目录
RNNoise:学习噪声抑制
原文地址:RNNoise: Learning Noise Suppression (jmvalin.ca)
1. RNNoise简介
该例子展示了如何利用深度学习来进行噪声抑制的,主要的目的是将传统的信号处理方法结合机器学习,得到一个内存消耗最小,运行速度更快的语音降噪算法,且不需要GPU的参与,它甚至可以在树莓派上运行,效果比传统的噪声抑制系统更好,算法参数也更容易调整。
2. 噪声抑制
噪声抑制是语音信号处理中一个永久性的话题,顾名思义,就是在对感兴趣的语音段造成最小失真的同时,接收有噪声的信号并尽可能多地去除噪声。
这是传统噪声抑制算法框图。
(1) 语音活动检测(VAD)模块检测信号什么时候包含语音以及什么时候仅有噪声
(2) 噪声频谱估计模块用来估计噪声的频谱特性(每个频率的功率谱)
(3) 直接进行减法,即从输入音频中“减去”噪声

从上面的框图来看,噪声抑制看起来十分简单:只需要完成三个简单的任务即可。我们可以轻松设计出噪声抑制算法的代码,关键是能不能让自己的算法在任何时候都能很好地工作,不受各种噪音类型的影响,在任何场合下。这需要对算法中的每个部分进行非常仔细的调整和研究,对一些奇奇怪怪的信号以及许多特殊情况进行大量测试。总有一些奇奇怪怪的信号,导致你的算法不能兼容,就算是一些知名的DSP开源库也不能说100%奏效,比如speexdsp:
Speex: a free codec for free speech
3. 深度学习和循环神经网络
Recurrent Neural Network:循环神经网络/递归神经网络.
深度学习的出现,促进了语音信号处理的发展和应用,近几年来的进展有:
(1)神经网络深度更深了,已经超过两个隐藏层
(2)循环神经网络具有更深的记忆
(3)训练用的数据集更丰富
RNN可以实现时间序列的建模,而不仅仅是单独地考虑输入和输出。这对噪声抑制来说特别重要,因为进行噪声估计是需要耗时的。在相当长的一段时间内,RNN的能力受到严重限制,因为它们不能长时间保存信息,并且进行反向传播计算时,所涉及的梯度下降过程非常低效。这两个问题都可以通过设计门控单元得以解决,比如:LSTM-长短期记忆网络(long short-term memory),GRU-递归门控单元(gated recurrent unit),还有其他很多方法。
注:GRU(Gate Recurrent Unit)是循环神经网络的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的
RNNoise使用门控递归单元(GRU),因为它在该任务上的性能略好于LSTM,并且需要更少的资源(权衡CPU运算能力和内存),与一般的循环单元相比,GRU有两个额外的门。
1)复位门:用来控制是否将当前的状态用于计算新的状态
