先在右侧目录查找感兴趣的问题➡
1. IL是什么?
IL的全称是Intermediate Language,很多时候我们看到的是CIL(Common Intermediate Language,特指在.NET平台下的IL标准),其实大部分文章中提到的IL和CIL表示的是同一个东西,即中间语言。IL是一种低阶(lowest-level)的人类可读的编程语言。我们可以将通用语言翻译成IL,然后汇编成字节码,最后运行在虚拟机上。也可以把IL看作一个面向对象的汇编语言,只是它必须运行在虚拟机上,而且是完全基于堆栈的语言。
IL有三种转译模式:
Just-in-time(JIT)编译:在编译的时候,把C#编译成CIL,在运行时,逐条读入,逐条解析翻译成机器码交给CPU再执行。
Ahead-of-Time(AOT)编译:在编译成CIL之后,会把CIL再处理一遍,编译成机器码,在运行的时候交给CPU直接执行,Mono下的AOT只会处理部分的CIL,还有一部分CIL采用了JIT的模式。
Full AOT 完全静态编译:在编译成CIL之后,把所有的CIL编译成机器码,在运行的时候直接执行,这个模式适用于iOS操作系统。
2. Mono和IL2CPP有什么区别?为什么要使用IL2CPP?
C#主要运行在.NET平台上,但.NET跨平台支持不好。
Mono是.NET的一个开源,跨平台的实现,它包含一个C#编译器,mono运行时(CLR),和一组类库,Mono使得C#有了很好的跨平台能力。C#这种遵循CLI规范的高级语言,会被编译器编译成中间语言IL(CIL),当需要运行它们时就会被实时地加载到运行时库中,由虚拟机动态地编译成汇编代码(JIT)并执行。
IL2CPP的编译和运行过程:首先还是由Mono将C#语言翻译成IL,IL2CPP在得到中间语言IL后,将它们重新翻译成C++代码,再由各个平台的C++编译器直接编译成能执行的机器码。
为什么要使用IL2CPP:
1)Mono虚拟机维护成本过大。
2)Mono版本授权受限。
3)提高运行效率。换成IL2CPP以后,程序的运行效率有了1.5~2.0倍的提升。
3. 什么是托管代码,什么是非托管代码?
C#代码生成的IL编码我们称为托管代码,由虚拟机的JIT编译执行,其中的对象无须手动释放,它们由GC管理。C/C++或C#中以不安全类型写的代码我们称为非托管代码,虚拟机无法跟踪到这类代码对象
4. Mono的垃圾回收机制
Mono将Simple Generational GC(SGen-GC)设置为默认的垃圾回收器,当我们向垃圾回收器申请内存时,如果发现内存不足,就会自动触发垃圾回收,或者也可以主动触发垃圾回收,垃圾回收器此时会遍历内存中所有对象的引用关系,如果没有被任何对象引用则会释放内存。SGen-GC的主要思想是将对象分为两个内存池,一个较新,一个较老,那些存活时间长的对象都会被转移到较老的内存池中去。这种设计是基于这样的一个事实:程序经常会申请一些小的临时对象,用完了马上就释放。而如果某个对象一段时间没被释放,往往很长时间都不会释放。
IL2CPP的虚拟机的内存管理仍然采用类似Mono的方式,因此程序员在使用IL2CPP时无须关心Mono与IL2CPP之间的内存差异。
5. List底层是如何实现的?
这个问题考察对源码的理解,源码地址
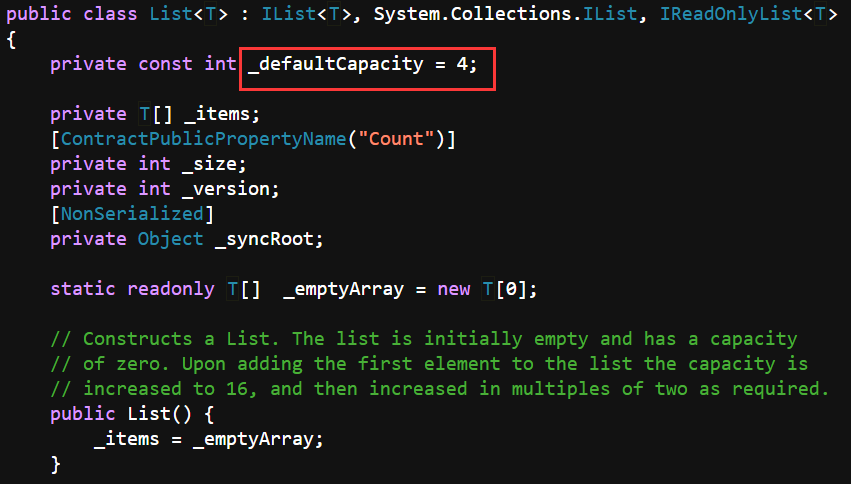
List内部是用数组实现的,如果不指定长度,则使用默认的空数组。
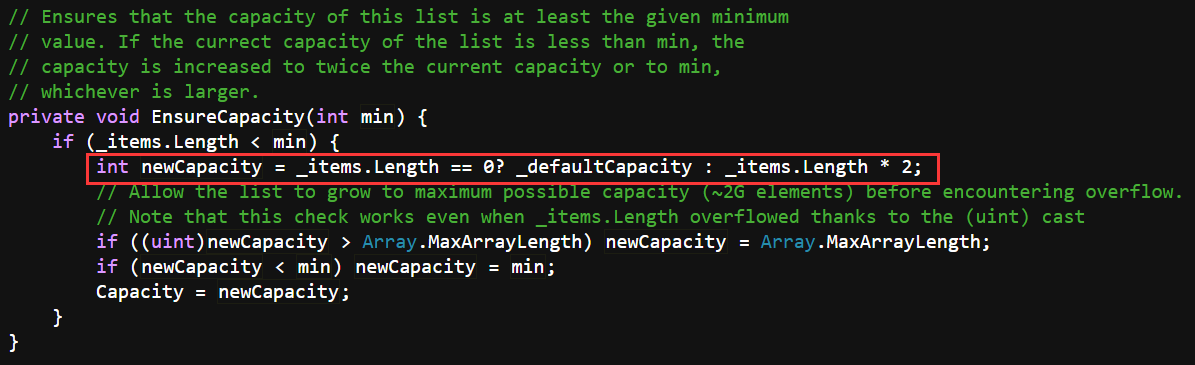
Add接口:添加元素前会先检查容量,容量为0则会增加到4,之后每次扩充都是增加到当前容量的2倍。改变容量会new一个新的数组,通过Array.Copy方法将原数组的元素复制过去。
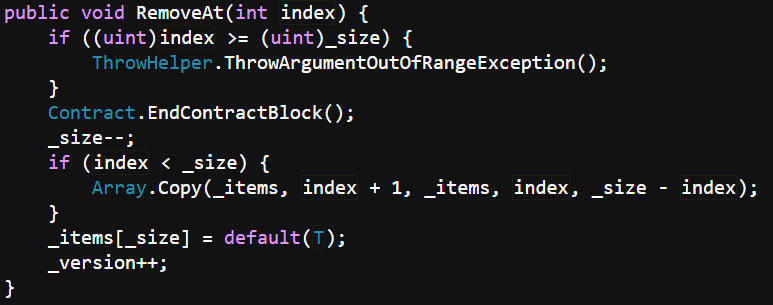
Remove接口:通过IndexOf方法查找元素位置(线性O(n)),然后在RemoveAt中使用Array.Copy对数组进行覆盖。
Insert接口:与Add接口一样,先检查容量是否足够,不足则扩容一倍。同样使用的是数组覆盖的形式,将数组里指定元素后面的所有元素向后移动一个位置。
Clear接口:调用Array.Clear方法,在调用时并不会删除数组,而只是将数组中的元素设置为0或NULL,并设置_size为0而已。
Contains接口:执行线性O(n)搜索。是否相等是通过调用Equals()来确定的。
ToArray接口:它重新创建了一个指定大小的数组,将本身数组上的内容复制到新数组上再返回
Find接口:同样线性O(n)。
Enumerator接口:每次获取迭代器时,Enumerator都会被创建出来,如果大量使用迭代器,比如foreach,就会产生大量的垃圾对象,这也是为什么我们常常告诫程序员尽量不要使用foreach,因为List的foreach会增加新的Enumerator实例,最后由GC单元将垃圾回收掉。虽然.NET在4.0后已经修复了此问题,但仍然不建议大量使用foreach。
Sort接口:它使用了Array.Sort接口进行排序,而Array.Sort使用快速排序实现,故效率为O(nlgn)。
总结:List的效率并不高,大部分算法使用的是线性复杂度的算法,我们可以在创建List实例时指定容量,这样List就不会因为空间不够而抛弃原有的数组去重新申请数组了。另外也可以从源码中看出,代码是线程不安全的,它并没有对多线程做任何加锁或其他同步操作。由于并发情况下无法判断_size++的执行顺序,因此当我们在多线程间使用List时应加上安全机制。
