一、题外话
数据来自秦路老师的公众号,关注秦路老师的公众号,然后回复CD数据即可获得,我是一名数据分析小白,跟着老师的文章撸了一遍代码,仍然觉得云里雾里的。因此,决定把代码重构,根据秦老师的数据分析的思维理一遍,具体记录里面的较为重要的函数的用法,故写此文。
二、做准备
1.观察数据
下载并打开数据,发现数据有60000多行,4列,但是每一列没有标题,根据数据的格式可以推断出这四列的标题应该是用户ID、购买时间、购买的商品数量、花费的价格。
2.导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot') #自带的美化方式数据分析常用的两个包pandas和numpy,数据可视化matplotlib,plt.style.use(‘ggplot’)这行代码开始不太熟悉,后来发现它能自动美化图片。比如说
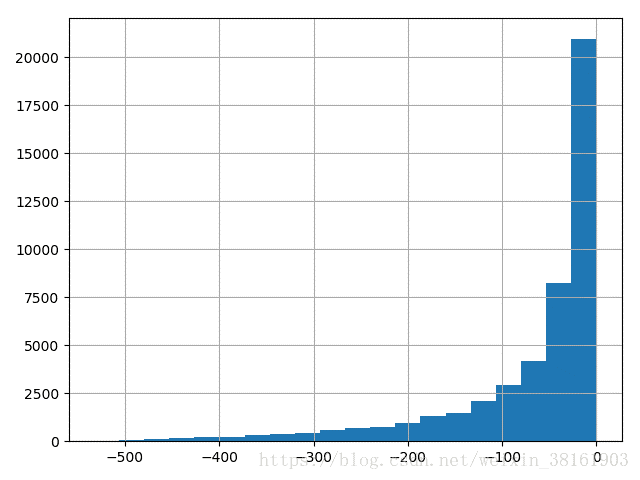
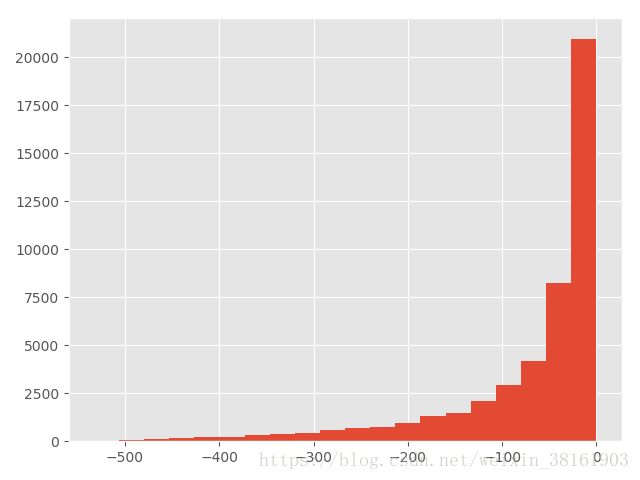
可以看出点区别,灰红色(经过美化)的搭配看起来更漂亮一些。
3.读取数据
根据观察数据得到的结论以及数据的格式导入数据
def read_file(file):
columns = ['user_id', 'order_dt', 'order_products', 'order_amount'] # 表头(列名)
df = pd.read_csv(file, names=columns, sep='\s+') # 读取文件
return df
if __name__ == "__main__":
file = 'CDNOW_master.txt' #等待读取的文件
df = read_file(file)
print(df.head()) #读取前5行(默认)输出:
user_id order_dt order_products order_amount
0 1 19970101 1 11.77
1 2 19970112 1 12.00
2 2 19970112 5 77.00
3 3 19970102 2 20.76
4 3 19970330 2 20.76输出正确,当然也可以输出前10行,前100行都可以,即print(df.head(10))
print(df.head(100))
还有另外两个很重要的方法
(1)df.describe()
print(df.describe())输出:
user_id order_dt order_products order_amount
count 69659.000000 6.965900e+04 69659.000000 69659.000000
mean 11470.854592 1.997228e+07 2.410040 35.893648
std 6819.904848 3.837735e+03 2.333924 36.281942
min 1.000000 1.997010e+07 1.000000 0.000000
25% 5506.000000 1.997022e+07 1.000000 14.490000
50% 11410.000000 1.997042e+07 2.000000 25.980000
75% 17273.000000 1.997111e+07 3.000000 43.700000
max 23570.000000 1.998063e+07 99.000000 1286.010000count:计数,mean:平均值,std:标准差,min:最小值,50%:中位数,25%:25分位,75%:75分位,max:最大值
(2)df.info()
print(df.info())输出:
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 4 columns):
user_id 69659 non-null int64
order_dt 69659 non-null int64
order_products 69659 non-null int64
order_amount 69659 non-null float64
dtypes: float64(1), int64(3)
memory usage: 2.1 MB可以看出数据没有空值,很“干净”。
4.转换时间的数据类型
从输出可以看出时间的输出是19970101的形式,如果转换成1997-01-01的格式该怎么办呢?
