上一话
引言此系列重点在于复现计算机视觉(分类、目标检测、语义分割)中深度学习各个经典的网络模型,以便初学者使用(浅入深出)!
代码都运行无误!!
首先复现深度学习的经典分类网络模块,其中专门做目标检测的Backbone(10.,11.)但是它的主要目的是用来提取特征所以也放在这里,有:
1.LeNet5(√,上一话)
2.VGG(√,上一话)
3.AlexNet(√,上一话)
4.ResNet(√,上一话)
5.ResNeXt(√)
6.GoogLeNet(√)

7.MobileNet(√)
8.ShuffleNet
9.EfficientNet
10.VovNet
11.DarkNet
...
注意:
完整代码上传至我的github,其次编译环境设置、分类数据集使用ImageNet或CIFAR10、项目文件结构上一章博客都讲过如何使用,其次由于GoogLeNet使用了全连接层不能修改图像的size,所以这个网络架构在图像预处理时图像的size就必须固定
5.ResNeXt[5]
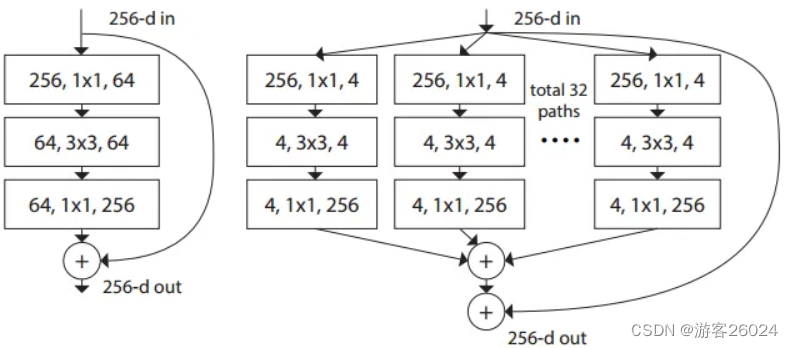
图 1.
如图 1. 所述ResNeXt与ResNet(在上一章已经讲过啦!)不同之处在于block。并且想清楚ResNeXt的网络架构,必须知道什么是分组卷积(Group Conv,其实AlexNet也有) 如下图2.1). 为普通卷积,2. 2). 为分组卷积
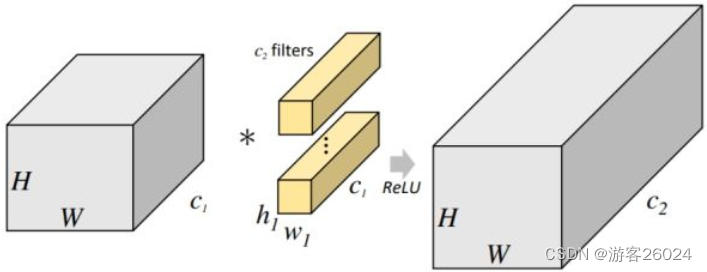
图 2.1).
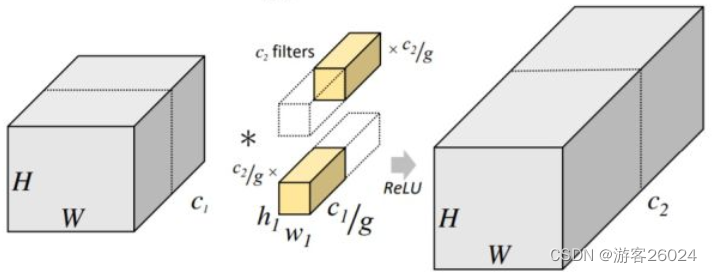
图 2.2).
这样做的最大好处是参数下降,节约了计算成本。
下图 2. 3).中的(a)、(b)、(c)三个block等价,也就是与图 1.中右边的block等价。理解看图 2. 4).
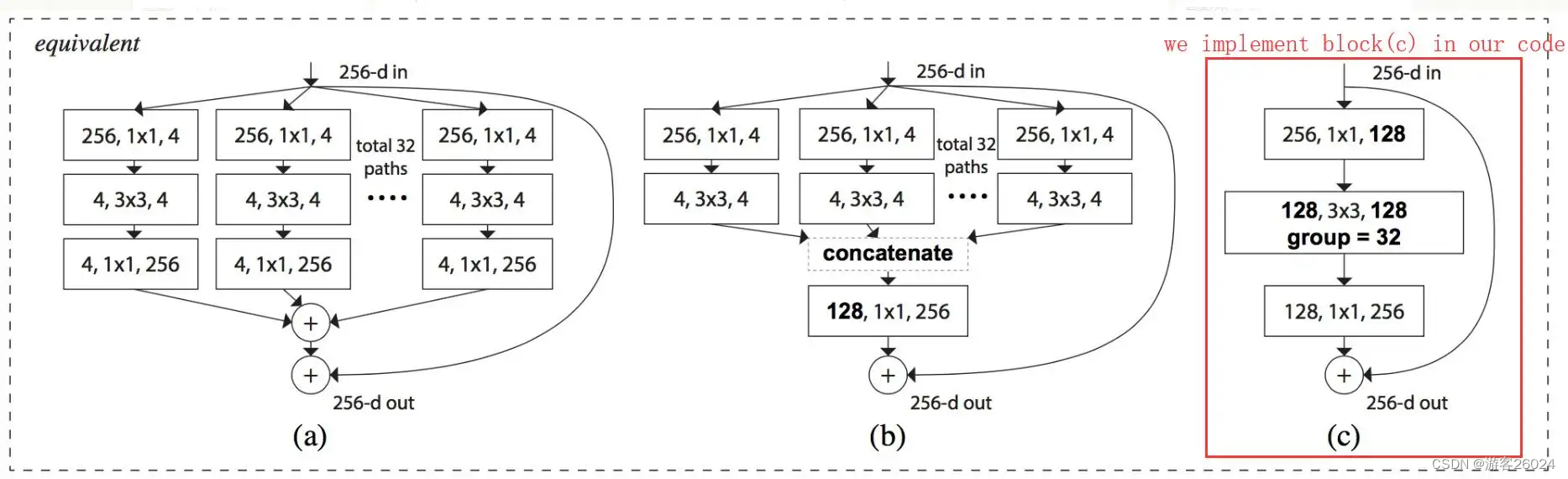
图 2. 3).

图 2. 4).
复现整个ResNeXt可从ResNeXt-50(32x4d)开始理解如下图 2. 5). ,32 表示每个block中的卷积的组分为32组,4 表示conv2中每个group中采用4个卷积核(比如128 = 32 * 4)。没复现18-layer与34-layer是因为其block低于3层,这样做不会使得错误率降低,没有意义。

图 2. 5).
对比ResNet其代码修改的地方便是 Bottleneck与ResNet分别都加了groups,width_per_group。
Bottleneck
# 50-layer, 101-layer, 152-layer
class Bottleneck(nn.Module):
"""
self.conv1(kernel_size=1,stride=2)
self.conv2(kernel_size=3,stride=1)
to
self.conv1(kernel_size=1,stride=1)
self.conv2(kernel_size=3,stride=2)
acc: up 0.5%
"""
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channels * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=width, kernel_size=1,
stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(width)
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, kernel_size=3,
groups=groups, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channels * self.expansion, kernel_size=1,
stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU()
self.downsample = downsample
@autocast()
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return outResNet
class resnet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000,
include_top=True, groups=1, width_per_group=64):
super(resnet, self).__init__()
self.include_top = include_top
self.in_channels = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(in_channels=3, out_channels=self.in_channels, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.flatten = nn.Flatten()
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channels, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channels != channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=channels * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channels * block.expansion))
layers = []
layers.append(block(in_channels=self.in_channels, out_channels=channels, downsample=downsample,
stride=stride, groups=self.groups, width_per_group=self.width_per_group))
self.in_channels = channels * block.expansion
for _ in range(1, block_num):
layers.append(
block(in_channels=self.in_channels, out_channels=channels,
groups=self.groups, width_per_group=self.width_per_group))
return nn.Sequential(*layers)
@autocast()
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = self.flatten(x)
x = self.fc(x)
return x完整代码
import torch
import torch.nn as nn
from utils.path import CheckPoints
from torch.cuda.amp import autocast
__all__ = [
'resnet18',
'resnet34',
'resnet50',
'resnet101',
'resnet152',
'resnext50_32x4d',
'resnext101_32x8d'
]
# if your network is limited, you can download them, and put them into CheckPoints(my Project:Simple-CV-Pytorch-master/checkpoints/).
model_urls = {
# 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth',
'resnet18': '{}/resnet18-5c106cde.pth'.format(CheckPoints),
# 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth',
'resnet34': '{}/resnet34-333f7ec4.pth'.format(CheckPoints),
# 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth',
'resnet50': '{}/resnet50-19c8e357.pth'.format(CheckPoints),
# 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth',
'resnet101': '{}/resnet101-5d3b4d8f.pth'.format(CheckPoints),
# 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth',
'resnet152': '{}/resnet152-b121ed2d.pth'.format(CheckPoints),
# 'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth',
'resnext50_32x4d': '{}/resnext50_32x4d-7cdf4587.pth'.format(CheckPoints),
# 'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth',
'resnext101_32x8d': '{}/resnext101_32x8d-8ba56ff5.pth'.format(CheckPoints)
}
def resnet_(arch, block, block_num, num_classes, pretrained, include_top, **kwargs):
model = resnet(block=block, blocks_num=block_num, num_classes=num_classes, include_top=include_top, **kwargs)