6. Stack底层如何实现的?
Stack内部也是数组实现的,与List一样,也是按照2倍的容量去扩容,只是默认容量不一样,Stack默认构建一个容量为10的数组。
7. Queue底层如何实现的?
Queue内部仍然是数组实现的,通过增长因子_growFactor和最小增长量_MinimumGrow来调整容量,默认的增长因子是200。
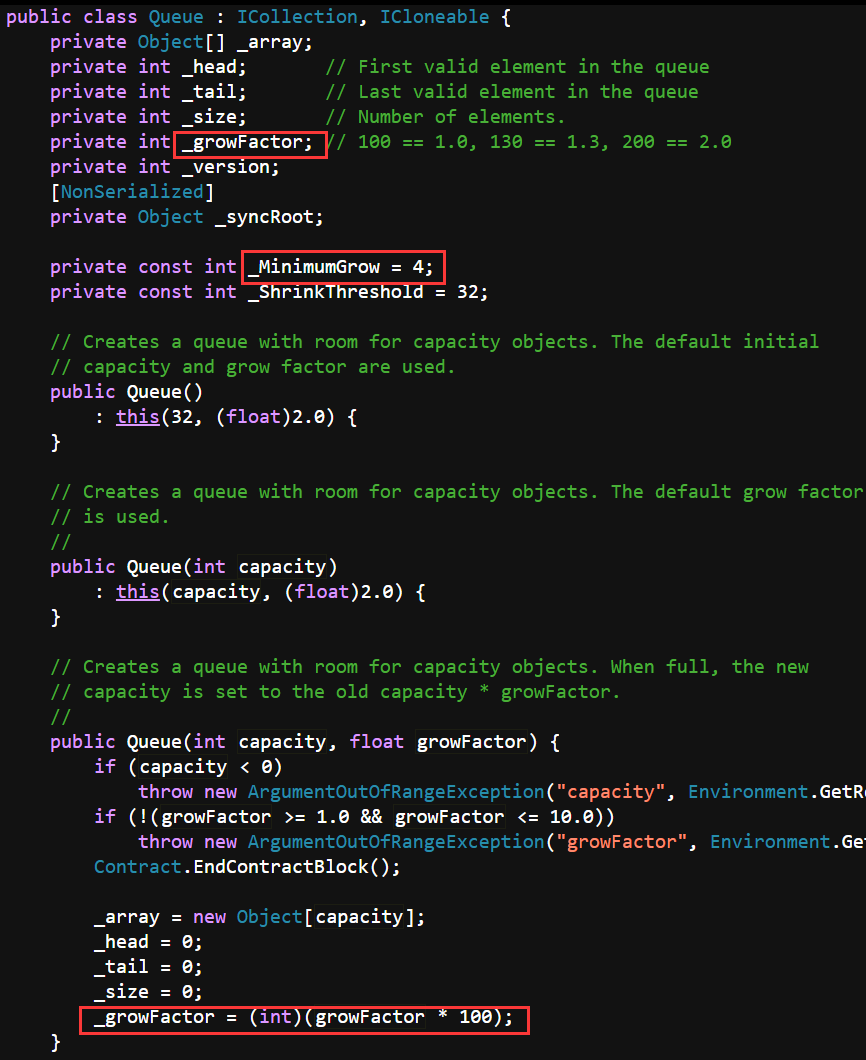
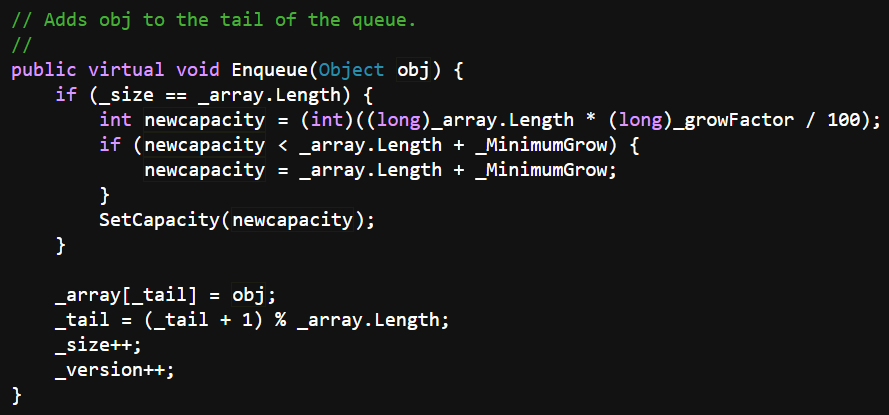
可以看到,Queue基本上还是按照两倍的容量去扩容。
8. Dictionary底层是如何实现的?是如何解决冲突的?
源码地址
详细的插入,删除操作参考这篇文章Dictionary原理
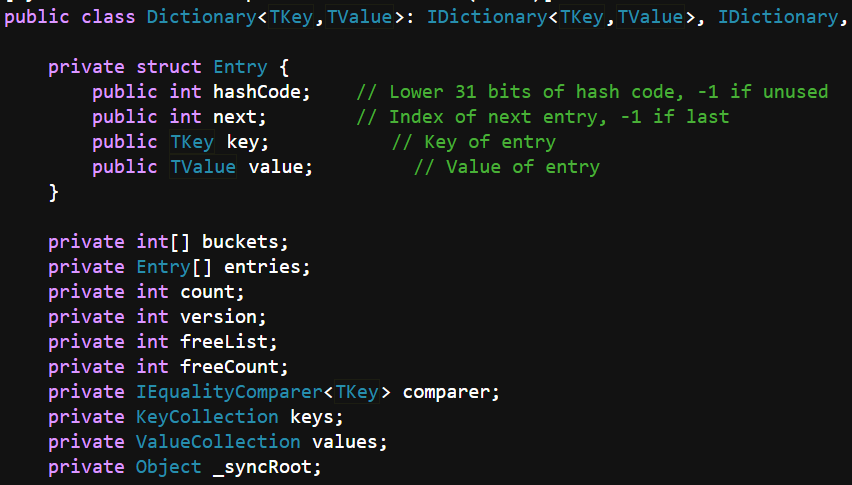
Dictionary底层仍然是用数组来实现的,Entry是个结构体,记录了数据的键值以及下一个元素的位置,entries数组记录每个元素,buckets数组主要用于碰撞检测,计算hash后,buckets数组对应位置记录entries数组元素的下标,所以buckets数组是存放索引的。
Hash函数有很多种算法,最简单的可以认为是余操作,比如当Key为整数时,可以直接取余。
对于实例对象和字符串来说,它们没有直接的数字作为Hash标准,因此它们需要通过内存地址计算一个Hash值,计算这个内存对象的函数就叫HashCode,它是基于内存地址计算得到的结果,编写类时可重载HashCode()来设计一个我们自己的Hash值计算方式,也可以使用原始的计算方式。
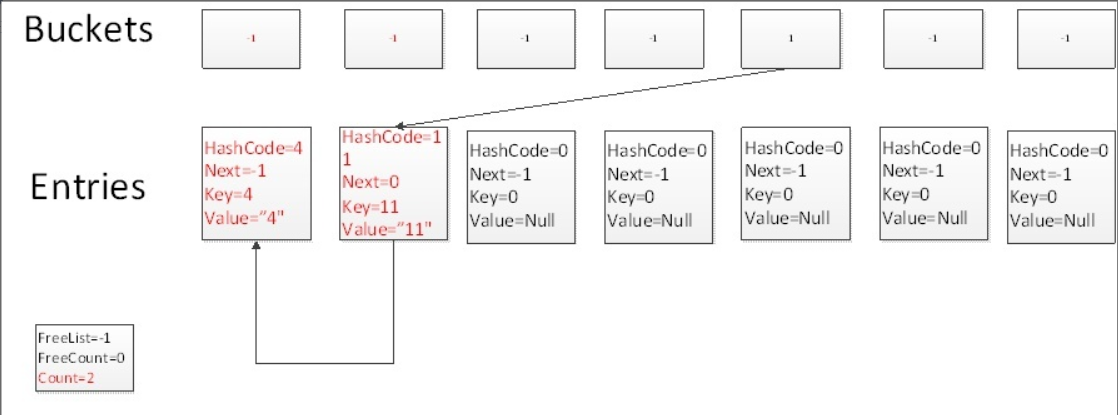
处理Hash冲突的方法中,通常有开放定址法、再Hash法、链地址法、建立一个公共溢出区等。Dictionary使用的解决冲突方法是拉链法,又称链地址法。
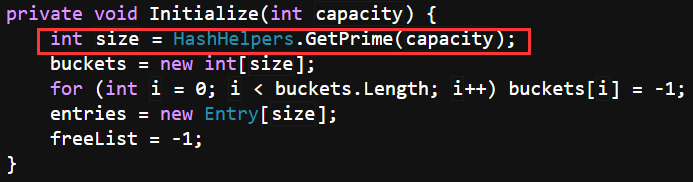
当实例化new Dictionary()后,不指定容量,内部的数组容量是0个的状态。

如果指定了容量,会调用HashHelpers.GetPrime(capacity)获取实际容量,HashHelpers内部有一个质数数组primes,会从数组中找到第一个比capacity大的质数作为实际容量。
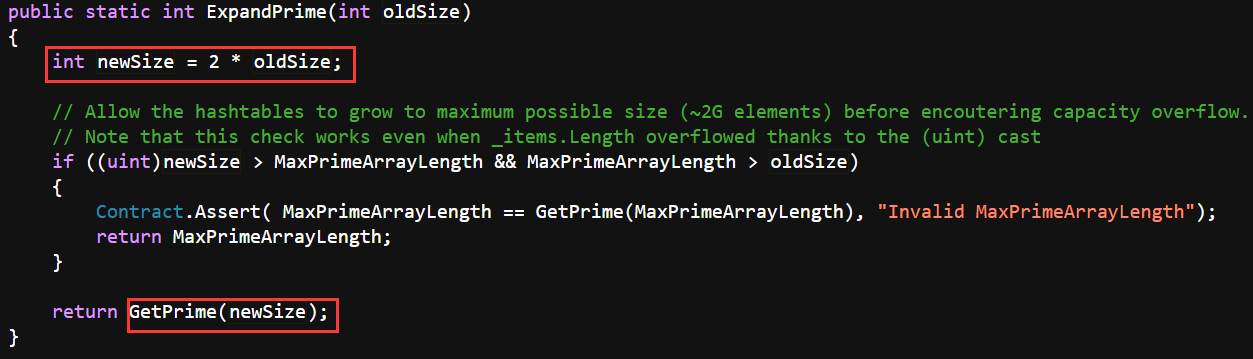
当数组容量不足触发扩容时,会先将当前容量乘以2得到newSize,然后从primes数组中找第一个比newSize大的质数作为新的容量,所以Dictionary扩容是按照两倍多的速度增加。
注意源码中Remove()函数的移除操作并没有对内存进行删减,而只是将其单元格置空,这是为了减少内存的频繁操作。
总结:Dictionary是由数组实现的,其中buckets主要用来进行Hash碰撞,entries用来存储字典的内容,并且标识下一个元素的位置,拉链法来解决冲突的。从效率上看,同List一样,最好在新建时,确定大致数量,这样会使得内存分配次数减少,另外,使用数值作为键值比使用类实例的方式更高效,因为类对象实例的Hash值通常都由内存地址再计算得到。从内存操作上看,其大小以3→7→17→37→…的速度(每次增加2倍多)增长,删除时,并不缩减内存。
9. HashSet底层是如何实现的?
HashSet与Dictionary类似,也是维护两个数组存放索引和数据,扩容的方式也一样,只是没有key值。
10. Dictionary与Hashtable的区别?
1.Hashtable在多线程读/写中是线程安全的,而Dictionary不是。如果要在多个线程中共享Dictionary的读/写操作,就要自己写lock,以保证线程安全。
2.Dictionary的key和value是泛型存储,数据类型固定,不需要进行类型转换,Hashtable的key和value都是object,在存储或者读取值时会发生装箱和拆箱,所以比较耗时,适合数据类型不唯一的情况。
3.Dictionary保持存储值的插入顺序,HashTable不维护插入键值数据的任何顺序。
11. 浮点数精度问题导致不同设备计算结果不同,有哪些解决方法?
1.使用某客户端的计算结果或由服务器决定计算结果,只计算一次,且认定这个值为准确值,把这个值传递给其他设备或模块。
2.改用int或long类型来替代浮点数,把浮点数乘以10的幂次得到更准确的整数再进行计算,由于整数的计算是确定的,因此就不会存在误差,但要注意计算结果可能超出上限。
3.用定点数替代浮点数,定点数把整数部分和小数部分拆分开来,都用整数的形式表示,缺点是由于拆分了整数和小数,两个部分都要占用空间,所以受到存储位数的限制。大部分项目都会自己实现定点数,无论是整数部分还是小数部分,都用整数表示,并封装在类中。因此需要重载所有的基本计算和比较符号,也可以使用开源的定点数库。
4.用字符串代替浮点数,缺点是CPU和内存的消耗特别大,只能做少量高精度的计算。
12. 委托,事件,UnityEvent
委托是一种类(class),我们在创建委托时,其实就是创建一个Delegate类实例。委托可以看作是一个函数指针数组,保存一个或多个函数地址,当使用 =(等号)操作时,就会把函数地址保存到这个数组中,多播委托就会保存多个函数地址。当委托被调用时,会把数组中的函数依次调用一遍。
事件(event)是委托(delegate)的封装,用户不能再直接用 =(等号)操作来改变委托变量,用户只能通过 “+=” 和 “-=” 操作来注册或删除委托函数的数量。公开的delegate会直接暴露在外,随时会被 “=” 赋值而清空前面累积起来的委托函数,封装后就保证了 “谁注册就必须谁负责销毁” 的目的,更好地维护了delegate的秩序。委托可以作为方法参数传递,事件不行。
UnityEvent使用Serializable序列化,方便开发者直接在检视面板中编辑事件及事件回调函数,简化开发流程。使用event需要手动编写代码且无法直接编辑。UnityEvent首次触发事件时会产生垃圾,而C# event不会产生任何垃圾,且前者的速度比后者慢两倍之多。
13. 栈内存和堆内存的区别?