方法
def convert_time(df):
df['order_date'] = pd.to_datetime(df.order_dt, format="%Y%m%d") # 把字符串转换成时间格式
df['month'] = df.order_date.values.astype('datetime64[M]') # 把时间保留到月
print(df.head())在主函数下调用该方法就可以了,这里就不着重说了。
输出:
user_id order_dt order_products order_amount order_date month
0 1 19970101 1 11.77 1997-01-01 1997-01-01
1 2 19970112 1 12.00 1997-01-12 1997-01-01
2 2 19970112 5 77.00 1997-01-12 1997-01-01
3 3 19970102 2 20.76 1997-01-02 1997-01-01
4 3 19970330 2 20.76 1997-03-30 1997-03-01从输出结果就可以推断出:
(1)df[‘order_data’]的作用是在df中添加一列名为order_data的数据
(2)pd.to_datetime将字符串或者数字转换成时间格式,format是转换后的格式。例如19970101,%Y匹配前四位数字1997,如果y小写只匹配两位数字97,%m匹配01,%d匹配01。另外,小时是%h,分钟是%M,注意和月的大小写不一致,秒是%s。若是1997-01-01这形式,则是%Y-%m-%d,以此类推。
(3)astype(‘datetime64[M]’)保留到月份
三、分析数据(维度法)
维度法顾名思义是从不同维度来分析数据,那么维度是什么呢?我的理解是看待事物的角度,比如说看待一个人可以从身高体重去评价他,也可以从学历工作经历去衡量。一份数据有多个维度,因此我们需要抓住最重要的几个维度去分析,那么什么是最重要的维度呢?我的理解是相关度越大越重要,那么怎么计算相关度呢?这就涉及到统计学里面的知识,很有趣,但是这里用不到,机器学习中的特征工程涉及的更多。
3.1.月分组
1.分析每月的销量
def convert_dimension_month_order_products(df):
grouped_month_order_products = df.groupby('month').order_products.sum()