# if you're training for the first time, no pretrained is required!
if pretrained:
# if you want to use cpu, you should modify map_loaction=torch.device("cpu")
pretrained_models = torch.load(model_urls[arch], map_location=torch.device("cuda:0"))
# transfer learning
# if you want to train your own dataset
# del pretrained_models['module.classifier.bias']
model.load_state_dict(pretrained_models, strict=False)
return model
# 18-layer, 34-layer
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None,
groups=1, width_per_group=64):
super(BasicBlock, self).__init__()
if groups != 1 or width_per_group != 64:
raise ValueError("BasicBlock only supports groups=1 and base_width=64")
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, stride=1, padding=1,
bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
@autocast()
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += identity
out = self.relu(out)
return out
# 50-layer, 101-layer, 152-layer
class Bottleneck(nn.Module):
"""
self.conv1(kernel_size=1,stride=2)
self.conv2(kernel_size=3,stride=1)
to
self.conv1(kernel_size=1,stride=1)
self.conv2(kernel_size=3,stride=2)
acc: up 0.5%
"""
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, downsample=None,
groups=1, width_per_group=64):
super(Bottleneck, self).__init__()
width = int(out_channels * (width_per_group / 64.)) * groups
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=width, kernel_size=1,
stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(width)
self.conv2 = nn.Conv2d(in_channels=width, out_channels=width, kernel_size=3,
groups=groups, stride=stride, bias=False, padding=1)
self.bn2 = nn.BatchNorm2d(width)
self.conv3 = nn.Conv2d(in_channels=width, out_channels=out_channels * self.expansion, kernel_size=1,
stride=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.relu = nn.ReLU()
self.downsample = downsample
@autocast()
def forward(self, x):
identity = x
if self.downsample is not None:
identity = self.downsample(x)
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
out += identity
out = self.relu(out)
return out
class resnet(nn.Module):
def __init__(self, block, blocks_num, num_classes=1000,
include_top=True, groups=1, width_per_group=64):
super(resnet, self).__init__()
self.include_top = include_top
self.in_channels = 64
self.groups = groups
self.width_per_group = width_per_group
self.conv1 = nn.Conv2d(in_channels=3, out_channels=self.in_channels, kernel_size=7, stride=2,
padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channels)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, blocks_num[0])
self.layer2 = self._make_layer(block, 128, blocks_num[1], stride=2)
self.layer3 = self._make_layer(block, 256, blocks_num[2], stride=2)
self.layer4 = self._make_layer(block, 512, blocks_num[3], stride=2)
if self.include_top:
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.flatten = nn.Flatten()
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
def _make_layer(self, block, channels, block_num, stride=1):
downsample = None
if stride != 1 or self.in_channels != channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(in_channels=self.in_channels, out_channels=channels * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(channels * block.expansion))
layers = []
layers.append(block(in_channels=self.in_channels, out_channels=channels, downsample=downsample,
stride=stride, groups=self.groups, width_per_group=self.width_per_group))
self.in_channels = channels * block.expansion
for _ in range(1, block_num):
layers.append(
block(in_channels=self.in_channels, out_channels=channels,
groups=self.groups, width_per_group=self.width_per_group))
return nn.Sequential(*layers)
@autocast()
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
if self.include_top:
x = self.avgpool(x)
x = self.flatten(x)
x = self.fc(x)
return x
def resnet18(num_classes=1000, pretrained=False, include_top=True):
return resnet_('resnet18', BasicBlock, [2, 2, 2, 2], num_classes, pretrained, include_top)
def resnet34(num_classes=1000, pretrained=False, include_top=True):
return resnet_('resnet34', BasicBlock, [3, 4, 6, 3], num_classes, pretrained, include_top)
def resnet50(num_classes=1000, pretrained=False, include_top=True):
return resnet_('resnet50', Bottleneck, [3, 4, 6, 3], num_classes, pretrained, include_top)
def resnet101(num_classes=1000, pretrained=False, include_top=True):
return resnet_('resnet101', Bottleneck, [3, 4, 23, 3], num_classes, pretrained, include_top)
def resnet152(num_classes=1000, pretrained=False, include_top=True):
return resnet_('resnet152', Bottleneck, [3, 8, 36, 3], num_classes, pretrained, include_top)
def resnext50_32x4d(num_classes=1000, pretrained=False, include_top=True):
groups = 32
width_per_group = 4
return resnet_('resnext50_32x4d', Bottleneck, [3, 4, 6, 3],
num_classes=num_classes, pretrained=pretrained,
groups=groups, width_per_group=width_per_group,
include_top=include_top)
def resnext101_32x8d(num_classes=1000, pretrianed=False, include_top=True):
groups = 32
width_per_group = 8
return resnet_('resnext101_32x8d', Bottleneck, [3, 4, 23, 3],
num_classes=num_classes, pretrianed=pretrianed,
groups=groups, width_per_group=width_per_group,
include_top=include_top)6.GoogLeNet(size: 224 * 224 * 3)[6]
谷歌为了致敬LeNet,便取名为GoogLeNet。但是GoogLeNet的使用没有同时期的VGG广泛,这是因为GoogLeNet多了两个辅助分类器,使得其的可拓展性没那么强。
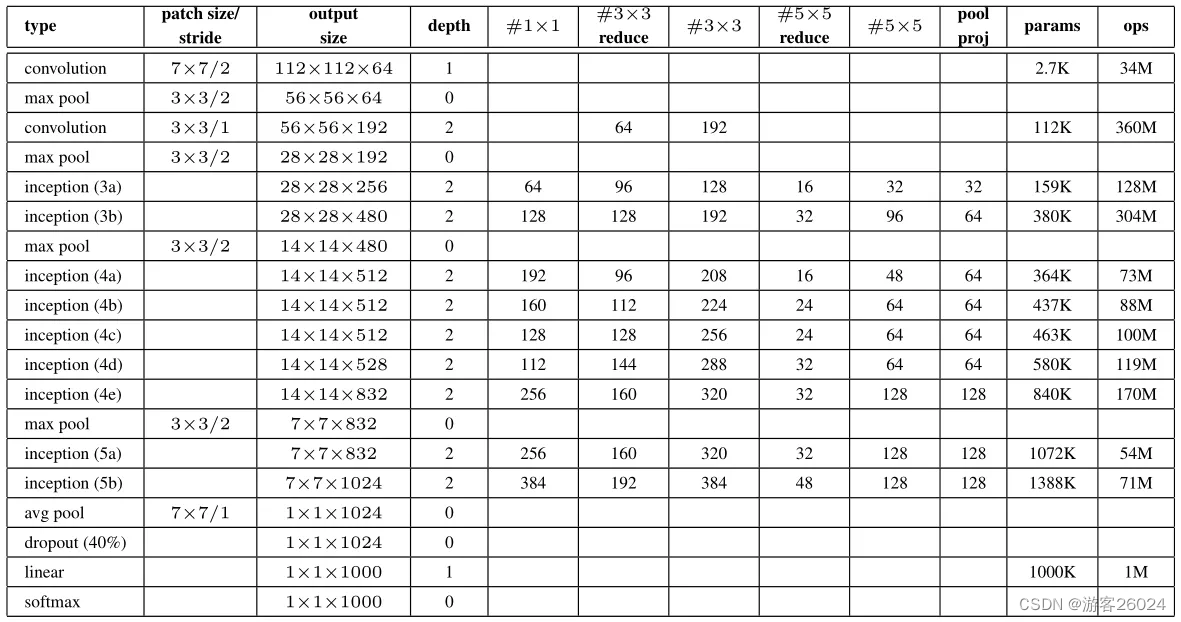
图 3.
如图 3. 所示还原GoogLeNet。
首先复现每个小的block,而每个小的block都是由一个卷积和一个ReLU激活,将其整合为class BasicConv2d
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, **kwargs)
self.relu = nn.ReLU()
@autocast()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x接着复现GoogLeNet中最重要的Inception,将图 3.(拆分成下图的图 4.)与图5. 还有代码 对照着来看,则
代码 图 2. 图 3.
self.branch1 (ch1x1) -> #1x1 -> 1x1 convolutions
self.branch2 (ch3x3red, ch3x3) -> #3x3reduce, #3x3 -> 1x1 convolutions, 3x3 convolutions
self.branch3 (ch5x5red, ch5x5) -> #5x5reduce, #5x5 -> 1x1 convolutions, 5x5 convolutions
self.branch4 (1x1conv[pool proj] maxpool) -> pool proj -> 1x1 convolutions, max pooling
其中
ch1x1 表示 在branch1中 1x1 conv 输出的channels
ch3x3read 表示 在branch2中 1x1 conv 输出的channels, ch3x3 表示 在branch3中 3x3 conv 输出的channels
ch5x5red 表示 在branch3中 1x1 conv 输出的channels, ch5x5 表示 在branch5中 5x5 conv 输出的channels
poolproj 表示 在branch4中 1x1 conv 输出的channels, 之后的max pool 输出的channels 与 之输入的channels(来自于这个1x1 conv)一样class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels=in_channels, out_channels=ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels=in_channels, out_channels=ch3x3red, kernel_size=1),
BasicConv2d(in_channels=ch3x3red, out_channels=ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels=in_channels, out_channels=ch5x5red, kernel_size=1),
BasicConv2d(in_channels=ch5x5red, out_channels=ch5x5, kernel_size=5, padding=2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels=in_channels, out_channels=pool_proj, kernel_size=1)
)
@autocast()
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
图 4.

图 5.
之后,复现辅助分类器,aux1与aux2,这两个辅助分类器的网络架构都是一样的如图 6.(经过一个 平均池化层,一个BasicConv2d,两个全连接层),仅仅是只是输入的channels不同,其输入的channels分别为512(aux1),528(aux2)

图 6.
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
# aux1 input: 14 * 14 * 512 -> 4 * 4 * 512
# aux2 input: 14 * 14 * 528 -> 4 * 4 * 528
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
# aux1 4 * 4 * 512 -> 4 * 4 * 128
# aux2 4 * 4 * 528 -> 4 * 4 * 128
self.conv = BasicConv2d(in_channels=in_channels, out_channels=128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
@autocast()
def forward(self, x):
x = self.averagePool(x)
x = self.conv(x)
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
x = F.relu(self.fc1(x))
x = F.dropout(x, 0.5, training=self.training)
x = self.fc2(x)
return x
最后复现整个GoogLeNet,如图 7.
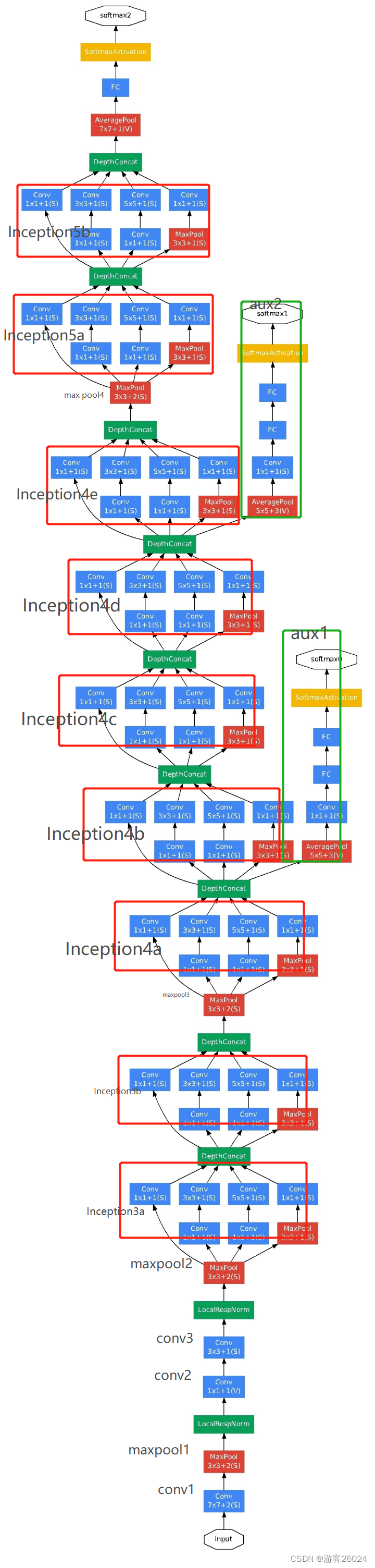
图 7.
先看conv1与maxpool1结合图 3. 与图 7.

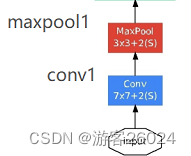
init
...
# input 224 * 224 * 3 -> 112 * 112 * 64
self.conv1 = BasicConv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
# 112 * 112 * 64 -> 56 * 56 * 64
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
...
forward
...
x = self.conv1(x)
x = self.maxpool1(x)
...由于LRN加入的效果不明显,影响不是很大,所以本次复现选择忽略LRN,如果想使用可调用
import torch.nn.functional as F
F.local_response_norm()再看conv2 、conv3 与maxpool2结合图 3. 与图 7.