栈空间比较小,栈遵循先进后出的原则。它是一段连续的内存,所以对栈数据的定位比较快速,栈创建和删除的时间复杂度则是O(1);
堆空间比较大,堆是随机分配的空间,处理的数据比较多,无论情况如何,都至少要两次才能定位。堆内存的创建和删除节点的时间复杂度是O(lgn)。
栈是由系统管理的,栈中的生命周期必须确定,销毁时必须按次序销毁,即从最后分配的块部分开始销毁,创建后什么时候销毁必须是一个定量,所以在分配和销毁上不灵活,它基本都用于函数调用和递归调用这些生命周期比较确定的地方。
相反,堆内存可以存放生命周期不确定的内存块,满足当需要删除时再删除的需求,所以堆内存相对于全局类型的内存块更适合,分配和销毁更灵活。
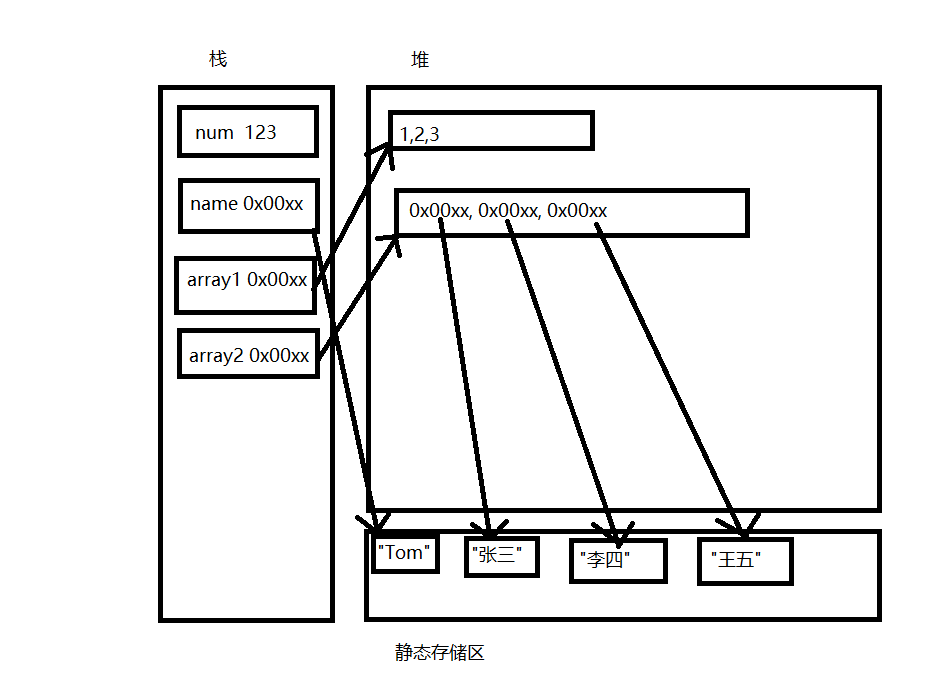
14. 内存分布
int num = 123;
string name = "Tom";
int[] array1 = new int[]{
1,2,3};
string[] array2 = new string[]{
"张三", "李四", "王五"};
上诉变量在内存中的分布
15. string暂存池
CLR对于string进行了特殊的优化,CLR中存在“字符串暂存池”概念。在CLR初始化时创建一个内部的哈希表,这个表相当于一个字典表,键就是字符串,值是指向该字符串对象的引用。详细参考
16. 闭包
C#会对闭包进行面向对象的改造,方法不能脱离类独立存在,所以编译器会生成一个类,将匿名函数作为这个类的方法,引用的外部变量作为类的字段。底层原理
17. 值类型和引用类型的区别?
1.值类型是直接存储数据,引用类型持有的是数据的引用,其真实数据存储在堆中。
2.值类型的复制操作是直接复制数据,引用类型的复制是复制引用(类似指针)。
3.引用类型可以实现继承关系,值类型不行。
4.很多人把值类型与引用类型归为栈内存和堆内存分配的区别,这是错误的,栈内存主要为确定性生命周期的内存服务,堆内存则更多的是无序的随时可以释放的内存。因此值类型可以在堆内也可以在栈内,引用类型的指针部分也一样,可以在栈内和堆内,区别在于引用类型指向的内存块都在堆内。
以下情况值类型会分配在堆上:数组中的元素,引用类型中的值类型字段,迭代器中的局部变量,闭包情况下匿名函数(lamda)中的局部变量,如果分配到栈上会随着方法调用的结束而清除,分配到托管堆上,以满足在方法调用后还能被访问的要求。
下面代码执行的结果是什么?
public struct Record
{
public int id;
public string name;
public int[] children;
}
public static void DoSomething(Record record)
{
record.id = 6;
record.name = "Bob";
record.children[0] = 7;
}
public static void Run()
{
var record = new Record();
record.name = "Alice";
record.children = new int[] {
1, 2, 3 };
DoSomething(record);
Debug.Log(string.Format("{0}-{1}-{2}", record.id, record.name, record.children[0]));
}
/*
上述代码执行结果是 0-Alice-7
Record是结构体属于值类型,方法参数没有标注ref,out都是值传递,所以DoSomething内部是创建了一个新的record,
并复制了原来record内部的值和引用。record.id默认初始化为0,DoSomething方法内部修改不影响原来的值。
record.name虽然是引用类型,但是因为字符串的不可变性,record.name = "Bob" 其实是创建了一个新的字符串"Bob"
并赋值给了record.name,所以DoSomething中的record.name和Run中的record.name是指向两个不同的地址。
DoSomething中的record.children和Run中的record.children指向同一个地址,所以修改会影响到原来的值。
如果将DoSomething里边的 record.chileren[0] = 7, 改成 record.children = new int[]{ 4, 5, 6 },
那DoSomething中的record.children和Run中的record.children就指向不同地址,修改不会影响原来的值。
如果将Record改为class,那么上述代码执行结果是 6-Bob-7
引用类型作为参数仍然是值传递,DoSomething内部会创建了一个新的record并复制原来record的引用,所以修改会
影响到原来的值。
此时如果修改DoSomething如下,那么DoSomething中的record和Run中的record就指向不同的地址。
public static void DoSomething(Record record)
{
record = new Record();
record.id = 6;
record.name = "Bob";
record.children = new int[] { 4, 5, 6 };
}
*/
18. 装箱和拆箱的区别,哪个会产生gc,什么时候会发生装箱?
装箱:把值类型实例转换为引用类型实例。拆箱:把引用类型实例转换为值类型实例。
装箱的内部操作:
第一步:在堆内存中新分配一个内存块(大小为值类型实例大小加上一个方法表指针和一个SyncBlockIndex类)。
第二步:将值类型的实例字段复制到新分配的内存块中。
第三步:返回内存堆中新分配对象的地址。这个地址就是一个指向对象的引用。
拆箱的操作:先检查对象实例,确保它是给定值类型的一个装箱值,再将该值从实例复制到值类型变量的内存块中。
由于装箱、拆箱时生成的是全新的对象,不断地分配和销毁内存不但会大量消耗CPU,同时也会增加内存碎片,降低性能。装箱需要消耗的托管堆内存,如果有大量的对象产生,会增加gc的压力。
发生装箱的情况:
1.当程序、逻辑或接口为了更加通用把参数定义为object,一个值类型(如Int32)传入时,就需要装箱。
2.一个非泛型的容器为了保证通用,而将元素类型定义为object,当值类型数据加入容器时,就需要装箱。
3.当结构体实现接口,而接口又持有该结构体时会发生装箱。
interface IAnimal
{
void Eat();
}
struct Animal : IAnimal
{
public void Eat()
{
//do some
}
}
public class Test : MonoBehaviour
{
void Start()
{
Animal ani = new Animal();
//struct是值类型,接口是引用类型,会装箱
IAnimal iAnimal = ani;
}
}
4.值类型调用基类Object中的方法可能会装箱。
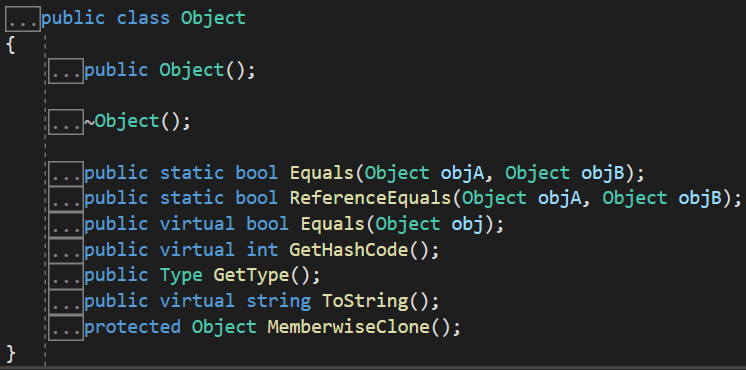
GetType方法返回System.Type是非虚方法,值类型实例调用GetType方法一定会装箱。
int重写了ToString方法,所以int调用ToString不会装箱。
结构体直接调用ToString,GetHashCode会装箱,如果重写了方法可以避免装箱。
Dictionary、HashSet, 如果Key是结构体,对其进行操作会触发Equals方法和GetHashCode方法,是会发生装箱的,解决方法是实现lEqualityComparer。
19. 结构体和类的区别
1.结构体是值类型,类是引用类型
2.结构体成员不能使用protected访问修饰符,而类可以
3.结构体成员变量申明不能指定初始值,而类可以
4.结构体不能申明无参的构造函数,而类可以
5.结构体不能申明析构函数,而类可以
6.结构体不能被继承,而类可以
7.结构体需要在构造函数中初始化所有成员变量,而类随意
8.结构体不能被静态static修饰(不存在静态结构体),而类可以
9.使用 new 操作符创建一个结构体,会调用构造函数来创建结构体。与类不同,结构可以不使用 new 操作符即可被实例化。
如果不使用 new 操作符,只有在所有的字段都被初始化之后,字段才被赋值,对象才能使用。
10.结构体比较特殊,他不能使用比较运算符(==),使用 Equals() 方法进行比较时,当两个结构体对象的所有字段的值都相等时返回 true,否则返回 false。

注意对象和结构体的对齐规则,对齐规则是按照其中元素最大的对齐规则决定的。参考视频
数据总线:CPU从内存中读取数据,一次读取多少,一般是8Byte。
一个地址存放1Byte,即CPU一次可以读取8个地址。
//优化前
struct S
{
int x;
long z;
int y;
}
//这个结构体的大小是24Byte,如果没有内存对齐,CPU读取z就要读2次,影响效率
//优化后
struct S
{
int x;
int y;
long z;
}
//这个结构体的大小是16
[StructLayout(LayoutKind.Sequential,Pack = 1)]
public struct S
{
byte b1;
int il;
byte b2;
}
//该结构体强制按1字节对齐,所以它的大小就是6。
20. 什么时候用结构体,什么时候用类?
1.用到继承和多态时用类。
2.结构体复制或者作为参数传递时不会改变原来对象的值,如果需要这种特性可以使用结构体。类对象是引用传递会改变原来对象的值。
3.因为值类型复制的特性,如果结构体定义了很多字段,复制的成本就会很高,所有结构体适用于数据量小的场景。
21. ref, in和out的区别
这三个关键字都是按引用传递,ref表示可读写,传递ref参数必须是最先初始化,in表示只读的,out表示只写的,传递out参数不需要显示初始化,类似返回值。按引用传参,特别是传递较大的结构体参数,可以减少复制带来的开销。在MSDN的优化建议中也提到,推荐所有大于IntPtr.Size的结构体,传参时都按引用传递,但需要注意这样会改变结构体原来的值。
22. 什么是drawcall?
CPU在每次通知GPU进行渲染之前,都需要提前准备好顶点数据(如位置、法线、颜色、纹理坐标等),然后调用一系列API把它们放到GPU可以访问到的指定位置,最后调用一个绘制命令。而调用绘制命令的时候,就会产生一个drawcall。过多的drawcall会造成CPU的性能瓶颈,这是因为每次调用drawcall时,为了把一个对象渲染到屏幕上,CPU需要检查哪些光源影响了该物体,绑定shader并设置它的参数,再把渲染命令发送给GPU。当场景中包含了大量对象时,这些操作就会非常耗时。降低drawcall应该避免使用过多材质,尽量共享材质,尽量合并网格。
23. 帧同步是如何同步的?
服务器把玩家的操作同步给所有的玩家,玩家在本地客户端,根据服务器发过来的操作,来推进游戏。
同样的代码 + 同样输入 —> 同样的结果
服务器,每隔一端时间,将采集的玩家的操作,发给所有的客户端,继续采集下一次的操作,等下一次时间到,又把采集到的操作发送給所有客户端。
客户端:收到服务器的操作 —> 计算游戏逻辑 —> 上报下一帧的操作给服务器。
24. 状态同步和帧同步区别?
