背景
电商搜索引擎,是帮助顾客快速找到需要购买的商品的工具。
内容
衡量一个电商搜索引擎是否成功的标准是:顾客在一连串的搜索行为当中,是否越来越接近自己的真实需求。顾客越快进入商品页面去浏览商品,越表明搜索引擎推荐的搜索结果越精确。
电商搜索引擎,是传统搜索引擎的一个垂直领域,为了更好地学习搜索引擎的相关知识,首先看一个完整的搜索引擎的技术架构。
搜索引擎的技术架构
一个完整的搜索引擎技术框架,如图所示,搜索引擎的技术架构,分成 3 个部分:信息采集、建立索引库、提供检索服务。
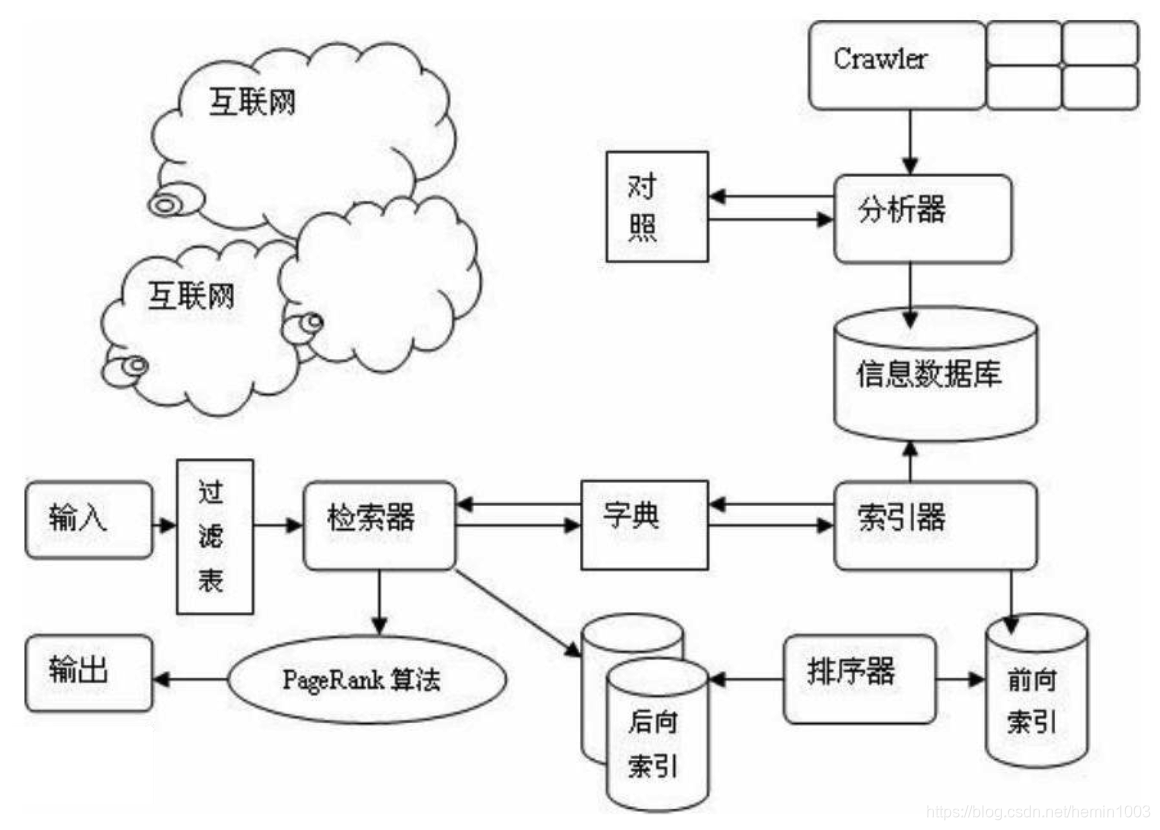
- 1.信息采集
在互联网中发现、搜集信息和数据。通常,这个步骤是通过爬虫(Crawler/Spider)抓取网页来实现的。每个独立的搜索引擎都有自己的网页抓取程序爬虫。 爬虫 Spider 顺着网页中的超链接,从这个网站爬到另一个网站,通过超链接分析连续访问抓取更多网页,被抓取的网页被称之为网页快照。由于互联网中超链接的应用很普遍,理论上,从一定范围的网页出发,就能搜集到绝大多数的网页。
- 2.建立索引库
对收集到的信息进行提取和组织建立索引库。搜索引擎抓到网页后,还要做大量的预处理工作,才能提供检索服务。其中,最重要的就是提取关键词,建立索引库和索引。根据应用场景的不同,其他可能的处理还包括去除重复网页、分词(中文)、判断网页类型、分析超链接、计算网页的重要度/丰富度等。
- 3.提供检索服务
由检索器根据用户输入的查询关键字,提供检索服务。接受到关键词后,系统在索引库中快速检出文档,进行文档与查询的相关度评价,对将要输出的结果进行排序,并将查询结果返回给用户。通常,为了用户便于判断,除了网页标题和 URL 外,还会提供一段来自网页的摘要及其他信息。
其实搜索已经是一项非常成熟的技术,这里不额外再展开讨论了,有兴趣的可以网上了解学习更多这方面的知识。
这里介绍几个在搜索技术架构上比较重要的技术点:分布式索引、分布式搜索
关键技术点
1.分布式索引
分布式索引就是通过很多普通配置的硬件,同时进行索引建立的工作,最后进行索引的合并操作。这样处理的好处在于,具备可扩展性,当数据增加的时候,无须增加单台机器的存储设备,而是通过水平扩展,增加配置普通的机器来解决。
建立分布式索引,可采用 Hadoop 这类分布式系统进行构建:
- Hadoop 实现了一个分布式文件系统(Hadoop Distributed File System),简称 HDFS。HDFS 有高容错性的特点,并且设计用来部署在低廉的硬件上。同时它提供高传输率来访问应用程序的数据,适合那些有着超大数据集的应用程序。
- HDFS 的上一层是 MapReduce 引擎,用于大规模数据集的并行运算。概念 Map(映射)和 Reduce (规约),和它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借 来的特性。基于这些分布式特性,搜索索引建立可以非常容易地通过它来进行扩展。
- 利用 Hadoop 的平台和 MapReduce 的机制,来实现建立分布式搜索索引,是非常好的实践。
2.分布式搜索
分布式搜索,是将原来的单个索引文件划分成 n 个切片(shards)。搜索时,并行的搜索这 n 个切片,每个切片返回当前 shard 的 topK 命中结果,然后将 n 个切片的局部 topK 进行归并排序,得到全局的 topK 排序结果。
分布式搜索的好处在于:
- 更好的可扩展性,在用户访问次数和索引大小两个维度都具有水平扩展能力。
- 更高的稳定性,容许部分失败,调用成功率显著提高。
- 更灵活的全量更新策略,可针对不同类型的数据。
- 更灵活的排序算法,可以针对不同类目,做定制化的排序。
- 更好的可维护性和通用性,支持不同类型的搜索。
上一章教程
该系列教程
我的专栏
至此,全部介绍就结束了
-------------------------------
-------------------------------
关于我(个人域名,更多我的信息)
期望和大家一起学习,一起成长,共勉,O(∩_∩)O谢谢
欢迎交流问题,可加个人QQ 469580884,
或者,加我的群号 751925591,一起探讨交流问题
不讲虚的,只做实干家
Talk is cheap,show me the code