init
...
# 56 * 56 * 64 -> 56 * 56 * 64
self.conv2 = BasicConv2d(in_channels=64, out_channels=64, kernel_size=1)
# 56 * 56 * 64 -> 56 * 56 * 192
self.conv3 = BasicConv2d(in_channels=64, out_channels=192, kernel_size=3, padding=1)
# 56 * 56 * 192 -> 28 * 28 * 192
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
...
forward
...
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
...接着复现Inception 3a,3b,maxpool3 结合图 3. 与图 7.
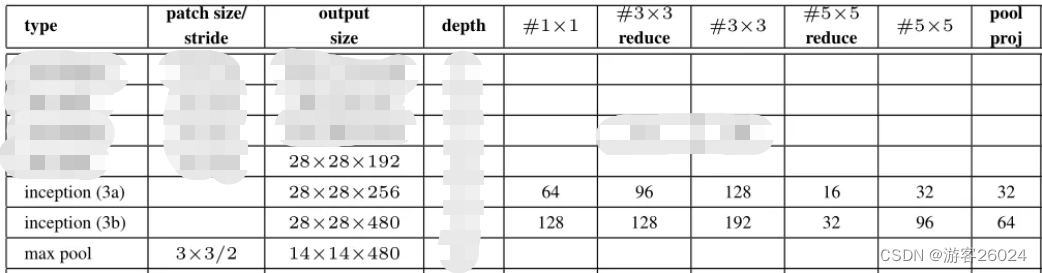
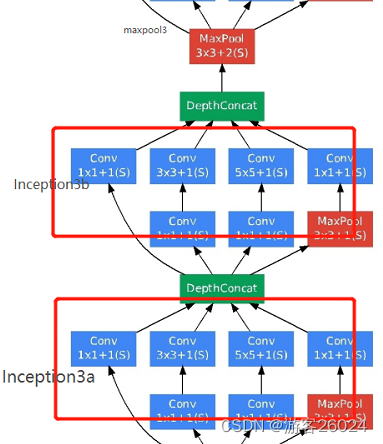
init
...
# 28 * 28 * 192 -> 28 * 28 * 256
self.inception3a = Inception(in_channels=192, ch1x1=64, ch3x3red=96, ch3x3=128, ch5x5red=16, ch5x5=32,
pool_proj=32)
# 28 * 28 * 256 -> 28 * 28 * 480
self.inception3b = Inception(in_channels=256, ch1x1=128, ch3x3red=128, ch3x3=192, ch5x5red=32, ch5x5=96,
pool_proj=64)
# 28 * 28 * 480 -> 14 * 14 * 480
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
...
forward
...
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
...之后复现Inception4a, 4b,4c,4d,4e,并且在4b(4a输出)与4e(4d输出)上分别插入aux1与aux2,结合图 3.与图 7.
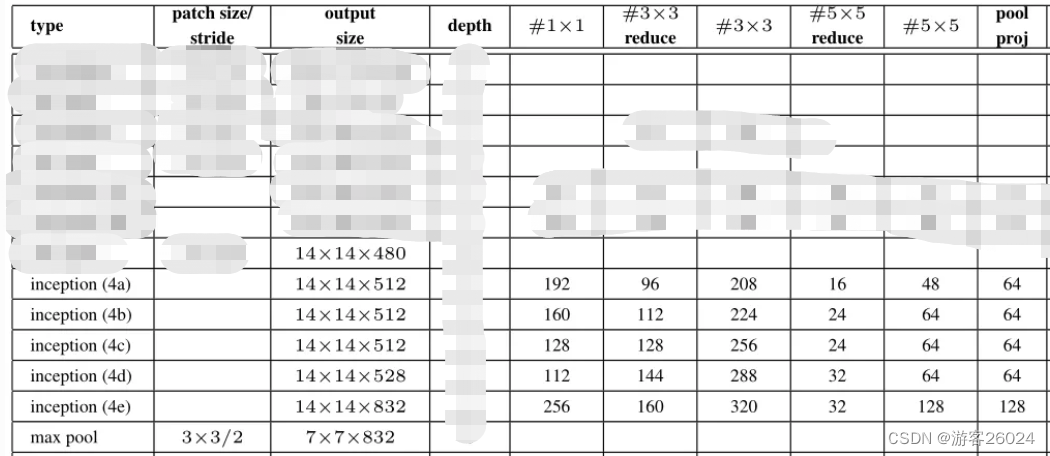

init
...
# 14 * 14 * 480 -> 512 * 14 * 14
self.inception4a = Inception(in_channels=480, ch1x1=192, ch3x3red=96, ch3x3=208, ch5x5red=16, ch5x5=48,
pool_proj=64)
# 512 * 14 * 14 -> 512 * 14 * 14
self.inception4b = Inception(in_channels=512, ch1x1=160, ch3x3red=112, ch3x3=224, ch5x5red=24, ch5x5=64,
pool_proj=64)
# 512 * 14 * 14 -> 512 * 14 * 14
self.inception4c = Inception(in_channels=512, ch1x1=128, ch3x3red=128, ch3x3=256, ch5x5red=24, ch5x5=64,
pool_proj=64)
# 512 * 14 * 14 -> 528 * 14 * 14
self.inception4d = Inception(in_channels=512, ch1x1=112, ch3x3red=144, ch3x3=288, ch5x5red=32, ch5x5=64,
pool_proj=64)
# 14 * 14 * 528 -> 14 * 14 * 832
self.inception4e = Inception(in_channels=528, ch1x1=256, ch3x3red=160, ch3x3=320, ch5x5red=32, ch5x5=128,
pool_proj=128)
# 14 * 14 * 832 -> 7 * 7 * 832
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
if self.aux_logits:
self.aux1 = InceptionAux(in_channels=512, num_classes=num_classes)
self.aux2 = InceptionAux(in_channels=528, num_classes=num_classes)
...
forward
...
x = self.inception4a(x)
if self.training and self.aux_logits:
aux1 = self.aux1(x)
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
if self.training and self.aux_logits:
aux2 = self.aux2(x)
x = self.inception4e(x)
x = self.maxpool4(x)
...复现Inception5a,5b,结合图 3.与图 7.
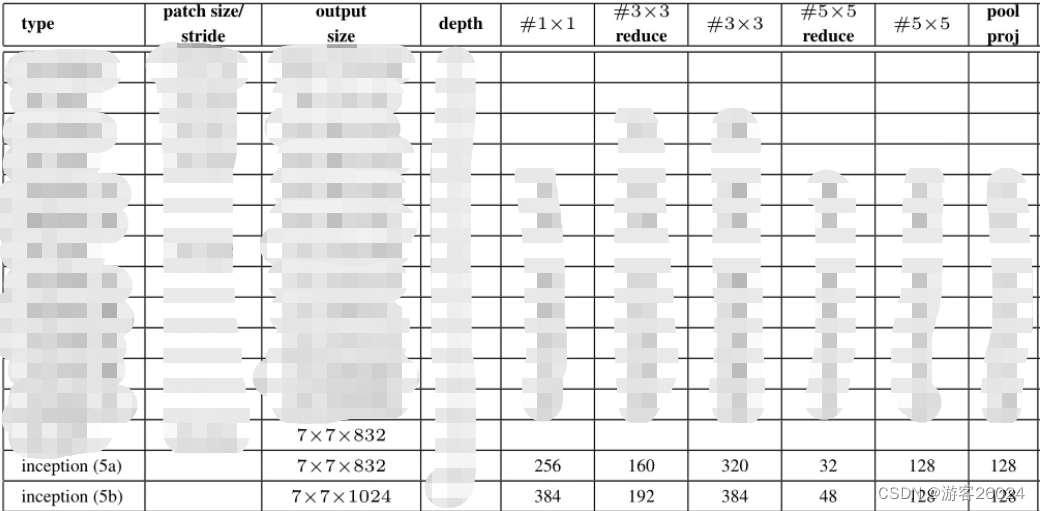
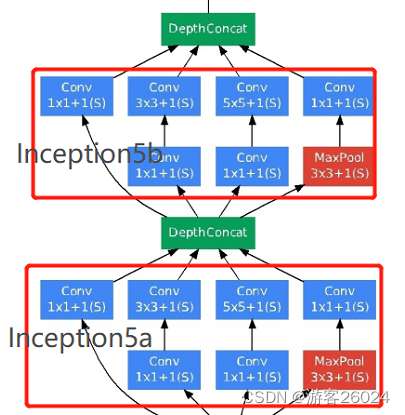
init
...
# 7 * 7 * 832 -> 7 * 7 * 832
self.inception5a = Inception(in_channels=832, ch1x1=256, ch3x3red=160, ch3x3=320, ch5x5red=32, ch5x5=128,
pool_proj=128)
# 7 * 7 * 832 -> 7 * 7 * 1024
self.inception5b = Inception(in_channels=832, ch1x1=384, ch3x3red=192, ch3x3=384, ch5x5red=48, ch5x5=128,
pool_proj=128)
...
forward
...
x = self.inception5a(x)
x = self.inception5b(x)
...之后复现平均池化层,dropout,全连接层,结合图 3.与图 7.

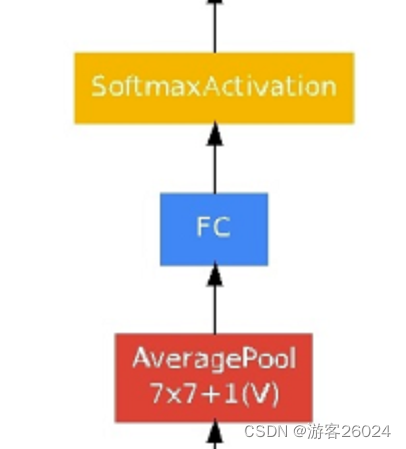
init
...
# 1 * 1 * 1024
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
...
forward
...