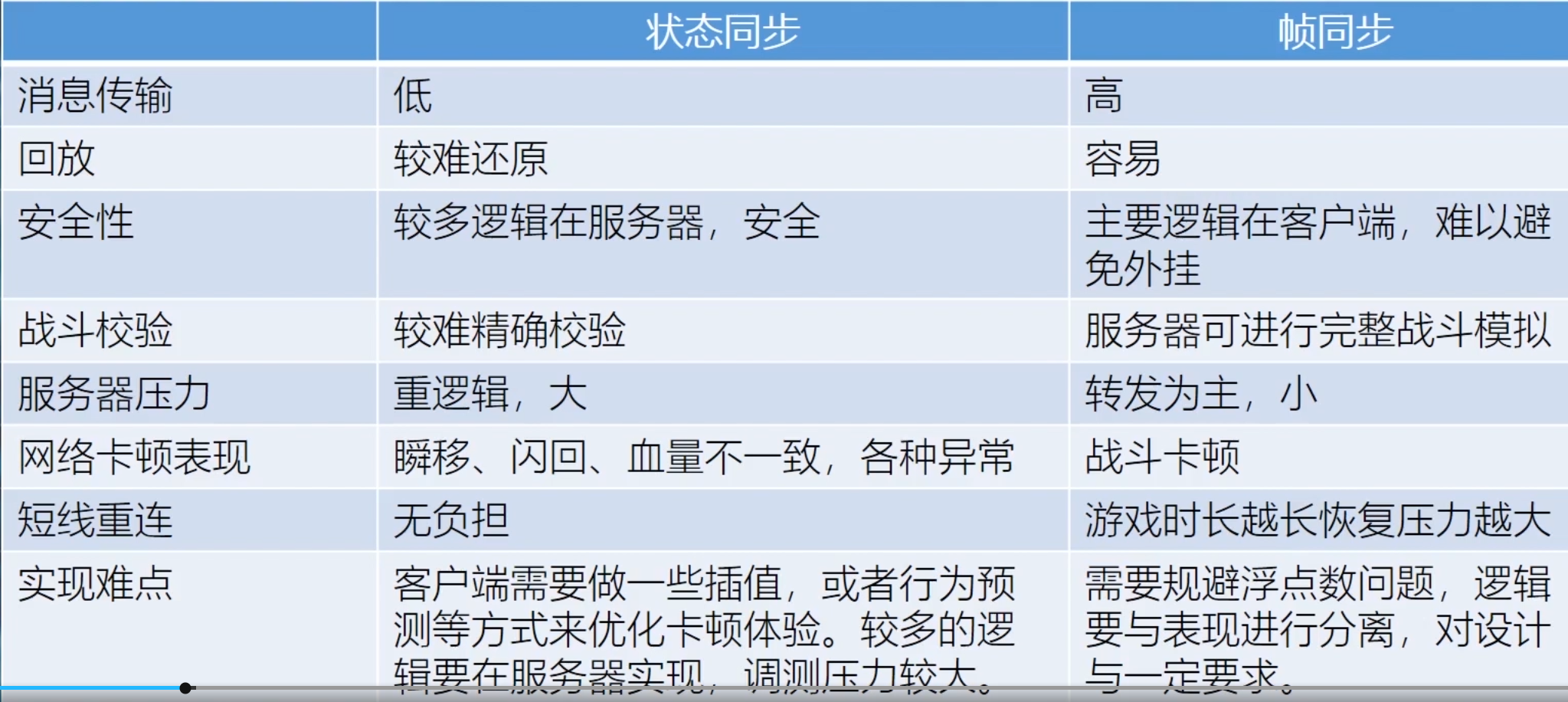
状态同步:发操作,收状态
帧同步:发操作,收操作
25. 面向对象三大特性,多态怎么实现?面向对象编程的七大原则
封装:隐藏对象的属性和方法的具体实现,只对外公开接口,增强数据的安全性。
继承:提高代码重用度,增强软件可维护性的重要手段,符合开闭原则。
多态性:主要通过子类对父类方法的覆盖来实现多态,多态性是指同名的方法在不同环境下,自适应的反应出不同得表现,是方法动态展示的重要手段。(这是动态的多态,重载属于静态的多态。)
七大原则
S 单一功能原则:设计的类,接口,对象等应该仅具有一种单一功能。
O 开闭原则:对于扩展开放的,但是对于修改封闭的。
L 里氏替换原则:子类可以扩展父类的功能,但不能修改父类的功能。
I 接口隔离原则:一个接口应该只有一个方法。
D 依赖反转原则:高层不应该依赖于底层,高层和底层都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
迪米特法则:一个类对于其他类知道的越少越好,即降低耦合。
合成复用原则:组合优于继承,能用组合的地方就不要用继承。ECS使用到这个原则
26. 设计一个与服务器进行socket通信的包结构
要进行socket通信,包结构基本原则,固定包头长度+包体内容。
包头:
- 消息数据id。这个id是用于反序列化时的标识,比如1代表开始战斗StartBattleMsg,那么服务器收到这个包头以后就根据双方协议StartBattleMsg的定义去反序列化后面的数据。
- 包体长度。因为每个数据包长度不一致,所以要知道后续包体有多长,才能进行对应的粘包拆包操作。
包体:序列化后的数据。
27. 遮挡剔除原理?
遮挡剔除会使用一个虚拟的摄像机来遍历场景,从而构建一个潜在可见的对象集合的层级结构。在运行时刻,每个摄像机将会使用这个数据来识别哪些物体是可见的,而哪些被其他物体挡住不可见。使用遮挡剔除技术,不仅可以减少处理的顶点数目,还可以减少overdraw,提高游戏性能。
28. 触发和碰撞条件?
触发:两者都有Collider组件,其中之一有刚体组件,其中之一有勾选Is Trigger,两者相交时,不管有没有勾选Is Trigger,都会触发OnTrigger相关函数。
碰撞:两者都有Collider组件,两者都不勾选Is Trigger,运动的物体有刚体,Physics设置中layer有碰撞检测。
29. Destroy和DestroyImmediate的区别?
DestroyImmediate是立即销毁,立即释放资源,做这个操作的时候,会消耗很多时间的,影响主线程运行。Destroy是异步销毁,一般在下一帧就销毁了,不会影响主线程的运行。
30. UI上的特效怎么被裁剪?
获取RectMask2D或者Mask的RectTransform,接着去调用GetWorldCorners获得该UI在世界坐标的信息坐标,然后设置参数给Shader,让其根据Rect坐标进行裁剪。而Shader的实现很简单,将超出部分的透明度设置为0。
31. UGUI和NGUI区别
1.UGUI通过Mask,RectMask2D来裁剪,而NGUI通过Panel的Clip。
2.NGUI的渲染前后顺序是通过Widget的depth,depth可以手动设置,而UGUI渲染顺序根据Hierarchy的顺序,越下面渲染在顶层,元素depth是动态算出来的。所以在制作功能界面时,DrawCall控制 NGUI > UGUI。
3.NGUI的UIPanel上有DrawCall Tool可以显示drawcall信息,哪些东西合并成了一个drawcall,UGUI没有这种功能。
4.UGUI不需要绑定Colliders,UI可以自动拦截事件,而NGUI需要绑定,UICamera用射线判断点击的物体并通过SendMessage调用OnClick() OnPress()等函数,而SendMessage利用反射机制。
5.UGUI的Navgation在Scene中能可视化。
6.UGUI界面展示是在Canvas下,而NGUI是在UIRoot下。
7.UGUI使用RectTransform控制元素的位置,缩放等信息,NGUI没有用到这个组件。
8.NGUI全部是用C#开发的,UGUI底层代码可以基于C++进行原生的编程。
9.元素的更新方式不同,NGUI的UIPanel会在LateUpdate里遍历所有的widget,如果有widget发生变化,则触发更新,即使没有变化的UI元素,也会有正常的轮询操作的开销。UGUI是通过两个队列m_LayoutRebuildQueue和m_GraphicRebuildQueue分别记录Layout和Graphic发生变化的UI元素,在渲染之前,会在这个回调函数Canvas.SendWillRenderCanvas里去处理这两个队列里的元素,即分别进行Rebuild。
10.NGUI是必须先打出图集然后才能开始做界面。这一点很烦,因为始终都要去考虑你的UI图集。比如图集会不会超1024 ,图集该如何来规划等等。而UGUI的原理则是,让开发者彻底模糊图集的概念,让开发者不要去关心自己的图集。做界面的时候只用小图,而在最终打包的时候unity才会把你的小图和并在一张大的图集里面。然而这一切一切都是自动完成的,开发者不需要去care它。
11.网格更新机制不同,NGUI可以只更新单个DrawCall,UGUI必须重建整个Canvas。 在功能界面的网格更新控制,NGUI >UGUI。在动态HUD界面(如血条,伤害数字,弹出的一些文本等)的网格更新控制,UGUI >> NGUI(因为UGUI网格合并这块的算法是用C++做的,所以会比在C#做的快很多,而且C#难免会触发一些堆内存的问题)
NGUI:UIPanel.LateUpdate两种更新方式
– UIPanel.FillDrawCall 更新单个DrawCall
– UIPanel.FillAllDrawCall 更新所有DrawCall
UGUI:Canvas.BuildBatch 更新所有DrawCall
– WaitingForJob
– PutGeometryJobFence
– BatchRenderer.Flush(开了多线程渲染之后) 所以做优化时建议先关闭多线程渲染
32. NGUI渲染过程
Unity在制作一个图元,或者一个按钮,或者一个背景时,都会先构建一个方形网格,网格的绘制单位是图元(点,线,三角面),再将图片放入网格中。可以理解为构建了一个3D模型,用一个网格绑定一个材质球,材质球里存放要显示的图片。
渲染过程:UI元素都继承自UIWidget,UIPanel遍历自己子物体的UIWidget组件,放入到一个List中,按照depth排序。List中相邻元素如果material,texture,shader相同,就传递它们的material,texture,shader,Geometry缓存都传给同一个UIDrawCall,否则就再创建一个新的UIDrawCall。每次有新的UIDrawCall产生,UIPanel就会调用上一个UIDrawCall的UpdateGeometry()函数,来创建渲染所需的对象。这些对象分别是MeshFilter,MeshRender,和最重要的Mesh(Mesh的顶点,UV,Color,法线,切线,还有三角面)。UIDrawcall是渲染UI元素的载体,UIPanel生成UIDrawcall,UIDrawcall是一个组件,挂载在一个GameObject,这个GameObject上再挂载MeshRender、Mesh、MeshFilter、材质等Unity组件,通过这些组件将UI元素渲染出来。我们在Editor中是看不到这个GameObject的,是因为创建的时候设置了HideFlags.HideAndDontSave。
33. UGUI渲染过程
UGUI的depth是动态算出来的,按照Hierarchy的节点顺序从上向下进行depth分析,最下层的元素depth = 0,元素相交会先判断是否能合批,材质id一样,图片id一样才能合批,比如元素A和元素B相交且B盖住了A,如果A,B可以合批,那么depthB = depthA,否则 depthB = depthA + 1,如果一个元素盖住了多个元素,则选取下面depth最大的元素进行合批判断。从规则中可以看出,depth值与是否相交有关,与是否为子节点无关。相同depth的元素会根据Material ID和Texture ID(字体的Texture ID就是其字体的ID)进行升序排序。
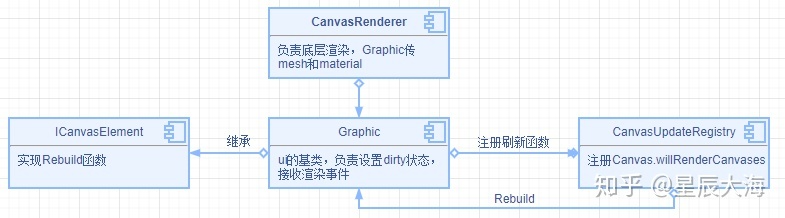
UGUI的渲染过程和NGUI类似,UI组件的基类是Graphic,Graphic保存了当前元素的mesh和material,Graphic实现接口ICanvasElement主要用于重绘,CanvasRenderer用于传递这些数据给Canvas,CanvasRenderer并不是直接渲染,而是交给Canvas,Canvas还要做合批等操作,Canvas会对节点下的Graphic进行合批,所以一个Graphic设置dirty,整个canvas都需要重新计算合批。
34. UGUI屏幕适配如何做?
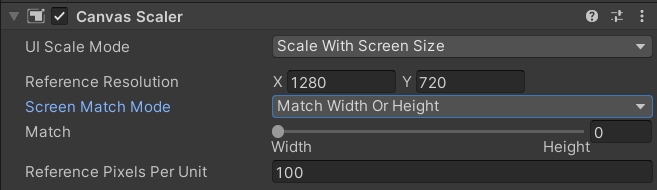
Canvas Scale中设置默认的分辨率,按照宽或者高来做适配。
背景图适配做法
(1)如果按照宽度比例缩放,背景图的高度需要上下预留出一些空间。按照高度比例缩放类似。
(2)可以在背景图上加脚本,根据屏幕分辨率来设置这个背景图的不同比例。
UI元素适配方法
(1)调整锚点
(2)根节点上挂脚本,根据屏幕分辨率来设置元素的缩放。如检测到是Ipad屏幕,就可以缩小Scale。
区域适配,如滚动列表,RectTransform中使用stretch锚边,根据父物体的大小变化。
35. Unity中三角面正面,背面是如何渲染的?
三角面正面是顶点顺时针,背面是顶点逆时针,如
a
b c
a,b,c为逆时针,渲染背面。a,c,b为顺时针,渲染正面。
36. 如何让粒子在界面上正确显示?
