1 引言
上一篇文章《Windows下VS2015编译YOLOv4的两种方法,以及__func__未定义问题的解决》记录了Windows下YoloV4编译涉及到的问题。
YOLO作者附带了几个权重文件可供下载,包含了日常常见的物体,可以直接用来测试和识别,但如果希望识别我们所指定的物体,那就需要自己制作样本和训练了,本文记录自己制作样本、标注样本、训练样本的过程。
2 下载
标注和训练前,需要下载几个文件:
样本标注软件:yolo_mark,下载源码后自己用VS编译。
预训练权重文件:yolov4.conv.137
3 需要准备的目录和文件
3.1 目录
YOLO作者建议放在…build\darknet\x64下,但实际上可以放在任意目录,因为这个darknet\x64目录文件太多了,所以我建了个d:\YoloV4\My目录用于放所有工作文件。
再在此目录下建立如下目录:
d:\YoloV4\My\data目录,用于放训练的数据文件。
d:\YoloV4\My\data\obj目录,用于存放训练样本图片。
d:\YoloV4\My\Backup目录,用于训练时存放临时权重文件。
3.2 CFG文件
作用:网络配置文件,训练时和识别时都需要用到
从源码附带的yolov4-custom.cfg,拷贝一份到d:\YoloV4\My目录,然后重命名为自己的文件名,比如yolov4-my.cfg。
进行下一修改前先要确定自己要识别的物体种类个数,因为以下几个参数与此有关,我们假设classes=4类。
用文本编辑器打开yolov4-my.cfg,进行如下修改:
batch=64
subdivisions=16,作者建议,但后面发现这个值不行,我改为了subdivisions=64
max_batches=8000,这个值=classes*2000,但这个值不能小于训练图片数,也不能小于6000
steps=6400,7200,这两个值是max_batches的80%和90%。
width=416 height=416,网络尺寸,这两个值必须是32的倍数。
classes=4,文件中一共有3处需要修改,搜索classes后修改即可
filters=27, 公式filters=(classes + 5)x3,这个对应classes也一共3处,注意一定是搜索到classes后的紧邻上一个[convolutional]节的filters需要如此修改
3.3 obj.names文件
作用:物体名称文件,训练时和识别时都需要用到
在d:\YoloV4\My\data下,新建一个文本文件,重命名为obj.names(可以取自己喜欢的名字,包括扩展名,以下所有文件均可自行取名,下同),按确定的classes个数,每行写一个物体名称,例如
plane
car
bus
pizza
...
网络识别物体时的结果是物体序号,本文件序号对应行的文字即为识别物体名称。
3.4 obj.data文件
作用:训练数据文件,训练时用
在d:\YoloV4\My\data下,新建一个文本文件,重命名为obj.data,其内容为
classes = 4
train = data/train.txt
valid = data/test.txt
names = data/obj.names
backup = backup/
文件中每行的作用为:
classes:指定要训练和识别的物体种类数
train:指定训练样本描述文件的路径和文件名,见后述
valid:validation_dataset文件路径和文件名,本例未使用,这里知道这是为了减少过拟合情况的发生而提出的即可。
names:指定物体名称文件的路径和文件名
backup:用于训练时存放临时权重文件的目录
4 样本准备、标注
4.1 样本准备
准备用于标注和训练用的图片,JPG格式,统一放到d:\YoloV4\My\data\obj目录。
4.2 train.txt文件
作用:训练样本描述文件,标注和训练时用
在d:\YoloV4\My\data下,新建一个文本文件,重命名为train.txt,按以上准备好的样本,在这个文件中每行写一个图片文件的路径和名称,类似如下:
data/obj/img1.jpg
data/obj/imga.jpg
data/obj/img2.jpg
...