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.dropout(x)
x = self.fc(x)
...class googlenet代码
class googlenet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(googlenet, self).__init__()
self.aux_logits = aux_logits
# input 224 * 224 * 3 -> 112 * 112 * 64
self.conv1 = BasicConv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
# 112 * 112 * 64 -> 56 * 56 * 64
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
# 56 * 56 * 64 -> 56 * 56 * 64
self.conv2 = BasicConv2d(in_channels=64, out_channels=64, kernel_size=1)
# 56 * 56 * 64 -> 56 * 56 * 192
self.conv3 = BasicConv2d(in_channels=64, out_channels=192, kernel_size=3, padding=1)
# 56 * 56 * 192 -> 28 * 28 * 192
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
# 28 * 28 * 192 -> 28 * 28 * 256
self.inception3a = Inception(in_channels=192, ch1x1=64, ch3x3red=96, ch3x3=128, ch5x5red=16, ch5x5=32,
pool_proj=32)
# 28 * 28 * 256 -> 28 * 28 * 480
self.inception3b = Inception(in_channels=256, ch1x1=128, ch3x3red=128, ch3x3=192, ch5x5red=32, ch5x5=96,
pool_proj=64)
# 28 * 28 * 480 -> 14 * 14 * 480
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
# 14 * 14 * 480 -> 512 * 14 * 14
self.inception4a = Inception(in_channels=480, ch1x1=192, ch3x3red=96, ch3x3=208, ch5x5red=16, ch5x5=48,
pool_proj=64)
# 512 * 14 * 14 -> 512 * 14 * 14
self.inception4b = Inception(in_channels=512, ch1x1=160, ch3x3red=112, ch3x3=224, ch5x5red=24, ch5x5=64,
pool_proj=64)
# 512 * 14 * 14 -> 512 * 14 * 14
self.inception4c = Inception(in_channels=512, ch1x1=128, ch3x3red=128, ch3x3=256, ch5x5red=24, ch5x5=64,
pool_proj=64)
# 512 * 14 * 14 -> 528 * 14 * 14
self.inception4d = Inception(in_channels=512, ch1x1=112, ch3x3red=144, ch3x3=288, ch5x5red=32, ch5x5=64,
pool_proj=64)
# 14 * 14 * 528 -> 14 * 14 * 832
self.inception4e = Inception(in_channels=528, ch1x1=256, ch3x3red=160, ch3x3=320, ch5x5red=32, ch5x5=128,
pool_proj=128)
# 14 * 14 * 832 -> 7 * 7 * 832
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
# 7 * 7 * 832 -> 7 * 7 * 832
self.inception5a = Inception(in_channels=832, ch1x1=256, ch3x3red=160, ch3x3=320, ch5x5red=32, ch5x5=128,
pool_proj=128)
# 7 * 7 * 832 -> 7 * 7 * 1024
self.inception5b = Inception(in_channels=832, ch1x1=384, ch3x3red=192, ch3x3=384, ch5x5red=48, ch5x5=128,
pool_proj=128)
if self.aux_logits:
self.aux1 = InceptionAux(in_channels=512, num_classes=num_classes)
self.aux2 = InceptionAux(in_channels=528, num_classes=num_classes)
# 1 * 1 * 1024
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
@autocast()
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
x = self.inception4a(x)
if self.training and self.aux_logits:
aux1 = self.aux1(x)
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
if self.training and self.aux_logits:
aux2 = self.aux2(x)
x = self.inception4e(x)
x = self.maxpool4(x)
x = self.inception5a(x)
x = self.inception5b(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.dropout(x)
x = self.fc(x)
if self.training and self.aux_logits:
return x, aux2, aux1
return x完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from utils.path import CheckPoints
from torch.cuda.amp import autocast
__all__ = ['googlenet']
models_urls = {
# 'googlenet': 'https://download.pytorch.org/models/googlenet-1378be20.pth',
'googlenet': '{}/googlenet-1378be20.pth'.format(CheckPoints),
}
def GoogLeNet(num_classes, pretrained, aux_logits=True, init_weights=True, **kwargs):
model = googlenet(num_classes=num_classes, aux_logits=aux_logits, init_weights=init_weights, **kwargs)
if pretrained:
# if you want to use cpu, you should modify map_loaction=torch.device("cpu")
pretrained_models = torch.load(models_urls['googlenet'], map_location=torch.device("cuda:0"))
# transfer learning
# I modify GoogLeNet
# Inception.branch3.1.conv(kernel_size=3) to Inception.branch3.1.conv(kernel_size=5)
del pretrained_models['inception3a.branch3.1.conv.weight']
del pretrained_models['inception3b.branch3.1.conv.weight']
del pretrained_models['inception4a.branch3.1.conv.weight']
del pretrained_models['inception4b.branch3.1.conv.weight']
del pretrained_models['inception4c.branch3.1.conv.weight']
del pretrained_models['inception4d.branch3.1.conv.weight']
del pretrained_models['inception4e.branch3.1.conv.weight']
del pretrained_models['inception5a.branch3.1.conv.weight']
del pretrained_models['inception5b.branch3.1.conv.weight']
model.load_state_dict(pretrained_models, strict=False)
return model
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, **kwargs)
self.relu = nn.ReLU()
@autocast()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels=in_channels, out_channels=ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels=in_channels, out_channels=ch3x3red, kernel_size=1),
BasicConv2d(in_channels=ch3x3red, out_channels=ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels=in_channels, out_channels=ch5x5red, kernel_size=1),
BasicConv2d(in_channels=ch5x5red, out_channels=ch5x5, kernel_size=5, padding=2)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
BasicConv2d(in_channels=in_channels, out_channels=pool_proj, kernel_size=1)
)
@autocast()
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
class InceptionAux(nn.Module):
def __init__(self, in_channels, num_classes):
super(InceptionAux, self).__init__()
# aux1 input: 14 * 14 * 512 -> 4 * 4 * 512
# aux2 input: 14 * 14 * 528 -> 4 * 4 * 528
self.averagePool = nn.AvgPool2d(kernel_size=5, stride=3)
# aux1 4 * 4 * 512 -> 4 * 4 * 128
# aux2 4 * 4 * 528 -> 4 * 4 * 128
self.conv = BasicConv2d(in_channels=in_channels, out_channels=128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
@autocast()
def forward(self, x):
x = self.averagePool(x)
x = self.conv(x)
x = torch.flatten(x, 1)
x = F.dropout(x, 0.5, training=self.training)
x = F.relu(self.fc1(x))
x = F.dropout(x, 0.5, training=self.training)
x = self.fc2(x)
return x
class googlenet(nn.Module):
def __init__(self, num_classes=1000, aux_logits=True, init_weights=False):
super(googlenet, self).__init__()
self.aux_logits = aux_logits
# input 224 * 224 * 3 -> 112 * 112 * 64
self.conv1 = BasicConv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
# 112 * 112 * 64 -> 56 * 56 * 64
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
# 56 * 56 * 64 -> 56 * 56 * 64
self.conv2 = BasicConv2d(in_channels=64, out_channels=64, kernel_size=1)
# 56 * 56 * 64 -> 56 * 56 * 192
self.conv3 = BasicConv2d(in_channels=64, out_channels=192, kernel_size=3, padding=1)
# 56 * 56 * 192 -> 28 * 28 * 192
self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
# 28 * 28 * 192 -> 28 * 28 * 256
self.inception3a = Inception(in_channels=192, ch1x1=64, ch3x3red=96, ch3x3=128, ch5x5red=16, ch5x5=32,
pool_proj=32)
# 28 * 28 * 256 -> 28 * 28 * 480
self.inception3b = Inception(in_channels=256, ch1x1=128, ch3x3red=128, ch3x3=192, ch5x5red=32, ch5x5=96,
pool_proj=64)
# 28 * 28 * 480 -> 14 * 14 * 480
self.maxpool3 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
# 14 * 14 * 480 -> 512 * 14 * 14
self.inception4a = Inception(in_channels=480, ch1x1=192, ch3x3red=96, ch3x3=208, ch5x5red=16, ch5x5=48,
pool_proj=64)
# 512 * 14 * 14 -> 512 * 14 * 14
self.inception4b = Inception(in_channels=512, ch1x1=160, ch3x3red=112, ch3x3=224, ch5x5red=24, ch5x5=64,
pool_proj=64)
# 512 * 14 * 14 -> 512 * 14 * 14
self.inception4c = Inception(in_channels=512, ch1x1=128, ch3x3red=128, ch3x3=256, ch5x5red=24, ch5x5=64,
pool_proj=64)
# 512 * 14 * 14 -> 528 * 14 * 14
self.inception4d = Inception(in_channels=512, ch1x1=112, ch3x3red=144, ch3x3=288, ch5x5red=32, ch5x5=64,
pool_proj=64)
# 14 * 14 * 528 -> 14 * 14 * 832
self.inception4e = Inception(in_channels=528, ch1x1=256, ch3x3red=160, ch3x3=320, ch5x5red=32, ch5x5=128,
pool_proj=128)
# 14 * 14 * 832 -> 7 * 7 * 832
self.maxpool4 = nn.MaxPool2d(kernel_size=3, stride=2, ceil_mode=True)
# 7 * 7 * 832 -> 7 * 7 * 832
self.inception5a = Inception(in_channels=832, ch1x1=256, ch3x3red=160, ch3x3=320, ch5x5red=32, ch5x5=128,
pool_proj=128)
# 7 * 7 * 832 -> 7 * 7 * 1024
self.inception5b = Inception(in_channels=832, ch1x1=384, ch3x3red=192, ch3x3=384, ch5x5red=48, ch5x5=128,
pool_proj=128)
if self.aux_logits:
self.aux1 = InceptionAux(in_channels=512, num_classes=num_classes)
self.aux2 = InceptionAux(in_channels=528, num_classes=num_classes)
# 1 * 1 * 1024
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(0.4)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
@autocast()
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.maxpool2(x)
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
x = self.inception4a(x)
if self.training and self.aux_logits:
aux1 = self.aux1(x)
x = self.inception4b(x)
x = self.inception4c(x)
x = self.inception4d(x)
if self.training and self.aux_logits:
aux2 = self.aux2(x)
x = self.inception4e(x)
x = self.maxpool4(x)
x = self.inception5a(x)
x = self.inception5b(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.dropout(x)
x = self.fc(x)
if self.training and self.aux_logits:
return x, aux2, aux1
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
7.MobileNet
7.1 MobileNet v1[7]
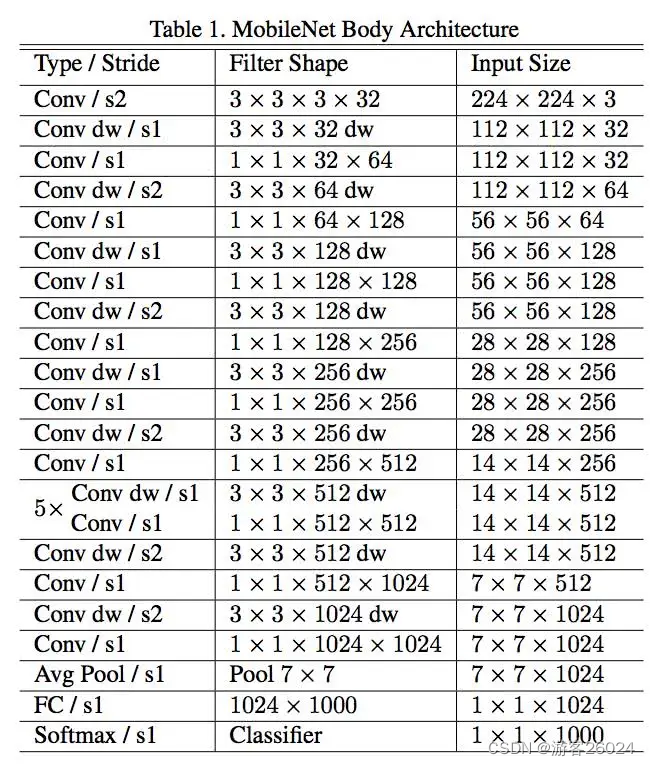
图 8.