方法1:修改ParticleSystem的Order in Layer参数,如果特效粒子勾选Render属性,这个特效就会有Order in Layer的概念,就会跟Canvas的order进行混合影响显示层级。
方法2:在Prefab根节点上挂Sorting Group,然后根据情况设置Order in Layer。
方法3:每个特效挂上脚本,脚本中的类继承MaskableGraphic重写OnPopulateMesh函数,该类是模拟Particle,将其转换成UGUI的Graphic,融入到UGUI体系,所以可以将其当做lmage一样控制。
37. mesh与shareMesh,material与shareMaterial,materials和sharedMaterials的区别?
mesh和material都是实例型的变量,对mesh和material执行任何操作,都是额外复制一份后再重新赋值,即使只是get操作,也同样会执行复制操作。也就是说,对mesh和material进行操作后,就会变成另外一个实例,虽然看上去一样,但其实已是不同的实例了。
sharedMesh和sharedMaterial与前面两个变量不同,它们是共享型的。多个3D模型可以共用同一个指定的sharedMesh和sharedMaterial,当你修改sharedMesh或sharedMaterial里面的参数时,指向同一个sharedMesh和sharedMaterial的多个模型就会同时改变效果。也就是说,sharedMesh和sharedMaterial发生改变后,所有使用sharedMesh和sharedMaterial资源的3D模型都会表现出相同的效果。
materials与sharedMaterials类似,只不过变成了数组形式。materials和sharedMaterials可以针对不同的子网格,material和sharedMaterial只针对主网格。也就是说,material和sharedMaterial等于materials[0]和sharedMaterials[0]。
38. 欧拉角,四元数,旋转矩阵优缺点
欧拉角
优点:直观,容易理解。3个数据可以节省内存空间
缺点:万向节死锁问题,必须严格按照顺序进行旋转(顺序不同结果就不同)
应用:只涉及到一个方向的简单旋转可以用欧拉角
四元数
优点:没有万向节死锁。存储空间小,计算效率高。平滑插值,
缺点:单个四元数不能表示在任何方向上超过180度的旋转。四元数的数字表示不直观。
应用:物体旋转的过渡
矩阵旋转:
优点:旋转轴可以是任意向量,没有万向节死锁
缺点:元素多,存储空间大
39. 在开发过程中哪些地方比较容易造成内存泄漏问题?如何避免?
造成内存泄漏的可能原因:
1.你的对象仍被引用但实际上却未被使用。 由于它们被引用,因此GC将不会收集它们,这样它们将永久保存并占用内存。
2.当你以某种方式分配非托管内存(没有垃圾回收)并且不释放它们。
3.过度使用委托会导致内存泄漏,多播委托会引用多个方法,而当这个方法是实例方法(非静态方法)的话,也就是说这个方法隶属于一个对象。一旦我们使用委托引用这个方法的话,那么这个对象就必须存在于内存当中。即便没有其他地方引用这个对象,因为委托的关系,这个对象也不能释放。因为一旦释放,委托就不再能够间接调用到这个方法了,所以没有正确删除委托的方法会导致内存泄漏。
4.静态对象没有及时释放。
如何避免:
1) 在架构上,多添加析构的abstract接口,提醒团队成员,要注意清理自己产生的“垃圾”。
2) 严格控制static的使用,非必要的地方禁止使用static。
3) 强化生命周期的概念,无论是代码对象还是资源,都有它存在的生命周期,在生命周期结束后就要被释放。如果可能,需要在功能设计文档中对生命周期加以描述。
40. 如果不想new,但又想获取对象实例,有哪几种方法?
1.使用反射。
Assembly assembly = Assembly.Load(“xxx”);
Type type = assembly.GetType(“yyy”);
return Activator.CreateInstance(type);
2.使用原型模式克隆。
3.反序列化
41. 点乘,叉乘和归一化的意义
- 点乘主要用于计算角度和投影
θ是向量A和向量B的夹角。
计算两个向量的夹角:cosθ = A·B /(|A||B|)
计算A向量在B向量上的投影:|A| * cosθ = A·B / |B| - 叉乘用于计算旋转的轴,判断向量的相对位置
计算旋转的轴:比如我面向前方,我要向右转,这时朝前的这个向量和朝右的这个向量叉乘得到了我需要的旋转轴。注意数学上叉乘用右手法则,Unity当中叉乘用左手法则。
判断相对位置:向量A和向量B做叉乘,如果结果向上,说明B向量在A向量的右边,否则B向量在A向量的左边。
|a X b| = |a||b|sinθ 几何意义:两个向量构成的平行四边形的面积。 - 归一化:归一化就是要把需要处理的数据经过处理后限制在你需要的一定范围内,用在只关系方向,不关心大小的时候。
42. 假设一个回合制战斗,战斗过程均由客户端计算,请问使用什么方式使得服务器可以验证此场战斗的数据是合法的?
1.最简单的方式,根据公式计算当前队伍的伤害上限,只要低于此伤害上限就认为战斗数据合法。
2.可以将整个战斗过程上传到服务器进行验算。数值计算涉及到随机结果的情况下,客户端、服务器使用同一随机种子及随机算法,保证数值结果的正确合法性。
43. 协程
IEnumerator Test()
{
yield return null; //下一帧再执行后续代码,执行时机是下一帧Update后
//如果yield带有参数返回,则会产生不必要的内存垃圾
//返回0,引发了装箱操作,一般还是用null。
yield return 0; //(任意数字)下一帧再执行后续代码
yield break; //直接结束该协程的后续操作
yield return asyncOperation;//等异步操作结束后再执行后续代码
yield return StartCoroution(/*某个协程*/);//等待某个协程执行完毕后再执行后续代码
yield return WWW();//等待www操作完成后再执行后续代码
yield return new WaitForEndOfFrame();//等下一帧LateUpdate后
yield return new WaitForSeconds(0.3f);//受到Time.Scale的影响
yield return new WaitForSecondsRealtime(0.3f);//不受到Time.Scale的影响
yield return new WaitForFixedUpdate();//等待下一次FixedUpdate开始时再执行后续代码
yield return new WaitUntil();//将协同执行直到当输入的参数(或者委托)为true的时候
yield return new WaitWhile();//将协同执行直到当输入的参数(或者委托)为false的时候
//总结
yield return xxxx; //终止本次协程,直到一个条件成立
}
什么时候用协程:
(1)等待下载完成
(2)异步加载资源
协程的原理:
协程分为两部分,协程与协程调度器:协程仅仅是一个能够中间暂停返回的函数,而协程调度是在MonoBehaviour的生命周期中实现的。 准确的说,Unity只实现了协程调度部分,而协程本身其实就是用了C#原生的 “迭代器方法”。MonoBehaviour生命周期的部分,有很多yield阶段,在这些阶段中,Unity会检查MonoBehaviour中是否挂载了可以被唤醒的协程,如果有则唤醒它。参考 Unity协程的原理与应用
调用协程时,会生成一个IEnumerator对象,它是C#的迭代器函数,这个对象可以看作是函数代码的容器,通过yield关键字将协程中的代码分割放入这个容器中。运行时碰到yield return会将函数暂时挂起,下一帧判断yield return后面的条件是否满足,如果满足则继续执行。协程不是多线程,协程还是运行主线程上,它是用同步的方式实现异步的效果。
IEnumerator Test()
{
Debug.Log("HelloWor1d");
yield return 1;
for (int i = 1; i <= 3; i++)
{
Debug.Log(" i = " + i);
yield return null;
}
Debug.Log("开始 MyWaitForSeconds");
yield return new MyWaitForSeconds(5f);
Debug.Log("结束");
}
/*
IEnumerator可以理解为一个函数对象的容器,[函数代码1,函数代码2,函数代码3,函数代4。。。]
yield关键字就是帮你抽出函数代码,生成一个函数,放到IEnumerator容器里面。
调用Test时会创建一个IEnumerator对象
IEnumerator对象
[
{
Debug.Log("HelloWor1d");
return 1;
},
{
int i = 1;
Debug.Log(" i = " + i);
},
{
int i = 2;
Debug.Log(" i = " + i);
},
{
int i = 3;
Debug.Log(" i = " + i);
},
]
IEnumerator会依次执行容器中的每个函数,
*/
void Start()
{
IEnumerator cor = this.Test();
// MoveNext执行完当前的函数,移动到下一个,到最后MoveNext返回一个false
// 这样写,cor会在一帧内执行完
while (cor.MoveNext())
{
//Current接收当前函数的返回值
Debug.Log(cor.Current);
}
MyStartCoroutine(Test());
}
IEnumerator nowEnum = null;
/// <summary>
/// 模拟StartCoroutine()的实现
/// 就是将IEnumerator容器里的函数,每隔一帧触发一次
/// </summary>
void MyStartCoroutine(IEnumerator e)
{
this.nowEnum = e;
}
void LateUpdate()
{
if (this.nowEnum != null)
{
if(this.nowEnum.Current is MyWaitForSeconds)
{
MyWaitForSeconds myWaitFor = this.nowEnum.Current as MyWaitForSeconds;
myWaitFor.Update();
if (!myWaitFor.IsOver())
return;
}
// 时间到了,继续执行
if (!this.nowEnum.MoveNext())
{
this.nowEnum = null;
}
}
}
/// <summary>
/// 模拟WaitForSeconds类
/// 模拟协程时间等待
/// </summary>
class MyWaitForSeconds
{
public float total;//总时间
public float now;//当前时间
public MyWaitForSeconds(float waitTime)
{
this.total = waitTime;
this.now = 0;
}
public void Update()
{
this.now += Time.deltaTime;
}
/// <summary>
/// 是否结束
/// </summary>
public bool IsOver()
{
return this.now >= this.total;
}
}
协程触发的生命周期,不同的 yield 的方法处于生命周期的不同位置
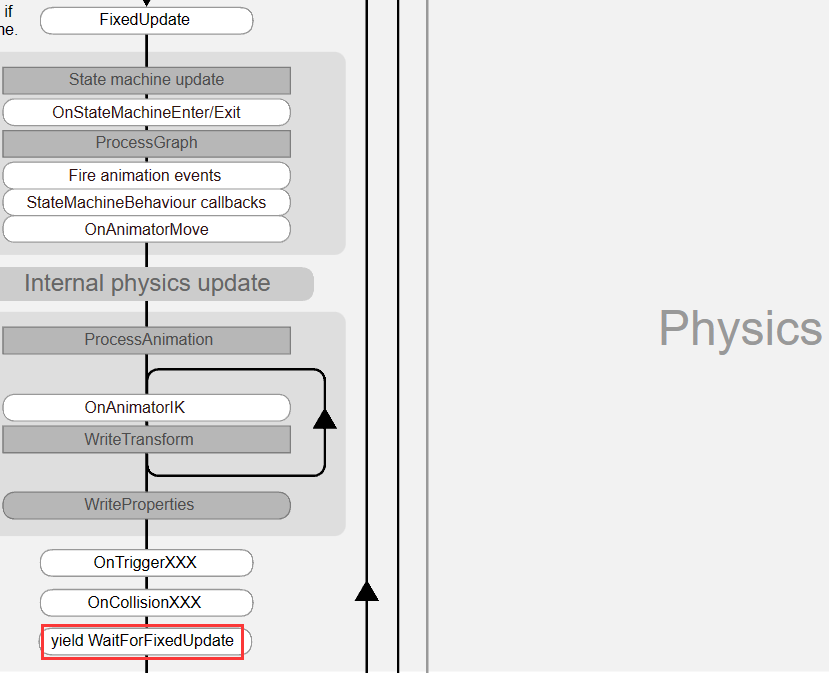
yield WaitForFixedUpdate 处于物理阶段的最后

yield WaitForEndOfFrame 一帧的最后
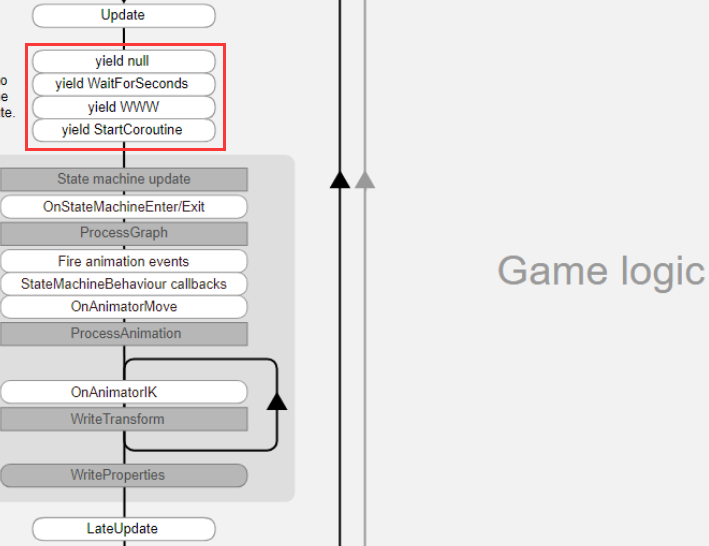
其他大部分都处在 Update 和 LateUpdate 之间
44. 什么时候用协程,什么时候用线程?
