一、引言
一个电商系统,存放了10万多条商品数据,每次用户浏览商品详情页时,需要先从数据库读取数据,再进行数据拼装和计算,,耗费的时间有时长达1s。从而导致页面打开速度慢。
面对这种问题,我们应该如何解决?
二、本地缓存
关于缓存问题,最简单的实现方法是使用本地缓存。在Google Guava中有一个cache内存缓存模型,它把所有商品的ID与商品详情信息一对一缓存在JVM内存中,用户获取商品详情数据时,系统会根据商品ID直接从缓存中读取数据,大大提升了用户界面访问速度。
咋一看,实现流程似乎简单、实用,不过,这种方式有个坑。我们来挖挖看下这个坑在哪:
假设1条商品数据中,包含品牌、分类、参数、规格、服务、描述等字段,光存储这些商品数据就需要占用500K左右内存;将这些数据缓存到本地的话,500Kx10万=50G内存。如果商品服务有30个服务器节点,单单缓存商品数据就需要额外准备 50Gx30= 1500G 内存空间。
经过简单换算,我们发现,该方法占用内存巨大,明显不合理。
三、分布式缓存
分布式缓存:
1)先将所有的缓存数据集中存储在同一个地方,而并非保存到各个服务器节点中;
2)然后所有的服务器节点从这个地方读取数据。

缓存中间件技术选型
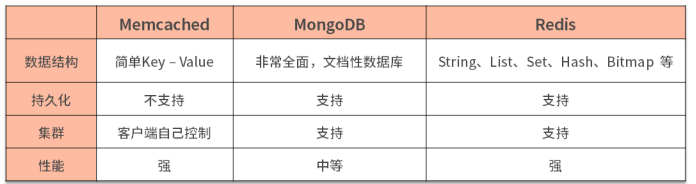
上图是目前比较流行的缓存中间件的简单比对。市面上通用的缓存中间件技术是Redis,使用MongoDB的公司最少,因为它只是一个数据库,由于它的读写速度与其他数据库相比较快,所以大家才把它当作类似缓存的存储。
Redis比memcached流行的原因有3
1)数据结构
Redis操作比Memcached简单快捷。
假设:要往List添加一条数据
使用Memcached:首先需要读取整个List,再反序列塞入数据,接着再序列化存储回Memcached。
使用Redis:仅仅需要给Redis发送一个请求,Redis会直接帮我们塞入数据并存储。
2)持久化
Memcached一旦宕机,数据就会丢失。
1.5.18以后Memcached支持restartable cache,其实现原理是重启时CLI先发信号给守护进程,然后守护进程将内存持久化至一个文件中,系统重启时再从那个文件恢复数据。不过,这个设计在正常重启情况下使用,意外情况还是没法处理。
Redis的持久化有两种模式:AOF和RDB,默认开启RDB。
具体可参考:Redis持久化原理和应用
3)集群(重点分水岭)
Memcached的集群设计非常简单,客户端根据hash值直接判断存取的Memcached节点。而Redis的集群在高可用、主从、冗余、failover等方面都有考虑,因此集群设计相对复杂些,数据较常规的分布式高可用架构。
四、缓存何时存储数据
想要知道缓存什么时候存储数据,我们需要先了解缓存的使用逻辑。
使用缓存的逻辑:
先尝试从缓存中读取数据–>缓存中没有数据或数据过期,再从数据库中读取数据保存到缓存中–>最终把缓存数据返回给调用方。
上述逻辑的问题:当用户发来大量的并发请求,且所有请求同时拥挤在上面的第2步,此时如果数据都从数据库读取,会直接挤爆数据库。
挤爆数据库有3种情况:
1)单一数据过期或不存在,这种情况称为缓存击穿
解决方案:第一线程如果发现key不存在,先给key加锁, 再从数据库读取数据保存到缓存中,最后释放。
2)数据大面积过期或Redis宕机,这种情况称为缓存雪崩
解决方案:设置缓存的过期时间随机分布,或永不过期。
3)一个恶意请求获取的key不在数据库中,这种情况称为还缓存穿透
解决方案1:在业务逻辑上直接校验,在数据库不被访问的前提下过滤掉不存在的key;
解决方案2:将恶意请求的key存放在一个空值在缓存中,防止恶意请求骚扰数据库。
缓存预热:在深夜无人或访问量小的时候,可以用考虑将预热的数据保存到缓存中,这样流量大的时候,用户查询无需再从数据库读取数据,大大减少了数据读压力。
五、如何更新缓存
简单概括为两步:更新数据库,更新缓存。
需要注意的是:更新需要考虑以下几个问题:
1)先更新数据库还是先更新缓存?更新缓存时先删除还是直接更新?
