文章目录
树是一种重要的数据结构。
可能大家一开始接触树的时候觉得树这个东西好难理解,觉得不好操作,但其实在现实世界中有许多食物都用到了树这种数据结构。
比如说一个国家下面有许多的省或市,省下面有县,县下面又分区等等,它们之间都是一种层次的关系。
还有比如说硬盘管理,C盘下面又一些文件,这些文件下面又有一些子目录,这也是一种层次关系。
对数据管理涉及的三个最典型的操作:插入,删除,查找。
树的定义
树:n(n>=0)个结点构成的有限集合。
当n=0时,树中没有结点,称为空树。
对于任意一棵非空树,都具有如下性质:
- 树中有一个根结点
- 其余结点可分为m个互不相交的有限集,每个集合本身也是一棵树,称为原来树的子树。
- 子树是不可以相交的。
- 除了根结点外,每个结点有且仅有一个父结点。
- 一棵有n个结点的树,有n-1条边。因为每个结点都有一条指向它的边,除了根结点。
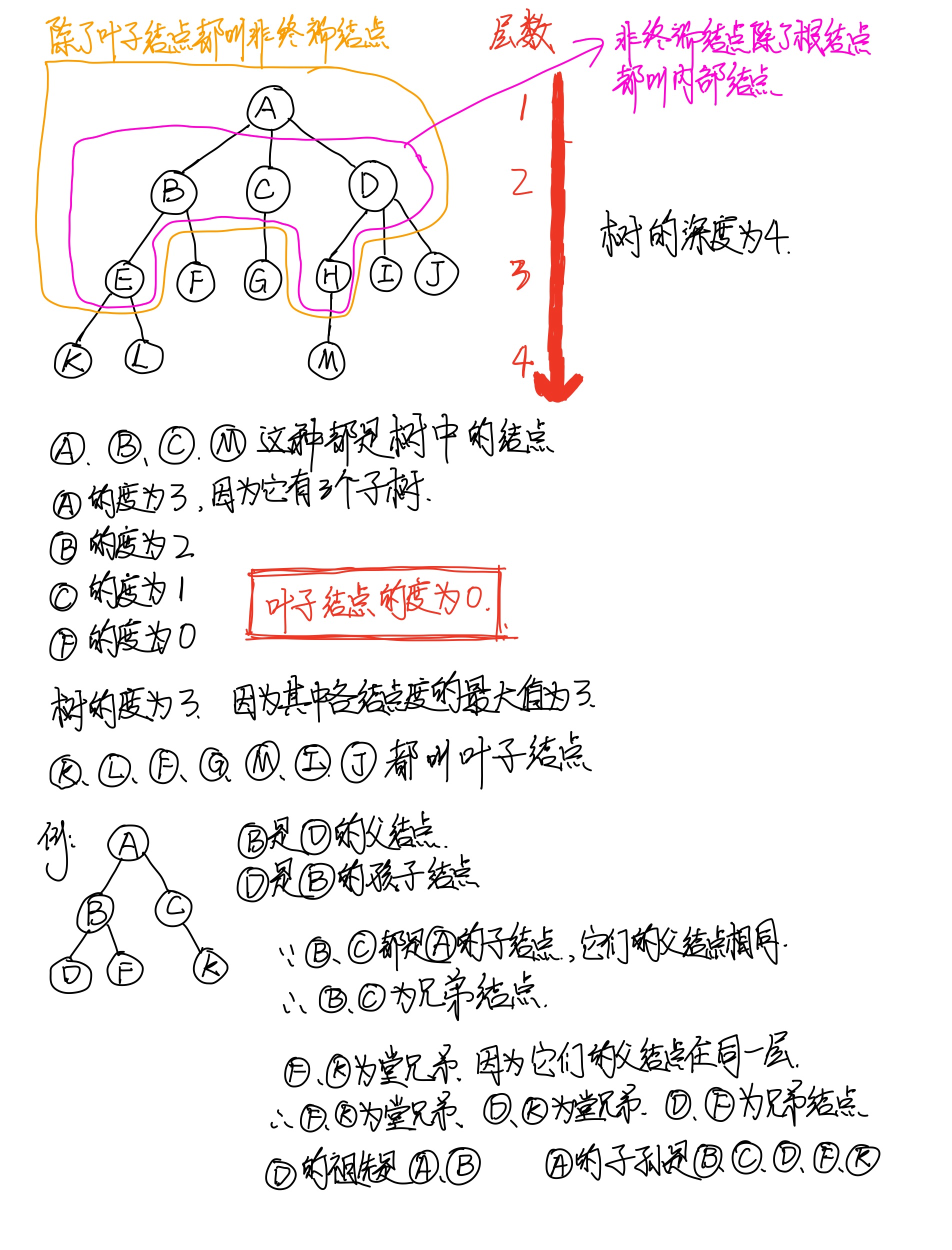
树的基本术语
- 结点:树中的一个独立单元。
- 结点的度:结点的子树的个数。
- 树的度:树内各结点度的最大值。
- 叶子:度为0个结点。也叫叶子结点或终端结点。
- 非终端结点:度不为0的结点称为非终端结点或分支结点。除了最底层的叶子结点都叫非终端结点。
- 内部结点:除了根结点,非终端结点也叫内部结点。也就是在根结点和叶子结点之间的结点。
- 父结点:有子树的结点是其子树的根结点的父结点。
- 子结点:若A是B的父结点,则B是A的孩子结点,子结点也叫孩子结点。
- 兄弟结点:同一个父结点的孩子可以之间互称为兄弟。
- 堂兄弟:双亲在同一层的结点互为堂兄弟。
- 祖先:从根结点到该结点所经分支上的所有结点。
- 子孙:以某结点为根结点的子树的任一结点都称为给结点的子孙。
- 层次:树的层次从根开始定义,根为第一层,依次向下层数递增。
- 树的深度:树中结点的最大层次称为树的深度或高度。指的是最大有多少层。
术语的图解表示:
树的表示
一般的树我们可以用 儿子-兄弟表示法,
二叉树的定义
二叉树:n(n>=0)个结点构成的集合。
当n=0时,为空树。
当n不为0时,有以下性质:
- 有且仅有一个称之为根的结点。
- 除根结点以外的其他结点分为2个互不相交的子集T1,T2,分别称为T的左子树和右子树,并且T1,T2本身也是二叉树。
二叉树有5种基本形式
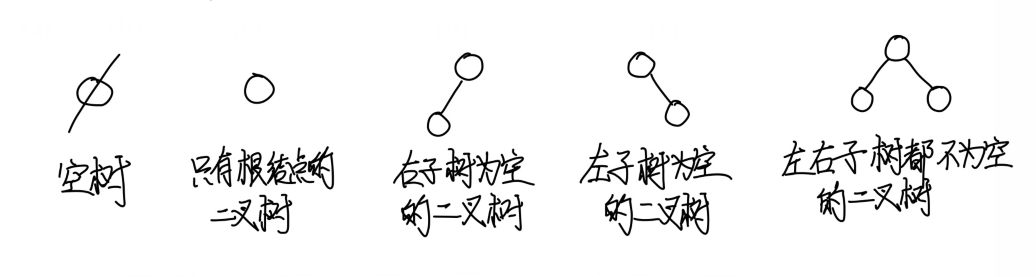
注意:二叉树的子树有左右之分。
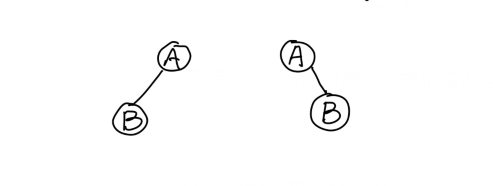
对于二叉树来说,这2棵是不同的二叉树。虽然它们都只有一个子树,但一个是左子树,一个是右子树,属于不同的二叉树。
二叉树的特殊形式
-
斜二叉树(每一个结点都只有左孩子或只有右孩子)。
-
满二叉树(完美二叉树):深度为k且含有 2k-1 个结点的二叉树。
满二叉树的每一层都是满的,在第 i 层上一定有 2i-1 个结点。
含有n个结点的满二叉树的深度为 log 2(n+1) 。
