Python数据分析:用户消费行为(持续更新)
红酒品鉴和用户消费行为分析是我学习Python数据分析入门的两个案例,记录一下。
网络上关于这两个案例的介绍非常多,但是我在学习过程中,发现有很多文章的逻辑不是很清晰,代码也调试不同。
所以,还是想把自己的调试代码写出来。
参考博文:
http://www.360doc.com/content/17/0717/17/16619343_672115832.shtml
准备
1. 数据分析的目标
2. 数据集
3. 在进行数据分析之前,进行数据清洗。即:处理缺失值,数据类型转化,按照需要将数据整理好。
开始
本数据集共有 6 万条左右数据,数据为 CDNow 网站 1997年1月至1998年6月的用户行为数据,共计 4 列字段,分别是:
- user_id: 用户ID
- order_dt: 购买日期
- order_products: 购买产品数
- order_amount: 购买金额
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
columns = ['user_id','order_dt','order_products','order_amount']
# 用户id 购买日期 购买产品数 购买金额
df=pd.read_csv('G:\\Data Scientist Learning\\CDNOW_master.txt',names=columns,sep='\s+') #载入数据
print(df.head())
接下来:
df.info() #检查数据是否存在空值
数据读出无误时要检查数据中是否存在空值,并检查数据的数据类型。发现数据中并不存在空值,很干净的数据。那接下来既然我们需要每月这个数据,就要给order_dt这一列的数据进行适当的转换一下,转化成通常的时间格式:Y(年)m(月)D(日)。
下面那句代码的意思是:在df里新增加一列列名是month,取出这一列的日期order_dt然后掉取这一列的值把值转换成以月为单位的,例如6月1号到30号统统属于6月。

这时候可以对数据进行简单初步分析,用df.describe()。

对以上数据进行分析:
- 均值:产品购买数量均值在2.4;
- 中位数:中位数是2;
- 四分位数:其3/4位数是3
- 最小值和最大值分别为:1和3
- 人均消费CD金额为:35.89元;中位数为:25.98元
说明:用户购买量大部分都不多,少部分购买量大的,最高购买量是99,其中存在一定的极致干扰。用户的订单金额比较稳定,人均购买CD金额在35,中位数在25元,存在极致干扰,很多销售行业都是类似这种分布,小额比较多,大额的较少,收入来源很大一部分是来自大额。也即是二八定律。
按月分析数据趋势
在这里用到了一个groupby,一个在数据分析中非常好用的函数,这一节是要按月分析用户行为,用groupby对用户按照月分分组。
分组完成之后得到一个新的dataframe叫group_month,然后直接取出组里的order_amount并求和可得到每个月份的销售总额,并且画出折线图



从上面三个图可以看出数据没有什么问题,用户购买总额跟用户购买次数以及用户购买量走势是大致相同的,但是从四月份开始销量严重下滑,具体是原因是什么,我们可以再来看一下每个月的消费人数:

每月的消费人数小于每月的消费次数,但是区别不大。前三个月每月的消费人数在8000—10000之间,后续月份,平均消费人数在2000不到。一样是前期消费人数多,后期平稳下降的趋势。
用户个体消费数据分析:
之前的都是看趋势,现在看个体的消费水平如何。主要分析的对象是:
- 用户消费金额和消费次数的统计以及散点图来观察用户的平均消费水平
- 用户消费金额的分布图(二八原则)
- 用户消费次数的分布图
- 用户累计消费金额的占比(百分之多的用户占了百分之多少的消费额)
group_user_ID = df.groupby('user_id')
print(group_user_ID.sum().describe())
以user_id为索引进行分组,在用户的角度来看,每位用户平均购买七张CD,最少的用户购买了一张,最多购买1033张,中位数是三张,反映出有些数据的波动还是挺大,用户购买的金额平均是106中位数是43,购买最大金额是13990,四分位数19,这些数据加上之前的按月分析,大致勾勒出CD销售大致趋势,在一段时间销量上升,突然在某时期不景气开始猛地下跌,但是大部分还都是处于平稳,销售额也低。
group_userID = df.groupby('user_id')
group_userID.sum().query("order_amount<3000").plot.scatter(x = 'order_amount',y = 'order_products')
# group_userID.sum().order_amount. plot.hist(bins = 20)
# group_userID.sum().query("order_products<100").order_products.plot.hist(bins = 40)
#柱状图
plt.show()上一段代码的意思是以user_id为索引进行分组,但是分组之后可能会发现打印出来的是对象,因为需要对分组完的数据进行进一步操作,例如:求和求均值等等。然后再这里用到的是对数据进行求和,然后调用quary方法规定x轴坐标order_amunt的值小于3000,调用plot里的scatter散点图,画出散点图。
用户购买金额和购买数量的散点图

