之前有篇文章概要的叙述了一下关于二叉树的创建,参考博文二叉树的c语言创建但是很不全面,这篇文章就让我们来好好探讨一下关于二叉树的创建吧~
首先,我们要做一些前期准备,有关于本课二叉树的结点信息和如何购买一个结点
结点信息
typedef char ElemType;
#define END '#'
typedef struct BtNode
{
struct BtNode* leftchild;
struct BtNode* rightchild;
ElemType data;
}BtNode, *BinaryTree;
新建一个结点
struct BtNode* Buynode()
{
struct BtNode* s = (struct BtNode*)malloc(sizeof(struct BtNode));
if (NULL == s) exit(1);
memset(s, 0, sizeof(struct BtNode));
return s;
}
首先关于二叉树的创建,我们知道最简单的递归方法
方式一:
struct BtNode *CreaetTree1()
{
struct BtNode* s = NULL;
ElemType item;
cin >> item;
if (item != END)
{
s = Buynode();
s->data = item;
s->leftchild = CreaetTree1();
s->rightchild = CreaetTree1();
}
return s;
}

在这儿,我们讲述一个错误的创建方法,大家注意
struct BtNode* CreaetTree2(const char *str)
{
struct BtNode* s = NULL;
if(NULL != str && *str != END)
{
s = Buynode();
s->data = *str;
s->leftchild = CreaetTree2(str+1);
s->rightchild = CreaetTree2(str+1);
}
return s;
}
这样创建的二叉树为
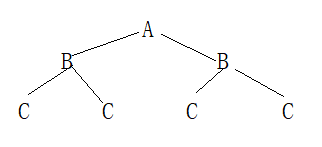
我们可以用层次分析法来解释一下,当结点A创建完毕;再创建其左子树的时候进入过后str+1为结点B,创建右子树传入的参数还是str :A。以此类推…
如果将str+1 改为str++,也不正确,构建出来的二叉树为下图:
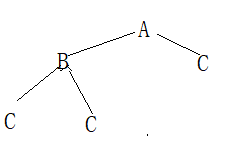
方式二:
struct BtNode* CreaetTree3(const char*& str)
{
struct BtNode* s = NULL;
if (NULL != str && *str != END)
{
s = Buynode();
s->data = *str;
s->leftchild = CreaetTree3(++str);
s->rightchild = CreaetTree3(++str);
}
return s;
}
在解释上述过程的时候,我们要引入一个关于指针和引用的概念。
引用的本质:语法糖(逻辑上很简单,将复杂的过程交给编译器,但是看起来很好理解)所以从逻辑和语法上来看就没有占有空间,但是编译过后的机器上面来看相当于指针所以是占用空间的

从上述代码中我们可以清晰的看出引用的使用方法,c在底层实质上就是一个自身为常性的指针。下面我们再来看一个引用逻辑和底层的对比

有了上述关于引用的了解,我们对这种方式的二叉树遍历就有了一个更为清楚的认识了想比于上述错误的做法,这样每次递归传入的值都是做了相应的改变的。
方式三:二级指针的做法
struct BtNode* CreaetTree4(const char** const pstr)
{
struct BtNode* s = NULL;
if (NULL != pstr && *pstr != NULL && **pstr != END)
{
s = Buynode();
s->data = **pstr;
s->leftchild = CreaetTree4(&++*pstr);
s->rightchild = CreaetTree4(&++*pstr);
}
return s;
}
主方法:
扫描二维码关注公众号,回复:
10096390 查看本文章

int main()
{
const char* str1 = "ABC##DE##F##G#H##";
BinaryTree root = NULL;
root = CreaetTree3(str1);
return 0;
}