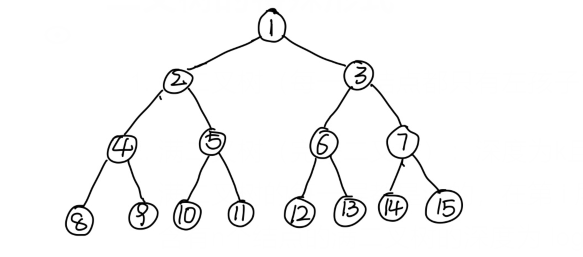
-
完全二叉树:深度为k的,有n个结点的二叉树,当且仅当其中的每一个结点都与深度为k的满二叉树中从1到n的结点一一对应时,为完全二叉树。

右侧例子不是一个完全二叉树,因为在8结点右边应该有一个兄弟结点,而不是直接到下一个叫结点的左孩子。
二叉树的重要性质
- 在二叉树的第 i 层上最多有 2i-1 个结点。(n>=1)
- 深度为 k 的二叉树拥有的最大结点数为 2k-1 个结点。(k>=1)
- 对于任何一棵二叉树,如果其终端结点个数为n0,度为2的结点个数为n2,则 n0=n2+1 。
- 具有n个结点的 完全二叉树 的深度为 log 2n(向下取整) +1 。
二叉树的操作
4种遍历方式和代码(为了方便大家学习,可以直接运行)
- 先序遍历(根,左,右) LeetCode:144. 二叉树的前序遍历
void preorderTraversal(TreeNode* root) {
if(!root)
return;
cout<<root->val<<" ";
preorderTraversal(root->left);
preorderTraversal(root->right);
}
- 中序遍历(左,根,右) LeetCode:94. 二叉树的中序遍历
void inorderTraversal(TreeNode* root) {
if(!root)
return;
inorderTraversal(root->left);
cout<<root->val<<" ";
inorderTraversal(root->right);
}
- 后序遍历(左,右,根) LeetCode:145. 二叉树的后序遍历
void postorderTraversal(TreeNode* root) {
if(!root)
return;
postorderTraversal(root->left);
postorderTraversal(root->right);
cout<<root->val<<" ";
}
注意:在给出二叉树的遍历序列时,3个遍历序列给出2个时,如果包含中序遍历序列,则可以得到唯一一棵对应的二叉树,但如果只给出前序和后序遍历,则不能得出唯一的一棵二叉树。
- 层次遍历(按每一层依次遍历,从上到下,从左到右) LeetCode:102. 二叉树的层序遍历
利用队列完成二叉树的层次操作:构建一个存放结点指针的队列,当队列不为空时,说明还有没有遍历到的二叉树结点,则继续进行循环,每一次都对队列中的所有元素进行一次遍历,队列中每一次存放的都是一行的元素,设一个临时指针指向队列开头结点,当该结点不为空时,将它的左右孩子入队,因为每次都是先将左孩子入队,所以每一行的遍历都是从左往右,孩子入队之后,再输出当前结点的值,然后退出第一个元素,继续遍历这一行中的下一个元素。
void levelOrder(TreeNode *root){
queue<TreeNode*> q;
q.push(root);