从散点图中看出数据集中分布在购买金额小购买量少上, 数据基本成线性分布,购买CD金额大数量就多,金额少数量也少。
group_userID.sum().order_amount. plot.hist(bins = 20)用户消费金额分布

从消费金额中可以看出消费金额偏向很低基本在0-1000元之间,可看出其主要还是面向低消费人群。
group_userID.sum().query("order_products<100").order_products.plot.hist(bins = 40)用户消费次数分布

从消费次数柱状图中可以看出,绝大部分用户消费次数并不多,甚至很少,消费次数基本在0-20次之间。
cum1 = group_userID.sum().sort_values("order_amount").apply(lambda x:x.cumsum()/x.sum())
cum1.reset_index().order_amount.plot()
plt.show()上面这段代码的意思是求出用户的累计消费金额占比,cumsum方法是滚动求和,对求完占比之后的dataframe进行重置 索引,重置索引之后的索引是按照升序排列好的,所以画出的图横坐标就是索引,纵坐标就是消费额所占比例,可以反映出百分之多少的用户占了消费额的百分之多少。

从消费额占比中看得出百分之五十的用户才占了百分之二十不到的消费额,排名前五百的用户占有了快百分之五十的消费额,消费还是主要集中在一些大客户上。
用户消费行为分析
- 用户第一次消费(首购)时间
- 用户最后一次消费时间
- 用户分层
RFM (RFM模型是衡量客户价值和客户创利能力的重要工具和手段)
新、老、活跃、回流、流失
- 用户购买周期(按订单)
用户消费周期描述
用户消费周期分布
- 用户生命周期(按第一次&最后一次消费)
用户生命周期描述
用户生命周期分布
用户首购时间
# 用户首次购买时间
grouped_user.min().month.value_counts()grouped_user.min().order_dt.value_counts().plot() # 首购
plt.show()
用户最后一次购买时间
grouped_user.month.max().value_counts()grouped_user.max().order_dt.value_counts().plot() # 最后一次消费
plt.show()
首购都在一月到三月份,最后一次购买也基本集中在一月到三月份,长期活跃的客户不是很多,大部分用户是购买一次之后不在购买,随着时间的增长,最后一次购买的用户量也在不断增加。
第一次消费时间等于最后一次消费时间的数量占到了一半,说明很多顾客仅消费一次不再消费。
用户数据分层
将用户分成:
- 111':'重要价值客户',
- '011':'重要保持客户',
- '101':'重要挽留客户',
- '001':'重要发展客户',
- '110':'一般价值客户',
- '010':'一般保持客户',
- '100':'一般挽留客户',
- '000':'一般发展客户'
至于前面数字的意义等下会解释。
构建RFM模型(Recency Frequency Monetary)
分别执行下面两段代码:
rfm = df.pivot_table(index = 'user_id',
values = ['order_products', 'order_amount', 'order_dt'],
aggfunc = {'order_dt':'max',
'order_amount':'sum',
'order_products':'sum'
})
rfm.head()到这里就开始使用一个新的函数,及python的透视函数,point_table此函数功能跟excel的透视表一样,但是比透视表更加灵活,df.point_table(index = [],columns = [],values = [],aggfunc = [])这几个参数等会要用到,先来解释一下这几个参数的意思:
- index指的是分组的时候选择哪个字段作为索引;
- columns指的是指定的列名是什么;
- values可以决定保留哪些属性字段;
- aggfunc则是决定对每个字段执行的函数
- 不写默认执行sum
rfm['R'] = -(rfm.order_dt - rfm.order_dt.max()) / np.timedelta64(1, 'D')