grouped_month_order_products.plot()
plt.show()输出:
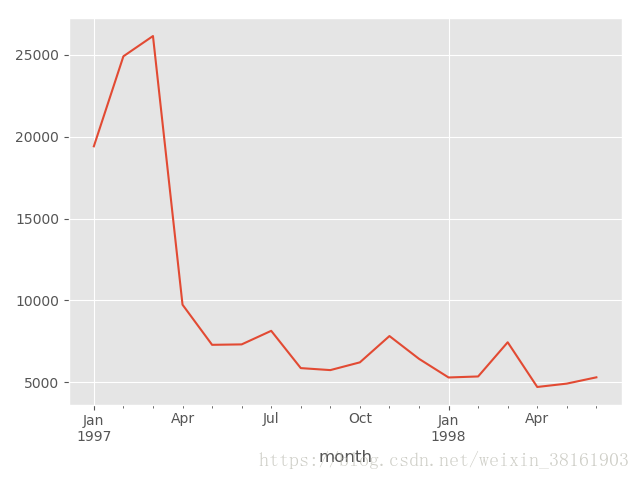
首先分析函数:
(a)groupby():分组函数
(b)sum():求和
(c)plt.show():显示图形
其次从图片可知:
(a)前三个月销售量逐渐增加,第三个月销售量最大
(b)第四个月销售量与第三个月相比减少1.5倍
(c)从第5个月开始销售量虽有波动但都在5000至8000的区间内。
2.分析每月的销售额
def convert_dimension_month_order_amount(df):
grouped_month_order_amount = df.groupby('month').order_amount.sum()
grouped_month_order_amount.plot()
plt.show()输出:
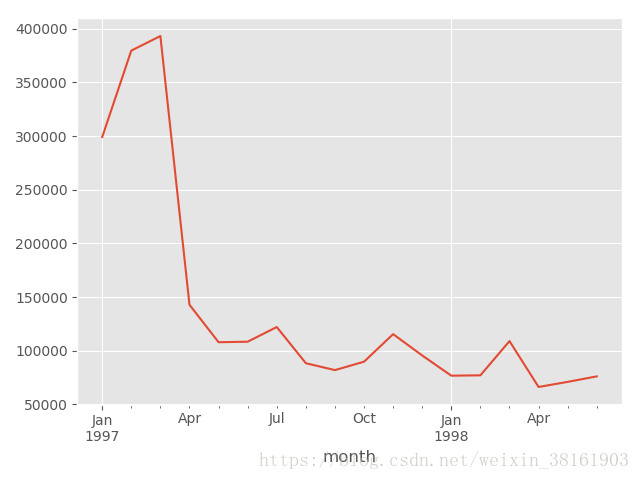
从图片可以看出每月销售额的变化趋势与销售量基本一致。
猜想:
前三个月中是否存在少数购买量巨大的用户拉高了销售水平
3.2 用户分组
1.散点图
def convert_dimension_user_id(df):
grouped_user_id= df.groupby('user_id') # 数据维度转换为用户
grouped_user_id_sum = grouped_user_id.sum()
grouped_user_id_sum.plot.scatter(x = 'order_amount', y = 'order_products') #从用户ID的角度,画销售额和销量的散点图输出:
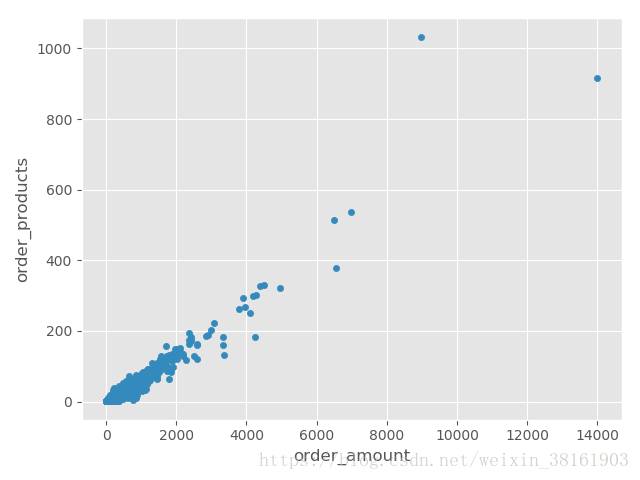
从图片可以看出:只有个别用户存在购买量巨大的问题,九成以上的用户的购买量合理。
由此可以推断前三个月存在的大额购买量用户的概率较低,但不能排除完全没有,因此通过直方图更清楚的表现大额消费者的数量。
2.直方图
(1)用户销量
grouped_user_id.order_products.sum().hist(bins=30) #销售额和销量的直方图输出: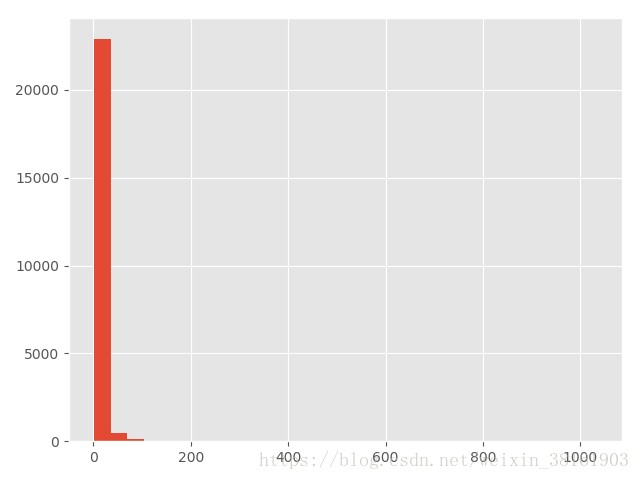
(2)用户销售额