2)更新门:基于新的输入,当前状态将改变多少(输入能贡献多少权值)。
这个更新门(关闭时)使GRU能够(并且容易)长时间记住信息,这也是GRU(和LSTM)比一般的递归单元执行得更好的原因。
术语:
| feed-forward unit:前向反馈单元 simple recurrent unit:一般的神经递归单元 |
如下图:
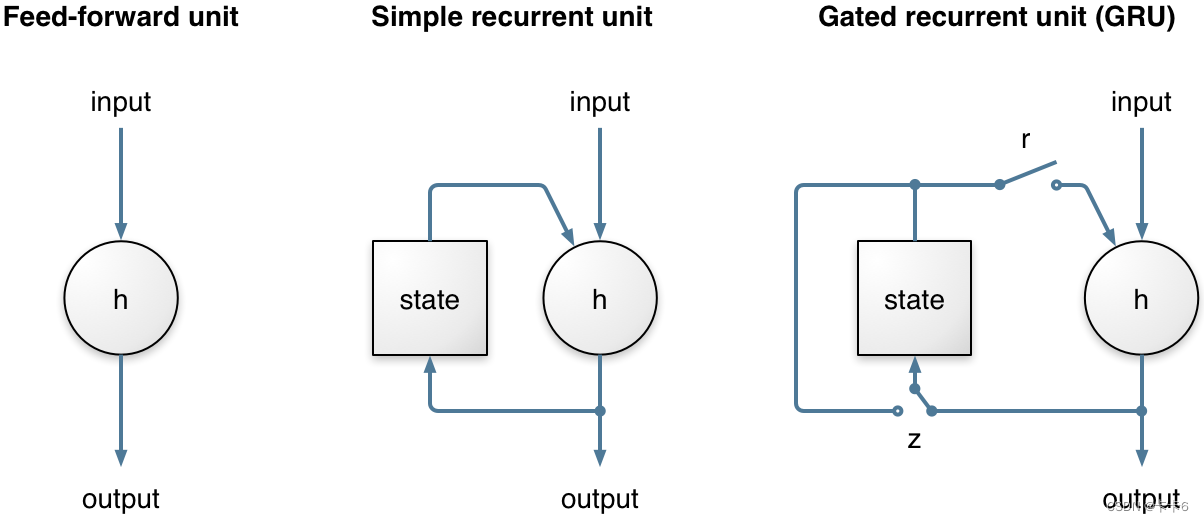
简单的循环单元与GRU进行对比:不同之处在于GRU的r门和z门,这就实现了长时间的记忆和学习功能。二者都是软开关(值介于0和1之间),基于整个层的先前状态和输入进行计算,使用的是sigmod激活函数。当更新门z位于左侧时,状态可以在很长一段时间内保持不变,直到某个条件成立,导致z切换到右侧,则状态就发生改变。
4. 一种混合的方法
由于深度学习的成功,现在流行将深度神经网络应用于整个问题。这些方法被称为端到端的方法,它都是基于神经元的。端到端的方法已经应用于语音识别和语音合成。一方面,这些端到端系统已经证明了深度神经网络的强大程度。另一方面,有时这些系统可能并不是最优的,而且浪费了系统资源。例如,一些噪声抑制方法单单是每一层,都使用数千个神经元和数千万个权值来进行噪声抑制。缺点不仅是运行深层网络的计算成本,而且还有模型本身的大小,一千行代码,以及几十兆字节的神经元权重值。
这里我们提出了不同的方法,保留基本的信号处理方法(不要让神经网络尝试模拟它)。神经网络要做的事:在信号处理之后无休止调整的棘手部分(指的是参数调整……)。另一个与现有的深度学习噪声抑制方法不同的地方是:目标是实时性,并不像语音识别对延迟的要求没有那么高,因此无法接收长时间的模型推理运行时间。
为了避免有非常多的输出(因为这样需要设计大量的神经元),我们决定不直接使用样本或频谱。我们考虑使用频带,这是一种与我们感知声音的方式相匹配的频率尺度。我们总共使用了22个子带,而不是80个(复数)光谱值。

术语:
| Bark scale:巴克频率标度 |
对比Opus频带和实际的巴克频率标度,对于RNNoise,使用的是类似于Opus这样的网络层。由于我们重叠了频带,Opus频带之间的边界成为重叠的RNNoise频带的中心,频率越高,则频带越宽,而人耳的听觉对频率分辨率不是很敏感;频率较低时,频带就较窄,但不像巴克标度所给出的那么窄,因为如果这样的话,我们就没有足够的数据来对噪声做出更好的估计。
并不是直接从这22个子带上进行重构,而是对应地计算出增益值,然后作用于这些子带上。可以把它看成一个长度为22的频率均衡器,可以快速改变每个子带上的值,目的是衰减噪声部分,让语音信号通过。
针对每个频带进行增益的计算,有几个优点:
(1)首先,以频带作为标准划分一段语音,频带数少,使得模型更加简单