rfm.rename(columns = {'order_products': 'F', 'order_amount':'M'},
inplace=True)
rfm.head()
def rfm_func(x):
level = x.apply(lambda x:'1' if x>=1 else '0')
label = level.R + level.F + level.M
d = {
'111':'重要价值客户',
'011':'重要保持客户',
'101':'重要挽留客户',
'001':'重要发展客户',
'110':'一般价值客户',
'010':'一般保持客户',
'100':'一般挽留客户',
'000':'一般发展客户'
}
result = d[label]
return result
rfm['label'] = rfm[['R', 'F', 'M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
rfm.head()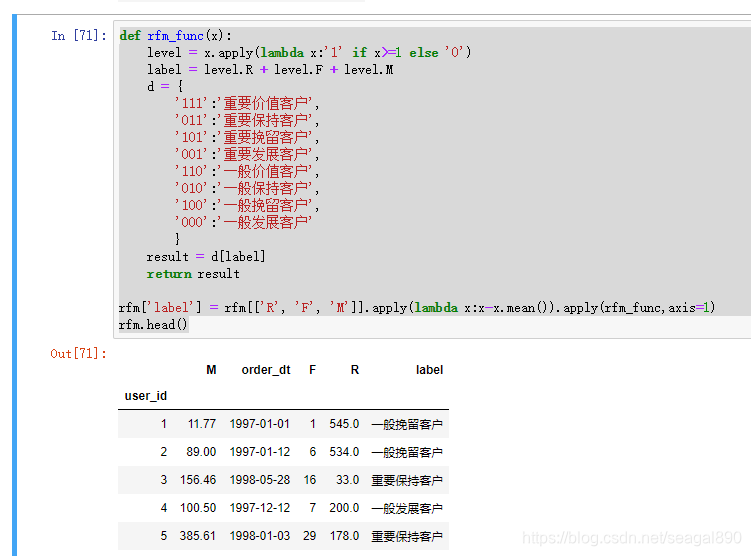
rfm.groupby('label').sum()
for label,gropued in rfm.groupby('label'):
x= gropued['F']
y = gropued['R']
plt.scatter(x,y,label = label) # 利用循环绘制函数
plt.legend(loc='best') # 图例位置
plt.xlabel('Frequency')
plt.ylabel('Recency')
plt.show()从 RFM 分层可知,大部分用户为重要保持客户,但这是因为极值存在,所以 FRM 的划分应按照业务为准划分
- 尽量用小部分的用户覆盖大部分的额度
- 不要为了数据好看而划分等级
按新、活跃、回流、流失分层用户
# 通过每月是否消费来划分用户
pivoted_counts = df.pivot_table(index = 'user_id',
columns = 'month',
values = 'order_dt',
aggfunc = 'count').fillna(0)
pivoted_counts.columns = df.month.sort_values().astype('str').unique()
pivoted_counts.head()
df_purchase = pivoted_counts.applymap(lambda x: 1 if x> 0 else 0)
df_purchase.tail() 
若本月没有消费
- 若之前未注册,则依旧未注册
- 若之前有消费,则为流失/为活跃
- 其他情况,未注册
若本月消费
- 若是第一次消费,则为新用户
- 如果之前有过消费,上个月为不活跃,则为回流
- 如果上个月未注册,则为新用户
- 除此之外,为活跃
purchase_states = df_purchase.apply(active_status,axis = 1)
purchase_states.tail()
purchase_states_ct = purchase_states.replace('unreg',np.NaN).apply(lambda x:pd.value_counts(x))
purchase_states_ct
unreg 状态排除掉,是未来才成为新用户,作为不同分呈用户每月统计量。
# 转置后方便观察
purchase_states_ct.fillna(0).T
# 绘制面积图
purchase_states_ct.fillna(0).T.plot.area(figsize = (12, 6))
plt.show()
由面积图,蓝色和灰色区域占大面积,可以不看,因为这只是某段时间消费过的用户的后续行为。其次红色代表的活跃用户非常稳定,是属于核心用户,以及紫色的回流用户,这两个分层相加,就是消费用户人数占比(后期没用新客)
回流用户占比
plt.figure(figsize=(20, 4))
rate = purchase_states_ct.fillna(0).T.apply(lambda x: x/x.sum())
plt.plot(rate['return'],label='return')
plt.plot(rate['active'],label='active')
plt.legend()
plt.show()