协程:实现一个任务在不同时间内分段执行,使用它来控制运动,以及对象的行为,或者实现延迟操作
线程:(1) 大量耗时的数据计算
(2) 网络请求
(3) 复杂密集的I/O操作
Unity支持多线程,有main Thread和renderer thread,但是组件和调用mono相关的接口只能运行在主线程上。
45. 解决哈希冲突的方法
1.开放定址法:冲突位置向后移动一个单位,直到不发生冲突。
2.平方探测法:按照+1,-1,+2²,-2²,+3²…顺序查找
3.再哈希法:对于冲突的哈希值再次进行哈希处理,直至没有哈希冲突。
4.拉链法
46. 游戏中常用的设计模式
1.简单工厂模式:把对象的创建封装到类中,根据不同的参数生成不同的对象,如根据建筑的类型生成不同的建筑。
2.观察者模式:C#的event。
3.状态模式:使用有限状态机,将行为抽象成一个个状态,通过状态管理器控制状态之间的转换,同一时间只能处于某一个状态。
4.组合模式:将一些功能抽象成一个个组件,对象创建时根据需求添加不同的组件,增强代码复用性。
5.单例模式:全局为一,游戏中的管理器。
6.外观模式:对多个子系统进行封装,通过外观类来获取这些系统,减少系统的互相依赖,减少和其他系统的耦合。
7.策略模式:定义了一组同类型的算法,在不同的类中封装起来,每种算法可以根据当前场景相互替换,从而使算法的变化独立于使用它们的客户端。
8.命令模式:将一个命令封装为一个对象,从而实现解耦,改变命令对象,撤销功能
9.原型模式:在不需要创建新对象的情况下复制现有对象,并根据需要修改一些属性
47. 热更新方案
1.整包:将完整更新资源放在Application.StreamAssets目录下,首次进入游戏将资源释放到Application.persistentDataPath下。
优点:首次更新少。缺点:下载时间长,首次安装时间久。
2.分包:少部分资源放在包里,其他资源存放在服务器上,进入游戏后将资源下载到Application.persistentDataPath目录下。
优点:安装包小,安装时间短,下载快。缺点:首次更新下载时间久。
48. MVC
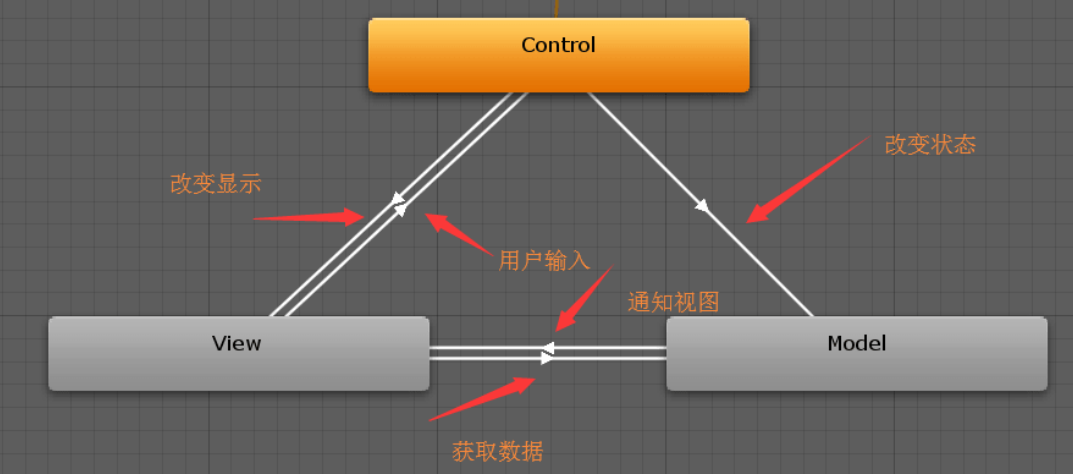
view初始化时从model中获取数据,并监听model数据变化,用户操作view触发事件,发送给control,control处理后更新model数据,model再通知view刷新。
数据部分分为配置表数据和网络数据,配置表数据相对固定,在界面中通过事件管理器监听网络数据的变化。
界面会监听对应数据的变化,比如背包界面监听背包道具的变化。view和model的关系只是查询,并不会改变数据,数据的变化只能来自于服务器的协议驱动。
49. 资源管理器需要注意哪些?
开发模式:编辑器下使用AssetDatabase.LoadAssetAtPath从StreammingAsset下加载资源。
发布模式:从ab包中加载资源。
加载的资源需要引用计数,当引用计数为0时,如果是GameObject就销毁或者回收到对象池,如果是ab包就unload;
50. 接口与抽象类区别?
接口是对动作的抽象,抽象类是对同一类事物的抽象。抽象类表示这个对象是什么。接口表示这个对象能做什么。
继承接口的类必须实现它的所有方法,可以用接口来定义一些行为。两者都不能实例化。例如把 “门” 定义为一个抽象类,根据具体情况实例化为铁门,木门等,门有打开的行为,可以把打开这个行为定义为接口,C#的类不能多继承,但接口可以多继承。抽象基类可以定义字段、属性、方法实现。接口只能定义属性、索引器、事件、和方法声明,不能包含字段。一个抽象类可以同时包含抽象方法和非抽象方法。
51. AssetBundle.Unload()参数为true和false有什么区别?
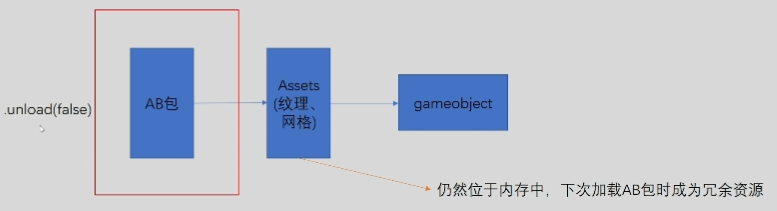
Unload(false)表示只卸载ab包
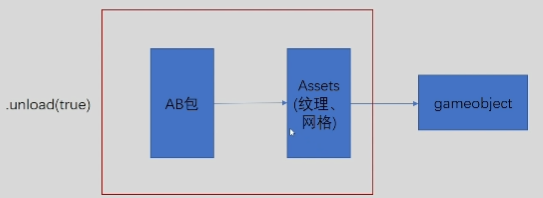
Unload(true)表示把ab包和加载的资源都卸载掉
52. 密封类,密封方法作用
密封类(sealed)是指该类不可以被继承,密封方法,则派生类不能重写该方法的实现。
53. 常用的hash算法
1.加法Hash,就是把输入元素一个一个的加起来构成最后的结果
2.位运算Hash,这类型Hash函数通过利用各种位运算(常见的是移位和异或)来充分的混合输入元素
3.乘法Hash,这种类型的Hash函数利用了乘法的不相关性
4.混合Hash,混合以上方式
54. 逆矩阵的作用
当我们将一个向量经过旋转或其他的变换后,如果想撤销这个变换,就乘以变换矩阵的逆矩阵。
55. Rigidbody和CharacterController区别
Rigidbody是用来模拟真实物理效果的,模拟物体相互碰撞后的相互作用。
CharacterController可以说是受限的Rigidbody,除了重力效果之外,它是不能受物理力的。本身自带了一个胶囊碰撞体,可以用来产生碰撞。只有调用Move或SimpleMove,对象才能移动。
56. Unity生命周期
- 初始化及编辑器:Awake –>OnEnable –> Reset –> Start
Awake:对象首次实例化后,仅会被调用一次。无论是否处于激活状态都会被调用
OnEnable: 对象每次被激活后调用
Rest:当Scripts第一次绑定到物体上或者点击Reset按钮的时候会触发,且只在Editor的模式下触发,游戏打包的时候并不会触发
Start:仅会在第一次启用实例后的,第一帧更新前调用 - 物理循环:FixedUpdate –> OnTriggerXXX -> OnCollisionXXX
FixedUpdate(物理Physics):根据设置的固定时间更新,执行物理计算和更新 - 输入事件:OnMouseXXX
- 游戏逻辑:Update –> 大部分协程 -> LateUpdate
Update:每帧调用,执行业务逻辑
LateUpdate:每一帧在Update调用完毕后,调用LateUpdate,常用于跟随第三人称摄像机 - 渲染:
OnPreCull 方法:在摄像机剔除场景之前调用。剔除取决于物体在摄像机中是否可见。在进行剔除之前调用 OnPreCull
OnBecameVisible 和 OnBecameInvisible 方法:当物体在任何摄像机中可见或不可见时调用
OnWillRenderObject 方法:如果物体可见,则为每个摄像机调用一次
OnPreRender 方法:在摄像机开始渲染场景之前调用
OnRenderObject 方法:所有固定场景渲染之后调用。此时,可以使用 GL 类或 Graphics.DrawMeshNow 来绘制自定义几何形状
OnPostRender 方法:在摄像机完成场景渲染后调用
OnRenderImage 方法:在场景渲染完成后调用,用来对屏幕的图像进行处理
OnDrawGizmos 方法:用于在场景视图中绘制辅助图标以实现可视化
OnGUI 方法:每帧调用,多次用来响应 GUI 事件。布局和重绘事件先被执行,然后为每一次的输入事件执行布局和键盘、鼠标事件 - 帧结束:yield WaitForEndOfFrame
- 退出/销毁:OnApplicationQuit –> OnDisable –> OnDestroy
OnApplicationQuit:当应用程序退出时,调用此函数
OnDisable:对象每次被设置为非激活状态时,调用此函数
OnDestroy:对象存在的最后一帧完成所有帧更新之后,调用此函数
57. 静态类和单例类的区别
1.静态类仅包含静态成员,无法实例化。单例类可以同时具有静态和非静态对象,只是一个实例。
2.静态类不能有实例构造函数,单例类的构造函数私有。
3.静态类是在应用程序第一次加载进行初始化,而单例加载可以懒加载也可以由CLR自动加载。
4.静态类不能实现接口,单例可以。
58. new关键字用法
1.用于创建对象和调用构造函数。
2.在用作修饰符时,new 关键字可以显式隐藏从基类继承的成员(变量、属性、函数)。
3.泛型约束条件:无参构造函数(仅无参构造函数,有参不行)。
public class BaseClass
{
public string name = "BaseClass";
}
public class SubClass : BaseClass
{
//new 关键字显式隐藏从基类继承的成员(变量、属性、函数)
new public string name = "SubClass";
}
//---------------------------------------------------------------------
public class Employee
{
private string name;
private int id;
public Employee()
{
name = "Temp";
id = 0;
}
}
//泛型约束条件:无参构造函数
class ItemFactory<T> where T : new()
{
public T GetNewItem()
{
return new T();
}
}
public class Test : MonoBehaviour
{
private void Start()
{
//此处编译器会检查Employee是否具有公有的无参构造函数。
ItemFactory<Employee> EmployeeFactory = new ItemFactory<Employee>();
}
}
59. 快排时间复杂度,空间复杂度
最好和平均情况下是nlogn,最坏情况下是n^2,空间复杂度是logn
每一趟比较和交换是O(n)的操作,每一轮折半,都能将一个元素归位,一个长度为n的序列能折半log2n,即logn次。
递归过程中,每分一层都有一些临时变量,总共分了logn层,所有空间复杂度为logn
60. 反射
反射是在运行期间,动态获取类、对象、方法、对象数据等的一种重要手段。
每个类都有对应的Type对象,Type是一种类型描述,描述了这个类型有哪些数据组成,同时描述一些成员函数。
类的实例: new类(),创建了具体的内存对象,这块内存是所有数据成员的集合。
类的成员函数会到哪里去呢?