(2)其次,不会产生所谓的“音乐噪声”,因为相邻频点被抑制的时候,就只有一个单音节能通过。音乐噪声在噪声抑制中非常常见,也是很令人讨厌的一个问题, 对于一个较宽的频带,即不让它全部通过,也不让它完全被抑制掉。
(3) 第三个优点是模型的优化。增益值的边界是0~1,可直接用sigmod函数来进行计算,这样做不会引入额外的噪声。
术语:
| Rectified Linear activation function:线性整流函数,人工神经网络中常用的一类激活函数(activation function) MFCC:梅尔频率倒谱系数 |
对于输出,可以用一个线性整流函数来计算0到无穷大之间的衰减值(单位是db),在训练的时候,为了更好地优化增益值,损失函数选择的是基于均方误差的MSE方法,增益值等于α的幂次。研究发现α=0.5在感知上能产生最佳结果。当α趋于0,则相当于最小化对数光谱距离,这是有问题的,因为最佳增益可能非常接近于零。
使用频带获得的较低分辨率的主要缺点是没有足够精细的分辨率来抑制音调谐波之间的噪声。幸运的是,它并不那么重要,甚至还有一个简单的技巧可以做到(见下面的音调过滤部分)。
输出基于22个频带,因此在输入上具有更高的频率分辨率是没有意义的,使用相同的22个频带来向神经网络提供频谱信息即可。音频具有较大的动态范围,所以计算能量的对数比直接输入能量要好得多。得到的数据基于巴克尺度的倒谱,该倒谱与语音识别中非常常用的梅尔频率倒谱系数(MFCC)密切相关。
除了倒谱系数,还有:
1) 前6帧的一二阶倒数
2) 基音周期(1/基音频率)
3)6个子带的基音增益(声音强度)
4)一个特殊的非平稳值,用于检测语音(该例子并未使用)
这为神经网络提供了总共42个输入特征。
5. 深度神经网络层架构
设计的深层架构灵感来自传统的噪声抑制方法。大部分工作由3个GRU层完成。下图显示了我们用于计算频带增益的层,以及架构如何映射到传统噪声抑制的每个步骤。
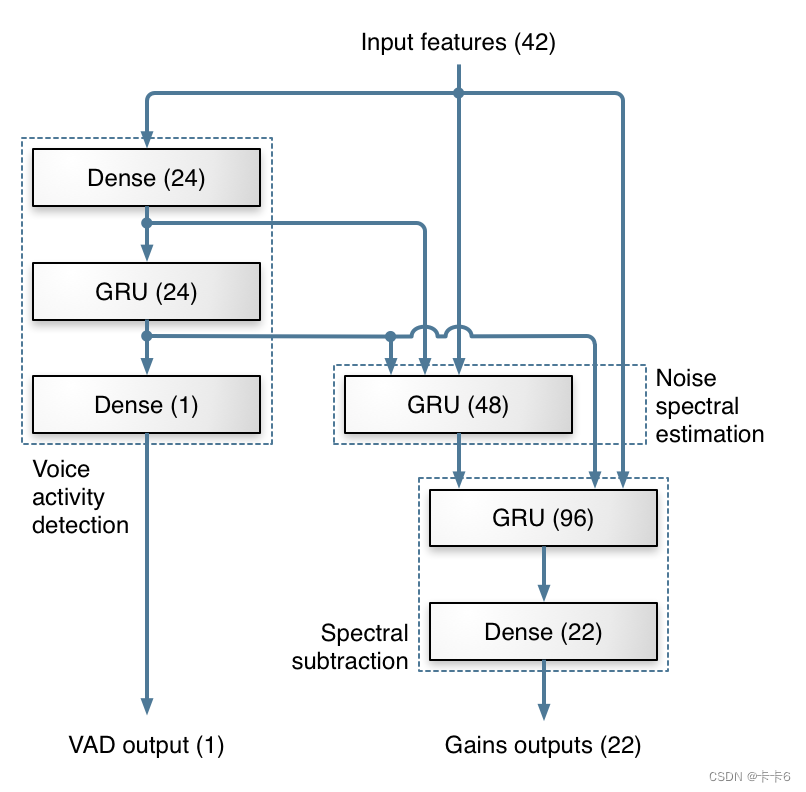
每个方框代表一层神经元,括号中的数字表示数量。Dense层是连在一起的,并且不重复。网络的一个输出对应不同频率下都适用的一组增益,另一个输出是语音活动检测,它不属于于噪声抑制的范围,是网络中一个附属的模块。
6. 关于数据集
深度神经网络有时也会非常愚蠢。他们非常擅长他们所知道的东西,但他们可能会在与所知道的相差太远的输入上犯下非常惊人的错误。神经网络就像一个懒惰的学生,他们可以利用训练数据的任何漏洞来避免学习更困难的东西,就会导致训练的结果不如我们的预期。所以说,训练用的数据十分关键。