4.3 样本标注
以上样本和文件都准备好后,这时就要用到前面下载的yolo_mark样本标注软件了,为了方便,我们把yolo_mark.exe拷贝到d:\YoloV4\My下,然后命令行运行(或者最方便的方法:在此目录建一个mark.cmd文件,把以下文字拷贝进去,然后双击此cmd即可运行):
yolo_mark.exe data/obj data/train.txt data/obj.names
然后就可以一帧一帧图片,指定物体名,用鼠标框选了,如下图所示,这里不赘述。
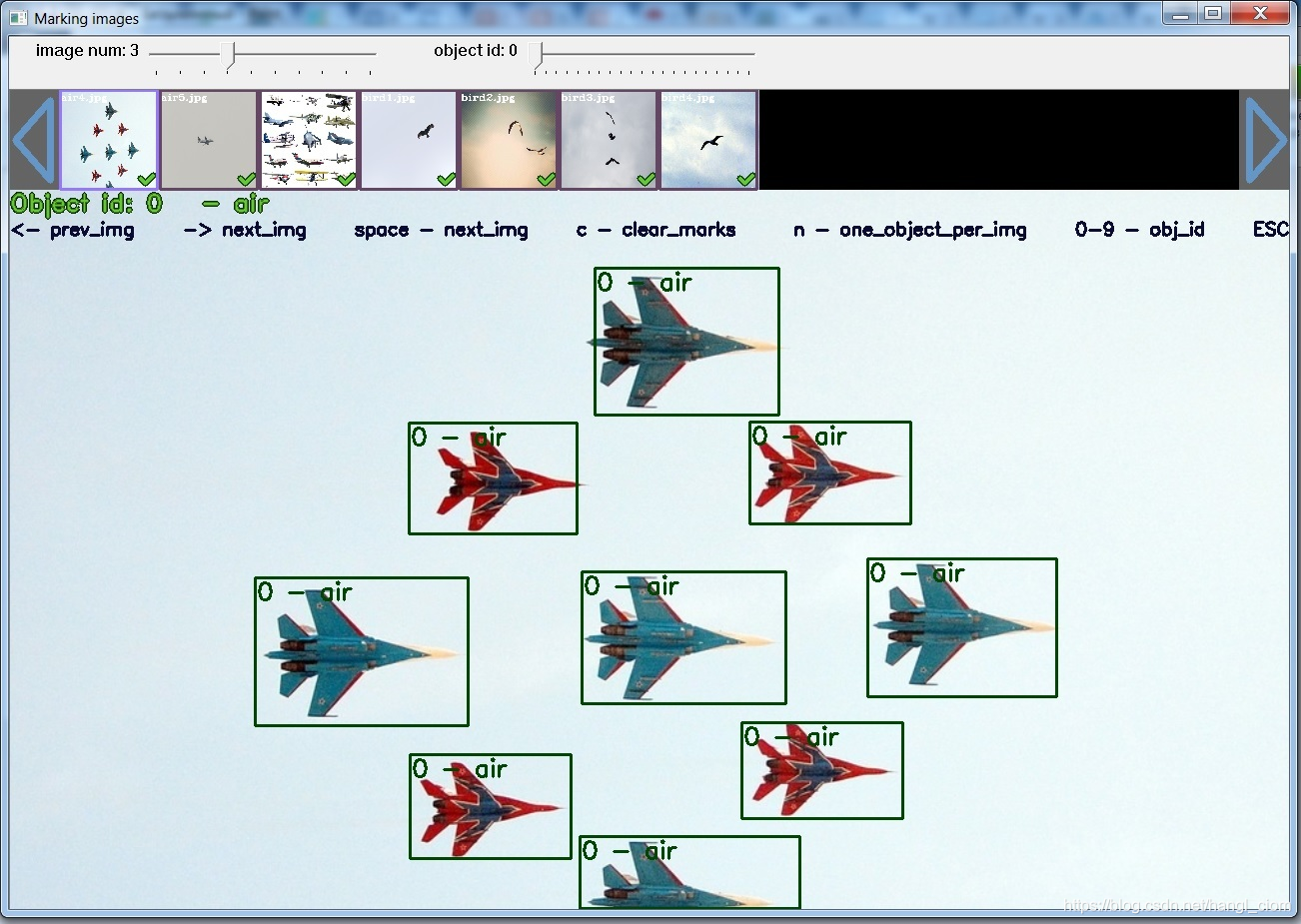
标注完成后,我们会看到在样本图像保存目录下,每个图片都出现了一个同名的txt文件,里面记录的就是样本标注的结果,打开看内容大概如下:
3 0.849609 0.839583 0.111719 0.120833
3 0.130859 0.591667 0.177344 0.058333
0 0.692578 0.313889 0.042969 0.016667
1 0.685547 0.568056 0.035156 0.036111
每行对应一个标注框,含义是:
< object-class> < x_center> <y_center> < width> < height>
object-class:即物体类别序号,从0开始
<x_center><y_center>:标注框中心X和Y坐标,分别占图像宽和高的比例
< width>< height>:标注框宽高,分别占图像宽和高的比例
知道这个原理,必要时可以自己编写程序生成样本标注结果。
5 训练
以上全部准备好后,就可以开始训练了。