类的成员函数属于代码指令,编译完成以后,会变成代码指令,全局只有一份,所有类的实例共用一份代码指令,存入到代码段。
编译器–代码—> .exe执行文件—> 运行这个文件的时候,会把里面的所有代码加载到内存的代码段。
编译完成了以后,就可以根据编译信息,来为每个类来生成一个全局的类型描述对象的数据存起来,写入到
.exe,这样就可以使用了Type的方式来获得一个类的描述。
编译器会知道每个数据的相对于对象实例内存块的偏移。
编译器也会知道,每个类的成员函数在代码段偏移位置。–>运行的时候,就可以让指令直接跳转到这里。
//描述信息类似这样
class FiledData
{
string filedName; //字段名
int type; //类型
int filedSize; //这个字段的内存大小;
int offset; //在内存对象中的内存偏移
}
class MethodData
{
string methName; //方法名
int type; //静态的还是,普通的;
int offset; //函数代码指令的地址;
}
class Type
{
int memSize; //当前类的实例的内存大小;
List<FiledData> datas; //当前这个类的成员变量;
List <MethodData> funcs; //当前这个类的所有的成员函数;
}
反射的作用:
// (1)System.Type.GetType("类型名"),
// typeof(T)根据类型或类型名字来获取我们的类型描述对象实例。
Type t = Type.GetType("类型名");
// (2)实例化一个对象
// 利用描述对象实例,构建一个对象出来;
var instance = Activator.CreateInstance(t);
// (3)Type里面存放了每个数据成员的偏移和大小,
// 用这两个数据就能从对象的内存里面读取/设置成员的数据
// 获取所有的成员变量的描述信息
FieldInfo[] fields = t.GetFields();
// 获取单个成员变量的描述信息
FieldInfo ageInfo = t.GetField("age");
// 设置实例成员变量的值
ageInfo.SetValue(instance, 4) ;
// (4)每个Type里面都存放了我们成员函数地址,通过这个调用方法
MethodInfo m = t.GetMethod("方法名");
object[] parameters = new object[3];
m.Invoke(t, parameters);
61. 如何判断客户端与服务器是否保持连接
使用心跳包,每隔一段时间,客户端向服务器发送一条指定的心跳协议。
62. 什么是黏包
收到的数据包不完整,这种现象称之为黏包。
出现黏包的原因:当发送端缓冲区的长度大于网卡的MTU(网络上传送的最大数据包)时,tcp会将这次发送的数据拆成几个数据包发送出去。
tcp的协议数据不会丢,没有收完包,下次接收,会继续上次继续接收,己端总是在收到ack时才会清除缓冲区内容。数据是可靠的,但是会粘包。
解决办法:
- 首先将所有接收到的字节流,塞入缓冲池
- 根据包头信息,判断是否能获取当前完整协议包,若能获取完整,则根据协议头提取数据。此时若有缓冲池还有其他协议数据,若能继续提取就继续,不能则跳过,继续等待接收新字节流,塞入缓冲池。
- 循环1和2
63. A星寻路
f(寻路消耗) = g(离起点的距离)+ h(离终点的距离)
起点添加到关闭列表,将起点周围的点添加到开放列表中,开放列表中选出一个消耗最小的点放入关闭列表中,如果这个点是终点则路径找完了,否则这个点作为新起点再循环找。每次从新起点找周围的点时,如果周围的点已经在开放列表或者关闭列表中则忽略。除了起点每个格子都会存其父对象,当找到终点后回溯父对象的格子直到起点,连成路径。
优化:预存路径,地图分块,优化开放列表的排序,最小堆数据结构非常适合A星寻路的open排序。
64. 有限状态机和行为树区别
有限状态机将游戏AI行为分为一个一个的状态,状态与状态之间通过状态管理器切换,某一个时刻只能处于其中一种状态
状态机的问题:随着状态的增多,需要考虑任意两个状态之间是否可以切换,逻辑复杂,复用性不好,如果设计一个全新的敌人,又需要重写一套状态节点和切换逻辑
行为树把行为抽象成一棵树,它是一种“轮询式机制”,即每次更新都会遍历树,判定逻辑是否成立,是否该继续往下执行。行为树从上到下,从左到右遍历节点,行为树的每个节点会有返回一个执行状态,一种设置方式是 {Running,Success,Failure } 三种状态,Running代表正在运行,Success,Failure对应执行成功和失败
综合来看,行为树更适合描述角色在复杂环境下的行为。状态机更适用于处理简单的状态转换,并且适合处理基于输入驱动的场景
65. Const和ReadOnly的区别?
- 初始化位置不同。const必须在声明的同时赋值;readonly即可以在声明处赋值,也可以在静态构造方法(必须是静态构造方法,普通构造方法不行)里赋值。
- 修饰对象不同。const即可以修饰类的字段,也可以修饰局部变量;readonly只能修饰类的字段
- const是编译时常量,在编译时确定该值;readonly是运行时常量,在运行时确定该值。
- const默认是静态的;而readonly如果设置成静态需要显示声明
- 修饰引用类型时不同,const只能修饰string或值为null的其他引用类型;readonly可以是任何类型。
66. ab包中的资源冗余怎么处理?
如果两个ab包A和B中的一些资源都依赖了资源C,那么C就会同时被打进A和B中,造成资源的冗余
资源C又可以分为两种类型,一种是我们自己创建的资源;另一种是Unity内置的资源,例如内置的Shader,Default-Material和UGUI一些组件如Image用的一些纹理资源等等
对于我们自己创建的资源,解决方案就是将这些被多个ab包依赖的资源打包到一个公共ab包中,处理过程如下:
- 使用 EditorUtility.CollectDependencies() 得到ab依赖的所有资源的路径
- 统计资源被所有ab引用的次数,将被多个ab引用的资源打包为公共ab包
对于内置资源:
将内置资源提取或者下载到本地,打成ab包,检测其他ab包是否引用内置资源,如果引用了内置资源,则修改引用关系
参考
67. 场景中有个物体(坐标未知),摄像机可以看到这个物体,已知摄像机的位置,怎么得到物体的坐标?
射线检测
68. 什么是扩展方法?
扩展方法使你能够向现有类型“添加”方法,无需修改类型
public static void SetText(this TextMeshProUGUI tmpUGUI)
{
tmpUGUI.text = "Text";
}
扩展方法必须满足的
条件1:必须要静态类中的静态方法
条件2:第一个参数的类型是要扩展的类型,并且需要添加this关键字以标识其为扩展方法
69. int?和int有什么区别?
int?为可空类型,默认值可以是null
int默认值是0
int?是通过int装箱为引用类型实现
70. using关键字的作用
1.引用命名空间,也可using 别名
2.释放资源,实现了IDisposiable的类在using中创建,using结束后会自定调用该对象的Dispose方法,释放资源。
71. 模型动画有哪些?
- 骨骼蒙皮动画
特点:文件格式复杂,文件体积小,耗CPU,需要大量矩阵运算。 - GPU动画
特点:体积小,运算快,动画相对简单,缺乏物理交互,因为顶点的移动是GPU处理的,CPU端的物理引擎认为点并没有移动。
骨骼本质是一个4*4的变换矩阵,可以将变换矩阵的数据当作颜色存储在贴图上,GPU读取贴图上的信息还原为变换矩阵。
72. FixedUpdate原理
Unity的主要逻辑是单线程的,Update和FixedUpdate都是在主线程上调用的,如果某一帧的Update卡了很长时间,下一帧的FixedUpdate肯定会受影响,那么是怎么保证FixUpdate的更新频率?
FixedUpdate在累计的时间大于一次物理更新时才会调用一次,当经过的时间大于多个物理更新时间就会按更新间隔分成多次调用。比如物理更新间隔设置的是15毫秒,但运行时,实际的帧间隔是30毫秒,30毫秒大于两次物理更新时间,所以fixedupdate会调用两次,update只调用一次。
73. 重写与隐藏
//重写
public class OverrideTest : MonoBehaviour
{
void Start()
{
B b = new B();
A a = b;
a.printStr(); //"重写的方法"
b.printStr(); //"重写的方法"
//只要对象是子类构造的,就会调用子类的重写方法
}
}
class A
{
public virtual void printStr()
{
Debug.Log("父类的方法");
}
}
class B : A
{
public override void printStr()
{
Debug.Log("重写的方法");
}
}
//隐藏
public class HideTest : MonoBehaviour
{
void Start()
{
//因为是用Father声明的对象,所有是调用Father的方法
//用子类声明时,才会调用隐藏方法
Father father = new Son();
father.Fun(); //"父类的方法"
}
}
abstract class Father
{
public virtual void Fun()
{
Debug.Log("父类的方法");
}
}
class Son : Father
{
//隐藏方法
public new void Fun()
{
Debug.Log("隐藏的方法");
}
}
74. 特性
特性是用来标记在某个元素上,默认是以Attribute结尾的一个类
可以标记类、类内部的所有元素(字段,方法),默认不能重复标记
特性只能通过反射调用
特性的参数是编译时决定的,定死的,不能给不确定的值
[Serializable]
class Person
{
public string Name {
get; set; }
public int Age {
get; set; }
public DateTime Birthday {
get; set; }
}
Serializable是C#中的一个系统特性,它用于标记一个类是可序列化的,这样就可以将类的实例转换成二进制格式或者JSON格式的数据,对于网络传输或者数据存储是非常有用的
[AttributeUsage(AttributeTargets.Class)]
class MyAttribute : Attribute
{
public string Name {
get; set; }
public MyAttribute(string name)
{
Name = name;
}
}
自己定义特性,定义一个类,直接或者间接的继承Attribute父类,约定俗成以Attribute结尾的,标记的时候可以省略Attribute。这里定义了一个名为MyAttribute的特性,它继承自系统特性类Attribute,我们可以使用它来标记其他的元素,例如类、属性、字段等等。然后,在运行时我们可以使用反射来检查自定义的特性是否存在,如果存在则执行自定义的逻辑
75. 纹理加载进内存以后占用内存如何计算?