df.order_amount.hist(bins=30) #直方图,分层30组
plt.show()输出:
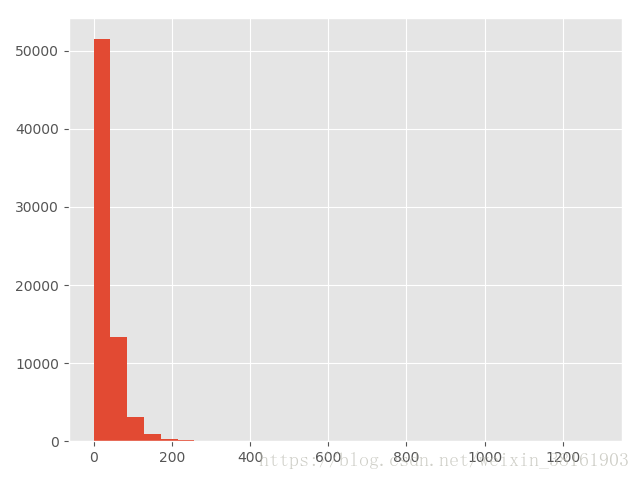
从两张图片可以看出:大部分用户的消费能力确实不高,高消费用户在图上几乎看不到。这也确实符合消费行为的行业规律。
3.用户的首次和最后一次消费月份
(1)首次消费
grouped_user_id_month_min = grouped_user_id.month.min().value_counts()输出:
1997-02-01 8476
1997-01-01 7846
1997-03-01 7248可以看出用户首次消费集中在前三个月,也就是说前三个月有大量的新用户
(2)最后一次消费
grouped_user_id_month_max = grouped_user_id.month.max().value_counts()输出:
1997-02-01 4912
1997-03-01 4478
1997-01-01 4192
1998-06-01 1506
1998-05-01 1042
1998-03-01 993
1998-04-01 769
1997-04-01 677
1997-12-01 620
1997-11-01 609
1998-02-01 550
1998-01-01 514
1997-06-01 499
1997-07-01 493
1997-05-01 480
1997-10-01 455
1997-09-01 397
1997-08-01 384可以看出绝大部分数据依然集中在前三个月。后续的时间段内,依然有用户在消费,但是缓慢减少。
因此可以知道前三个月销售水平高的原因了
4.用户的复购率
复购率:某时间窗口内消费两次及以上的用户在总消费用户中占比。
(1)数据透视
def repeat_purchase_ratio(df):
pivoted_counts = df.pivot_table(index = 'user_id', columns = 'month',
values='order_dt',aggfunc= 'count').fillna(0) #数据透视(用户每月的订单数)
columns_month = df.month.sort_values().astype('str').unique() #优化时间格式
pivoted_counts.columns = columns_month重要方法:
