目录
在看这篇论文的时候,我们既学习论文的思想,也学习论文的写作方式。
O. Abstract
摘要是最亮眼的部分,需要简洁明了地点出:
- 简要背景介绍,及其存在的问题或者动机。
- 提出的方法。
- 达到的效果。
作者指出,视频超分辨中最关键的环节,是从相邻帧中获取有效信息。
获取方法无非是 frame alignment 和运动补偿。
而作者正是通过引入 SPMC layer ,取得了更好的效果。
- 之前的基于 CNN 的视频超分辨方法,需要 align multiple frames to the reference 。
我们发现,合理的 frame alignment 和运动补偿,对超分辨结果非常关键。- 我们提出了 sub-pixel motion compensation (SPMC) 层。
- 该运动补偿层在 SR 网络中的适应性很好,与整体 CNN 网络配合默契,效果超过了 state-of-the-art 且不需要调参。
I. Introduction
Introduction 是对工作的概述,说白了就是对 Abstract 的全面拓展。注意以下几点:
- 在介绍动机或解决的问题时,只需要简要说明前人的工作,但目的是引出自己工作的不同和进步。
回顾前人工作不能太详细,详细部分在后面的 Related Work 部分。 - 贡献点是需要着重强调的,最好有最精炼、最亮眼的数据支持。详细数据也应该
首先作者再次强调了 alignment 对视频 SR 的重要性。这实际上也是 Motivation 。
其次,作者用两个大标题:Motion Compensation 和 Detail Fusion ,回答了 Motivation 中需要解决的两大核心问题。
最后,作者再用一个大标题:Scalability ,补充阐述了本文的第三大贡献点。
这种写作方式值得借鉴,在分段概述工作的同时,还说清楚了贡献点,简洁明了。
图像 SR 只能从 external 样本中获取先验知识(因为测试集和训练集是分开的);但对于一个好的视频 SR 系统,它必须能够从多帧中提取信息,而不借助外部力量(其他视频的样本)。
因此,多帧 align 和 fuse 是视频 SR 的两大核心问题。
Motion Compensation
帧间的剧烈运动,使得我们很难在多帧中寻找同一物体。但是,亚像素的运动是微小的,因此有助于细节的恢复。
大多数前人的工作,都通过预测 optical flow 或通过 block-matching ,来实现帧间运动补偿。
补偿完了,再用传统的方法重建 HR 图像。这种方法计算量很大。
近期的深度学习方法,是通过 backward warping 来实现运动补偿的。
我们将要证明,这个看上去合理的方法,实际上对视频 SR 而言是不合理的!通过改进运动补偿机制,SR 效果可以提升。
我们提出的是 SPMC 策略,我们将从理论分析和实验上验证它。
Detail Fusion
当然了,这一部分是 SR 的第二个核心问题。
我们提出了新的 CNN 网络,来与 SPMC 协同合作。
尽管前人的 CNN 网络也可以输出边缘清晰的图像,但是,我们不清楚这些细节是从输入中得到的,还是从外部数据中得到的(训练得到的先验知识)。
后果是,在人脸识别、文字识别等实际应用中,只有真实的细节是有效的。
因此,本文会提供 insightful ablation study ,来验证这一观点。
Scalability
这是一个一直以来被忽视,但在应用中很有意义的 SR 系统特点:可放缩性。
之前的基于学习的网络,受参数影响很大。如果输入的格式不同,那么训练好的网络参数可能就不能用了。
与之相反,我们的网络具有完全的可放缩性。扫描二维码关注公众号,回复: 4203342 查看本文章