while(!q.empty()){
int n=q.size();
for(int i=0;i<n;++i){
TreeNode *temp=q.front();
if(temp){
q.push(temp->left);
q.push(temp->right);
cout<<temp->val<<" ";
}
q.pop();
}
}
}
测试数据:
-1
2 5 -1 7 56 -1 -1 34 -1 -1 55 -1 22 -1 66 -1 -1
代码:(按 ctrl+Z 结束输入,程序输出结果)
#include<iostream>
#include<vector>
#include<string>
#include<sstream>
#include<queue>
#include<stack>
#include<algorithm>
#include<stdio.h>
#include<map>
#include<unordered_map>
using namespace std;
int em,shu;
//二叉树的结点
struct TreeNode{
int val;//树中结点的值
TreeNode *left,*right;//结点的左右指针
TreeNode():left(NULL),right(NULL){
} //构造函数
TreeNode(int value):val(value),left(NULL),right(NULL){
}
TreeNode(int value,TreeNode *l,TreeNode *r){
//带参数的构造函数
val=value; left=l; right=r;
}
int Getval(){
return val;}//返回结点的值
TreeNode* Getleft(TreeNode *root){
return root->left;}//返回root结点的左孩子
TreeNode* Getright(TreeNode *root){
return root->right;}//返回root结点的右孩子
};
//二叉树
class BinaryTree{
private:
TreeNode *root=NULL;//根结点指针
int sum=0;//结点总数
public:
BinaryTree():root(NULL),sum(0){
}//无参数的构造函数
//带参数的构造函数
//返回根结点
TreeNode* Getroot() const {
return root;}
//返回二叉树结点的个数
int GetBinaryTreeSize() const {
return sum;}
//判断二叉树是否为空
bool isBinaryTreeNULL() const {
return root==NULL;}
//返回根结点的值
int GetRootval() const {
return root->val;}
void SetRoot(TreeNode *r){
root=r;}
//构建二叉树的内部函数(前序遍历)