(a)pivot_table(index,columns,values,aggfunc)
index:数据透视后的索引,相当于表格的行名。
columns:数据透视后的列,相当于表格的列名。
values:表格中的值
aggfunc:计算方法
(b)sort_values():排序
输出:
1997-01-01 1997-02-01 1997-03-01 1997-04-01 1997-05-01 \
user_id
1 1.0 0.0 0.0 0.0 0.0
2 2.0 0.0 0.0 0.0 0.0
3 1.0 0.0 1.0 1.0 0.0
4 2.0 0.0 0.0 0.0 0.0
5 2.0 1.0 0.0 1.0 1.0 大体上是这样后续的月份我就不贴出来了
(2)转换格式
pivoted_counts_transf = pivoted_counts.applymap(lambda x: 1 if x > 1 else np.NaN if x == 0 else 0) #转换数据格式,方便计算重要函数:
(a)applymap:作用于数组中每一个元素
(b)lambda表达式用法很多,可以详细看这里
(3)复购率及可视化
rep_purchase_ratio = (pivoted_counts_transf.sum() / pivoted_counts_transf.count()) #复购率
rep_purchase_ratio.plot(figsize=(10, 4)) #复购率可视化输出:
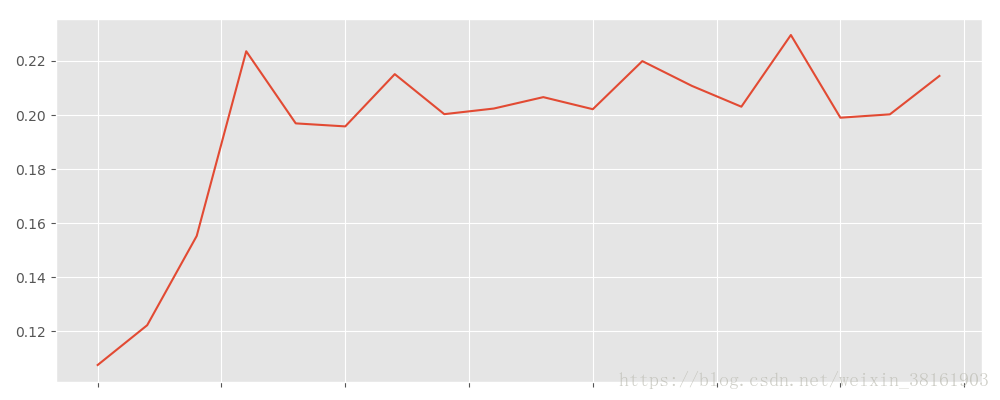
这个图片横轴可能被我吃掉了。。。是月份的哈。
图上可以看出复购率在早期,因为大量新用户加入的关系,新客的复购率并不高,譬如1月新客们的复购率只有6%左右。而在后期,这时的用户都是大浪淘沙剩下的老客,复购率比较稳定,在20%左右。单看新客和老客,复购率有三倍左右的差距。
5.用户的回购率
回购率:某一个时间窗口内消费的用户,在下一个时间窗口仍旧消费的占比。我1月消费用户1000,他们中有300个2月依然消费,回购率是30%。
(1)计算回购率
def purchase_return(data):
status = []
for i in range(17):
if data[i] == 1:
if data[i+1] == 1:
status.append(1)