此时还要用到之前下载下来的yolov4.conv.137,预训练权重文件,拷贝到d:\YoloV4\My下,并在此路径下,运行以下命令(由于我们的目录不在darknet.exe所在目录,所以写全路径名)(同上最方便是建立一个cmd文件后双击运行)
D:\YoloV4\darknet-master\build\darknet\x64\darknet.exe detector train data/obj.data yolov4-my.cfg yolov4.conv.137
正常的话,就会出现如下界面,训练过程开始。

图形显示的是损失函数变化曲线,横轴为迭代次数,纵轴为损失率。平均损失率会从一千多开始,逐渐下降,开始下降的很快,如下图为我训练一个多小时后的曲线,但越往后下降越慢。
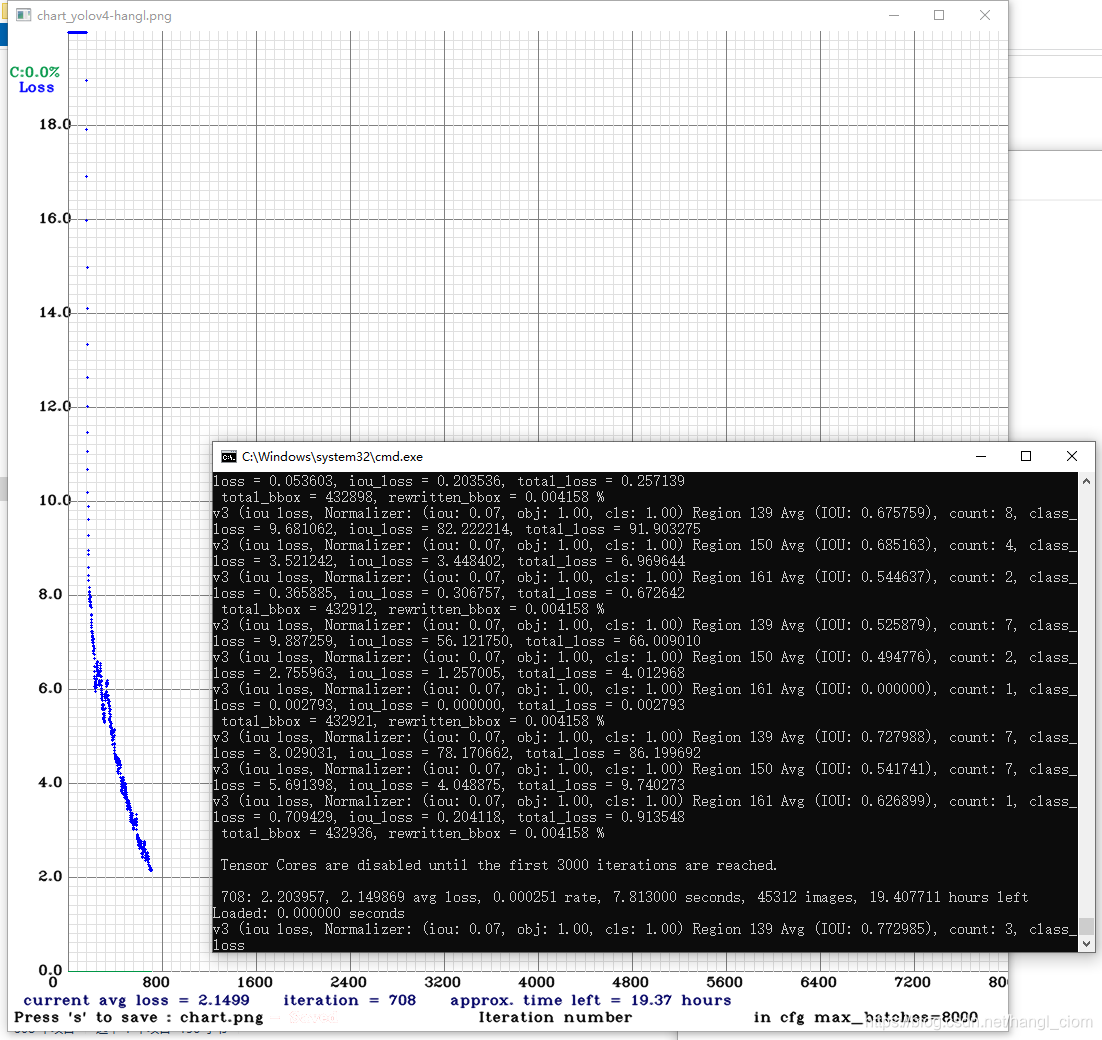
训练过程中,训练出的权重文件会生成于d:\YoloV4\My\Backup目录,训练软件每100次迭代会自动保存一次权重文件,每1000次迭代会产生一个新的权重文件,便于训练后比较最优。
训练结束的判断:通常每个类别对应2000次迭代,一般平均损失率在0.xxx,且多次迭代后基本不再变化,就差不多可以停止训练了。
训练结束后,生成的权重文件*.weights,与前述的yolov4-my.cfg、obj.names就可以用于识别了。
训练过程是一个漫长的过程,一般都需要十几甚至几十个小时,我为了测试,用200多张样本,训练4个目标,大概训练了3个多小时,迭代了1200次,Avg loss大约降到0.8,就中途停止训练了,测试了一下,已经识别的非常好了。