基准数据集 和 task

Spatial-based GNN

从i层到i+1层
(SBC)
最后一层需要全部合起来变成一个代表的feature ,这个叫做readout,把所以节点,合起来变成一个特征,来classification或者regression。

NN4G(Neural Network for Graph )
学习这个之前先看一下Embedding Matrix
和之前一样,假设我们的词汇表有10,000个单词,词汇表里有a,aaron,orange,zulu,可能还有一个未知词标记UNK。我们要做的就是学习一个嵌入矩阵E,它将是一个300×10,000的矩阵,如果你的词汇表里有10,000个,或者加上未知词就是10,001维。这个矩阵的各列代表的是词汇表中10,000个不同的单词所代表的不同向量。假设orange的单词编号是6257,代表词汇表中第6257个单词,我们用符号O_6257来表示这个one-hot向量(这个向量除了第6527个位置上是1,其余各处都为0),显然它是一个10,000维的列向量,它只在一个位置上有1,它的高度和左边的嵌入矩阵的宽度(行数)相等。
假设用嵌入矩阵E去乘以O_6257,那么就会得到一个300维的向量,E是300×10,000的,O_6257是10,000×1的,所以它们的积是300×1的,即300维的向量。以此类推,直到你得到这个向量剩下的所有元素。得到的300维向量我们记为e_6257,这个符号是我们用来表示这个300×1的嵌入向量(embedding vector)的符号,它表示的单词是orange。
要记住我们的目标是学习一个嵌入矩阵E。在之后的操作中你将会随机地初始化矩阵E,然后使用梯度下降法来学习这个300×10,000的矩阵中的各个参数,E乘以one-hot向量会得到嵌入向量。但当你动手实现时,用大量的矩阵和向量相乘来计算它,效率是很低下的,因为one-hot向量是一个维度非常高的向量,并且几乎所有元素都是0,所以矩阵向量相乘效率太低。所以在实践中你会使用一个专门的函数(function)来单独查找矩阵E的某列,而不是用通常的矩阵乘法来做,但是在画示意图时(上图所示,即矩阵E乘以one-hot向量示意图),这样写比较方便。
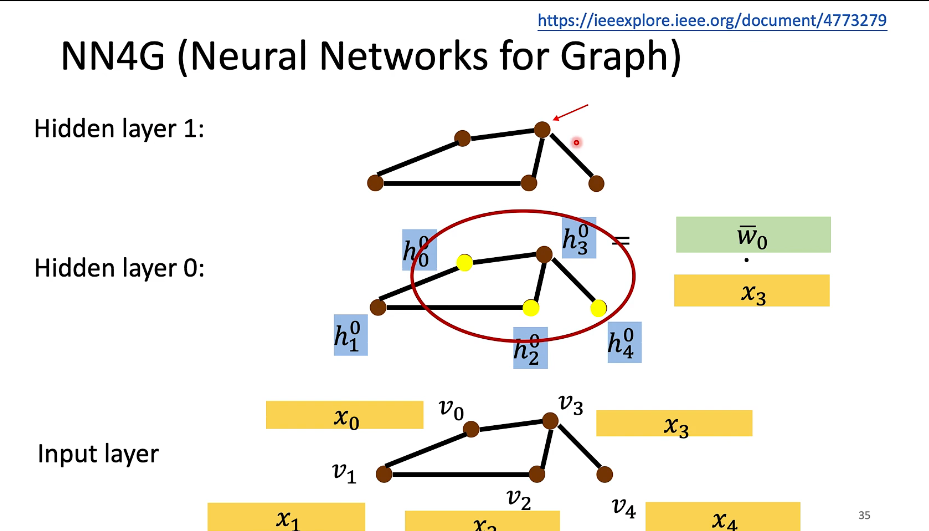
邻接接点aggregate到这个新的节点去 旁边邻居的先加起来,再加上原本input的feature。


全部加起来,各自进行一个transform 然后再加起来。代表整个graph的feature
DCNN(Diffusion-Convolution Neural Network)


把和3这个节点,距离是一的节点全部加起来 然后取平均,取完平均之后再做一个weight transform
到了第二层的时候
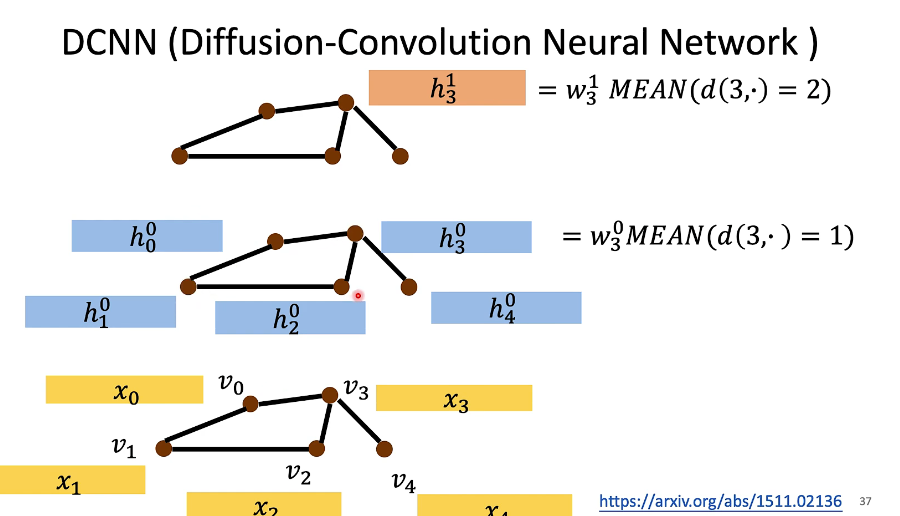
用的还是第一层的feature
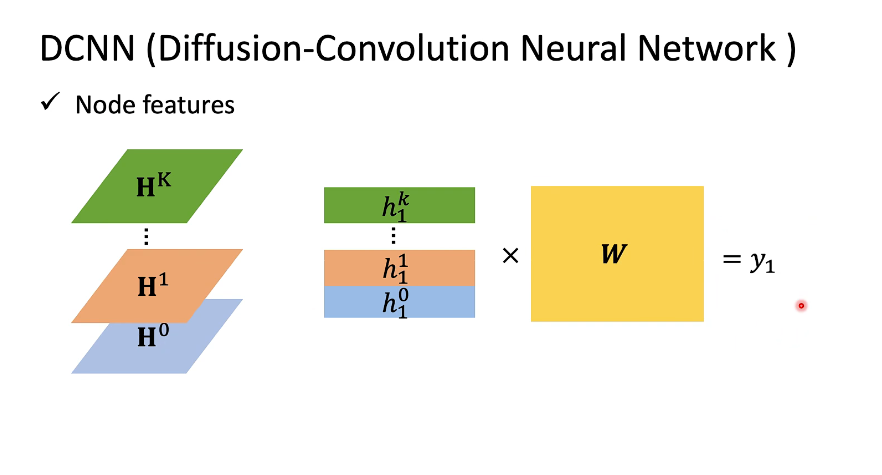
DGC(Diffusion Graph Convolution)

MoNET 

GraphSAGE

GAT(Graph Attention Networks)
GIN(Graph Isomorphism Network)