如图 8.为MobileNet v1的网络架构。搞懂MobileNet v1之前需要搞懂 depthwise 卷积 与 pointwise 卷积,如果想让一个feature map 进行卷积之后 输出的通道数与之前不一样,普通卷积 与 depthwise 卷积 + pointwise 卷积的做法是不一样的,但是可以得到一样的输出通道数,但是depthwise 卷积 + pointwise 卷积 参数 远远少于 普通卷积。
如图 9.为普通卷积,其中卷积的输出通道表示有多少个卷积参与其中。(比如对一个shape为32x32x3的feature map做卷积,其中卷积的kernel_size为1,in_channels就是这个feature map的channels,而out_channels就是用了多少个卷积,如果用了4个就是4,会得到的feature map就是32x32x4(就用个1x1 conv 对其通道进行改变一下,不看stride,padding之类,不要把这个弄得太麻烦了))
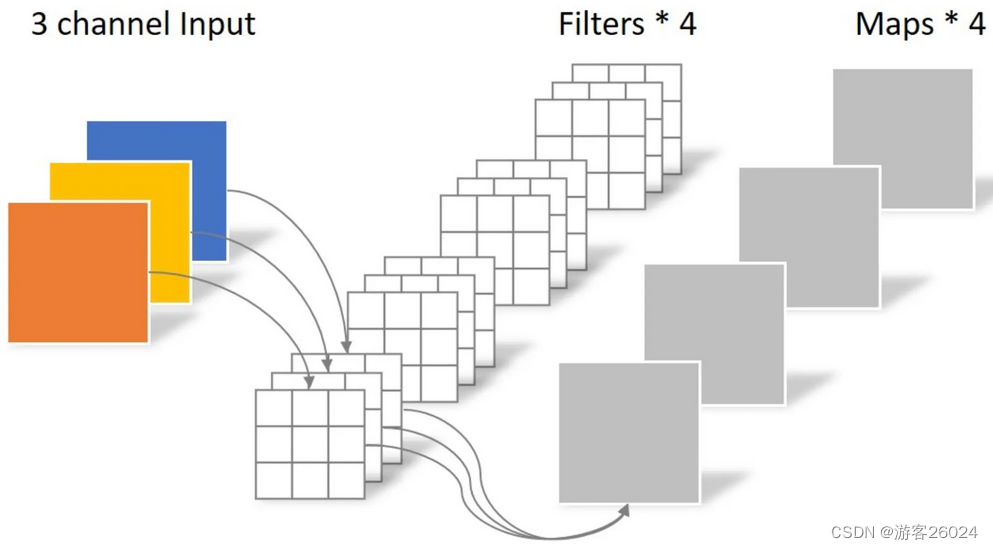
图 9.

图 10.
如图 11.,pointwise 卷积(大致理解)把之前depthwise得到的feature map 经过4个1x1xM的卷积在深度上进行加权组合,得到最终的feature map,其shape为?_size x ?_size x 4。
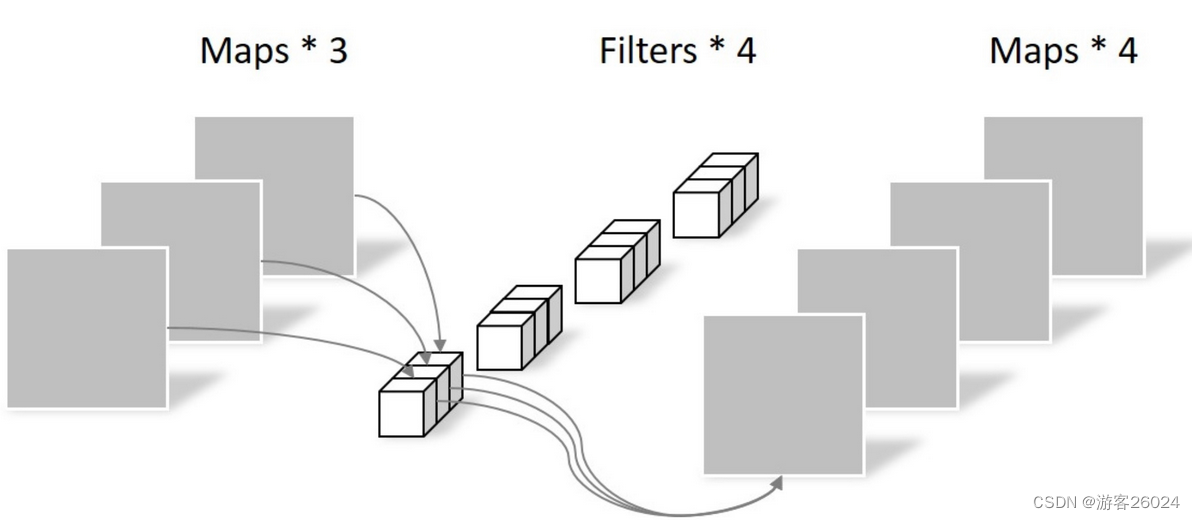
图 11.
由于在MobileNet v1网络架构中,在训练后depthwise部分的卷积核参数大部分等于零,也就是depthwise卷积和没有起到作用。于是便有了v2版本,所以v1不复现,直接看v2。
7.2 MobileNet v2[8]

图 12.
MobileNet v2: Inverted residuals and linear bottlenecks,亮点在这个名字中体现了,就是Inverted residuals 与 Linear bottlenecks,如图 12.为MobileNet v2的网络架构(其中, t 表示 扩展因子,扩展卷积核的个数;c 表示 输出的通道数;n 表示 bottleneck[倒残差结构]重复的个数,s 表示 步长,每个block一层的stride。)。
首先复现这个Inverted residuals 倒残差结构,如下图 13.(其中的t为扩展因子,扩展卷积核的个数)与图 14.,(左图有个shortcut,这个shortcut有且仅有当stride=1 and input feature map shape == output feature map shape)步骤,
1x1 conv 升维
3x3 conv DepthWise
1x1 conv 降维一层 ConvBNReLU(继承nn.Sequential)
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride,
padding=padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU6())
图 13.

图 14.
整个Inverted residuals,结合图 13. 与 图 14.
class InvertedResidual(nn.Module):
def __init__(self, in_channels, out_channels, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channels = in_channels * expand_ratio
self.use_shortcut = stride == 1 and in_channels == out_channels
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channels=in_channels, out_channels=hidden_channels, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(in_channels=hidden_channels, out_channels=hidden_channels, stride=stride,
groups=hidden_channels),
# 1x1 pointwise conv(liner)
nn.Conv2d(in_channels=hidden_channels, out_channels=out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels)
])
self.conv = nn.Sequential(*layers)
@autocast()
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)其中 expand_ratio 表示 t 扩展因子,in_channels 表示k,隐藏层的channels就为(t*k) hidden_channels
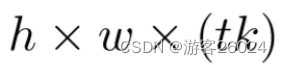
hidden_channels = in_channels * expand_ratio之后查看,是否使用shorcut->self.use_shortcut,满足之前所述的两个条件,1. stride=1; 2. in_channels=out_channels;
self.use_shortcut = stride == 1 and in_channels == out_channels接着,查看bottleneck是否使用为1,如果为1就没有1x1 conv(改变通道),如果不为1则有1x1 conv。
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channels=in_channels, out_channels=hidden_channels, kernel_size=1))MobileNet v2网络架构,结合图 12.,先来看初始化,其中alpha 表示 控制卷积核使用的倍率;_make_divisible(params,round_nearest) 表示将channels调整为round_nearest的整数倍。
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channels = _make_divisible(32 * alpha, round_nearest)
last_channels = _make_divisible(1280 * alpha, round_nearest)_make_divisible函数为:ch->32 * alpha or 1280 * alpha, divisor->round_nearest
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch之后,倒残差的参数设置,结合图 12.来看
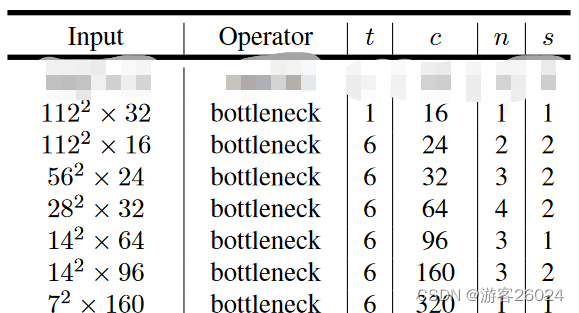
inverted_residual_setting = [
# t,c,n,s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]第一层卷积,结合图 12.

搭建bottlenck,结合图 12.,(其中, t 表示 扩展因子,扩展卷积核的个数;c 表示 输出的通道数;n 表示 bottleneck[倒残差结构]重复的个数,s 表示 步长,每个block一层的stride。)
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channels = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(
block(in_channels=input_channels, out_channels=output_channels, stride=stride, expand_ratio=t))
input_channels = output_channels结合图 12.,定义后续

# building last several layers
features.append(ConvBNReLU(in_channels=input_channels, out_channels=last_channels, kernel_size=1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channels, num_classes)
)整个MobileNet v2网络架构代码
class mobilenet_v2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8, init_weights=False):
super(mobilenet_v2, self).__init__()
block = InvertedResidual
input_channels = _make_divisible(32 * alpha, round_nearest)
last_channels = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t,c,n,s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(in_channels=3, out_channels=input_channels, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channels = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(
block(in_channels=input_channels, out_channels=output_channels, stride=stride, expand_ratio=t))
input_channels = output_channels
# building last several layers
features.append(ConvBNReLU(in_channels=input_channels, out_channels=last_channels, kernel_size=1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channels, num_classes)
)
if init_weights:
self._initialize_weights()
def _initialize_weights(self):
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
@autocast()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x完整代码
import torch
import torch.nn as nn
from utils.path import CheckPoints
from torch.cuda.amp import autocast
__all__ = ['mobilenet_v2']
models_urls = {
# "mobilenet_v2": "https://download.pytorch.org/models/mobilenet_v2-b0353104.pth",
'mobilenet_v2': '{}/mobilenet_v2-b0353104.pth'.format(CheckPoints),
}
def MobileNet_v2(num_classes=1000, pretrained=False, init_weights=False, **kwargs):
model = mobilenet_v2(num_classes=num_classes, init_weights=init_weights, **kwargs)
if pretrained:
# if you want to use cpu, you should modify map_loaction=torch.device("cpu")
pretrained_models = torch.load(models_urls['mobilenet_v2'], map_location=torch.device("cuda:0"))
model.load_state_dict(pretrained_models, strict=False)
return model
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels,
kernel_size=kernel_size, stride=stride,
padding=padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU6())
class InvertedResidual(nn.Module):
def __init__(self, in_channels, out_channels, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channels = in_channels * expand_ratio
self.use_shortcut = stride == 1 and in_channels == out_channels
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channels=in_channels, out_channels=hidden_channels, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(in_channels=hidden_channels, out_channels=hidden_channels, stride=stride,
groups=hidden_channels),
# 1x1 pointwise conv(liner)
nn.Conv2d(in_channels=hidden_channels, out_channels=out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels)
])
self.conv = nn.Sequential(*layers)
@autocast()
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class mobilenet_v2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8, init_weights=False):
super(mobilenet_v2, self).__init__()
block = InvertedResidual
input_channels = _make_divisible(32 * alpha, round_nearest)
last_channels = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t,c,n,s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(in_channels=3, out_channels=input_channels, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channels = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(
block(in_channels=input_channels, out_channels=output_channels, stride=stride, expand_ratio=t))
input_channels = output_channels
# building last several layers
features.append(ConvBNReLU(in_channels=input_channels, out_channels=last_channels, kernel_size=1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channels, num_classes)
)
if init_weights:
self._initialize_weights()
def _initialize_weights(self):
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
@autocast()
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x7.3 MobileNet v3[9]
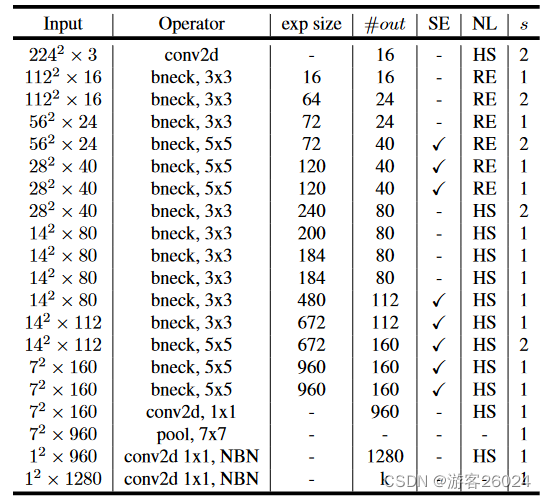
Large
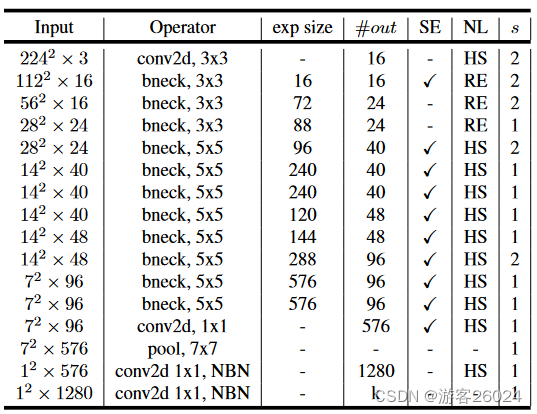
small
买个关子,下一章更新...