纹理内存大小(字节) = 纹理宽度 x 纹理高度 x 像素字节
像素字节 = 像素通道数(R/G/B/A) x 通道大小(1字节/半字节)
举例:比如一个1024 * 1204的RGBA 32bit的纹理占用多大内存?
占用总位数 :allbits = 1024 * 1024 * (4*8bit)
占用总字节数:allbytes = allbits / 8bit
76. 刚体中的Is Kinematic
勾选Is Kinematic时将会忽略外部对此刚体的作用(重力以及addforce或者其他物体对此物体的冲撞),但是此刚体仍然主动对外部非Kinematic刚体产生物理作用
77. 渲染顺序
PlanceDistance越大越先渲染(canvas距离摄像机的距离)
Sorting layer越小越先渲染
Order in Layer越小越先渲染
默认的UI/Default,渲染队列是Transparent,此队列针对半透明物体的。
去材质调节面板查看,渲染队列(Render Queue)大于3000的都是半透明物体。
Unity提前定义的5个渲染队列如下
| 名称 | 队列索引号 | 描述 |
|---|---|---|
| Background | 1000 | 在其他任何渲染队列之前被渲染,正如名称一样,一般用来渲染背景物体 |
| Geometry | 2000 | 默认的渲染队列,不透明物体使用此渲染队列 |
| AplhaTest | 2450 | 需要进行透明度测试的物体使用此物体,从Geometry抽离出来,原因是在所有不透明物体渲染完成后再渲染它们更高效 |
| Transparent | 3000 | 此队列的物体会在前面三个渲染队列的物体渲染后,按照物体从后往前的顺序进行渲染。任何使用了透明度混合的物体都应该使用这个渲染队列 |
78. Material和Shader的区别
Material是模型的材质,包含贴图,shader等。 Shader是Material的一部分,本质是一小段程序,它负责将输入的Mesh(网格)以指定的方式和输入的贴图或者颜色等组合作用,然后输出。
79. 材质、贴图、纹理的关系
材质 Material 包含贴图 Map,贴图包含纹理 Texture。
纹理是最基本的数据输入单位,游戏领域基本上都用的是位图。此外还有程序化生成的纹理 Procedural Texture。
贴图的英语 Map 其实包含了另一层含义就是“映射”。其功能就是把纹理通过 UV 坐标映射到3D 物体表面。贴图包含了除了纹理以外其他很多信息,比方说 UV 坐标、贴图输入输出控制等等。
材质是一个数据集,主要功能就是给渲染器提供数据和光照算法。贴图就是其中数据的一部分,根据用途不同,贴图也会被分成不同的类型,比方说 Diffuse Map,Specular Map,Normal Map 和 Gloss Map 等等。另外一个重要部分就是光照模型 Shader ,用以实现不同的渲染效果。
80. LineRenderer的实现原理是什么?
Line Renderer组件是一种用于在3D空间中绘制线的工具。它使用一个点的数组来确定线条的形状和位置,然后在每个点之间插值生成顶点和三角形
81. 多个mono代码,如何指定它们的运行顺序
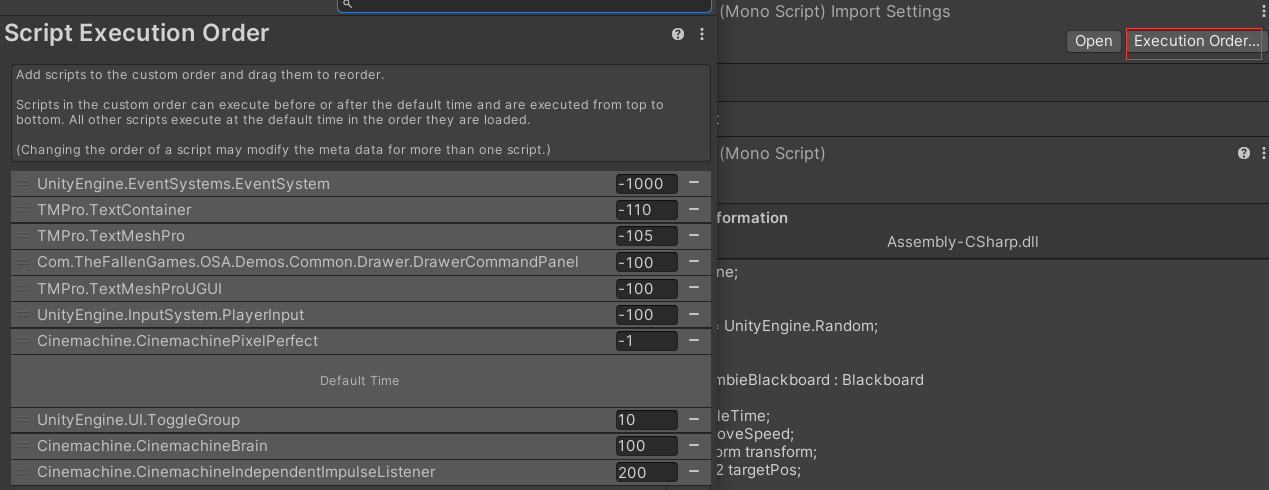
点击脚本上的Execution Order打开Project Settings中的Script Execution Order,后面数字越小的越先执行,比如这里的UnityEngine.UI.ToggleGroup比Cinemachine.CinemachineBrain先执行
82. 热更新的大致流程
- 首先,需要将资源或代码打包成AssetBundle文件,生成一个热更配置文件记录版本号及所有资源信息(地址,MD5,大小等),并上传到服务器
- 然后,应用程序启动时,会从服务器下载这个热更配置文件,与本地的文件进行对比,如果服务器版本号更高,则需要进行热更新,版本号一致也需要检测文件的大小和MD5,保证资源没有丢失或修改
- 如果有需要更新的内容,会遍历本地资源计算MD5,如果与服务器不一致,则下载相应的AssetBundle文件,并替换现有的资源,下载完成后会进行文件校验,对比本地资源和服务器资源的大小和MD5,不一致则重新下载
- 热更新完成后,客户端会把最新的热更配置文件存储在本地,方便下一次更新检测
83. 垂直同步对游戏帧率有什么影响
垂直同步是一种调整显示器和GPU之间帧率同步的技术。在启用垂直同步时,GPU将帧率锁定为与显示器刷新率相同的数值。例如,如果你的显示器刷新率是60Hz,那么GPU会将帧率锁定为60fps
启用垂直同步有以下影响:
- 减少画面撕裂
- 如果游戏的帧率无法达到显示器的刷新率,那么垂直同步将会导致帧率下降。这是因为在垂直同步的情况下,每当显示器完成一次刷新,图形卡必须等待下一次刷新才能开始呈现下一个帧,因此在某些情况下,帧率将被降低到不到60帧以下
84. 骨骼动画原理
在mesh中添加骨骼,骨骼的两端为关节,骨骼只能以关节为轴心旋转,把mesh上的点绑定到骨骼上,即刷权重,这样mesh就能够随着骨骼的动作而变形。骨骼动画的本质,便是在不同的时间点为某节骨骼定义了特定的位置、缩放、旋转。动画的运作便是根据两个时间点之间的骨骼数据做数值变化,这种行为称之为补间(Tweens),同理骨骼动画也就是一种补间动画
85. 骨骼包含哪些信息
通常包含以下信息:
骨骼名称:每个骨骼都有一个唯一的名称,用于标识该骨骼和在程序中引用它。
骨骼的旋转、位移和缩放:这些变换信息指示了骨骼在动画中的变化,如旋转方向、位置和大小。
骨骼的层次结构:骨骼可以是单个骨骼,也可以是层次结构中的父骨骼或子骨骼。这些关系确定了骨骼在空间中的位置和姿态。
骨骼的绑定信息:这些信息指示了哪些网格顶点与该骨骼相关联,以及它们的权重。这些权重指示了骨骼对网格的影响程度,决定了网格的变形方式。
86. 动画融合是怎么实现的
混合树(Blend Tree)是一种将多个动画片段以位置、速度、角速度为依据经行线性混合的方式,可以将几个动画文件很好的融合在一起
还可以通过动画层(Layer)的方式实现,每一个动画层只对动画主体的部分进行控制,其他部分通过遮罩屏蔽
87. 打ab包时,LZMA和LZ4这两种压缩方法有什么区别?
LZMA压缩的ab包较小,它是流式压缩,只支持顺序读取,获取ab包中的某个资源需要完全解压后再加载,加载时间较慢
LZ4压缩的ab包较大,它是块压缩,支持随机读取,加载时间较快
88. 修改Time.timeScale会影响什么?
timeScale改变时,会对以下值产生影响:time、deltaTime、fixedTime以及fixedUnscaledDeltaTime
timeScale会影响 FixedUpdate 的执行速度,当timeScale为0时,FixedUpdate完全停止。但不会影响Update、LateUpdate的执行速度,如果Update、LateUpdate中使用了deltaTime,则也会影响这部分逻辑的执行
timeScale 不会影响 Coroutine本身的执行速度。当timeScale为0时,如果Coroutine中yield了某个WaitForSeconds或者WaitForFixedUpdate,那么该Coroutine会在此处停下。如果想要等待一个不受timeScale影响的时间,请用WaitForSecondsRealtime
89. 什么情况下会用到Animator Override Controller?
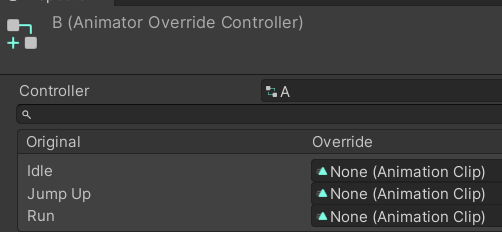
如果A,B两个角色使用的Animator Controller结构完全相同,只是用到Animation Clip不一样,这时可以使用Animator Override Controller。实现A的状态机后,B使用Animator Override Controller覆盖掉A中的Animation Clip
90. 内存碎片
内存碎片是指内存中存在的一些不连续的小块空闲内存,由于它们不连续,所以无法被利用。
内存碎片分为外碎片和内碎片:
外碎片:外部碎片指的是还没有被分配出去(不属于任何进程),但由于太小了无法分配给申请内存空间的新进程的内存空闲区域。
内碎片:内部碎片就是已经被分配出去(能明确指出属于哪个进程)却不能被利用的内存空间;
91. OSI 和 TCP/IP 网络模型
OSI七层
物理层,数据链路层,网络层,传输层,会话层,表示层,应用层
tcp/ip四层
网络接口层,网络层,传输层,应用层
应用层 HTTP、HTTPS、FTP、DNS、SNMP
会话层 Socket
传输层 TCP UDP
网络层 IP
数据链路层:MTU
92. 为什么使用Protocol Buffers
比较流行,使用简单,可以用工具生成协议代码,对数据进行压缩,在内存占用和网络传输方面具有优势
93. 什么时候用Reflection Probe(反射探针)
反射探针可在场景中的关键点对视觉环境进行采样。通常将这些探针放置在反射对象外观发生明显变化的每个点上(例如,隧道、建筑物附近区域和地面颜色变化的地方)。当反射对象靠近探针时探针采样的反射可用于对象的反射贴图。此外,当几个探针位于彼此附近时,Unity可在它们之间进行插值,从而实现反射的逐渐变化。因此,使用反射探针可以产生非常逼真的反射,同时将处理开销控制在可接受的水平。
反射探针捕获的是间接光,参考 IBL和Unity反射探针
94. 64位平台上,空struct对象和空class对象占用多少字节
public struct A {
}
public class B {
}
类型A创建的对象占用1 Byte,存储它的地址
类型B创建的对象占用24 Byte,引用类型对象的值由三个部分组成,对象头,方法表指针,空占位符(非空对象就是各个字段的内容),每个部分占用8 Byte,如果是32位平台每个部分占用4 Byte
参考文章
参考视频
参考书籍 《Unity3D 高级编程》
以后会慢慢补充
to be continue