if data[i+1] == 0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return status
def return_purchase_ratio(df):
pivoted_amount = df.pivot_table(index='user_id', columns='month',
values='order_amount', aggfunc='mean').fillna(0) #数据透视(用户每月的消费金额)
columns_month = df.month.sort_values().astype('str').unique()
pivoted_amount.columns = columns_month
pivoted_purchase = pivoted_amount.applymap(lambda x: 1 if x > 0 else 0) #转换格式
pivoted_purchase_return = pivoted_purchase.apply(purchase_return, axis=1)#转换格式
ret_purchasr_ratio = pivoted_purchase_return.sum() / pivoted_purchase_return.count() #回购率重要函数:
(a)apply():参数axis=1则作用于行,如果axis=0或者不写则作用于列。
(2)可视化
输出:
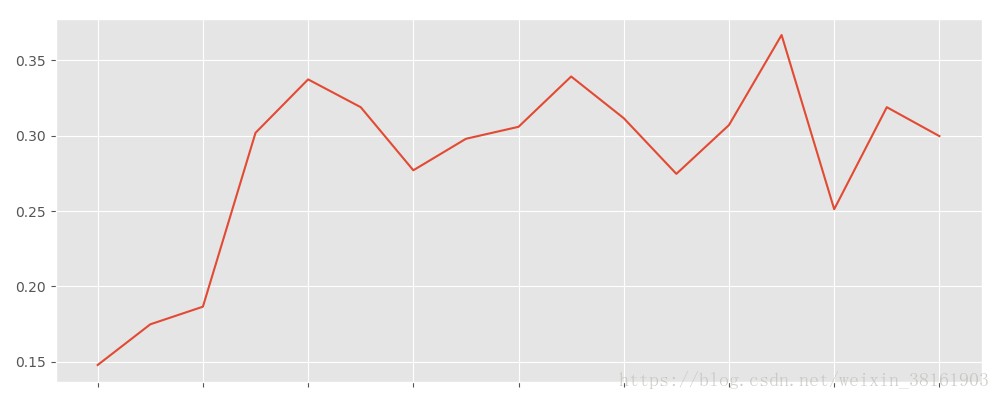
从图中可以看出,用户的回购率高于复购,约在30%左右,波动性也较强。新用户的回购率在15%左右,和老客差异不大。
将回购率和复购率综合分析,可以得出,新客的整体质量低于老客,老客的忠诚度(回购率)表现较好,消费频次稍次,这是CDNow网站的用户消费特征。
6.用户分层
按照用户的消费行为,简单划分成几个维度:新用户、活跃用户、不活跃用户、回流用户。
(1)可视化(面积图)
def active_status(data):
status = []
for i in range(18):
if data[i] == 0: #没有消费
if len(status) > 0: #不是第一个月
if status[i - 1] == 'unreg':#前一个月还不是新用户
status.append('unreg')#仍然不是新用户
else:
status.append('unactive')