TreeNode* CreatBinaryTree(vector<int> &v,int &e,int &i){
if(i+1>=v.size())
return NULL;
int x=v[i];
++i;
if(x==em)
return NULL;
else{
++sum;
TreeNode *node=new TreeNode(x);
node->val=x;
node->left=CreatBinaryTree(v,e,i);
node->right=CreatBinaryTree(v,e,i);
return node;
}
}
//对二叉树前序遍历
void preorderTraversal(TreeNode* root) {
if(!root)
return;
cout<<root->val<<" ";
preorderTraversal(root->left);
preorderTraversal(root->right);
}
//对二叉树中序遍历
void inorderTraversal(TreeNode* root) {
if(!root)
return;
inorderTraversal(root->left);
cout<<root->val<<" ";
inorderTraversal(root->right);
}
//对二叉树后序遍历
void postorderTraversal(TreeNode* root) {
if(!root)
return;
postorderTraversal(root->left);
postorderTraversal(root->right);
cout<<root->val<<" ";
}
//对二叉树层次遍历
void levelOrder(TreeNode *root){
queue<TreeNode*> q;
q.push(root);
while(!q.empty()){
int n=q.size();
for(int i=0;i<n;++i){
TreeNode *temp=q.front();
if(temp){
q.push(temp->left);
q.push(temp->right);
cout<<temp->val<<" ";
}
q.pop();
}
}
}
};
//构建二叉树
void CreatTree(BinaryTree &T,int e){
int x;
vector<int> v;
while(scanf("%d",&x)!=EOF)
v.push_back(x);
TreeNode *root=NULL;
int num=0;
root=T.CreatBinaryTree(v,em,num);
T.SetRoot(root);
}
int main(){
cin>>em;
getchar();
BinaryTree T;
CreatTree(T,em);
TreeNode *root=T.Getroot();//获得二叉树的根结点