训练代码
import os
import logging
import argparse
import warnings
warnings.filterwarnings('ignore')
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
sys.path.append(BASE_DIR)
import time
import torch
from data import *
import torchvision
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
from torchvision import transforms
from utils.accuracy import accuracy
from torch.utils.data import DataLoader
from utils.get_logger import get_logger
from models.basenets.lenet5 import lenet5
from models.basenets.alexnet import alexnet
from utils.AverageMeter import AverageMeter
from torch.cuda.amp import autocast, GradScaler
from models.basenets.googlenet import googlenet, GoogLeNet
from models.basenets.vgg import vgg11, vgg13, vgg16, vgg19
from models.basenets.mobilenet_v2 import mobilenet_v2, MobileNet_v2
from models.basenets.resnet import resnet18, resnet34, resnet50, resnet101, resnet152, resnext50_32x4d, resnext101_32x8d
def parse_args():
parser = argparse.ArgumentParser(description='PyTorch Classification Training')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset',
type=str,
default='ImageNet',
choices=['ImageNet', 'CIFAR'],
help='ImageNet, CIFAR')
parser.add_argument('--dataset_root',
type=str,
default=ImageNet_Train_ROOT,
choices=[ImageNet_Train_ROOT, CIFAR_ROOT],
help='Dataset root directory path')
parser.add_argument('--basenet',
type=str,
default='resnext',
choices=['resnet', 'vgg', 'lenet', 'alexnet', 'googlenet', 'mobilenet', 'resnext'],
help='Pretrained base model')
parser.add_argument('--depth',
type=int,
default=50,
help='BaseNet depth, including: LeNet of 5, AlexNet of 0, VGG of 11, 13, 16, 19, ResNet of 18, 34, 50, 101, 152, GoogLeNet of 0, MobileNet of 2, 3, ResNeXt of 50, 101')
parser.add_argument('--batch_size',
type=int,
default=32,
help='Batch size for training')
parser.add_argument('--resume',
type=str,
default=None,
help='Checkpoint state_dict file to resume training from')
parser.add_argument('--num_workers',
type=int,
default=8,
help='Number of workers user in dataloading')
parser.add_argument('--cuda',
type=str,
default=True,
help='Use CUDA to train model')
parser.add_argument('--accumulation_steps',
type=int,
default=1,
help='Gradient acumulation steps')
parser.add_argument('--save_folder',
type=str,
default=config.checkpoint_path,
help='Directory for saving checkpoint models')
parser.add_argument('--tensorboard',
type=str,
default=False,
help='Use tensorboard for loss visualization')
parser.add_argument('--log_folder',
type=str,
default=config.log,
help='Log Folder')
parser.add_argument('--log_name',
type=str,
default=config.classification_train_log,
help='Log Name')
parser.add_argument('--tensorboard_log',
type=str,
default=config.tensorboard_log,
help='Use tensorboard for loss visualization')
parser.add_argument('--lr',
type=float,
default=1e-3,
help='learning rate')
parser.add_argument('--epochs',
type=int,
default=30,
help='Number of epochs')
parser.add_argument('--num_classes',
type=int,
default=1000,
help='the number classes, like ImageNet:1000, cifar:10')
parser.add_argument('--image_size',
type=int,
default=224,
help='image size, like ImageNet:224, cifar:32')
parser.add_argument('--pretrained',
type=str,
default=True,
help='Models was pretrained')
parser.add_argument('--init_weights',
type=str,
default=False,
help='Init Weights')
parser.add_argument('--patience',
type=int,
default=2,
help='patience of ReduceLROnPlateau')
parser.add_argument('--weight_decay',
type=float,
default=1e-4,
help='weight decay')
parser.add_argument('--momentum',
type=float,
default=0.9,
help='Momentum value for optim')
return parser.parse_args()
args = parse_args()
# 1. Log
get_logger(args.log_folder, args.log_name)
logger = logging.getLogger(args.log_name)
# 2. Torch choose cuda or cpu
if torch.cuda.is_available():
if args.cuda:
torch.set_default_tensor_type('torch.cuda.FloatTensor')
if not args.cuda:
print("WARNING: It looks like you have a CUDA device, but you aren't using it" +
"\n You can set the parameter of cuda to True.")
torch.set_default_tensor_type('torch.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
if not os.path.exists(args.save_folder):
os.mkdir(args.save_folder)
def train():
# 3. Create SummaryWriter
if args.tensorboard:
from torch.utils.tensorboard import SummaryWriter
# tensorboard loss
writer = SummaryWriter(args.tensorboard_log)
# vgg16, alexnet and lenet5 need to resize image_size, because of fc.
if args.basenet == 'vgg' or args.basenet == 'alexnet' or args.basenet == 'googlenet':
args.image_size = 224
elif args.basenet == 'lenet':
args.image_size = 32
# 4. Ready dataset
if args.dataset == 'ImageNet':
if args.dataset_root == CIFAR_ROOT:
raise ValueError('Must specify dataset_root if specifying dataset ImageNet2012.')
elif os.path.exists(ImageNet_Train_ROOT) is None:
raise ValueError("WARNING: Using default ImageNet2012 dataset_root because " +
"--dataset_root was not specified.")
dataset = torchvision.datasets.ImageFolder(
root=args.dataset_root,
transform=torchvision.transforms.Compose([
transforms.Resize((args.image_size,
args.image_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
]))
elif args.dataset == 'CIFAR':
if args.dataset_root == ImageNet_Train_ROOT:
raise ValueError('Must specify dataset_root if specifying dataset CIFAR10.')
elif args.dataset_root is None:
raise ValueError("Must provide --dataset_root when training on CIFAR10.")
dataset = torchvision.datasets.CIFAR10(root=args.dataset_root, train=True,
transform=torchvision.transforms.Compose([
transforms.Resize((args.image_size,
args.image_size)),
torchvision.transforms.ToTensor()]))
else:
raise ValueError('Dataset type not understood (must be ImageNet or CIFAR), exiting.')
dataloader = torch.utils.data.DataLoader(dataset=dataset, batch_size=args.batch_size,
shuffle=True, num_workers=args.num_workers,
pin_memory=False, generator=torch.Generator(device='cuda'))
top1 = AverageMeter()
top5 = AverageMeter()
losses = AverageMeter()
# 5. Define train model
# Unfortunately, LeNet5 and AlexNet don't provide pretrianed Model.
if args.basenet == 'lenet':
if args.depth == 5:
model = lenet5(num_classes=args.num_classes,
init_weights=args.init_weights)
else:
raise ValueError('Unsupported LeNet depth!')
elif args.basenet == 'alexnet':
if args.depth == 0:
model = alexnet(num_classes=args.num_classes,
init_weights=args.init_weights)
else:
raise ValueError('Unsupported AlexNet depth!')
elif args.basenet == 'googlenet':
if args.depth == 0:
model = GoogLeNet(num_classes=args.num_classes,
pretrained=args.pretrained,
aux_logits=True,
init_weights=args.init_weights)
else:
raise ValueError('Unsupported GoogLeNet depth!')
elif args.basenet == 'vgg':
if args.depth == 11:
model = vgg11(pretrained=args.pretrained,
num_classes=args.num_classes,
init_weights=args.init_weights)
elif args.depth == 13:
model = vgg13(pretrained=args.pretrained,
num_classes=args.num_classes,
init_weights=args.init_weights)
elif args.depth == 16:
model = vgg16(pretrained=args.pretrained,
num_classes=args.num_classes,
init_weights=args.init_weights)
elif args.depth == 19:
model = vgg19(pretrained=args.pretrained,
num_classes=args.num_classes,
init_weights=args.init_weights)
else:
raise ValueError('Unsupported VGG depth!')
