文章目录
一、先介绍几个概念
1、什么是当前读

当前读就是加了锁的增删改查语句
2、什么是快照读
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VBOB0mpv-1587714794974)(C:\Users\Taogege\AppData\Roaming\Typora\typora-user-images\image-20200422190432323.png)]](https://img-blog.csdnimg.cn/20200424164455513.png)
快照读读到的有可能不是数据的最新版本,可能是之前的历史版本
3、什么是mvcc
mvcc全称是multi version concurrent control(多版本并发控制)。mysql把每个操作都定义成一个事务,每开启一个事务,系统的事务版本号自动递增。每行记录都有两个隐藏列:创建版本号和删除版本号
二、RR级别下避免幻读的方法
- 表象:快照读(非阻塞读)–InnoDB实现了伪MVCC来避免幻读。
- 内在:next-key锁(X锁+gap锁),当前读情况下通过next-key锁避免幻读
三、RC级别下测试快照读和当前读
创建表如下(account_innodb):
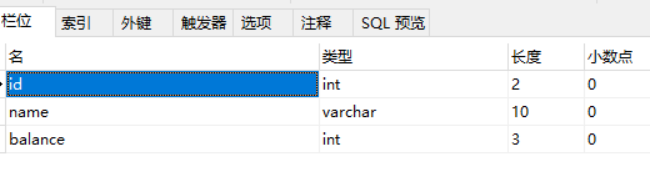
添加数据如下
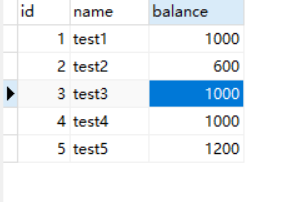
开启两个查询,会话1和会话2,两个都取消自动提交:set autocommit = 0;,都开启事务:start TRANSACTION;
3.1、测试快照读
会话1开启事务后执行以下sql:
select * from account_innodb where id = 2;
然后会话2对该记录进行更新并提交
update account_innodb set balance = 700 where id = 2;
COMMIT;
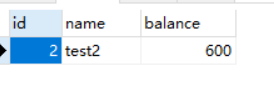
然后再用会话1查询得出:

3.2、测试当前读
与快照读有一点不同的是select加上了共享锁,紧接着上边的操作,快照读查询完后,用当前读查询一遍:
select * from account_innodb where id = 2 lock in share mode;
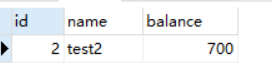
可见RC下的快照读和当前读查询结果是一样的
四、RR级别下测试快照读和当前读
操作与上边差不多,新建两个查询,自动提交关闭掉,将隔离级别调整为repeatable read,mysql默认的级别就是这个,然后开启事务:start TRANSACTION;
会话1
select * from account_innodb where id = 2;
结果为:
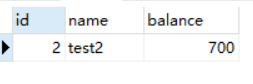
然后我们会话2来更新数据:select * from account_innodb where id = 2;并提交事务,然后会到会话1用快照读
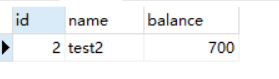
发现是原数据,我们再用当前读:select * from account_innodb where id = 2 lock in share mode;
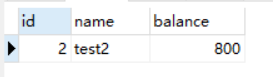
发现是刚刚更新的数据
那RR级别下的快照读能读到最新的数据吗?肯定可以
还是上边的基础,即RR级别,先关闭掉两个会话的事务,重新开启事务,直接执行会话2
update account_innodb set balance = 900 where id = 2;
commit;
然后回到会话1,执行快照读:select * from account_innodb where id = 2;,得到结果:
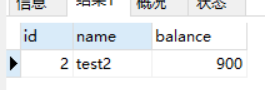
是更新后的数据,再执行以下当前读:select * from account_innodb where id = 2 lock in share mode;
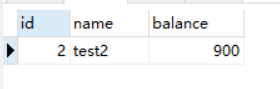
结果一样,到了这一步不难想到,RR级别下的快照读跟他什么时候执行有关,先这么说,后边详细解释
五、RC、RR级别下的InnoDB的非阻塞读(快照读)如何实现主要
主要靠下边三点:

一个事务的情况下的undo log存储情况
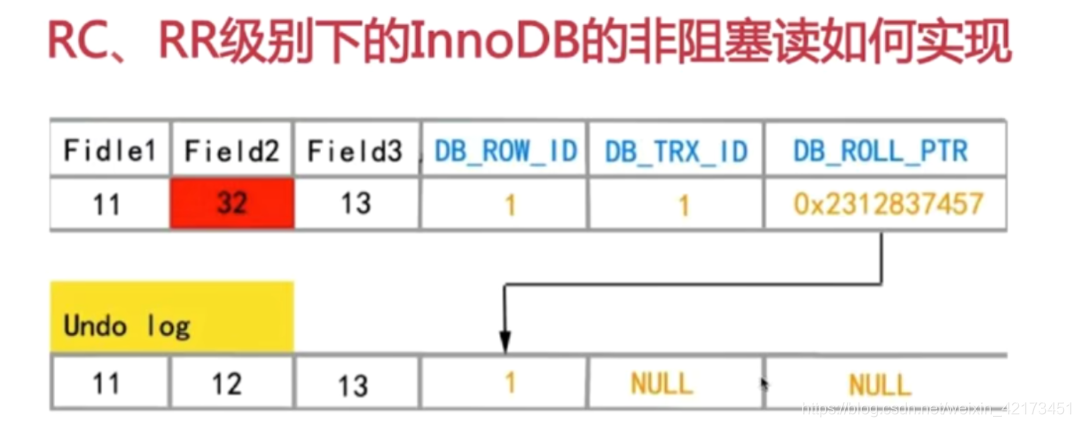
第一行右边的三个字段是关键:
- DB_ROW_ID(标识插入的新的数据行的id)
- DB_TRX_ID(事务ID)
- DB_ROLL_PTR(回滚指针)指向Undo log中的数据行
可以看到在Field2的数据进行更新之前,数据库会将更新之前的数据复制进update(包含update/delete) Undo log中,快照读通过DB_ROLL_PTR指针读取之前的数据行,这样一来,快照读每次读的就是更新前的稳定数据,可以用来表象上避免幻读,有的朋友可能会问,RC级别为什么不能避免,我们后边会说。
undo log是干什么的
undo日志用于存放数据修改被修改前的值,假设修改 tba 表中 id=2的行数据,把Name=‘B’ 修改为Name = ‘B2’ ,那么undo日志就会用来存放Name='B’的记录,如果这个修改出现异常,可以使用undo日志来实现回滚操作,保证事务的一致性。
read view呢
- Read View就是事务进行快照读操作的时候生产的读视图(Read View),在该事务执行的快照读的那一刻,会生成数据库系统当前的一个快照,记录并维护系统当前活跃事务的ID(当每个事务开启时,都会被分配一个ID, 这个ID是递增的,所以最新的事务,ID值越大)
- 它决定的是当前事务能看到的是哪个事务操作前的数据。它遵循一个可见性算法:将要修改的数据事务的DB_TRX_ID取出来与系统其它事务活跃ID做对比,如果大于或者等于这些ID,那么就取出当前DB_TRX_ID的事务的DB_ROLL_PTR指针所指向的undo log的版本数据,直到DB_TRX_ID小于这些系统活跃事务的ID,这样即可取到稳定的数据。注意(每当进入一个transaction时,事务ID就会增大)。
示意图如下图——多个事务操作,undo log 数据存储图:

多个事务操作就会有数据的多个版本,如上图,第二行在被第二个事务修改前要将数据拷贝到Undo log中并有指针指向。可以说DB_ROLL_PTR是连接undo版本数据的关键。
下面解释一下前边的问题:为什么RC、RR级别下的快照读有区别
在RC级别下,快照读每调用一次,那么以上的Undo log操作就会执行一次,里面的版本数据就会更新到最新。而在RR级别下,我们第一次调用快照读,创建了Undo log,后边是不会再执行,直到提交事务,譬如我们上边的RR测试,先执行一次快照读,再更新一次,然后再读,还是之前的数据,有心的朋友可以继续更新一次提交,然后回到会话1再进行一次快照读,还是最开始的数据,从而达到避免幻读,所以对于RR级别来说,其第一次快照读的时机很重要。这也是为什么RC不可以避免幻读的原因。
以上都是表象部分,只不过是先进行增删改事务,导致read view的能获取到的是可见性版本内的数据,InnoDB的RR及以上级别避免幻读的内在是next-key锁。还有SERIALIZABLE隔离级别的快照读可不像其他级别那样无阻塞,这里的快照读是要上共享锁的,所以下面还是要说一下next-key(行锁+gap锁)
六、next-key(行锁+gap锁)
行锁我们都知道,那么gap锁是什么?
gap锁是间隙锁,即锁定一个范围,但不包括记录本身,它的目的是为了防止事务的两次当前读产生幻读
gap锁上锁条件:
- 如果where条件全部命中,则不会用Gap锁,只会加记录锁
- 如果where条件部分命中或者全不命中,则会加Gap锁
- 如果sql走的是非唯一索引或者不走索引,则会加Gap锁
下边我们进行测试
建立表tb:
SET FOREIGN_KEY_CHECKS=0;
-- ----------------------------
-- Table structure for tb
-- ----------------------------
DROP TABLE IF EXISTS `tb`;
CREATE TABLE `tb` (
`name` varchar(10) NOT NULL,
`id` int(100) NOT NULL DEFAULT '0',
PRIMARY KEY (`name`),
UNIQUE KEY `unique_id` (`id`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
(数据自拟),我的是:
创建两个session,隔离级别默认RR,都开启事务
6.1、测试sql走唯一索引,并精准命中
session1:
# 检测是否走的唯一键
explain delete from tb where id = 8;

然后我们测试执行该sql,然后在其前后插入数据,看有没有间隙锁存在
session1:
delete from tb where id = 8;
session2:
insert into tb values('ii',9);

插入成功,说明没有gap锁
6.2、测试部分命中、精准命中(不存在的值)、精确命中全部数据
session1和session2 rollback,然后开启事务
- 先测试不存在的记录:
session1
delete from tb where id = 13;
session2
insert into tb values('i',14);
# 结果被阻塞
说明不存在的值,等于没有被命中,要上Gap锁
- 部分命中测试
为了方便测试我们删除数据id=6
session1
select * from tb where id in (5,6,8) lock in share mode;
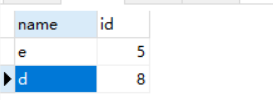
session2:
insert into tb values('i',4);
# 插入成功
insert into tb values('ii',7);
# 7插入失败,被阻塞
insert into tb values('ii',6);
# 6插入失败,被阻塞
insert into tb values('ii',6);
# 9插入成功
总结:部分命中的话,也是中间部分加锁
- 精确命中全部数据测试
回滚之前事务,并开启事务
session1
select * from tb where id in (5,6,9) lock in share mode;

session2
insert into tb values('iii',7);
# 插入成功
insert into tb values('iii',8);
# 插入成功
总结:全部命中不会上Gap锁
验证了前面的两点总结
6.3、Gap锁用在非唯一索引或者不走索引的当前读
图示

我们可以看到,上图下边显示的是间隙,真正上Gap锁的部分是(6,9]和(9,11],遵循左开右闭原则,凡是插入的id在区间之中都被阻塞,还有边界情况,比如(6,a)是可以插入的,因为a的ASCII码在c的前面,(6,dd)是不可以插入的,道理一样,(11,h)可以插入,(11,a)就不行,可能有人会说(9,c)不在范围里面啊,但是也不行,因为id=9上了行锁,专门应对这种情况。这一部分我就不举例了,挺详细的了,可以自己测试一下。
如有问题,请及时指出