T.preorderTraversal(root);//先序遍历
cout<<endl;
T.inorderTraversal(root);//中序遍历
cout<<endl;
T.postorderTraversal(root);//后序遍历
cout<<endl;
T.levelOrder(root);//层次遍历
cout<<endl;
return 0;
}
执行结果:

二叉树的经典题目
1.对称二叉树
题目:101. 对称二叉树
代码分析:(C++)
class Solution {
public:
bool cmp(TreeNode *lchild,TreeNode *rchild){
if(lchild==NULL&&rchild==NULL)//当一个结点的左右孩子都为空时对称
return true;
if(lchild&&!rchild||!lchild&&rchild||lchild->val!=rchild->val)
return false;//当其中有一棵为空,另一棵不为空时不对称,或者当左右子树的值不同时也不对称
return cmp(lchild->left,rchild->right)&&cmp(lchild->right,rchild->left);
}
bool isSymmetric(TreeNode* root) {
if(!root)//如果是空树直接返回true
return true;
return cmp(root->left,root->right);//递归判断左右子树是否对称
}
};
引用一段高赞评论:
递归的难点在于:找到可以递归的点 为什么很多人觉得递归一看就会,一写就废。 或者说是自己写无法写出来,关键就是你对递归理解的深不深。
对于此题: 递归的点怎么找?从拿到题的第一时间开始,思路如下:
1.怎么判断一棵树是不是对称二叉树? 答案:如果所给根节点,为空,那么是对称。如果不为空的话,当他的左子树与右子树对称时,他对称
2.那么怎么知道左子树与右子树对不对称呢?在这我直接叫为左树和右树 答案:如果左树的左孩子与右树的右孩子对称,左树的右孩子与右树的左孩子对称,那么这个左树和右树就对称。
仔细读这句话,是不是有点绕?怎么感觉有一个功能A我想实现,但我去实现A的时候又要用到A实现后的功能呢?
当你思考到这里的时候,递归点已经出现了: 递归点:我在尝试判断左树与右树对称的条件时,发现其跟两树的孩子的对称情况有关系。
想到这里,你不必有太多疑问,上手去按思路写代码,函数A(左树,右树)功能是返回是否对称
def 函数A(左树,右树): 左树节点值等于右树节点值 且 函数A(左树的左子树,右树的右子树),函数A(左树的右子树,右树的左子树)均为真 才返回真
实现完毕。。。
写着写着。。。你就发现你写出来了。。。。。。
2.相同的树
题目:100. 相同的树
代码分析:(Java)
class Solution {
public boolean cmp(TreeNode lchild,TreeNode rchild){