else:
status.append('unreg') #还不是新用户
else:
if len(status) == 0: #第一个月
status.append('new')#新用户
else:
if status[i - 1] == 'unactive': #上一个月不活跃
status.append('return') #回流用户
elif status[i - 1] == 'unreg': #上一个月不是新用户
status.append('new') #新用户
else:
status.append('active') #活跃用户
return status
def user_stratification(df):
pivoted_purchase = return_purchase_ratio(df)
pivoted_purchase_status = pivoted_purchase.apply(lambda x: active_status(x), axis=1)
purchase_status_counts = pivoted_purchase_status.replace('unreg', np.NaN).apply(lambda x: pd.value_counts(x))
purchase_status_counts.fillna(0).T.plot.area(figsize=(12, 6)) #面积图输出:
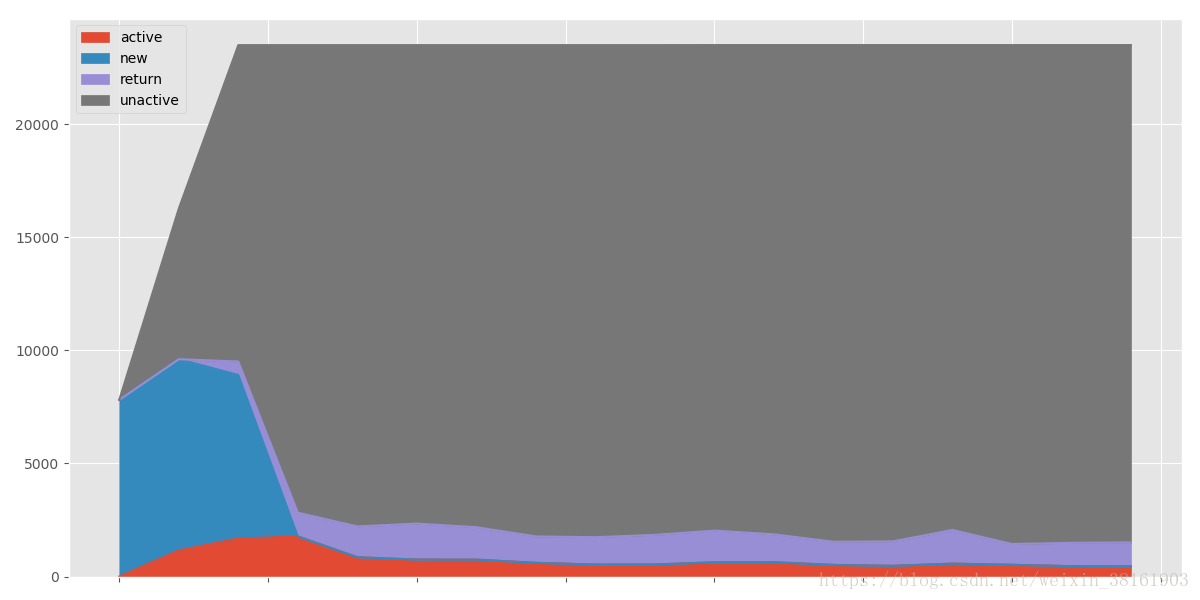
(2)用户回流比和活跃用户比
return_rata = purchase_status_counts.apply(lambda x:x / x.sum(),axis = 1)
plt.figure()
plt.subplot(121)
return_rata.loc['return'].plot(figsize = (12,6)) #回流用户占比
plt.subplot(122)
return_rata.loc['active'].plot(figsize = (12,6)) #活跃用户占比
plt.show()同时画出两张图:
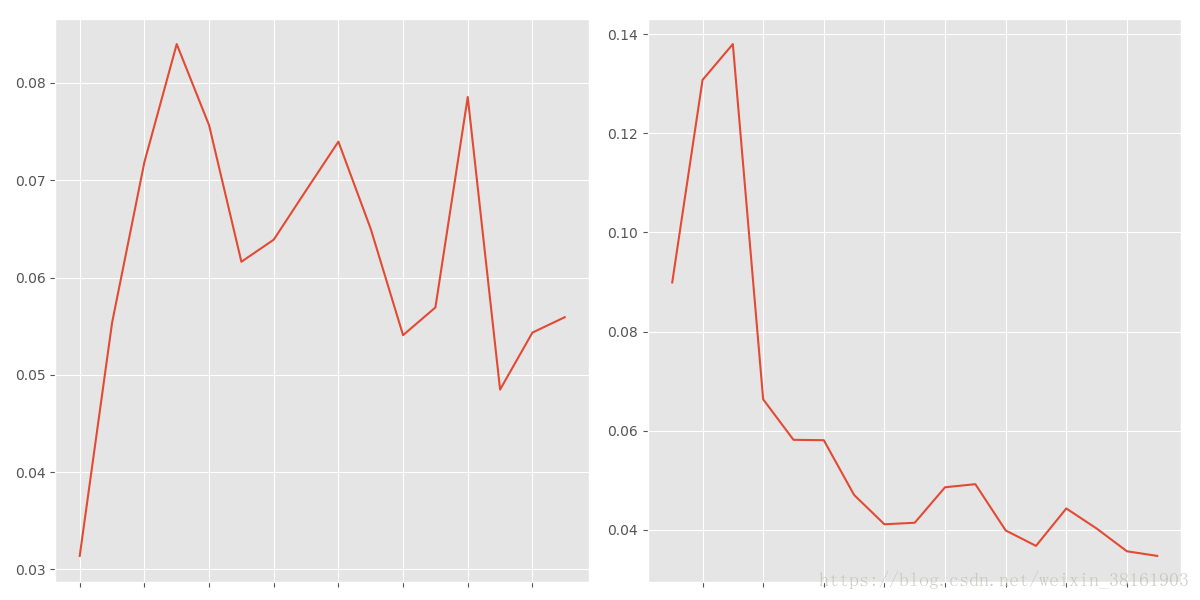
从图片看看出用户回流占比在5%~8%,有下降趋势,活跃用户的下降趋势更明显,占比在3%~5%,二者结合可以看出四月份之后的销量很大一部分来源于老用户的回流。
7.用户质量