( O(k) ) )时,将计数器 j 递增1(j = j+1)
3)计算 到与 O(k) 的索引相关联的点的距离,这些点在数组的范围 [j-SR2,j+SR2]内,并跟踪h个最近的邻居(n1,n2,…,nh)及其相关的平方距离
。SR2是用户定义的参数,用于控制最近邻居搜索的准确性。SR2的可能值为8、16、32和64。SR2的值越小,计算复杂度和最近邻搜索的准确性越低。
a. 如果当前点和最后一个处理点之间的距离低于阈值,则使用最后一个点的邻居作
为初始猜测,并在它们周围搜索。
b. 迭代到 n=1,2,3,4…last点
c. 排除距离大于用户自定义阈值的点
5. ,
代码实现
待续
三、LOD属性编码的dist2值计算方法
引入了一种计算LOD生成参数的低复杂度、全自动非标准技术。
为LOD属性编码选择dist2值的一般原则是在最佳细节层次和次细节层次中获得1:4的点数比。当前的dist2值最初是在响应提案时确定的。
对于新的测试序列,dist2值(最初是一个列表)是从相似的测试序列中复制而来的,几乎不考虑正确性。
LOD子采样方案是下采样的一种形式。它需要一个平方距离值来计算二次采样率。用于编码点云的八叉树也是下采样的形式。对于八叉树的每一级,它在每个方向上以2倍的因子向下采样。
该方法的一个出发点是使用在八叉树编码过程中可以发现的信息来近似八叉树级别,产生总点数的四分之一的比率。假设密度均匀,最终发现类似表面的结构并进行下采样。由于实际上这不可能发生在两个八叉树级别之间的精确转换中,因此通过在转换两端的级别之间进行线性插值来得到LOD子采样的平方距离。图2显示了不同序列的每个八叉树级别中的点的比率。
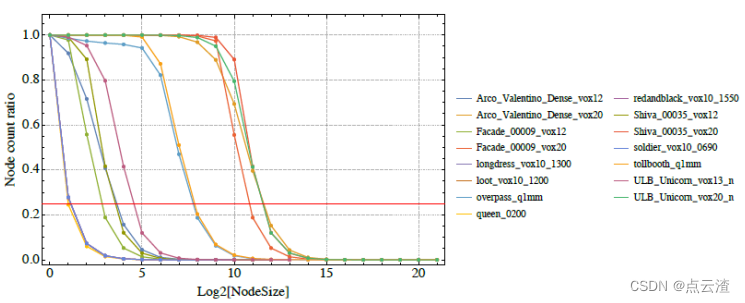
图2(源自,mpeg-pcc标准文档)
具体流程如下:
- 设lvln是第n个最低八叉树级别中唯一点的个数。lvl0表示源点云中唯一点的个数。
- 设lvlRation=lvln / lvl0为第n级唯一点与源点云中唯一点的数量之比。
- 找到满足以下条件的最小a, lvlRatioa > ¼
- 在lvlRatioa和lvlRationa+1的值之间进行线性插值,以确定y=¼时的x0值:
x0 = (¼ − lvlRatioa) / (lvlRatioa+1 − lvlRatioa) + a + 1
5. 将平方距离确定为![]()
虽然基本方法提供了一个合理的近似值,但并不总是产生所需的比率。平方距离值可以通过如下迭代插值来细化,以便以增加计算工作量为代价提高RD性能。
以i=0开始
- 使用平方距离di对点进行LoD二次采样,以确定最佳LoD点的真实比率lodRatioxi。
- 线性插值如下:
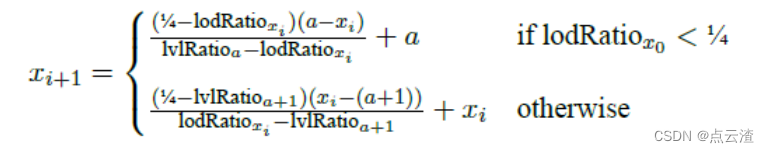
3. 重复使用连续值if i,直到达到以下任一条件:
1) lodRatioxi非常接近¼,
2)di的连续值已收敛。(因为di是整数,因此可能收敛)
4. 使用最终迭代中的di作为LoD生成的dist2。
四、基于常规采样的LOD生成
介绍了一种低复杂度的LOD生成过程,该过程可以更好地捕捉初始点分布,并可以对不规则采样点云上定义的非平滑属性信号进行更有效的预测。它具有线性复杂性,并且不需要对点进行第二次重新排序。相反,它直接利用用于确定预测邻居的点的基于莫顿的排序。
设 是有序索引的集合和
表示整个点云的关联LOD。它不是定义一组采样距离,而是定义一组表示为
的采样率,其中
是描述
的采样率的整数(例如,
=4)。与 LOD
相关联的索引的有序数组,表示为
, 通过对
进行二次采样来计算,同时保留每
个索引中的一个索引。采样率kl可以用LOD进一步更新,以便更好地适应点云分布。更准确地说,编码器可以在比特流中针对预定义的一组点(例如,每个连续的H=1024个点)显式地编码要应用于最新可用kl值的不同值或更新。kl可以基于信号的特性或点云分布、先前的统计数据自动确定,或者可以是固定的。可以针对每个属性(例如,颜色、反射率)和每个通道(例如,Y和U/V)定义不同的子采样率