if(lchild==null&&rchild==null)//当相同位置的结点都为空时相等
return true;
//相同位置的结点只有一个为空,或者2个结点的值不同时不相等
if(lchild==null&&rchild!=null||lchild!=null&&rchild==null||lchild.val!=rchild.val)
return false;
//每次比较的都是相同位置的结点是否相等
return cmp(lchild.left,rchild.left)&&cmp(lchild.right,rchild.right);
}
public boolean isSameTree(TreeNode p, TreeNode q) {
return cmp(p,q);
}
}
3.二叉树的最大深度
在这里插入代码片
树的优势
查找
查找:给定某个关键字K,在集合R中找出关键字与K相同的记录。
查找分为 静态查找 和 动态查找。
- 静态查找:集合中的记录是固定的。没有插入和删除操作,只有查找。
静态查找一般的思路是把数据放到数组中,最简单的查找方式是顺序查找,也就是从头到尾一个一个找。
(C++顺序查找代码)
int Finder(int x,int a[],int n){
for(int i=0;i<n;++i)
if(a[i]==x)
return i; //如果找到了则返回下标i
return -1; //没找到就返回下标-1
}
可以看出,这种查找方式的时间复杂度为O(n),查找效率并不高。
当然还有更快的查找方式,就是二分查找。
二分查找的条件:n个元素有序并且连续存放(如在数组中),可以进行二分查找。如果不是有序的,二分是做不出来的。
(C++二分查找代码)
int Finder(int x,int a[],int n){
int left=0,right=n-1;
while(left<=right){
int mid=(left+(right-left)/2);//这里其实等效与(left+right)/2 ,但是这样写如果数字比较大时可能会越界,超出范围
if(x>a[mid])
left=mid+1;
else if(x<a[mid])
right=mid-1;
else
return left;
}
return -1;
}
二分查找图解:
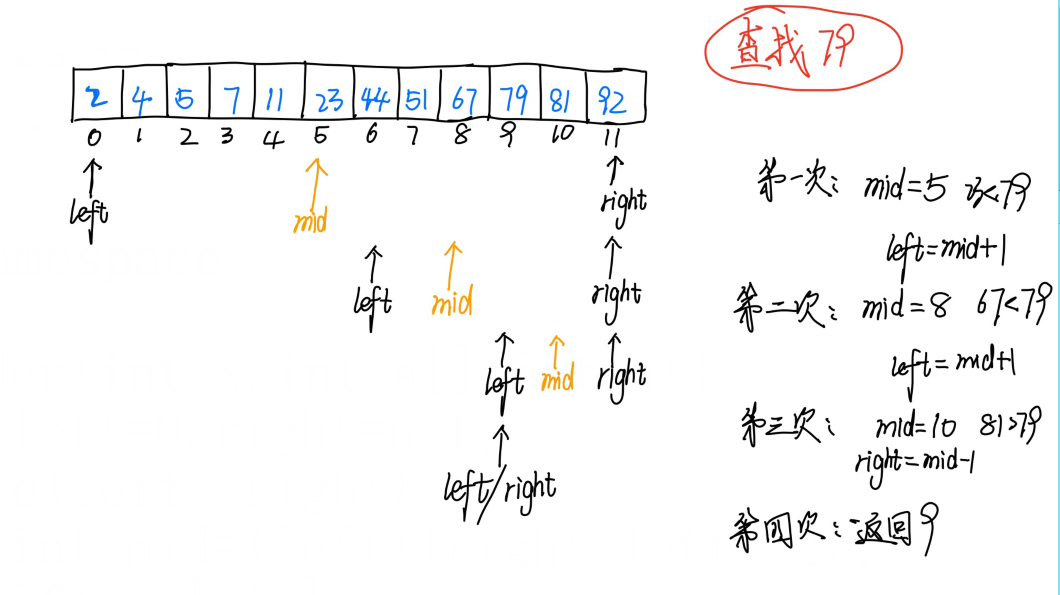
二分查找每次查找的都是查找范围的一半,所以时间复杂度是O(logn)。
这样我们就可以构成一个二分查找判定树:
- 判定树上每个结点需要查找的次数等于该结点所在的层数
- 查找成功时的查找次数不会超过判定树的深度
- n个结点的判定树的深度为 [log 2n]+1
- 平均查找次数=(每一行的结点个数*对应行数)的和 除以 结点总个数。平均查找长度称为ASL
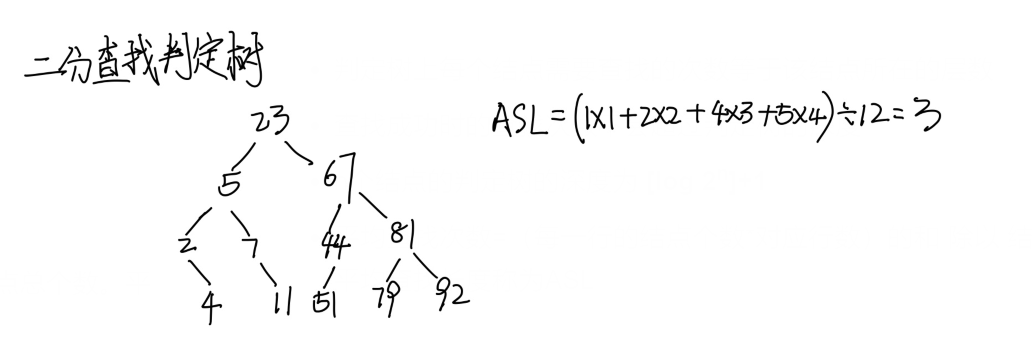
ASL为3则说明平均查找每个数的长度为3。
- 动态查找:除了查找,还可能发生插入和删除。
用查找树可以很好的解决动态查找的问题。