2)假设第一步成功了,第二步失败怎么办?
3)假设2个线程同时更新同一个数据,A线程先完成第一步,B线程先完成第二步,怎么办?
下面针对上面几个问题进行讨论:
组合1:先更新缓存,再更新数据库
会遇到的情况:数据库更新失败,要求回滚缓存的更新,此时应该怎么办?
Redis不支持事务回滚,除非采用手工回滚方式,先保存原有数据,然后再将缓存还原到原来的数据,这种方案比较尴尬。
举个栗子:
–>原缓存的值是a, 两个线程同事更新库存
–> 线程A将缓存中的值更新为b,且保存了原来的a值,然后更新数据库
–> 线程B将缓存中的值更新为c,且保存了原来的b值,然后更新数据库
–> 线程A更新数据库失败了,它必须回滚,现在缓存的值更新回什么呢?
你可能会想到,A线程更新缓存与数据库整个过程中,先把缓存及数据库都锁上,确保别人不能更新,这种方法是否可行?当然可以,不过别人能不能读呢?
假设A更新数据库失败回滚缓存时,线程C也来参一腿,它需要先读取缓存中的值,这时又返回什么值呢?
这就是典型的事务隔离级别场景。话说,我们只是用一下缓存而已,你让我自己实现事务隔离级别,要求是不是有点高?
组合2:先删除缓存,再更新数据库
使用这种方案,即使更新数据库失败了,也不需要回滚缓存。不过带来两个问题:
–> 假设 A 线程先删除缓存,再更新数据库。在 A 线程完成更新数据库之前,后执行的 B 线程反而超前完成了操作,读取 key 发现没数据后,将数据库中的旧值存放到了缓存中。A 线程在 B 线程都完成后再更新数据库,这样就会出现缓存(旧值)与数据库的值(新值)不一致的问题。
–> 为了解决一致性问题,我们可以让 A 线程给 key 加锁,因为写操作特别耗时,这种处理方法会导致大量的读请求卡在锁中。
以上描述的是典型的高可用和一致性难以两全的问题,要再加上分区容错就是CAP了。
组合3:先更新数据库,再更新缓存
这种方案,同样要考虑两个问题:
–> 假设第一步成功,第二步失败了怎么办?因为缓存不是主流程,数据库才是,所以我们不会因为更新缓存失败而回滚第一步对数据库的更新。此时,我们一般采取的做法是做重试机制,但重试机制如果存在延时还是会出现数据库与缓存不一致的情况。
–> 假设 2 个线程同时更新同一个数据,A 线程先完成了第一步,B 线程先完成了第二步怎么办?推演过程:A 线程把值更新成 a,B 线程把值更新成 b,此时数据库中的最新值是 b,因为 A 线程先完成了第一步,后完成第二步,所以缓存中的最新值是 a,数据库与缓存的值还是不一致。
组合4:先更新数据库,再删除缓存
该方案,同样要考虑下面两个问题:
–> 假设第一步成功了,第二步失败了怎么办?还是有概率被读取到缓存数据与数据库数据不一致的问题,虽然删除的成功率高。
–> 假设2个线程同时更新同一个数据,A线程先完成第一步,B线程先完成第二步怎么办?
推演整个过程:A 线程把值更新成 a,B 线程把值更新成 b,此时数据库中的最新值是 b,因为 A 线程先完成第一步,至于第二步谁先完成已经无所谓了,反正是直接删除缓存数据。
组合分析结果
组合4相对较好的解决了一些其他组合的问题,建议使用组合4。不过组合4也存在一些问题:
- 删除缓存数据后变相出现u俺村击穿(解决方案看前文);
- 删除缓存失败如何重试?
- 删除缓存失败,重试成功前出现脏数据。
如果对缓存高可用有需求,可以使用Redis的Cluster模式。