资源下载:https://download.csdn.net/download/wouderw/87402799
1,分析学生消费行为的目的
(1)分析学生的消费行为和食堂的运营状况,为食堂运营提供建议。
(2)根据学生的整体校园消费行为,选择合适的特征,构建模型,分析每一类学生群体的消费特点。
(3)构建学生消费细分模型,为学校判定学生的经济状况提供参考意见。
2,分析方法
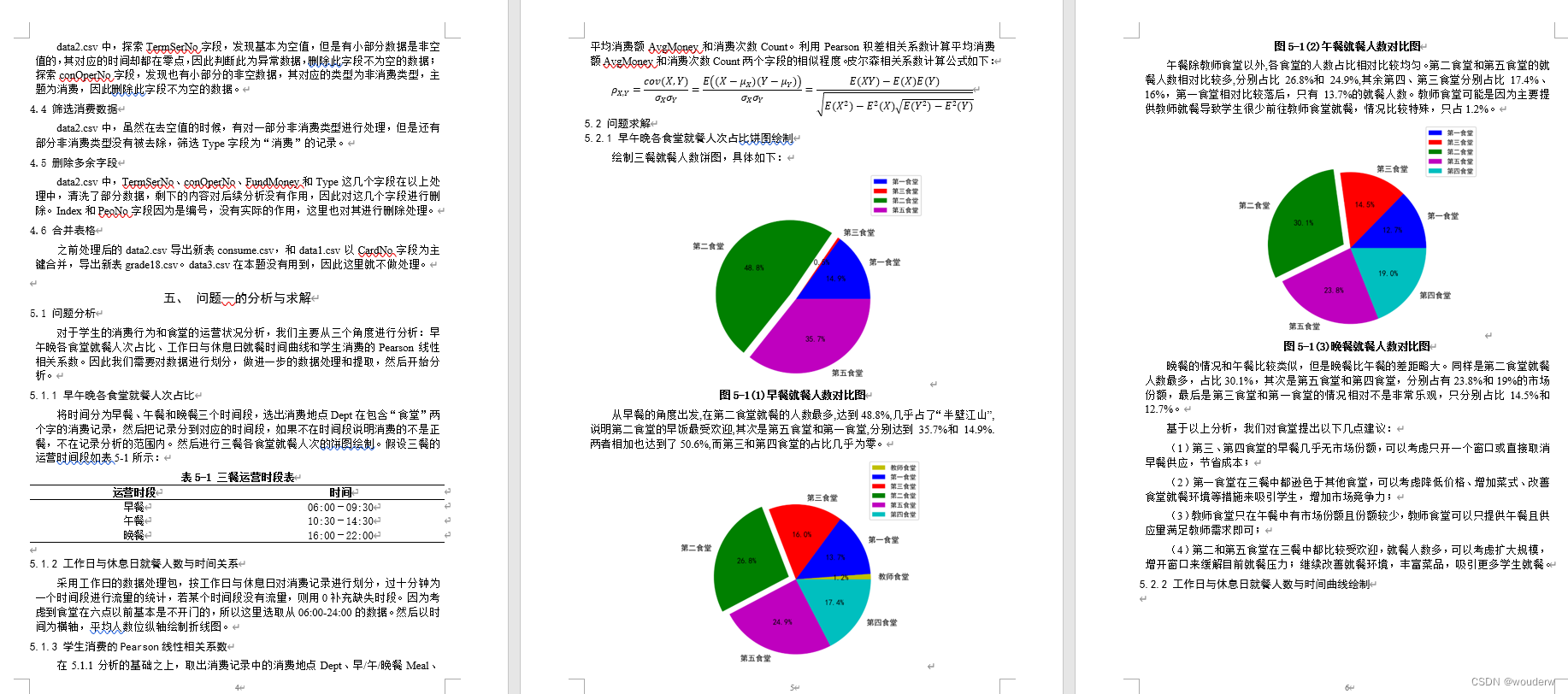
(1)对于学生的消费行为和食堂的运营状况分析,主要从三个角度进行分析:早午晚各食堂就餐人次占比、工作日与休息日就餐时间曲线和学生消费的Pearson线性相关系数。因此我们需要对数据进行划分,做进一步的数据处理和提取,然后开始分析。
(2)针对学生的整体校园消费行为,就需要考虑到学生的存储情况与消费情况,因此需要建立一个能有效刻画学生整体消费行为特征的模型。在众多的用户消费模型中,RFM模型是衡量客户消费行为的重要工具。但是考虑到本文的研究对象为学校的学生,最近一次消费这个指标在学校基本是天天消费,所以没有太大的参考价值。因为学生的消费频繁,可以增加一个储蓄情况的指标。故引入DFM模型,对学生的消费行为进行刻画,并基于DFM模型对学生进行K-Means++聚类。
(3)为了判断学生的经济状况,使用聚类方法虽然可以大致确定一个学生的消费水平,但是误差比较大,而且无法得出更多有用的信息,我们希望可以通过数据,来给学生下更加精细的划分,我们就以上题中选出的那最有可能包含需要补助学生的信息的数据集为输入数据,在DFM模型的基础上使用AHP算法进行打分,为学校判定经济状况提供更加可靠的数据。
3,模型的优缺点
优点:
(1)K-Means算法在分类中算是收敛速度比较快的,外加上我们使用的K-Means++由于对初始值做了优化,导致收敛速度更加快。
(2)无论是第二题的K-Means和第三题的AHP都相当简单,易于解释和理解。
(3)AHP每个层次中的每个因素对结果的影响程度都是量化的,非常清晰明确。
缺点:
(1)K-Means对噪声(异常值)比较铭感,所以我们花了很多时间去研究如何洗数据。
(2)K-Means的输出并不是很稳定,所以每次跑下来的结果都会有一点点差异。
4,部分代码
# %%
"""基于AHP算法细分模型"""
criteria = comparision([1, 5, 3])
b = [
comparision(deep_model['AvgSurplus'].values),
comparision(deep_model['TotalConsume'].values),
comparision(deep_model['Freq'].values)
]
results = AHP(criteria, b).run()
# %%
""""""
std = MinMaxScaler(feature_range=(0, 10)) # 标准化,不然画出来比较难看
results_t = list(map(lambda x: x * 10000, results[0]))
deep_model['Rank'] = results_t
deep_model['Grade'] = deep_model['Rank'].apply(int)
deep_model = deep_model.sort_values(by='Rank')
display(deep_model)5,资料内容