# Unfortunately for my resnet, there is no set init_weight, because I'm going to set object detection algorithm
elif args.basenet == 'resnet':
if args.depth == 18:
model = resnet18(pretrained=args.pretrained,
num_classes=args.num_classes)
elif args.depth == 34:
model = resnet34(pretrained=args.pretrained,
num_classes=args.num_classes)
elif args.depth == 50:
model = resnet50(pretrained=args.pretrained,
num_classes=args.num_classes) # False means the models was not trained
elif args.depth == 101:
model = resnet101(pretrained=args.pretrained,
num_classes=args.num_classes)
elif args.depth == 152:
model = resnet152(pretrained=args.pretrained,
num_classes=args.num_classes)
else:
raise ValueError('Unsupported ResNet depth!')
elif args.basenet == 'resnext':
if args.depth == 50:
model = resnext50_32x4d(pretrained=args.pretrained,
num_classes=args.num_classes)
elif args.depth == 101:
model = resnext101_32x8d(pretrained=args.pretrained,
num_classes=args.num_classes)
else:
raise ValueError('Unsupported ResNeXt depth!')
elif args.basenet == 'mobilenet':
if args.depth == 2:
model = MobileNet_v2(pretrained=args.pretrained,
num_classes=args.num_classes,
init_weights=args.init_weights)
else:
raise ValueError('Unsupported MobileNet depth!')
else:
raise ValueError('Unsupported model type!')
if args.cuda:
if torch.cuda.is_available():
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 6. Loading weights
if args.resume:
other, ext = os.path.splitext(args.resume)
if ext == '.pkl' or '.pth':
print('Loading weights into state dict...')
model_load = os.path.join(args.save_folder, args.resume)
model.load_state_dict(torch.load(model_load))
else:
print('Sorry only .pth and .pkl files supported.')
if args.init_weights:
# initialize newly added models' weights with xavier method
if args.basenet == 'resnet':
print("There is no set init_weight, because I'm going to set object detection algorithm.")
else:
print("Initializing weights...")
else:
print("Not Initializing weights...")
if args.pretrained:
if args.basenet == 'lenet' or args.basenet == 'alexnet':
print("There is no available pretrained model on the website. ")
else:
print("Models was pretrained...")
else:
print("Pretrained models is False...")
model.train()
iteration = 0
# 7. Optimizer
optimizer = optim.SGD(model.parameters(), lr=args.lr,
momentum=args.momentum, weight_decay=args.weight_decay)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(
optimizer, patience=args.patience, verbose=True)
scaler = GradScaler()
# 8. Length
iter_size = len(dataset) // args.batch_size
print("len(dataset): {}, iter_size: {}".format(len(dataset), iter_size))
logger.info(f"args - {args}")
t0 = time.time()
# 9. Create batch iterator
for epoch in range(args.epochs):
t1 = time.time()
model.training = True
torch.cuda.empty_cache()
# 10. Load train data
for data in dataloader:
iteration += 1
images, targets = data
# 11. Backward
optimizer.zero_grad()
if args.cuda:
images, targets = images.cuda(), targets.cuda()
criterion = criterion.cuda()
# 12. Forward
with autocast():
if args.basenet == 'googlenet':
outputs, aux2_output, aux1_output = model(images)
loss1 = criterion(outputs, targets)
loss_aux2 = criterion(aux2_output, targets)
loss_aux1 = criterion(aux1_output, targets)
loss = loss1 + loss_aux2 * 0.3 + loss_aux1 * 0.3
else:
outputs = model(images)
loss = criterion(outputs, targets)
loss = loss / args.accumulation_steps
if args.tensorboard:
writer.add_scalar("train_classification_loss", loss.item(), iteration)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
# 13. Measure accuracy and record loss
acc1, acc5 = accuracy(outputs, targets, topk=(1, 5))
top1.update(acc1.item(), images.size(0))
top5.update(acc5.item(), images.size(0))
losses.update(loss.item(), images.size(0))
if iteration % 100 == 0:
logger.info(
f"- epoch: {epoch}, iteration: {iteration}, lr: {optimizer.param_groups[0]['lr']}, "
f"top1 acc: {acc1.item():.2f}%, top5 acc: {acc5.item():.2f}%, "
f"loss: {loss.item():.3f}, (losses.avg): {losses.avg:3f} "
)
scheduler.step(losses.avg)
t2 = time.time()
h_time = (t2 - t1) // 3600
m_time = ((t2 - t1) % 3600) // 60
s_time = ((t2 - t1) % 3600) % 60
print("epoch {} is finished, and the time is {}h{}min{}s".format(epoch, int(h_time), int(m_time), int(s_time)))
# 14. Save train model
if epoch != 0 and epoch % 10 == 0:
print('Saving state, iter:', epoch)
torch.save(model.state_dict(),
args.save_folder + '/' + args.dataset +
'_' + args.basenet + str(args.depth) + '_' + repr(epoch) + '.pth')
torch.save(model.state_dict(),
args.save_folder + '/' + args.dataset + "_" + args.basenet + str(args.depth) + '.pth')
if args.tensorboard:
writer.close()
t3 = time.time()
h = (t3 - t0) // 3600
m = ((t3 - t0) % 3600) // 60
s = ((t3 - t0) % 3600) % 60
print("The Finished Time is {}h{}m{}s".format(int(h), int(m), int(s)))
return top1.avg, top5.avg, losses.avg
if __name__ == '__main__':
torch.multiprocessing.set_start_method('spawn')
logger.info("Program started")
top1, top5, loss = train()
print("top1 acc: {}, top5 acc: {}, loss:{}".format(top1, top5, loss))
logger.info("Done!")测试代码
import logging
import os
import argparse
import warnings
warnings.filterwarnings('ignore')
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
sys.path.append(BASE_DIR)
import time
from data import *
from PIL import Image
import torch.nn.parallel
from torchvision import transforms
from utils.get_logger import get_logger
from models.basenets.lenet5 import lenet5
from models.basenets.alexnet import alexnet
from models.basenets.vgg import vgg11, vgg13, vgg16, vgg19
from models.basenets.googlenet import googlenet, GoogLeNet
from models.basenets.mobilenet_v2 import mobilenet_v2, MobileNet_v2
from models.basenets.resnet import resnet18, resnet34, resnet50, resnet101, resnet152, resnext50_32x4d, resnext101_32x8d
def parse_args():
parser = argparse.ArgumentParser(description='PyTorch Classification Testing')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset',
type=str,
default='ImageNet',
choices=['ImageNet', 'CIFAR'],
help='ImageNet, CIFAR')
parser.add_argument('--images_root',
type=str,
default=config.images_cls_root,
help='Dataset root directory path')
parser.add_argument('--basenet',
type=str,
default='resnext',
choices=['resnet', 'vgg', 'lenet', 'alexnet', 'googlenet', 'mobilenet', 'resnext'],
help='Pretrained base model')
parser.add_argument('--depth',
type=int,
default=50,
help='BaseNet depth, including: LeNet of 5, AlexNet of 0, VGG of 11, 13, 16, 19, ResNet of 18, 34, 50, 101, 152, GoogLeNet of 0, MobileNet of 2, 3,ResNeXt of 50, 101')
parser.add_argument('--evaluate',
type=str,
default=config.classification_evaluate,
help='Checkpoint state_dict file to evaluate training from')
parser.add_argument('--save_folder',
type=str,
default=config.checkpoint_path,
help='Directory for saving checkpoint models')
parser.add_argument('--log_folder',
type=str,
default=config.log,
help='Log Folder')
parser.add_argument('--log_name',
type=str,
default=config.classification_test_log,
help='Log Name')
parser.add_argument('--cuda',
type=str,
default=True,
help='Use CUDA to train model')
parser.add_argument('--num_classes',
type=int,
default=1000,
help='the number classes, like ImageNet:1000, cifar:10')
parser.add_argument('--image_size',
type=int,
default=224,
help='image size, like ImageNet:224, cifar:32')
return parser.parse_args()
args = parse_args()
# 1. Torch choose cuda or cpu
if torch.cuda.is_available():
if args.cuda:
torch.set_default_tensor_type('torch.cuda.FloatTensor')
if not args.cuda:
print("WARNING: It looks like you have a CUDA device, but you aren't using it" +
"\n You can set the parameter of cuda to True.")
torch.set_default_tensor_type('torch.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
if not os.path.exists(args.save_folder):
os.mkdir(args.save_folder)
# 2. Log
get_logger(args.log_folder, args.log_name)
logger = logging.getLogger(args.log_name)
def get_label_file(filename):
if not os.path.exists(filename):
print("The dataset label.txt is empty, We need to create a new one.")
os.mkdir(filename)
return filename
def dataset_labels_results(filename, output):
filename = os.path.join(BASE_DIR, 'data', filename + '_labels.txt')
get_label_file(filename=filename)
with open(file=filename, mode='r') as f:
dict = f.readlines()
output = output.cpu().numpy()
output = output[0]
output = dict[output]
f.close()
return output
def test():
# vgg16, alexnet and lenet5 need to resize image_size, because of fc.
if args.basenet == 'vgg' or args.basenet == 'alexnet' or args.basenet == 'googlenet':
args.image_size = 224
elif args.basenet == 'lenet':
args.image_size = 32
# 3. Ready image
if args.images_root is None:
raise ValueError("The images is None, you should load image!")
image = Image.open(args.images_root)
transform = transforms.Compose([
transforms.Resize((args.image_size,
args.image_size)),
transforms.ToTensor()])
image = transform(image)
image = image.reshape(1, 3, args.image_size, args.image_size)
# 4. Define to train mode
if args.basenet == 'lenet':
if args.depth == 5:
model = lenet5(num_classes=args.num_classes)
else:
raise ValueError('Unsupported LeNet depth!')
elif args.basenet == 'alexnet':
if args.depth == 0:
model = alexnet(num_classes=args.num_classes)
else:
raise ValueError('Unsupported AlexNet depth!')
elif args.basenet == 'googlenet':
if args.depth == 0:
model = googlenet(num_classes=args.num_classes,
aux_logits=False)
else:
raise ValueError('Unsupported GoogLeNet depth!')
elif args.basenet == 'vgg':
if args.depth == 11:
model = vgg11(num_classes=args.num_classes)
elif args.depth == 13:
model = vgg13(num_classes=args.num_classes)
elif args.depth == 16:
model = vgg16(num_classes=args.num_classes)
elif args.depth == 19:
model = vgg19(num_classes=args.num_classes)
else:
raise ValueError('Unsupported VGG depth!')
elif args.basenet == 'resnet':
if args.depth == 18:
model = resnet18(num_classes=args.num_classes)
elif args.depth == 34:
model = resnet34(num_classes=args.num_classes)
elif args.depth == 50:
model = resnet50(num_classes=args.num_classes) # False means the models is not trained
elif args.depth == 101:
model = resnet101(num_classes=args.num_classes)
elif args.depth == 152:
model = resnet152(num_classes=args.num_classes)
else:
raise ValueError('Unsupported ResNet depth!')
elif args.basenet == 'resnext':
if args.depth == 50:
model = resnext50_32x4d(num_classes=args.num_classes)
elif args.depth == 101:
model = resnext101_32x8d(num_classes=args.num_classes)
else:
raise ValueError('Unsupported ResNeXt depth!')
elif args.basenet == 'mobilenet':
if args.depth == 2:
model = mobilenet_v2(num_classes=args.num_classes)
else:
raise ValueError('Unsupported MobileNet depth!')
else:
raise ValueError('Unsupported model type!')
if args.cuda:
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 5. Loading model
if args.evaluate:
other, ext = os.path.splitext(args.evaluate)
if ext == '.pkl' or '.pth':
print('Loading weights into state dict...')
model_evaluate_load = os.path.join(args.save_folder, args.evaluate)
model_evaluate_load = torch.load(model_evaluate_load)
if args.basenet == 'googlenet':
model_evaluate_load = {k: v for k, v in model_evaluate_load.items() if "aux" not in k}
model.load_state_dict(model_evaluate_load)
else:
print('Sorry only .pth and .pkl files supported.')