典型的失败示例:很久以前,一些军队研究人员试图训练神经网络来识别伪装在树上的坦克。他们拍摄了有坦克和没有坦克的树木的照片,然后训练神经网络来识别有坦克的树木。训练结果远远达不到预期,原因在于:有坦克的照片是在阴天拍摄的,而没有坦克的照片则是在晴天拍摄的,因此网络真正学到的是如何区分阴天和晴天!
对于噪声抑制的场合,不能只收集可用于监督学习的输入/输出数据,因为我们很少能同时获得干净的语音和有噪声的语音,所以需要人为地结合纯净语音以及噪声语音制造一些数据。所以比较棘手的部分应该是如何获取到各种各样的噪声数据,并将噪声数据添加到语音中。此外还必须确保涵盖所有录制条件类型,比如,仅在全频带音频(0-20kHz)上训练的早期版本,训练结果在音频以8kHz以下的音频中不起作用。
与语音识别中常见的做法不同,并不对特征应用倒谱均值进行归一化,且保留表示能量的第一个倒谱系数。而是保持数据包含所有真实级别的音频,还将随机滤波器应用于音频上,使得系统对各种麦克风频率响应具有鲁棒性。
由于我们的频带的频率分辨率不足,无法滤除音调谐波之间的噪声,所以我们使用基本的信号处理。 这是混合方式的另一部分。当有相同变量的多个测量值时,提高精度(降低噪声)的最简单方法就是计算平均值。显然,只是计算相邻音频样本的平均值不是我们想要的,因为它会导致低通滤波。然而,当信号是周期性的(例如语音)时,我们可以计算由基频周期偏移的采样的平均值。引入梳状滤波器,使基频谐波通过,同时衰减它们之间的频率这是含有噪声的部分。为了避免信号失真,梳状滤波器被独立地应用于每个频带,并且其滤波器强度取决于基频相关性和神经网络计算的频带增益。
目前使用FIR滤波器进行基音滤波,但也可以使用IIR滤波器,如果强度太强,则会导致更大的噪声衰减,同时可能导致更高的失真。
7. 从python到C语言
神经网络的所有设计和训练都是使用Keras深度学习库在Python中完成的。由于Python通常不是实时系统的首选语言,所以我们必须在C中实现代码。幸运的是,运行神经网络比训练一个神经网络简单得多,所以我们只需要实现一次前向传播经过GRU层,输出22维的增益。为了更好的调整出权重的合理步幅,我们在训练期间将权重的大小限制为+/- 0.5,这使得可以使用8位值轻松存储它们。所得到的模型仅85 kB(而不是将权重存储为32位浮点数所需的340 kB)。
C代码可以使用BSD许可证。代码在x86 CPU上的运行速度比实时的要快60倍。它甚至比Raspberry Pi 3上的实时速度快7倍。具有良好的矢量化(SSE / AVX),应该可以比现在快四倍。
8. 其他资源
(1)代码:Xiph.Org / rnnoise · GitLab
(2)论文:
AHybridDSP/DeepLearningApproachtoReal-TimeFull-BandSpeechEnhancement (arxiv.org)。
(3)示例项目地址:jmvalin.dreamwidth.org