- 我们的网络可以接收任意大小的输入;
- SPMC 不含任何可训练参数,因此缩放倍数可随意选择;
- 我们的 Conv-LSTM 可以接收任意数量的图片。
II. Relative Work
要按时间顺序,列举具有代表性的重要工作,并且指出本文工作的不同点。
要分别介绍不同环节各自的 Relative work 。
III. Sub-pixel Motion Compensation (SPMC)
概述和铺垫都介绍完了,以下是正文时刻。
网络的不同环节,可以分为多个章节介绍。这就是第一个环节。
在介绍前,一定要说清楚 notations 。有时候借助 notations ,后文讲解起来也更轻松。
比如要表示相邻的最近2帧,左、右各1帧,不妨定义帧序列,用下标来表示。
本文的做法:定义帧,帧序列,降质过程:

接下来的一张图非常重要:
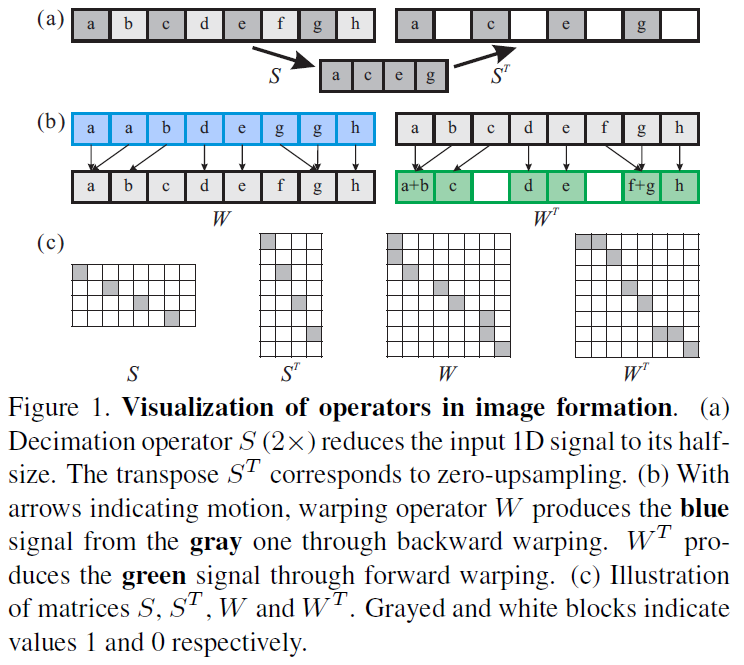
很有意思的是,我们可以把这些操作都理解为矩阵运算。
首先,每一张图片都是一个列向量。如果是一张 8x8 的图片,那么该向量维度就是64。向量中的元素非0即1。
其次,我们对图片的操作有两种:降采样和形变。
如果是2倍降采样,那么 S 矩阵就是 4x8 的,意味着 LR 图片是一个维度为16的列向量。
形变矩阵恒为 8x8 。
通过矩阵转置,我们可以看出这两种操作的转置操作的物理意义:降采样的转置是补零升采样,形变的转置操作结果看图,会产生一些新的元素。
注意,转置操作虽然不是逆操作,但操作方向是相反的。如果我们定义正向为第0帧到第i帧,那么转置操作就是从第i帧到第0帧。
现在,我们的目的就是构建这一降质过程。由于是利用多帧信息,因此事情变得不那么简单,需要考虑噪声的影响。
论文中还近似求解了降质误差最小时:

参考我的博客:https://www.cnblogs.com/RyanXing/p/9487245.html
摘抄本
0. Abstract
We show that ... is crucial. We accordingly propose a ...
For that reason.
1. Introduction
Video SR aims at recovering HR images from a sequence of LR ones.
避免 images 重复出现。
An ideal video SR system should be able to correctly extract and fuse image details in multiple frames.
这两个词的搭配在 CNN 中使用得非常频繁。
While large motion between consecutive frames increases the difficulty to locate corresponding image regions, subtle sub-pixel motion contrarily benefits restoration of details.
一句话就说清楚了,原来的局限性,和 sub-pixel 的优势。
A traditionally-overlooked but practically meaningful property of SR systems is the scalability.
简洁。
2. Related Work
With the seminal work of SRCNN, a majority of recent SR methods employ deep neural networks.
一句话介绍开端、工作和方向。