- 回流用户比:某个时间段内回流用户在总用户中的占比
由图可知,用户每月回流用户比占 5% ~ 8% 之间,有下降趋势,说明客户有流失倾向。
- 回流用户率:上月有多少不活跃用户在本月消费
由于这份数据的不活跃用户量基本不变,所以这里的回流率,也近似等于回流比
- 活跃用户比:某个时间段内活跃用户在总用户中的占比。
活跃用户的占比在 3% ~ 5%间,下降趋势更显著,活跃用户可以看作连续消费用户,忠诚度高于回流用农户。
结合活跃用户和回流用户看,在后期的消费用户中,60%是回流用户,40%是活跃用户,整体用户质量相对不错。也进一步说明前面用户消费行为分析中的二八定律,反应了在消费领域中,狠抓高质量用户是不变的道理。
用户购买周期
# 订单时间间隔
order_diff = grouped_user.apply(lambda x:x.order_dt - x.order_dt.shift())
order_diff.head(10)
order_diff.describe()
# 订单周期分布图
(order_diff / np.timedelta64(1, 'D')).hist(bins = 20)
plt.show()
- 订单周期呈指数分布
- 用户的平均购买周期是 68 天
- 绝大部分用户的购买周期低于 100 天
- 用户生命周期图是典型的长尾图,大部分用户的消费间隔确实比较短。不妨将时间召回点设为消费后立即赠送优惠券,消费后10天询问用户CD怎么样,消费后30天提醒优惠券到期,消费后60天短信推送。
用户生命周期
# 最后一次购买的时间减去首购时间
user_life = grouped_user.order_dt.agg(['min', 'max'])
user_life.head()
# 只消费过一次的用户占比
(user_life['min'] == user_life['max']).value_counts().plot.pie()
plt.show()
(user_life['max'] - user_life['min']).describe()
通过描述可知,用户平均生命周期 134 天,比预想高,但是平均数不靠谱,中位数 0 天,大部分用户第一次消费也是最后一次,这批属于低质量用户,而最大的是 544 天,几乎是数据集的总天数,这用户属于核心用户。
因为数据中的用户都是前三个月第一次消费,所以这里的生命周期代表的是1月~3月用户的生命周期。因为用户会持续消费,这段时间过后还会继续消费,用户的平均生命周期会增长。
plt.figure(figsize=(20, 4))
plt.subplot(121)
((user_life['max'] - user_life['min']) / np.timedelta64(1, 'D')).hist(bins = 15)
plt.title('二次消费以上用户的生命周期直方图')
plt.xlabel('天数')
plt.ylabel('人数')
# 过滤生命周期为0 的
plt.subplot(122)
u_l = ((user_life['max'] - user_life['min']).reset_index()[0] / np.timedelta64(1, 'D'))
u_l[u_l > 0].hist(bins = 40)
plt.title('二次消费以上用户的生命周期直方图')
plt.xlabel('天数')
plt.ylabel('人数')
plt.show()
通过两图对比看出,过滤掉周期为 0 的用户后,图像呈双峰结构,虽然还是有不少用户生命周期趋于 0 天,但是相比第一幅图,靠谱多了。部分低质用户,虽然消费两次,但还是不能持续消费,要想提高用户转化率,应该用户首次消费 30 天内尽量引导,少部分用户集中在 50 - 300 天,属于普通用户,忠诚度一般。集中在 400 天以后的,是高质量用户了,后期人数还在增加,这批用户已经属于核心用户了,忠诚度极高,尽量维护这批用户的利益。
# 消费两次以上用户平均生命周期
u_l[u_l > 0].mean()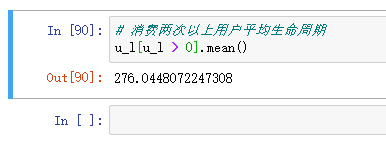
消费两次以上的用户平均生命周期是 276 天,远高于总体,所以如何在用户首次消费后引导其进行多次消费,可以有效提高用户生命周期。
复购率和回购率分析
- 复购率
- 自然月内,购买多次的用户占比
- 回购率
- 曾经购买的用户在某一时期内的再次购买的占比
# 消费两次及以上为 1 ,消费一次为 0 ,没有消费为空
purchase_r = pivoted_counts.applymap(lambda x: 1 if x > 1 else np.NaN if x==0 else 0)
purchase_r.head()
# 复购率折线图
(purchase_r.sum() / purchase_r.count()).plot(figsize = (10, 4))
plt.show()
复购率稳定在 20% 左右,前三个月因为有大量新用户涌入,而这批用户只购买了一次,所以导致复购率降低。
def purchase_back(data):
status = []
for i in range(17):
if data[i] == 1:
if data[i+1] == 1:
status.append(1)
if data[i+1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return pd.Series(status,df_purchase.columns)purchase_b = df_purchase.apply(purchase_back,axis = 1)
purchase_b.head()
1 为回购用户, 0 为上月没购买当月购买过,NaN 为连续两月都没购买

由回购率图可以看出,用户回购率高于复购率,约在 30% 左右,波动性较强。新用户回购率在 15 % 左右,与老用户相差不大。
由人数分布图发现,回购人数在前三月之后趋于稳定,所以波动产生的原因可能由于营销淡旺季导致,但之前复购用户的消费行为与会回购用户的行为大致相同,可能有一部分用户重合,属于优质用户。
结合回购率和复购率分析,可以新客的整体忠诚度低于老客,老客的回购率较好,消费频率稍低,这是 CDNow 网站的用户消费特征。
留存率分析
# 每一次消费距第一次消费的时间差值
user_purchase = df[['user_id','order_products','order_amount','order_dt']]
user_purchase_retention = pd.merge(left = user_purchase,
right = user_life['min'].reset_index(),
how = 'inner',
on = 'user_id')
user_purchase_retention['order_dt_diff'] = user_purchase_retention['order_dt']-user_purchase_retention['min']
user_purchase_retention['dt_diff'] = user_purchase_retention.order_dt_diff.apply(lambda x: x/np.timedelta64(1,'D'))
user_purchase_retention.head() 
后续补充。