elif args.evaluate is None:
print("Sorry, you should load weights! ")
model.eval()
# 6. print
logger.info(f"args - {args}")
# 7. Test
with torch.no_grad():
t0 = time.time()
# 8. Forward
if args.cuda:
image = image.cuda()
output = model(image)
output = output.argmax(1)
t1 = time.time()
m = (t1 - t0) // 60
s = (t1 - t0) % 60
folder_name = args.dataset
output = dataset_labels_results(filename=folder_name, output=output)
logger.info(f"output: {output}")
print("It took a total of {}m{}s to complete the testing.".format(int(m), int(s)))
return output
if __name__ == '__main__':
torch.multiprocessing.set_start_method('spawn')
logger.info("Program started")
output = test()
logger.info("Done!")评估代码
import os
import logging
import argparse
import warnings
warnings.filterwarnings('ignore')
import sys
BASE_DIR = os.path.dirname(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
sys.path.append(BASE_DIR)
import time
import torch
from data import *
import torchvision
import torch.nn.parallel
from torchvision import transforms
from utils.accuracy import accuracy
from utils.get_logger import get_logger
from torch.utils.data import DataLoader
from models.basenets.lenet5 import lenet5
from models.basenets.alexnet import alexnet
from utils.AverageMeter import AverageMeter
from models.basenets.vgg import vgg11, vgg13, vgg16, vgg19
from models.basenets.googlenet import googlenet, GoogLeNet
from models.basenets.mobilenet_v2 import mobilenet_v2, MobileNet_v2
from models.basenets.resnet import resnet18, resnet34, resnet50, resnet101, resnet152, resnext50_32x4d, resnext101_32x8d
def parse_args():
parser = argparse.ArgumentParser(description='PyTorch Classification Evaluation')
parser.add_mutually_exclusive_group()
parser.add_argument('--dataset',
type=str,
default='ImageNet',
choices=['ImageNet', 'CIFAR'],
help='ImageNet,CIFAR')
parser.add_argument('--dataset_root',
type=str,
default=ImageNet_Eval_ROOT,
choices=[ImageNet_Eval_ROOT, CIFAR_ROOT],
help='Dataset root directory path')
parser.add_argument('--basenet',
type=str,
default='resnext',
choices=['resnet', 'vgg', 'lenet', 'alexnet', 'googlenet', 'resnext'],
help='Pretrained base model')
parser.add_argument('--depth',
type=int,
default=50,
help='BaseNet depth, including: LeNet of 5, AlexNet of 0, VGG of 11, 13, 16, 19, ResNet of 18, 34, 50, 101, 152, GoogLeNet of 0,ResNext of 50, 101')
parser.add_argument('--batch_size',
type=int,
default=32,
help='Batch size for training')
parser.add_argument('--evaluate',
type=str,
default=config.classification_evaluate,
help='Checkpoint state_dict file to evaluate training from')
parser.add_argument('--num_workers',
type=int,
default=8,
help='Number of workers user in dataloading')
parser.add_argument('--cuda',
type=str,
default=True,
help='Use CUDA to eval model')
parser.add_argument('--save_folder',
type=str,
default=config.checkpoint_path,
help='Directory for saving checkpoint models')
parser.add_argument('--log_folder',
type=str,
default=config.log,
help='Log Folder')
parser.add_argument('--log_name',
type=str,
default=config.classification_eval_log,
help='Log Name')
parser.add_argument('--num_classes',
type=int,
default=1000,
help='the number classes, like ImageNet:1000, cifar:10')
parser.add_argument('--image_size',
type=int,
default=224,
help='image size, like ImageNet:224, cifar:32')
return parser.parse_args()
args = parse_args()
# 1. Torch choose cuda or cpu
if torch.cuda.is_available():
if args.cuda:
torch.set_default_tensor_type('torch.cuda.FloatTensor')
if not args.cuda:
print("WARNING: It looks like you have a CUDA device, but you aren't using it" +
"\n You can set the parameter of cuda to True.")
torch.set_default_tensor_type('torch.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
if os.path.exists(args.save_folder) is None:
os.mkdir(args.save_folder)
# 2. Log
get_logger(args.log_folder, args.log_name)
logger = logging.getLogger(args.log_name)
def eval():
# vgg16, alexnet and lenet5 need to resize image_size, because of fc.
if args.basenet == 'vgg' or args.basenet == 'alexnet' or args.basenet == 'googlenet':
args.image_size = 224
elif args.basenet == 'lenet':
args.image_size = 32
# 3. Ready dataset
if args.dataset == 'ImageNet':
if args.dataset_root == CIFAR_ROOT:
raise ValueError("Must specify dataset_root if specifying dataset ImageNet")
elif os.path.exists(ImageNet_Eval_ROOT) is None:
raise ValueError("WARNING: Using default ImageNet dataset_root because " +
"--dataset_root was not specified.")
dataset = torchvision.datasets.ImageFolder(
root=args.dataset_root,
transform=torchvision.transforms.Compose([
transforms.Resize((args.image_size,
args.image_size)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
]))
elif args.dataset == 'CIFAR':
if args.dataset_root == ImageNet_Eval_ROOT:
raise ValueError('Must specify dataset_root if specifying dataset CIFAR')
elif args.dataset_root is None:
raise ValueError("Must provide --dataset_root when training on CIFAR")
dataset = torchvision.datasets.CIFAR10(
root=args.dataset_root, train=False,
transform=torchvision.transforms.Compose([
transforms.Resize((args.image_size,
args.image_size)),
torchvision.transforms.ToTensor()]))
else:
raise ValueError('Dataset type not understood (must be ImageNet or CIFAR), exiting.')
dataloader = torch.utils.data.DataLoader(dataset=dataset, batch_size=args.batch_size,
shuffle=True, num_workers=args.num_workers,
pin_memory=False, generator=torch.Generator(device='cuda'))
top1 = AverageMeter()
top5 = AverageMeter()
# 4. Define to mode
if args.basenet == 'lenet':
if args.depth == 5:
model = lenet5(num_classes=args.num_classes)
else:
raise ValueError('Unsupported LeNet depth!')
elif args.basenet == 'alexnet':
if args.depth == 0:
model = alexnet(num_classes=args.num_classes)
else:
raise ValueError('Unsupported AlexNet depth!')
elif args.basenet == 'googlenet':
if args.depth == 0:
model = googlenet(num_classes=args.num_classes,
aux_logits=False)
else:
raise ValueError('Unsupported GoogLeNet depth!')
elif args.basenet == 'vgg':
if args.depth == 11:
model = vgg11(num_classes=args.num_classes)
elif args.depth == 13:
model = vgg13(num_classes=args.num_classes)
elif args.depth == 16:
model = vgg16(num_classes=args.num_classes)
elif args.depth == 19:
model = vgg19(num_classes=args.num_classes)
else:
raise ValueError('Unsupported VGG depth!')
elif args.basenet == 'resnet':
if args.depth == 18:
model = resnet18(num_classes=args.num_classes)
elif args.depth == 34:
model = resnet34(num_classes=args.num_classes)
elif args.depth == 50:
model = resnet50(num_classes=args.num_classes) # False means the models is not trained
elif args.depth == 101:
model = resnet101(num_classes=args.num_classes)
elif args.depth == 152:
model = resnet152(num_classes=args.num_classes)
else:
raise ValueError('Unsupported ResNet depth!')
elif args.basenet == 'resnext':
if args.depth == 50:
model = resnext50_32x4d(num_classes=args.num_classes)
elif args.depth == 101:
model = resnext101_32x8d(num_classes=args.num_classes)
else:
raise ValueError('Unsupported ResNeXt depth!')
elif args.basenet == 'mobilenet':
if args.depth == 2:
model = mobilenet_v2(num_classes=args.num_classes)
else:
raise ValueError('Unsupported MobileNet depth!')
else:
raise ValueError('Unsupported model type!')
if args.cuda:
if torch.cuda.is_available():
model = model.cuda()
model = torch.nn.DataParallel(model).cuda()
else:
model = torch.nn.DataParallel(model)
# 5. Loading model
if args.evaluate:
other, ext = os.path.splitext(args.evaluate)
if ext == '.pkl' or '.pth':
print('Loading weights into state dict...')
model_evaluate_load = os.path.join(args.save_folder, args.evaluate)
model_evaluate_load = torch.load(model_evaluate_load)
if args.basenet == 'googlenet':
model_evaluate_load = {k: v for k, v in model_evaluate_load.items() if "aux" not in k}
model.load_state_dict(model_evaluate_load)
else:
print('Sorry only .pth and .pkl files supported.')
elif args.evaluate is None:
raise ValueError("Sorry, you should load weights! ")
model.eval()
# 6. Length
iter_size = len(dataset) // args.batch_size
print("len(dataset): {}, iter_size: {}".format(len(dataset), iter_size))
logger.info(f"args - {args}")
t0 = time.time()
iteration = 0
# 7. Test
with torch.no_grad():
torch.cuda.empty_cache()
# 8. Load test data
for data in dataloader:
iteration += 1
images, targets = data
if args.cuda:
images, targets = images.cuda(), targets.cuda()
# 9. Forward
outputs = model(images)
# 10. measure accuracy and record loss
acc1, acc5 = accuracy(outputs, targets, topk=(1, 5))
top1.update(acc1.item(), images.size(0))
top5.update(acc5.item(), images.size(0))
logger.info(
f"iteration: {iteration}, top1 acc: {acc1.item():.2f}%, top5 acc: {acc5.item():.2f}%. ")
t1 = time.time()
m = (t1 - t0) // 60
s = (t1 - t0) % 60
print("It took a total of {}m{}s to complete the evaluating.".format(int(m), int(s)))
return top1.avg, top5.avg
if __name__ == '__main__':
torch.multiprocessing.set_start_method('spawn')
logger.info("Program started")
top1, top5 = eval()
print("top1 acc: {}, top5 acc: {}".format(top1, top5))
logger.info("Done!")
运行结果
5.ResNeXt
basenet: resnext50_32x4d
dataset: ImageNet
batch_size: 32
optim: SGD
lr: 0.001
momentum: 0.9
weight_decay: 1e-4
scheduler: ReduceLROnPlateau
patience: 2
epoch: 30
pretrained: True| No.epoch | times/eopch | top1 acc (%) | top5 acc (%) |
|---|---|---|---|
| 7 | 4h5min16s | 72.28 | 91.56 |
6.GoogLeNet
basenet: GoogLeNet
dataset: ImageNet
batch_size: 32
optim: SGD
lr: 0.01
momentum: 0.9
weight_decay: 1e-4
scheduler: MultiStepLR
milestones: [15, 20, 30]
gamma: 0.1
epoch: 30| No.epoch | times/epoch | top1 acc (%) | top5 acc (%) |
|---|---|---|---|
| 5 | 3h59min21s | 37.50 | 65.62 |
or
basenet: GoogLeNet
dataset: ImageNet
batch_size: 32
optim: SGD
lr: 0.01
momentum: 0.9
weight_decay: 1e-4
scheduler: ReduceLROnPlateau
patience: 2
epoch: 30
pretrained: True| No.epoch | times/eopch | top1 acc (%) | top5 acc (%) |
|---|---|---|---|
| 5 | 3h54min31s | 42.70 | 69.34 |
7.MobileNet
7.1.MobileNet_v2
basenet: MobileNet_v2
dataset: ImageNet
batch_size: 32
optim: SGD
lr: 0.001
momentum: 0.9
weight_decay: 1e-4
scheduler: ReduceLROnPlateau
patience: 2
epoch: 30
pretrained: True| No.epoch | times/epoch | top1 acc (%) | top5 acc (%) |
|---|---|---|---|
| 5 | 3h58min3s | 66.90 | 88.19 |
下一话